一种基于多分类语义分析和个性化的语义检索方法
2014-03-13马应龙李鹏鹏张敬旭
马应龙 李鹏鹏 张敬旭
(1 华北电力大学控制与计算机工程学院,北京102206)
(2 甘肃省电力公司,兰州730030)
Web 信息量的爆炸式增长对信息获取手段提出了更高的要求.传统的基于语法的检索方式存在精度偏低和冗余文档过多等问题,基于概念的语义检索成为研究热点.近年来,其研究内容主要包括3 个方面:①基于用户信息的个性化,即利用分析用户历史[1-2]或个人信息[3]来提高检索精度;②利用数学模型计算上下文的语义关联度,以增加检索结果的有效涵盖面[4-5];③侧重检索结果的优化,对检索结果进行重新排序和组织,以改善用户体验[6-7].但这些方法仍然存在用户数据和分类信息获取困难的问题,且没有考虑不同个人信息的重要程度.
本文提出了一种基于多分类语义分析和个性化的语义检索方法.它使用多分类语义分析对目标文本进行语义分类,利用分类结果和分类过程中获取的词向量库,结合用户个人信息和检索历史数据对目标文档进行分析匹配.相关实验评估和分析显示,本文方法能在额外时间开销较小的情况下大幅提高综合语义检索效果.
1 多分类语义分析
语义分析(semantic analysis)是一种向量表示方法,通过计算每个词和预定义好的概念之间的关系,对词和文档片段进行阐释.Li 等[8]提出了简明语义分析,利用语料库的类别标签构造概念空间,能有效降低文档向量维数、提高分类效率,且这种思想在语议检索领域具有较高的价值[9].但在确定词权重时使用的tfrf 权值计算法所涉及到的正反面文档概念在多分类中没有定义,因而存在一定的局限性.为此,本文提出了一种多分类语义分析表示法,可以在实现多分类的同时,更高效地利用语义分析过程中产生的数据.其优势主要体现在:
1)构造向量所需的概念空间取决于语料库的标签集,通常情况下维数大大小于传统方法.
2)在特征选择阶段只需去除噪声词,无需复杂的降维操作.
3)遴选具有一定语义的词向量加入词向量库,可以结构化数据,有力支持个性化工作和后续相关研究.
4)采用了适用于多分类的词权值计算法和支持向量机,支持文本多分类.
1.1 概念空间
概念空间是由概念构成、从语料库标签中提取的,能表示整个语料库类别信息的向量空间.语料库中的分类标签被直接提取为概念空间的概念.
1.2 词向量表示
概念空间建立后,需要考虑如何在此空间上将文档表示成向量.文档是由词构成的,下面给出把一个词解析成在特定概念空间上的词向量的方法.对于文档dk中的每个词tj,它与概念空间C 中的概念ci之间的紧密度w(ci,tj)可表示为
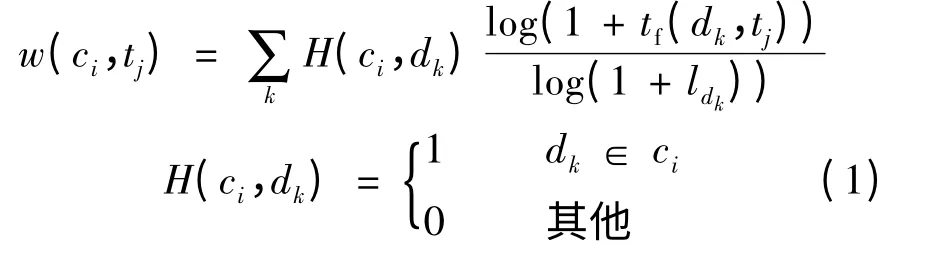
式中,tf为词的频度;ldk为文档dk的长度.当dk在语料库中是类别ci(对应概念空间的概念ci)下的文档时,H(ci,tj)=1;否则,H(ci,tj)=0.
计算一个词与概念空间中每个概念的紧密度并将其作为词向量的每个维度值,便可得到其在这个概念空间上的词向量.词向量可以把词的概念意义数量化,具有强的语义关联性.
然后,使用归一化方法将词向量中每一个维度的值都落在[0,1]之间,完成词向量的表示,即归一化后的紧密度为
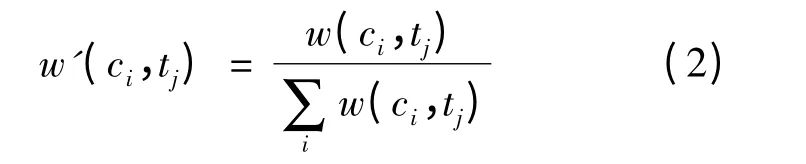
1.3 文档向量表示
文档向量是由文档所包含的所有有效词的词向量取中心值得到的.当然,中心值并不是简单的取平均值,因为文档中每个词的重要性是不同的.本文使用TFIDF 公式确定每个词的权值,即
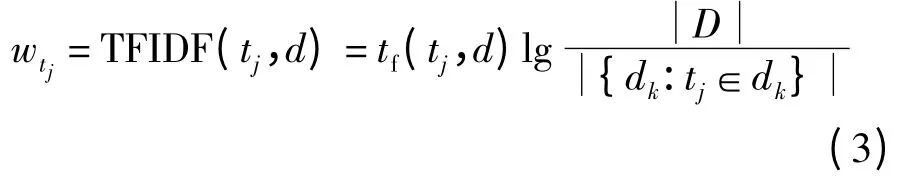
式中,wtj为词tj的权值;D 为整个语料库的文档集合;d 为tj当前所在的文档.TFIDF 权值法由于不涉及正反类别文档的概念,可以用于多分类的情况.这样,给定一个文档dk,它对应的文档向量中每一个维度的值wd(ci,dk)可以表示为
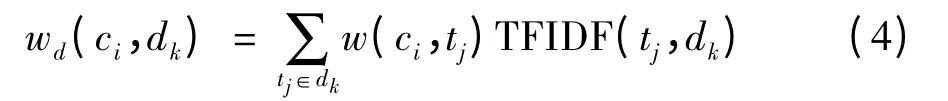
其向量形式为

式中,Tj为tj的词向量.
进行与式(2)类似的归一化后,文档被表示成向量形式,可以用于支持向量机的分类.这样形成的每个文档向量的维数只取决于概念空间的概念数(通常在100 以内),故能大大减少分类用时.
2 语义个性化
语义个性化工作建立在匹配思想的基础上,通过分析用户检索意图与其个人信息间的关系,从文档集中匹配出最贴近用户真实需要的结果.
2.1 用户信息选取和分析
经调查和统计,影响用户检索意图的个人信息要素主要包括爱好、职业和性别3 种,其重要性权值依次为0.5,0.3 和0.2.
2.2 语义匹配
语义匹配的目的是从目标文档中筛选出用于个性化的初始结果集.在已知文档类别的情况下,可以结合词向量库,分别对用户的查询和用户的个人信息进行匹配分析.
2.2.1 查询匹配
假设用户查询经分词和去噪后形成关键词集合K={k1,k2,…,kn},在词向量库中对应的词向量空间为T ={T1,T2,…,Tn}.当词向量库中不存在ki时,Ti为零向量.若初始的概念空间中有m个概念,则查询向量Q 为

式中,α1,α2,…,αm为查询向量Q 中每个维度的值.
根据文献[1]的研究,一个查询最多能划分为3 种类别.取查询向量前3 个维度值最大的维度α1,α2,α3,其对应的类别分别为c1,c2,c3.由此便可将这3 类文档从目标文档中筛选出来,并生成类别权值向量W,即
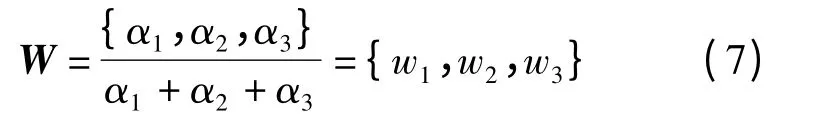
将筛选出的3 类文档按照向量W 中对应的维度值大小排序后,便可得到初始检索结果集.
2.2.2 个人信息匹配
个人信息匹配的目的是构造表示用户职业和爱好的类别权值向量Wp和Wh,以用于下一步的个性化算法.Wp与Wh构造的方法与查询向量的构造流程相同,不同之处在于这里需要使用用户个人信息,而不是用户查询到词向量库中进行查找和分析.
2.3 个性化算法
个性化算法的目的是利用用户个人信息优化初始检索结果集的排序.初始结果集里每个文档的基础得分由Lucene 方法评分给出.
给定一个职业权值向量Wp={w1,w2,w3},对应的概念类别为{c1,c2,c3},同理,爱好权值向量Wh= {v1,v2,v3},对应概念类别为{c4,c5,c6}.设概念集合C={c1,c2,c3}∪{c4,c5,c6},则对于每一个初始结果集文档,若它的类别为ci,且ci∈C,根据下式更新其得分:

式中,nnew为新的得分;nold为初始得分;ntop和nlast分别为初始结果集中所有文档的最高基础得分和最低基础得分;wi和vi分别为权值向量Wp与Wh对应概念ci的维度值;s 为条件参数,当文档与用户的性别相关时s=1,反之则s=0.
2.4 历史数据优化
在用户检索时,检索历史会被记录下来.若一个文档链接被大量的用户点击过,则称之为热门链接.这些历史数据是动态变化的,并影响着用户潜在的搜索意向.在本文中,大众用户的近期点击历史也被加入考虑,从而增加了历史数据的权威性.
若文档d 在此用户的点击历史记录里是一个热门链接,则进行如下计算以更新其初始排名r(d):
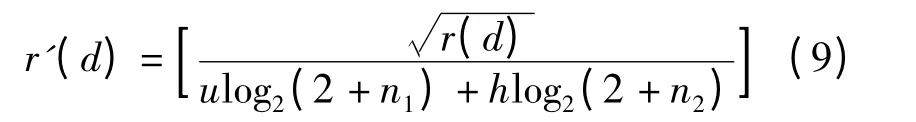
式中,r′(d)为新的排名;n1和n2分别为历史链接和热门链接被点击的次数;u 和h 为条件参数.当此文档在用户点击历史中时,u =1;否则u =0.当此文档是热门链接时,h=1;否则h=0.
经过根据历史数据的重排序后,最终的结果被返回给用户.
3 实验评估与分析
3.1 语料库选择
为了测试本文方法的检索效果,本文使用搜狗新闻语料库以及来自Yahoo Directory 的部分网页进行文本处理后,参考文献[10]的评估方法进行实验.同时,将Lucene 方法和Yahoo Directory 方法作为考察检索性能时的比较对象.
3.2 评估指标
3.2.1 检索精度
对于每个查询,取检索结果的前10 个文档,若其中与查询内容相关的文档数目为Dr,则每次查询的检索精度R 为

多次查询取平均值,即可得到该方法的检索精度.
3.2.2 综合检索效果
DCG(discounted cumulative gain)评估是一个衡量搜索引擎算法整体检索效果的指标,建立在PI 评分的基础上.PI 评分是一种用户对文档的评分.通常,第i 名用户的PI 评分Ei=2 表示用户与文档相关,Ei=1 表示一般,Ei=0 表示不相关.其计算公式为

式中,Fp为文档的DCG 值;Ei为第i 名的PI 评分;p 为统计文档个数,这里设为10.
3.2.3 排序效果
nDCG 是一个基于DCG 的排序效果评估指标,仅对相同结果下排序的优劣作出评估.其计算公式为

式中,F′p,Ip分别表示最优情况下这些文档的nDCG 值和IDCG 值.
3.2.4 时间复杂度
由于Yahoo Directory 方法是一种在线检索,有网络延迟的因素,这里只对比采用Lucene 方法与采用本文方法检索的平均时间消耗,以此评估时间复杂度.
3.3 实验结果及分析
3.3.1 检索精度
图1为3 种检索方式的检索精度对比结果.由图可知,相比Lucene 方法的检索精度(0.41),本文方法的检索精度(0.70)有较大提升.尽管个别用户认为本文方法相对于Yahoo Directory 方法的提高并不明显,但是就前两者的均值(0.53)而言,本文方法仍然有着31%的提升效果.值得注意的是,精度反映的只是前10 名结果中相关文档的平均数目,并没有考虑排序优劣.
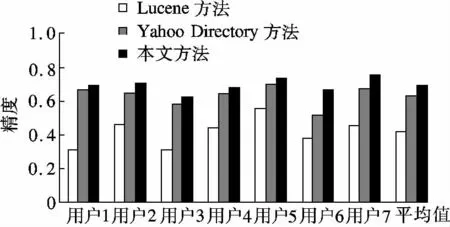
图1 3 种检索方式的检索精度对比
3.3.2 综合检索效果
表1为同一组查询下3 种检索方式的DCG 值对比结果.由表可知,本文方法在考验整体检索水平的DCG 指标上明显优于另外2 种,其均值较Lucene 方法和Yahoo Directory 方法分别高出52%和25%,比二者的平均水平高出36%.尤其是当关键词具有多义性或涉及不同领域时,这种优势更加明显.这表明得益于有效的语义分析工作,本文方法在应对语义模糊的查询时具有较高的辨识准确性.

表1 同一组查询下3 种检索方式的DCG 值对比
3.3.3 排序效果
由表2可以看出,本文方法的nDCG 指标几乎都保持在0.8 以上,且其均值较Lucene 方法和Yahoo Directory 方法分别高出了30%和10%,比二者的平均水平高出19%.这表明本文方法在排序稳定性和效果上都有较大提升.同样地,在进行多义性查询时,本文方法的优势更加明显.
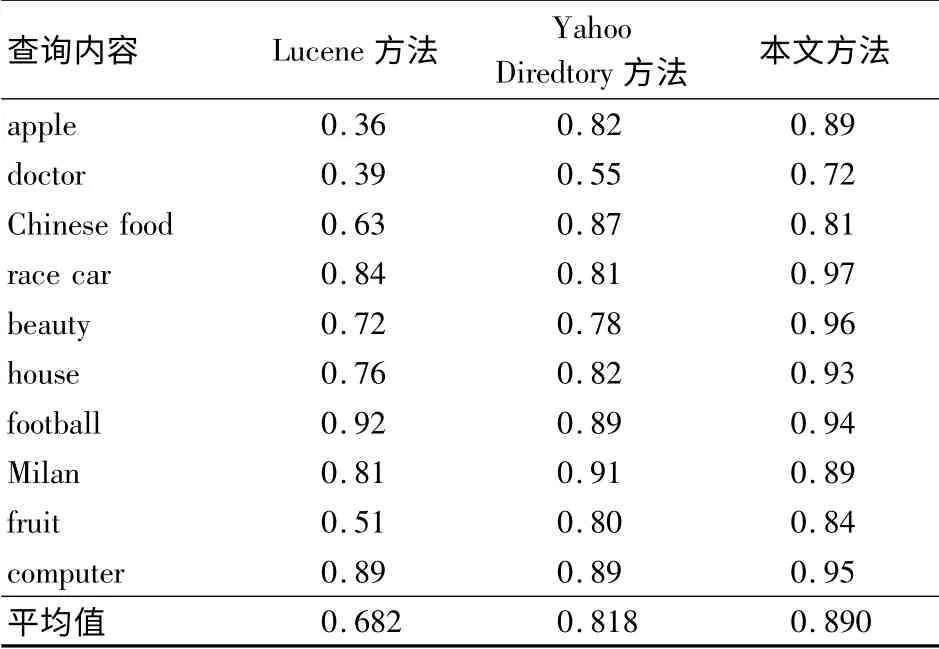
表2 同一组查询下3 种检索方式的nDCG 值对比
3.3.4 时间复杂度
由于进行了额外的优化工作,本文方法在时间消耗上必然会有一定程度上的增加.
实验分别采用Lucene 方法和本文方法,在2.0 GHz 主频、2 GB 内存的主机上进行了时间复杂度的评估.实验结果表明,本文方法的平均检索时间为0.669 s,较Lucene 方法仅增加了0.326 s,对用户的搜索体验几乎没有太大影响.
综上所述,结合4 个不同的评估指标来看,本文方法在整体检索效果上有着比较明显的优势,具有较高的实用价值.
4 结语
通过使用改进的多分类语义分析法给目标文档添加类别并建立词向量库,并结合以匹配思想为中心的个性化算法,能够在较少时间消耗的基础上提高检索效果.由于计算了词的概念信息,并把用户个人信息的权重加入考虑,本文方法在处理歧义查询时表现尤为优秀.但是,在特定情况下,本文方法存在检索效果提升不明显等问题.下一步研究旨在利用词向量库计算关键词之间的语义相似度,并据此返回语义更接近的文档的方法,以进一步提高语义检索的精度.
References)
[1]Liu F,Yu C.Personalized web search for improving retrieval effectiveness [J].IEEE Transactions on Knowledge and Data Engineering,2004,16(1):28-40.
[2]Wang T D,Deshpande A,Shneiderman B.A temporal pattern search algorithm for personal history event visualization[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(5):799-812.
[3]Pang M,Xu G.A personalized search engine research based on bloom filter mechatronic science[C]//Proceedings of 2011 IEEE International Conference on Mechatronic Science,Electric Engineering and Computer.Changchun,China,2011:2365-2366.
[4]Eberlein A.Calculating the strength of ties of a social network in a semantic search system using hidden Markov models [C]//Proceedings of 2011 IEEE International Conference on Systems,Man and Cybernetics.Anchorage,Alaska,USA,2011:2755-2760.
[5]Lai L F,Wu C C,Lin P Y.Developing a fuzzy search engine based on fuzzy ontology and semantic search[C]//Proceedings of 2011 IEEE International Conference on Fuzzy Systems.Taipei,China,2011:2684-2689.
[6]Singh R,Dhingra D A.A SCHISM—a web search engine using semantic taxonomy [J].IEEE Potentials,2010,29(5):36-40.
[7]Paltoglou G,Thelwall M.A study of information retrieval weighting schemes for sentiment analysis[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,Pennsylvania,USA,2010:1386-1395.
[8]Li Z X,Xiong Z Y.Fast text categorization using concise semantic analysis [J].Pattern Recognition Letters,2011,32(3):441-448.
[9]Imielinski T,Signorini A.If you ask nicely,I will answer:semantic search and today′s search engines[C]//Proceedings of 2009 IEEE International Conference on Semantic Computing.Berkeley,CA,USA,2009:184-191.
[10]Tamine-Lechani L,Boughanem M,Daoud M.Evaluation of contextual information retrieval effectiveness:overview of issues and research[J].Knowledge and Information Systems,2010,24(1):1-34.
