基于Apriori算法的数据挖掘算法研究
2014-03-05李晋芳
李晋芳
(晋城广播电视大学,山西晋城 048026)
一、引言
关联规则挖掘是一项最有影响的数据挖掘技术,尤其在针对交易数据的分析上,更是发挥了重要的作用。关联规则广泛应用在各个领域中,除了电信网络、商品市场、电子商务风险管理及库存控制之外,也涉及到商业情报和市场营销领域。关联规则挖掘技术的重点就在于频繁项目集的挖掘。经过大量文献的调查显示,关联规则挖掘中要花费巨大的处理时间去计算发现频繁项目集。我们注意到,大部分的算法发现频繁模式需要多次遍历数据库,导致大量的磁盘读取,造成了巨大的I/O负载。Apriori算法是关联规则挖掘的经典算法,它采用自下而上的方式,搜索枚举出所有的频繁项集。本文提出的Apriori算法的改进版本,则采用自上而下的方式,避免生成不必要的模式规则,从而大大减少了数据库扫描的次数。
二、相关工作
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。其中最有名的、最流行的数据挖掘技术是关联规则和频繁项集挖掘算法。该算法最初是由Agrawal等人提出的购物篮分析。由于该算法显著的实用性,关联规则挖掘已成为大家都热衷于研究的课题。
继Apriori算法之后,不同的学者针对此算法的弱点提出了很多种改进算法,其中J.Han等提出了不产生候选挖掘频繁项集的方法—FP-树频集算法。此算法采用分而治之的策略,在经过第一遍扫描之后,把数据库中的频集压缩进一棵频繁模式树(FP-tree),同时依然保留其中的关联信息,随后再将FP-tree分化成一些条件库,每个库和一个长度为1的频集相关,然后再对这些条件库分别进行挖掘。当原始数据量很大的时候,也可以结合划分的方法,使得一个FP-tree可以放入主存中。实验表明,FP-growth对不同长度的规则都有很好的适应性,同时在效率上较之Apriori算法有巨大的提高。它是关联规则挖掘发展的又一个里程碑。
尽管FP树算法对Apriori算法进行了改进,但它仍然继承了Apriori算法扫描多遍数据库的缺点。需要注意的是,为了减少数据库扫描的次数,同时用较少的执行速度,以减少内存空间,就导致了需要进行大量的磁盘读取工作,由此给I/O子系统造成了巨大的负担。这些相关问题促使我们继续进行这方面的研究工作。由此,我们提出了一种新的改进的Apriori算法,从而减少了程序运行的时间和空间。
三、频繁项集和关联规则
设I={i1,i2…,in}为所有项目的集合,设A是一个由项目构成的集合,称为项集。事务T是一个项目子集,每一个事务具有唯一的事务标识Tid。事务T包含项集A,当且仅当AT。如果项集A中包含k个项目,则称其为k项集。S为事务数据库,项集A在事务数据库S中出现的次数占S中总事务的百分比叫做项集的支持度(support)。如果项集的支持度超过用户给定的最小支持度阈值,就称该项集是频繁项集。
Apriori算法用来进行频繁项集的挖掘,算法中关联规则的发现分解成两个步骤:
1、查找所有大项集(一个大项目集是一组超过最小支持度的项目)。
2、从大项目集中生成关联规则。
只有同时满足最小支持度和最小置信度阈值的项目才会被关联规则考虑。
四、提出的工作
现在有许多算法通过访问路径来生成频繁访问模式。但他们在执行时间和内存需求方面的效率较低。本文提出的算法是FP-树算法的改进版本,该算法不会使用递归来生成频繁模式。它保持了数据库的频繁模式树,这是一个扩展的前缀树结构,其中存储了频繁模式关键的信息。该算法不同于FP-树算法,它不使用递归。该算法在扫描一次数据库的基础上生成一个页表,该表存储了一些相关信息,有关用户访问网页的次数和存储该网页模式树的指针字段。页表节点根据页数进行排序。树节点就是频繁项目。页表节点用于生成频繁访问模式。从存储树节点的页表seqptr开始,然后从底部到根节点来遍历整个树。在遍历时,若满足条件总页数>min_sup则将此节点添加到频繁树中。如果不满足这个条件,则将其移到树的下一个路径中。最终,利用反向遍历树来为用户生成所有的频繁模式。
该算法分为两步:
步骤1:根据来自用户文件中的访问路径来构建频繁访问模式树,并记录每个页面的访问次数。



该算法的第一步和FP树算法一样,但在第二步算法中采用向后遍历来寻找频繁访问模式,因此,遍历这些树的执行时间就会减少。
五、运算结果
该算法使用的是AMD处理器,主内存256 MB,虚拟内存756 MB,本地磁盘空间40 GB操作系统是微软的Windows XP。该算法采用的是JAVA1.4.2实现的。
下图显示了比较结果。
比较1:Apriori算法和改进算法时间结果比较

图1 Apriori算法和改进算法时间结果的比较
比较2:Apriori算法和改进算法内存使用情况的比较
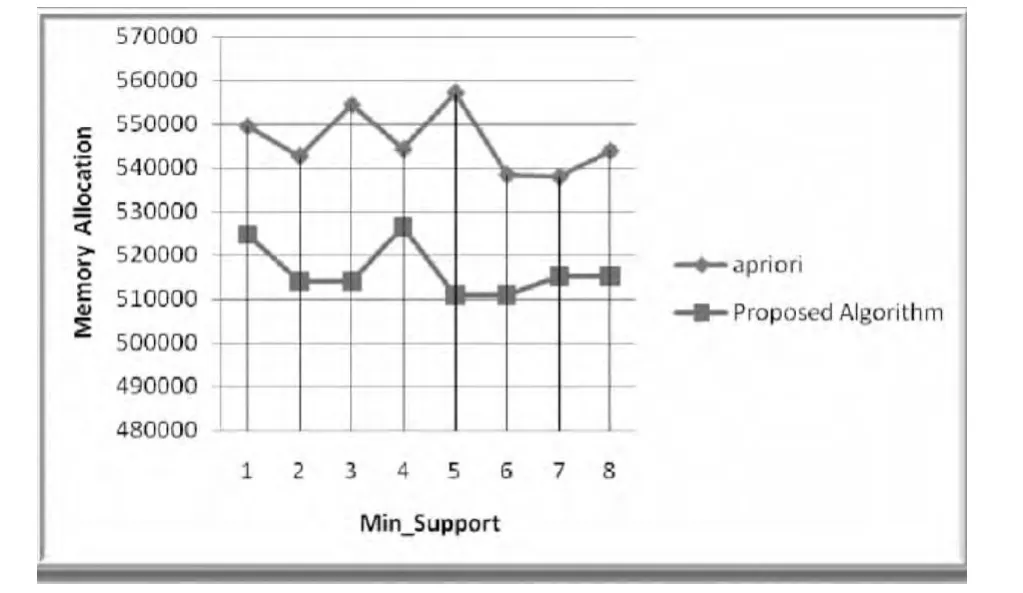
图2 Apriori算法和改进算法内存使用情况的比较
六、结论
本文基于Apriori算法的缺点,开发了一个改进的版本,此算法是采用无候选集来生成频繁模式的方法,不需要使用递归来生成频繁模式,采用自上而下的方式,避免生成不必要的模式规则,从而大大减少了数据库扫描的次数,以此来提高程序运行的时间和空间。
[1]岳鹏宇.Apriori算法的探讨[J].山西经济管理干部学院学报,2012(4).
[2]丁一琦.基于Apriori算法的数据挖掘技术研究[J].现代计算机,2012(36).
[3]张琪.基于 Apriori算法的数据挖掘系统设计[J].计算机光盘软件与应用,2013(15).
