面向媒体处理可重构系统中数据缓存结构和缓存管理策略优化
2014-03-12杨苗苗
刘 波 肖 建 曹 鹏 杨苗苗
(东南大学国家专用集成电路系统工程技术研究中心,南京210096)
在媒体处理领域中,传统数字信号处理器DSP虽然具有很好的灵活性,但由于采用串行的指令流驱动模式,因此难以满足高性能的需求.专用集成电路ASIC 虽然具有较高的能量效率,但因其定制的功能特性难以满足层出不穷的应用需求.动态可重构计算架构由于兼具ASIC 的高性能和DSP 的高灵活性,作为一种新的计算模式被提出并得到广泛采用[1].
在可重构系统中设置和提供更多的计算资源通常很容易实现,但是只有为这些计算资源提供足够的数据存取带宽,最大化地利用可重构计算阵列提供的硬件计算资源,才能获得高的计算并行度以及能效比.因此如何设计数据缓存结构,为可重构计算阵列提供足够的数据流带宽,是可重构系统设计中必须考虑的关键问题之一.
基于参考像素的空间局部性同时沿着水平和垂直两个维度分布,文献[2-4]对传统Cache 的一维组织方式进行改进,设计出以二维形式组织的Cache.Chang 等[4]提出了一种基于2D Cache 的数据重用缓冲机制,增加了宏块间数据重用的功能,但色度和亮度数据存储在一个缓存中,会使得Tag比较电路开销增大并造成缓存冲突.Tsai 等[5]设计了一种参考帧数据和缓存块数据一一对应的2D Cache 机制,相对于传统的IWR 数据复用方案[6],带宽需求减少了46%.文献[3]设计的2D Cache架构与文献[2]相似,采用了VBSMC 机制[5,7],将数据带宽减少了41%,外部访问延迟减少了30%.但是文献[2-3]使用的方案地址映射设计复杂且采用简单的轮转替换策略.上述方法都取得了一定的效果,但是此类2D Cache 仍然使用传统的Cache 块作为2D 数据块的行,从本质上来说是以单个数据进行比较和缓存的[7].而媒体算法是以2D 方式访问数据的,若使用上述缓存方式,会使得数据访问效率不高.另外,Zatt 等[8]提出了一种3D Cache 结构,其本质是多块2D Cache 的拼接,不足之处在于Tag比较电路开销过大且缓存存储开销过高.
为了进一步减少面向媒体处理可重构系统中访存带宽的压力,本文将对上述诸多不足方面进行进一步改进.如将亮度和色度像素块分开存储以节省Tag 比较电路开销,采用更优的缓存替换策略和缓存结构,以提升可重构系统的访存性能.
1 系统总体架构
如图1所示,典型的可重构系统主要包含主控核(ARM7TDMI)、可重构处理单元RPU(reconfigurable processor unit)、重构控制单元μPU(microprocessor unit)、DMAC 以及存储访问接口EMI(external memory interface)等多个功能模块.其中,RPU 用于加速计算密集型任务;μPU 用来控制RPU 的功能重构.为了提高可重构处理器单元的数据访问效率,通常会在RPU 与外部存储器之间设置一块数据缓存结构(图1中2D Cache),通过预取和缓存片外数据,利用访存的局部性特征,降低数据访存的延时,提高可重构系统的工作性能.

图1 可重构系统总体架构
2 媒体算法片外数据访存分析
视频解码算法访问外存进行数据存取过程中存在大量的重复和冗余数据,其原因是:①运动补偿算法中由于宏块分割导致数据重复访问.运动补偿中,对于M ×N 的子块,最大需要(M +5)×(N+5)的参考帧数据与之对应[2].以宏块16 ×16、预测模式(1,3)为例,所需要参考帧的数据为441 字节;采用16 ×8 的分割方式,参考帧数据量为546字节,重复传输的数据是有用数据的1.24 倍;采用8 ×8 的分割方式,参考帧数据量为676 字节,重复传输的数据是有用数据的1.53 倍.②由于外部存储器的访问造成了数据冗余和重复.媒体处理数据都是按照像素访存(8 位)为单位进行的,而对片外存储器的访问通常是在32 位以上.这种非对齐的存储访问操作使得单次访存的冗余数据可能被再次读取,带来数据复用的可能.
外部存储器DDR SDRAM 由Bank,Page(页)和Column(列)3 个基本单元构成,这种行列组织特性使得访问不同行的存储单元时,由于需要进行预充电和激活的换行操作,导致性能降低[9].一般而言,媒体算法如H.264,MPEG-2,AVS 等,其图像是按帧为单位存放,每一帧图像按照光栅扫描方式存放在外部存储器中[10].由于媒体应用中,图像和视频的编解码都是基于宏块(MB)和块进行操作的[11-12],导致宏块中上、下两行数据在地址空间不连续,读取宏块时需多次换行;同时一个块内的所有数据都有相同的数据依赖关系,因此在处理一个宏块数据时,应保证访问该宏块数据时不被其他操作打断.
3 基于二维访问机制的数据缓存结构与替换策略
根据上述媒体算法数据访存特点及需求,针对大量重复使用和读取的数据,本文在可重构处理单元RPU 与外部存储器访问接口EMI 之间设计了一个片外数据缓存单元2D Cache,通过利用数据访存的局部性特征来减少可重构处理单元RPU 对外部数据的访问次数和外部带宽访问延迟.
3.1 2D Cache 结构
本文设计的数据缓存(2D Cache)结构如图2所示.该结构包含3 个数据缓存(Data Cache):亮度数据缓存、色度Cb 数据缓存、色度Cr 数据缓存,分别用于缓存一个宏块的亮度数据块、色度Cb数据块以及色度Cr 数据块,3 个缓存模块结构类似.每个数据缓存分别包括一个存储单元和一个数据访问控制单元.其中,存储单元包含前向预测数据缓存和后向预测数据缓存.对于B 帧来说,既有可能读取当前帧之前的帧图像数据(称为前向预测),也有可能读取当前帧之后的帧图像数据(称为后向预测).因此,此处设置了2 个缓存单元用来避免由于前向预测和后向预测访问不同帧图像引起的2D Cache 中数据的频繁替换.数据访问控制单元的作用包括:以二维数据块作为比较单位,当RPU 需要取数据时,先将要取的宏块地址信息与2D Cache 结构中宏块的地址信息进行比较(compare and select),如果命中,那么直接将该宏块的数据输出到RPU;否则,数据访问控制单元将针对二维数据块的不命中情况进行不同的处理.

图2 2D Cache 结构框图
3.2 2D Cache 结构的大小
为寻求性能提升与实现开销之间的最佳平衡点,需要评估Cache 结构的大小.需要考虑的2 个因素是:①Cache 行需要尽可能开发数据的空间局部性;②Cache 行容量是外存突发访问长度的整数倍.由于Cache 结构大小对于不同的算法标准(H.264,MPEG-2,AVS 等)差异不大,因此可以设置统一的参数.本文以{24 ×13,32 ×13,40 ×21,64 ×21,64 ×3}字节来分析亮度缓存的大小对于命中率的影响.以{16 ×5,16 ×9,16 ×10,24 ×9,32 ×13}字节来分析色度缓存的大小与命中的关系.为了选取最佳的缓存大小参数,需要通过命中率和收益率这2 个指标来评估Cache 的性能.命中率和收益率的定义如下:
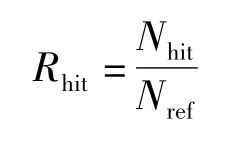

式中,Rhit表示Cache 的命中率;Nhit表示Cache 的命中次数;Nref表示RPU 读取参考帧的次数;Ropt表示收益率;Topt表示优化后数据存取的周期数;Tpre表示优化前数据存取的周期数.命中率Rhit代表了可重构处理单元RPU 读取参考帧数据时在Cache中的命中几率.收益率Ropt为采用本文设计的2D Cache 后,RPU 在解码一个宏块时访问参考帧数据平均所需花费的时间周期数占优化前时间周期数的比例,反映了优化后数据访问性能的提升率.
从图3可以看出(图中Airshow,Stockholm,Mobile 分别表示3 种不同的测试码流),Cache 越大,命中率越高,对于亮度和色度数据,从命中率来说,最佳尺寸分别为64 ×32,24 ×9 字节;但是考虑到Cache 的尺寸越大,当RPU 所需要的二维数据块不完全命中时,每次从外存访问的相应数据块的量就越大,换行次数就越多,进而导致访问外存延迟越大.因此为了寻求性能提升与实现开销之间的最佳平衡点,还要考虑2D Cache 尺寸不能过大的问题.由图3可看出亮度和色度的缓存大小对收益率的影响,当亮度和色度Cache 大小分别为64 ×21 字节和24 ×9 字节时,收益率最高.综合以上2种情况,本文选取64 ×21 字节的亮度Cache 大小以及24 ×9 字节的色度Cache 大小来作为最佳平衡点,此时Cache 不但大小合适,收益率最高,命中率也能高达80% ~90%,整体效能最佳.

图3 缓存大小对收益率和命中率的影响
3.3 2D Cache 结构的替换策略
当RPU 所需要的二维数据块不完全命中时,替换Cache 数据将影响对外访问的性能.针对参考块数据位置的不同设计了如下的替换策略:replace-flag 为替换标识,当不命中次数miss-number 达到M 时,令replace-flag 等于1,否则为0.当replace-flag 等于1 时,Cache 从片外读取数据进行替换更新.不命中次数的更新分以下2 种情况讨论:
1)当非完全命中的数据块为小块时(小于8 ×8字节),miss-number 加1.在媒体算法中,树状结构的运动补偿技术通过采用小块预测图像中的细节部分来实现.因此,当小块不命中时,图像细节部分的数据需要加载,并且由于空间局部性,一段时间内此细节部分周围数据都需要被加载.
2)当非完全命中的数据块为较大块,但其在Cache 中命中部分小于阈值Threshold 时,miss-number 加1;否则不变.如图4所示,MB1 完全命中,但是另外4 个数据块在Cache 中都不是完全命中,其中MB2,MB3,MB4 部分命中,MB5 完全不命中.对于MB2,MB3,非命中的数据是一个矩形块,需要向外部存储器发起一次访问.当处理MB2情况,需要考量命中部分是否达到阈值Threshold;而对MB3 情况,由于视频图像大多情况是水平方向向上的运动,所以令此情况下的Threshold 为0.MB4 与MB2,MB3 不同,如果要对剩余非命中部分数据进行读取,那么需要分2 次向外部存储器发起访问.这种情况造成访问次数的增多,并且数据块信息的计算复杂,反而导致访问延迟增大.因此针对此种情况,当数据块不是完全命中时,直接从外存访问相应的数据.

图4 二维数据块在Cache 中的不命中情况
当满足上述2 种情况时,不命中次数miss-number 便开始计数,只有当miss-number 计数到达M 次时,才更新replace-flag,继而替换整个Cache.如果不满足上述条件,那么对于没有命中的二维数据块,Cache 控制器直接从外部存储器中对其访问,而后发送给RPU,但是并不替换Cache 中的数据.以下为2D Cache 结构替换策略的伪码:

从图5中的实验数据得出,以码流Airshow 为例,当M=8,命中阈值为0.6 时,Cache 效率最高,能获得30%以上的性能收益.

图5 设计参数对收益率的影响
4 优化效果与对比
为了评估上文中提出的优化方法,本文将上述设计方案集成到一款可重构SoC 中,名为REMUS-Ⅱ(reconfigurable multimedia system version 2),目标应用包括H.264,MPEG-2 和AVS 等多种标准格式的视频解码.更进一步地,本文基于可重构系统REMUS-Ⅱ和TSMC65nm LP 工艺,设计实现了一款芯片RINOCEROS,如图6所示.

图6 RINOCEROS 版图
4.1 外部数据访问性能结果与分析
表1是采用本文所述数据缓存结构后,解码时平均访问一个宏块外部数据对应的时间.表中第3列和第4 列分别为平均访问一个宏块数据的总时间和访问参考帧数据的时间,第5 列为访存整体性能提升效果.
由表1可见,对于不同分辨率码流的解码,通过数据重用缓存优化参考帧数据访问时间后,REMUS-Ⅱ整体访存性能都有提升,幅度为29.16%~35.65%,性能平均提升率为31.73%.其次,从第3 列中平均访问一个宏块数据的总时间可以看到,对于所有码流,REMUS-Ⅱ都很好地满足实时解码1080p @30fps 时对访存数据的时间要求.

表1 优化后系统各码流访存性能提升效果
综上所述,通过采用基于二维访问机制的片外数据缓存来访问外部数据,最终使得系统性能提升,达到系统实时解码的性能要求.这是因为本文设计的数据缓存结构大量减少了访问冲突,减少了冲裁时间.同时本文通过增加参考帧数据在Cache中的命中率来减少对外部存储器的访问次数,不仅减少了外部存储器固有的发起延迟,并且减少了访问外部存储器时的换行时间,最终减少了对外部数据的访问延迟,提升了系统的整体性能.
与表2中的2D Cache 缓存结构[3]相比,本文所提出的缓存结构,其性能提升率要略高于前者,且数据缓存的存储开销仅为前者的44.4%.与3D Cache 缓存结构[8]相比,本文所提出的Cache 结构,虽然性能提升率略低于前者,但是存储开销仅为前者的8%.
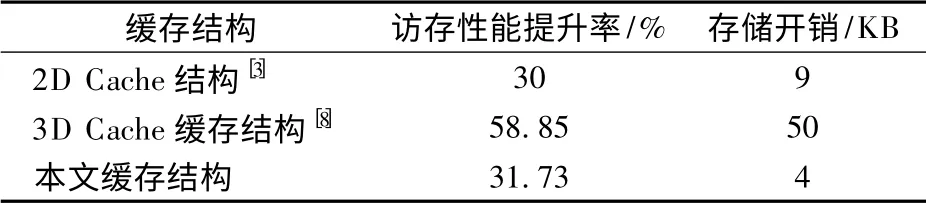
表2 访存性能及存储开销对比
4.2 可重构系统整体验证结果与对比
表3比较了REMUS-Ⅱ与国际上2 款主流可重构系统XPP 和ADRES 的性能.以H.264 解码为例,XPP 在450 MHz 主频下实现了Main Profile 1080p@24fps 的实时解码,ADRES 在200 MHz 主频下达到了Base Profile 720p@30fps 的实时解码,REMUS-Ⅱ在主频200 MHz 下,可以满足更高的High Profile 1080p@30fps 解码要求.表3中还将性能进行归一化为执行单个宏块的性能,即单位频率下每秒可解码宏块的个数.REMUS-Ⅱ单位频率单位时间内可解码的宏块个数为1 224,相对于ADRES 和XPP,REMUS-Ⅱ分别获得8.1 倍和1.8倍的加速比.

表3 与国际同类可重构系统的比较
5 结语
本文提出的基于二维访问机制的数据缓存结构与替换策略,对于不同标准的媒体处理算法都能获得较好的优化效果,使得可重构系统的访存提升了29.16% ~35.65%,在有效控制硬件存储开销的同时,获得相对较高的访存性能提升率.
References)
[1] Cervero T,Lopez S,Callico G M,et al.Survey of reconfigurable architectures for multimedia applications[C]//VLSI Circuits and Systems IV.Dresden,Germany,2009,736303-01-736303-12.
[2] Chuang T D,Chang L M,Chiu T W,et al.Bandwidthefficient cache-based motion compensation architecture with dram-friendly data access control[C]//IEEE International Conference on Acoustics,Speech,and Signal Processing.Taipei,China,2009:2009-2012.
[3] Chuang T D,Tsung P K,Lin P C,et al.A 59.5 mW scalable/multi-view video decoder chip for quad/3D full HDTV and video streaming applications[C]//2010 IEEE International Solid-State Circuits Conference.San Francisco,CA,USA,2010:330-331.
[4] Chang Y N,Tong T C.An efficient design of H.264 interpolator with bandwidth optimization[J].Signal Processing Systems,2008,53(3):435-448.
[5] Tsai C Y,Chen T C,Chen T W,et al.Bandwidth optimized motion compensation hardware design for H.264/AVC HDTV decoder[C]//48th Midwest Symposium on Circuits and Systems.Covington,KY,USA,2005:1199-1202.
[6] Chien Chih-Da,Lin Chien-Chang,Shih Yi-Hung,et al.A 252kgate/71mW multi-standard multi-channel video decoder for high definition video applicatioins[C]//ISSCC Dig Tech Papers.San Francisco,CA,USA,2007:282-283.
[7] Cucchiara Rita,Piccardi Massimo,Prati Andrea.Exploiting cache in multimedia[C]//IEEE Conference on Multimedia Computing and Systems.Florence,Italy,1999,1:345-350.
[8] Zatt B,de L Silva L M,Azevedo A,et al.A reduced memory bandwidth and high throughput HDTV motion compensation decoder for H.264/AVC high 4 ∶ 2 ∶ 2 profile[J].Journal of Real-Time Image Processing,2013,8(1):127-140.
[9] Whitty S,Ernst R.A bandwidth optimized SDRAM controller for the MORPHEUS reconfigurable architecture[C]//IEEE International Symposium on Parallel and Distributed Processing.Miami,FL,USA,2008:1-8.
[10] Probell J.Architecture considerations for multi-format programmable video processors[J].Journal of Signal Processing Systems,2008,50(1):33-39.
[11] Wiegand T.Draft ITU-T recommendation and final draft international standard of joint video specification[J].ITU-T rec.H.264 | ISO/IEC 14496-10 AVC,2003,26(2):167-184.
[12] ITU-T.ISO/IEC-13818 Generic coding of moving pictures and associated audio(MPEG-2)[J].Journal of the Audio Engineering Society (AES),1994,42(10):780-792.
[13] Ganesan M K A,Singh S,May F,et al.H.264 decoder at HD resolution on a coarse grain dynamically reconfigurable architecture[C]//International Conference on Field Programmable Logic and Applications.Amsterdam,Netherlands,2007:467-471.
[14] Mei B,de Sutter B,Vander Aa T,et al.Implementation of a coarse-grained reconfigurable media processor for AVC decoder[J].Journal of Signal Processing Systems,2008,51(3):225-243.
