我国社会标签研究进展内容分析*
2014-03-14邱均平
邱均平,柴 雯
我国社会标签研究进展内容分析*
邱均平,柴 雯
社会标签是一种交互式Web2.0应用,能够实现对网络信息资源的有效分类和组织。文章利用内容分析法从时间、学科和关键词三个维度对CNKI数据库2006年至2012年国内社会标签领域相关论文进行分析,探讨了当前社会标签领域的研究主题和研究进展。
社会标签 内容分析 进展研究
0 引言
社会标签(Social Tag)起源于2003年Delicious网站的上线,该网站旨在使用标签的形式帮助用户管理、共享和利用网络资源,公众可随意对收藏的网络资源进行标注,“贴”上标签。这种自由灵活的标注方法很快受到用户的关注。随着用户数量和标签数量的累积,社会标签在网络资源聚合中的优势逐渐显现,用户可以通过标签来迅速有效地查找、聚合与共享网络资源。当前国外关于社会标签的研究与讨论很多,有学者将国外相关研究分为存在价值的研究、基于Tag的定量分析、基于用户的定量分析、系统的设计及应用研究、缺陷解决措施研究以及检索问题等六方面[1]。国内相关研究起步晚,学界一般认为从2006年开始[2]。本文以研究社会标签的相关论文为对象,力图通过时间分析、高频词分析和共词分析等内容分析方法了解近年社会标签的研究状况与新进展,为数字资源语义化聚合研究提供借鉴。
1 数据来源与分析方法
本文选取CNKI作为数据来源,以关键词进行检索,关键词包括社会标签、社会分类法、社会化标签、社会标注、大众分类、分众分类、协同标注、公众分类和民俗分类共九个中文词及Folksonomy一个英文词。论文发表时间为2006-2012年。然后对检索结果进行查重过滤,最终得到学术论文221篇。
本文采用内容分析法进行研究。内容分析法是一种对具有明确特性的传播内容进行的客观定量且系统化描述的研究方法[3-4]。在进行关键词分析时,本文辅助采用了共词分析法。由于主题词汇共同出现的频次可以用来代表主题之间的亲疏关系,该方法利用文献集中词汇对或名词短语共同出现的情况,来确定该文献集所代表学科中各主题之间的关系[5]。本文选择论文的“篇”以及其关键词的“频次”作为分析单位,依次通过论文的时间分布、学科分布、关键词分析等三个层面来进行社会标签研究现状的分析,进而探讨社会标签研究的新进展。
2 分析结果
2.1 论文的时间分布
图1显示了2006-2012年论文数量的时间分布情况,总体上看论文累积量呈现逐年增加的趋势。国内最早的专业网摘站点是2004年上线的365key,当时社会标签的应用在我国还不普遍,关于这一领域的研究非常少。2006年开始,国内出现了相关学术研究成果,并呈快速发展趋势。中国互联网协会发布的《2005-2006中国Web2.0现状与趋势调查报告》显示:2005年到2006年用户使用网摘收藏文章比较频繁,其中每周1次的占22.3%,每周2-3次的占22.8%,每周4-6次的占10.7%;此外,每天都使用网摘服务的用户也有14.5%[6]。门户网摘迅速崛起,专业网摘站点数量大幅增加,这些都使得社会标签逐渐成为Web2.0中的重要角色,并引起了学者对该领域的研究兴趣,反映到学术成果上则表现为2006年起论文数量的快速增加。结合论文的逐年累积情况进行趋势分析发现,2006年至2012年的论文累计数量呈指数增长(图1中虚线)。根据文献信息增长规律[7]可知,当前国内社会标签领域的研究正处于诞生和发展时期。

图1 论文数量及增长趋势
2.2 学科分布情况
221篇论文共刊载于59种学术期刊,根据RCCSE分类,论文的学科分布见图2。从图2中可以看出,社会标签研究论文主要集中于图书馆学、情报学与文献学,共162篇,占全部论文的73.3%。此外,计算机科学技术领域也在社会标签研究中占据了相对重要的位置,共发表21篇论文,所占比例为9.5%。
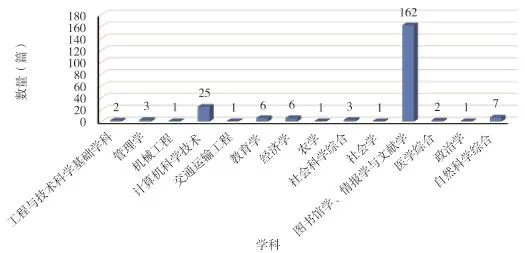
图2 学科分布
社会标签是一种通过用户参与创建和管理,从而对内容进行标注和分类的方法与应用,它向用户提供一种协同组织与分享网络资源的开放式平台。因此,作为新型的信息组织方式,它是图书馆学、情报学与文献学的重要研究方向。该领域的专家主要从社会标签本身、知识组织、知识创新与知识共享、资源聚类与检索、语义化以及社会标签在不同领域尤其是在图书馆的应用研究等角度来探索社会标签的理论、技术与应用。从学科分布情况看出,图书情报专家是社会标签研究的主要参与者。
2006-2009年,国内仅有4篇文献发表于计算机科学与技术类期刊,分别研究协同标注的技术与模型、检索技术(语义检索、图像检索、个性化检索)和网页挖掘技术。2009年以后,随着图书情报理论研究的深入,技术研究开始细化,主要体现在4个研究方面:(1)标签推荐,包括模糊标签和冗余标签的处理、推荐算法、推荐系统研究;(2)用户,包括用户特征描述和用户模型构建;(3)标签语义化和规范化,包括标签层次关系提取、本体研究和概念格在提升标签概念结构方面的应用;(4)信息检索,包括标签排序、标签云和查询词扩展研究。
少数论文分布在其余12个学科领域,在交叉学科和综合领域,社会标签的理论研究和技术研究占据主要地位;在教育、航空航天、政治、农学等学科领域,学者们主要研究社会标签的具体应用,主要目的是为了提升知识组织效果,优化检索结果,促进知识共享。
2.3 关键词分析
2.3.1 关键词统计分析
表1是2006-2012年热点词汇按照词频进行排列生成。在关键词处理过程中,笔者发现,尽管业界学者对社会标签的定义是比较统一的,基本上都满足公众参与、无严格分类体系、自由易用等特点,但是国内学者在这一概念的称呼上各持一词,约有十余种。因此在关键词排序结果中,为了突出研究热点与特点,笔者去除了标签、社会标签、分众分类、社会分类、Tag、Folksonomy等十余个高频同义词。
2006年文献数量较少,仅有“信息组织”的词频大于1,其余关键词词频均为1。学者们分别从元数据、网络信息组织方法、知识组织等角度来探讨这一新型信息组织方法,认识其优缺点、模式和应用前景。除了理论上的一些探索,还有学者已经认识到了Tag在教育技术中的可行性和优越性[8]。2007年的关键词排名与2006年相比,除去排名第一的“信息组织”,情形几乎完全不同。这一年的研究不仅仅再从宏观角度来认知社会标签,主要关注Web2.0环境下社会标签作为一种独特的网络分类法在具体的应用中如何进行信息组织。2008年,“本体”和“信息检索”成为了热点词汇,学者开始认识到社会标签包含了潜在的语义信息,可以用来快速构建本体,优化本体构建方法。同时,从信息检索的角度重点关注如何利用社会标签来优化检索效果,提高查准率和查全率。2009年出现了“无标度”“小世界”“复杂网络”等词汇,这表明对社会标签的研究逐渐从定性的认知发展到定量研究。2010年首次出现了“凝聚子群分析”词汇,在对资源、标签、用户三者关系进行定量化分析的基础上,学者们开始了标签的聚类研究,为信息资源聚类和本体研究提供良好的参考。2011年“个性化”和“用户分类”首次成为高频词,对标签的理论和应用研究最终开始归结于如何给用户提供更好的服务,社会标签的出现为用户兴趣研究、个性化信息推送和个人知识管理提供了新的思路和方法。2012年也出现了与用户相关的一系列词语,如“个人知识管理”“推荐系统”等,同时“数据挖掘”也成为了热点词汇。这几年来,高频词的变化体现了社会标签研究内容的变化,社会标签的研究重点逐渐从特点、性质、数学模型等基本理论的研究转入图书馆、用户、关键技术等应用性研究。
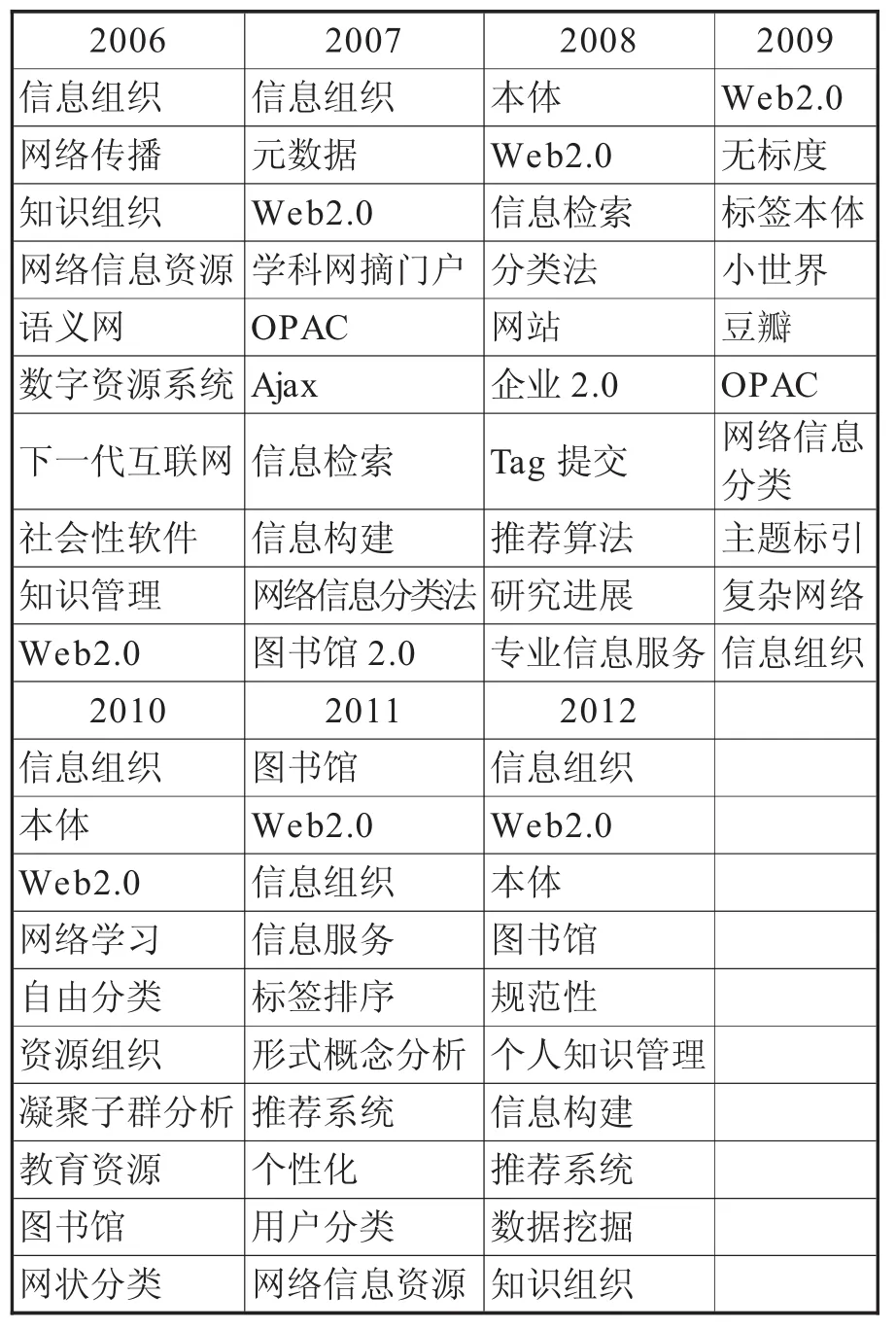
表1 2006~2012年高频词列表
总体来看,当前我国社会标签的研究体现出两个较明显的趋势:(1)从以定性为主的理论研究转入了结合计算机技术和数学模型的定量研究;(2)从以意义与特性为主的理论研究转入以功能和用户为主的应用研究。与此同时,社会标签的研究还出现了不同的分支,研究方法也逐渐与新兴技术相结合。
2.3.2 关键词聚类分析
提取221篇论文的关键词后进行规范,统一同义词,去掉其中包含的检索词和不具有实际意义的词汇,如概述、发展研究,得到326个关键词。本文选取词频大于2、词频占全部词频65%[9]的45个词汇作为分析对象。
由于共词矩阵中的元素均为绝对词频,难以反映词语对之间真正的依赖关系,因此进一步对共词矩阵进行包容化处理。目前包容化处理的算法[10]主要有三种:包容指数法、临近指数法和相互包容系数法。相互包容系数法可以用来计算共词对中的每一个词汇在对方词汇集合中的频次,也称为等价系数法。该方法的计算公式为:

其中,Eij表示共词矩阵中第i个词与第j个词的相互包容系数,Cij表示词汇i与词汇j的绝对共词词频,Ci表示词汇i在文献集中出现的绝对频次,Cj表示词汇j在文献集中出现的绝对频次。本文选取相互包容系数计算得到共词矩阵,并绘制系统聚类图如图3。在聚类分析过程中,本文选用夹角余弦距离计算个体距离,组内平均链接距离计算个体与小类或者小类与小类之间的距离。在聚类的前5步中,仅有7组共14词分别聚成小类,占到高频词的31%左右。大部分词汇因为相关性较低,距离较远而不能聚集在一起。这种情况至第15步才有所改善。说明在社会标签领域中,研究者在使用关键词时并没有达成一致,主题相对分散,相关性较低。
从图3可以看出,关键词可以大致分为7类。结合词汇的中心度以及文献内容进行分析,可以确定7大类主题。
(1)社会分类法的比较与改进。作为新兴的网络分类法,研究者们常常通过与传统分类法的比较来了解和认识社会标签。研究指出,由于社会标签的标注过程伴随着强烈的个人主观性,使得这一分类法带有很大程度的随意性和自由性。虽然这种随意性和自由性降低了元数据的门槛,使得社会标签能够通过扁平的信息架构以利于知识的组织和发现,但是这种不受控的标引过程中常常会出现一词多义、同义词[11]等不规范词汇,为知识组织与管理埋下隐患。
(2)社会标签在数字图书馆中的应用。以分众分类模式运营的Web2.0网站的成功,显现出社会标签能够体现用户价值、迎合用户需求的优点。学科导航数据库、数字图书馆等纷纷借鉴,用以弥补自身缺点,以适应新的信息组织和检索特点。钟远薪、张春晓[12]探讨在图书馆2.0中引入社会标签的意义,认为Tag是一种通过用户参与共享从而构建交互平台的方式,只有通过应用Tag,图书馆才能真正做到对用户开放,对网络开放;只有将Tag引入图书馆2.0,图书馆才能更加契合用户的需要。
(3)知识管理与知识组织。作为一种新兴的信息组织方式,社会标签自诞生之初便受到的广泛的关注。知识时代的大背景结合社会分类法对网络资源组织的高效性,引导人们关注社会标签在知识组织和知识管理方面的应用。信息资源的内容控制主要是通过信息的描述来进行[13],通过描述来揭示信息的实质和中心,从而达到良好的组织和应用的目的。社会分类法相较于其他网络分类法具有更强的语义特性,使得信息的描述和知识的揭示变得更加准确和丰富。此外,社会标签还可以用于个性化服务,在词频分析中已经得知,2012年个人知识管理成为了热点关键词。这些都说明知识管理和知识组织是社会标签研究领域中相当重要的一部分。
(4)知识创新。社会标签能够进行知识创新与知识发现这一观点是近两年才兴起的。社会性网站(如WIKI、BLOG、社会书签网站)提供了用户交流、共享、发布知识的平台,这种群体内的互动使得个体和群体的知识相互“供养”[14],从而达到知识创新和知识发现的目的。
(5)数学模型与数字特征。在关于社会标签领域的研究中,除了定性的描述以外,还有很多定量的描述,这些定量的描述主要从两个角度出发:一是从标签、用户和网络信息资源所构成的网络本身出发来研究网络的特性,包括小世界、无标度等特性;二是从社会标签的应用角度出发,利用数据挖掘、支持向量机和向量空间模型等方法和技术研究其语义挖掘、自动信息分类和检索效率的提升等方面的应用。
(6)标签推荐与聚类。根据Fabian M.Suchanek[15]等人的研究,标签推荐的主要目的是为了便利和规范用户标注行为,但是推荐系统往往在一定程度上会使得标注结果带有“偏见”,因此合理的标签推荐算法成为人们研究与关注的重点。同时,通过对标签、用户和网络信息资源所构成的三方网络的研究,研究者们发现,以往关于两方网络的算法并不适用对三方网络进行的研究,他们希望通过对三方网络的研究来达到网络信息资源利用标签聚类的目的。
(7)标签本体与语义网。社会标签和本体在其构成上具有一致性,都是概念和概念关系的集合。社会标签在概念上具有自由性,在结构上具有单一性,因此可将之视为本体的一种自由简化的形式。相较于本体,社会标签更加的自由易用,这使得人工智能不再仅仅局限于结构和逻辑严密的本体。本体与社会标签的融合成为新一代互联网技术的发展趋势之一[16]。
3 总结与讨论
社会标签是一种全新的分类思想和互联网应用方式。目前社会标签的研究正处于快速发展阶段,涉及学科面广,但是由于受到理论研究和技术的限制,其成果数量并不多。通过对2006年至2012年的期刊文献进行时间、学科、关键词和主题聚类分析,我们可以对社会标签的研究进展做进一步分析和讨论。

图3 树状聚类图
第一,社会标签这一新的信息组织方法为越来越多的学科研究领域提供了借鉴。社会标签最早流行于门户网摘、博客、豆瓣网等Web2.0应用之中,很快,其良好的易用性、自由性和有效的信息组织能力使得人们开始将它引入不同的环境和功能中,包括个性化服务、图书馆2.0、教育领域、企业2.0、博物馆2.0、学习型组织和电子商务等,进而达到提升知识管理能力、促进知识共享交流、构建关系网络[17]、改善服务质量等目的。
第二,从主题分析的结论不难看出,社会标签对信息内容的良好揭示效果为语义关联提供了新的思路。社会标签本身就是一种资源的语义标示,标签、用户和资源的关系为信息的语义组织、语义挖掘和语义检索提供了良好的数据基础,标签的语义特性可以优化知识组织的方法和效果、对资源和用户进行语义聚类、提升搜索引擎检索效率并改善排序、简化图像与音频数据检索的难度、为语义网和本体研究提供思路与借鉴。
第三,社会标签推动了用户研究的技术、方法和形式的进展。不同于博客、微博等Web2.0应用,标签不是长博文或者微博客,也不是难以揭示主题的文本信息。用户的兴趣挖掘不再需要繁琐的算法和过程,高频标签在一定程度上就可以代表用户所关注的信息,通过个人的标签图可以很方便的观察到用户兴趣所在,进而对相同兴趣的用户进行聚类和分析。在社会标签这种新的信息组织过程和模式下还诞生了标签推荐这样一种新的用户服务方式,研究者们致力于研究最优的标签推荐策略和算法,从而提升用户服务质量。不仅如此,将社会标签引入知识管理,还为个人知识管理和群体知识共享提供了灵活的方式,达到了更好的知识管理效果。
[1]余金香.Folksonomy及其国外研究进展[J].图书情报工作,2007,51(7):38-40.
[2]官凤婷.基于文献计量的国内Folksonomy研究现状分析[J].图书馆论坛,2012,32(4):94-100.
[3]邹菲.内容分析法的理论与实践研究[D].武汉:武汉大学,2004.
[4]邱均平,楼雯.基于内容分析法的索引研究论文主题分析[J].图书馆工作与研究,2012(10):62-66.
[5]冯璐,冷伏海.共词分析方法理论进展[J].中国图书馆学报,2006(2):88-92.
[6]Inter-Asia Internet Research Institute.2005-2006中国Web2.0现状与趋势调查报告[R].北京,中国互联网协会,2006.
[7]邱均平.文献计量学[M].北京:科学技术文献出版社,1988.
[8]夏天,杨瑛霞,田爱奎,等.Tag和现代教育技术[J].中国电化教育,2006(9):89-92.
[9]马费成,望俊成,陈金霞,等.我国数字信息资源研究的热点领域:共词分析透视[J].情报理论与实践,2007,30(4):438-443.
[10]钟伟金,李佳.共词分析法研究(一)——共词分析的过程与方式[J].情报杂志,2008(5):70-72.
[11]梁桂英,李记旭.Folksonomy初探[J].图书馆杂志,2006,25(4):46-49
[12]钟远薪,张春晓.基于Ajax的嵌入式Tag系统初步研究[J].图书馆杂志,2007,26(8):40-43.
[13][14]张敏,邓胜利.基于内容揭示的信息资源控制的演进[J].图书情报工作,2009,53(2):117-120.
[15]Fabian M.Suchanek,Milan Vojnovi'c and Dinan Gunawardena.Social Tags:Meaning and Suggestions [J].Microsoft Research,2008:223-232.
[16]李学庆.浅议Web2.0环境下基于本体论的Folksonomy[J].情报探索,2011(8):4-6.
[17]贾君枝,张宁.社会标签的应用功能分析[J].情报理论与实践,2012,35(11):112-116.
Content Analysis as a Tool for Folksonomy Research in China
QIUJun-ping,CHAI Wen
As a Web2.0 application,Folksonomy can organize internet information effectively.From the perspective of time,discipline and keywords,this paper gives an analysis of the articles on Folksonomy from CNKI database between 2006 and 2012 with content analysis method;and discusses the current topics and advances of Folksonomy research in China.
Folksonomy;content analysis;research advances
格式 邱均平,柴雯.我国社会标签研究进展内容分析[J].图书馆论坛,2014(7):8-14.
邱均平(1947-),男,武汉大学中国科学评价研究中心主任;柴雯,女,武汉大学信息管理学院在读硕士研究生。
2013-10-31
*本文系国家社会科学基金重大项目“基于语义的馆藏资源深度聚合与可视化展示研究”(项目编号:11&ZD152)研究成果之一
