基于多层协同纠错的中文层次句法分析
2014-02-28蒋志鹏董喜双
蒋志鹏,关 毅,董喜双
(哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
1 引言
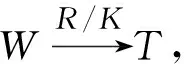
层次句法分析是一种典型的自底向上分析方法,其优点是时空开销小、易于实现,但是错误累积问题严重[2]。Abney[3]早在1991年就提出了组块的概念,并将其应用到句法分析中,成为层次句法分析的先驱。Ramshaw[4]等人在组块分析中加入{B,I,O}标记,将组块分析转化成序列化标注问题,利用基于转换的机器学习方法进行组块分析,间接推动了层次句法分析的发展。1999年,Ratnaparkhi[5]设计了基于最大熵模型的句法分析器,该方法结合组块分析的策略,将句法分析过程划分为词性标注、组块分析、句法树构建及核对4个阶段,通过最大熵模型预测每次执行的动作(移近/规约),这种方法的准确率接近当时的最好水平(Collins,1997),为层次句法分析奠定了基础。Sagae[6]利用自底向上移进归约的方式进行句法分析,该算法的特点是运行速度快,实现简单,并且能同时得到依存树结构。在中文句法分析方面,Fung[7]首次将最大熵模型应用于中文句法分析中,在Ratnaparkhi[5]的基础上加入中文分词,实现了基于字的统计句法分析器。Wang[8]将Sagae[6]的模型应用到中文句法分析中,并在预测时选择多种分类器中的最优结果,该模型在保证较高F1值的同时,获得了更快的解析速度。李军辉[9]以Ratnaparkhi[5]为基础,将组块分析过程分解为基本块分析和复杂块分析,并通过引入产生式右侧分值进一步提高句法分析的性能,该模型在宾州中文树库(CTB2.0)上的F1值为77.4%,达到了当时的最好水平。2010年,Zhou[10]采用分治策略进行句法分析。该方法将句子转化为两个部分:最长名词短语及用中心词代替最长名词短语后的新句子。首先利用Berkeley句法分析器识别出输入句子中的最长名词短语,对于新句子利用链式CRF模型进行组块分析,再以搜索的策略进行解码,最后将解析后的两部分合并成一个完整的句法树。该方法在CLP2010的完全句法分析评测中F1值为74.8%,只比当时最好的结果(Berkeley Parser)低了0.36%。
近几年,传统句法分析的研究进入瓶颈期,句法纠错技术成为提高现有句法分析水平的关键。句法纠错技术可以分为限定类型纠错和不限类型纠错。不限类型纠错的研究主要集中在句法树重排序方面,Collins[11]利用基于历史模型的句法分析器产生一个候选句法树列表,通过引入额外特征对句法树进行重排序,使得句法分析的错误率降低了13%,但该方法受列表规模的限制,排除了一些有潜质的候选结果。针对此缺点,Huang[12]提出了森林重排序方法,该方法首先生成一个句法森林,然后自底向上地为每个结点生成候选子树列表,最终选择根节点上评分最高的句法树。王志国[13]以森林重排序为基础,引入高阶词汇依存特征进行重排序, F1值达到85.74%,是目前CTB上最好的结果;限定类型纠错一般针对句法树中某一种或几种结点标记进行纠错,英文方面,介词结构附加问题(PP Attachment)一直是句法纠错的热点问题,常用的纠错方法包括:单独设计特征模板[14]、引入语义信息[15]、统计搭配模式[16]等。中文方面,王锦[17]归纳出7种歧义模式,通过引入语义知识和搭配知识分别进行消歧,是中文上鲜有的限定类型纠错研究,缺点是过分依赖外部资源。综上所述,常见的句法纠错研究一般基于概率上下文无关文法(PCFG),通过引入额外的特征或资源,单独训练模型进行纠错,目前还没有针对层次句法分析框架的纠错研究。本文以CLP2010评测任务2*http://www.cipsc.org.cn/clp2010/task2_en.htm中最优的层次句法分析系统[10]作为实验基线,在保留原有系统分层思想及压缩方式的基础上,结合层次框架的特殊性,提出了多层协同纠错算法,在不引入任何外部资源及训练新模型的情况下,使得该系统在中文句法分析上的效果达到了较高的水平。
2 基于多层协同纠错的句法分析
2.1 系统框架
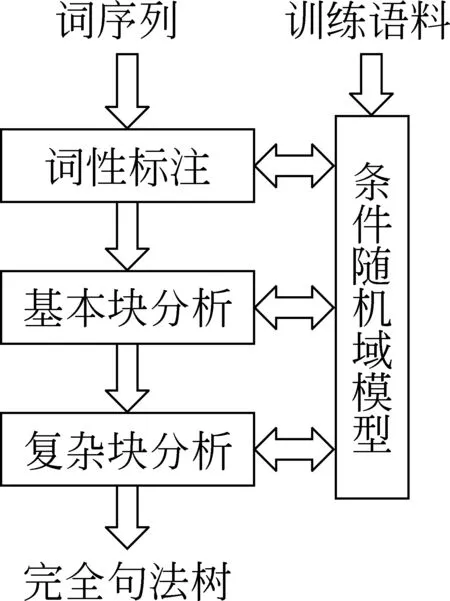
图1 层次句法分析 系统框架
由于国内外的许多句法分析工作都是在自动词性标注基础上进行的[2,8-10],词性标注结果直接影响句法分析的精度,所以我们将词性标注作为系统框架的重要组成部分。在句法分析阶段,我们比较了李军辉[9]和Zhou[10]的不同分层方式,将句法分析细分为基本块分析和复杂块分析,分别采用不同的特征模板识别非递归组块和递归组块,这里我们将非递归组块定义为不包含任何组块的组块,递归组块定义为包含组块的组块,例如,“[pp 用/p 火/n ]”和“[vp 熟/v 食/n]”均为非递归组块,“[vp [pp 用/p 火/n ] [vp 熟/v 食/n] ]”为递归组块。系统以正确分词的句子作为输入,依次经过词性标注、基本块分析,识别出非递归组块,再循环调用复杂块分析,识别出递归组块,最终输出一个句法树。系统整体框架如图1所示。
2.2 基于条件随机域(CRF)的词性标注
在词性标注方面,我们以Yang[18]在CIPS-ParsEval-2009中的特征模板作为实验基线。直接在语料(语料划分见3.1节)上进行测试,词性标注准确率为93.52%。通过对标注结果进行错误分析,我们发现(1)某些专有名词的字数存在一定的规律性,例如,标注为指人专名(nP)多数为二字词或三字词;(2)某些词的词性之间存在一定的搭配关系,例如,数词与量词经常同时出现;(3) 地点专名(nS)和组织机构名(nO)的构词方式存在一定的特点,例如,地点专名以“省”、“市”等结尾。因此,我们在基线特征模板中引入字数、前一词的词性作为特征,并针对CRF打分低于0.4的结果利用规则辅助判定,即判断是否符合某些构词规律,经过改进后的词性标注准确率达到了95.39%。例如,直接利用CRF标注“光明乡”词性时,识别成名词(n)的概率最高,在进行后处理时,发现该词匹配“字数:3,尾字:乡”的规则,于是该词词性变为地点专名(nS)。调整后的特征模板如表1所示,训练数据的格式如表2所示,其中w0表示当前词,pre为当前词的第一个字,suf为当前词的最后一个字,num为当前词的字数,pos-1表示前一词的词性。

表1 词性标注特征
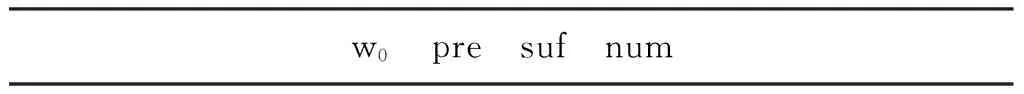
表2 训练数据格式
2.3 层次句法分析实验基线
本文将Zhou[10]在CLP2010评测任务2中的句法分析系统作为实验基线,使用基本块识别模块替换原系统中的最长名词短语识别模块,采用多层组块分析的方式自底向上进行句法分析。
在基本块分析阶段,我们使用实验室已有的浅层句法分析系统,该系统以传统的{B, I, O}方式[4]结合MEM识别基本块,在CIPS-ParsEval-2009评测任务2汉语基本块分析中获得第一名的成绩。由于我们使用的语料不需要标注基本块的关系信息,所以本阶段我们只保留基本块的边界和成分信息。基本块分析的处理流程如下:
第一步,输入经过词性标注的句子,使用MEM进行预测:
药物/n@np-B 的/uJDE@np-I 发现/vN@np-E 与/p@O 原始人/n@np-B 的/uJDE@np-I 采集/vN@np-E
第二步,合并预测结果,形成非递归组块:
[np 药物/n 的/uJDE 发现/vN] 与/p [np 原始人/n 的/uJDE 采集/vN ]
在复杂块分析阶段,以经过词性标注和基本块分析的句子作为输入,使用CRF递归地进行复杂块识别,直到识别出根结点,其中结点的类别标记包括xx_Start, xx_Middle, xx_End,分别表示xx块的开始结点、中间结点和结束结点,xx_Single表示结点单独成xx块,Other表示不成块结点。复杂块分析类似于递归地进行基本块分析,除了标记和模板不同之外,在选择合并方式时,考虑到所用语料没有标注中心词,如果仅靠规则提取中心词会引入额外的错误,于是我们每层压缩句子时,以首尾词的形式替换原组块,例如,
第一步,输入经过组块分析的句子:
[np 药物/n 的/uJDE 发现/vN] 与/p [np 原始人/n 的/uJDE 采集/vN ]
第二步,保留组块首尾词并压缩句子:
[np 药物/n 发现/vN] 与/p [np 原始人/n 采集/vN]
第三步,使用CRF进行预测:
[np 药物/n 发现/vN]@np_Start 与/p@np_ Middle [np 原始人/n 采集/vN] @np_End
……
重复上述步骤直到识别出根结点。
本文选择开源的CRF++*http://crfpp.googlecode.com/svn/trunk/doc/index.html作为标注工具。由于CRF++只能进行单层标注,本文增加了后处理模块,功能包括: 组块合并、输出输入格式转换、识别根结点,使其能够递归地进行序列化标注;另外,CRF++训练时将所有的信息都保留在内存中,直到训练结束再全部写入模型,这样增加了训练模型的内存消耗,本文将数据分两次写入模型,即先将特征表达式相关信息存入模型,一定程度上降低了训练时的内存使用。
2.4 基于多层协同纠错的层次句法分析方法
由于层次框架下每层只输出一个确定性结果,导致标注歧义带来的错误累积严重。本文提出了多层协同纠错算法,有效减少了数据传递单一性带来的错误累积。
CRF预测过程就是对待标记数据的特征函数进行线性求和,以确定在该上下文环境中分类的概率,即对预测结果进行打分*本文所使用的CRF预测分数均为经过归一化的结果,归一化方法见文献[19],这里不再赘述。。通常来说,预测分数越高,获得正确结果的可能性越大,但是由于概率本身具有不确定性,分数最高的结果不一定是正确结果。本文设计算法的初衷就是为了纠正那些预测分数最高的错误结果,不同于仅保留单一结果的传统方式,本算法将分数最高及次高的结果传入下一层,通过对两层分数进行线性插值,最终确定全局最优的标注结果。算法分为确定候选错误及多层协同纠错两步进行。
1. 确定候选错误
本文没有采用传统的歧义界定方式[19]预判错误,而是提出了一种简单可行的方法,将预测分数没有“明显差异”的情况均视为可能存在错误,“差异”形式化定义如式(1)所示。
这里,pre1和pren分别表示CRF预测分数排序第1位及第n位结果。为了确定diff最合适的阈值,我们在3.1节提到的调试集上进行实验,计算前两个分数差大于某一阈值时的错误数量,结果如图2所示,图中纵坐标表示调试集中错误标记的个数,横坐标表示diff的取值。
从曲线整体趋势看,错误数量随diff阈值增大而减少,而且当阈值大于0.5时曲线下降较明显,在调试集上进行纠错实验也证明了当diff阈值取0.5时效果最好。
2. 多层协同纠错
在层次框架下,父序列的上下文环境对子序列是不可见的,损失的正是对纠错有益的父序列特征,本文希望将候选错误带入父序列的上下文环境中,通过引入父序列的特征进行纠错。另一方面,由于CRF对于父子序列的预测可在同一模型下进行,为了避免重复计算,本文并没有训练新的模型,而是采用线性求和的方式获得最终概率。
本文首先提出了基于整体预测分数的多层协同纠错算法,该算法的核心思想是每层输出多个标注序列,分别进入下一层产生各自父序列,将子序列与其父序列的整体预测分数进行加权求和,最终确定本层的标注序列。整体纠错分数计算如式(2)所示,S为本层序列预测分数,S′为父序列预测分数,α、β为调节参数。

图3 父子序列关系表示
算法1基于整体预测分数的多层协同纠错算法
步骤1 输入待标记序列L到CRF++,如果L为根结点则算法终止,否则保存预测结果为多个<序列,分数>对, 如
整体预测分数虽然能说明标注序列正确的可能性,但是算法1将其作为纠错的标准,容易引入非歧义项的干扰,增加了造成误判的几率。于是我们提出了一种更加具有针对性的纠错算法-基于局部预测分数的多层协同纠错算法,该算法与算法1最大的不同在于,歧义项从序列变成了结点,即跟踪本层歧义结点进入下一层产生父结点,将该结点与其父结点的预测分数进行加权求和,最终确定本层的标注结果。在计算局部纠错分数时,式(2)中的S和S′分别表示歧义结点和其父结点的预测分数。
算法2基于局部预测分数的多层协同纠错算法
步骤1 输入待标记序列L到CRF++,如果L为根结点则算法终止,否则保存预测结果为多个<序列,分数>对,如
步骤2 取分数最高的前两个序列L0和L1,依次计算各标注结点分数差sn=s0n-s1n,若各标注结点分数差均大于diff,则直接合并L0为待标记序列(见2.3节)返回步骤1;否则进入步骤3;
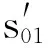
与算法1相比,算法2仅增加了计算标注结点分数差的过程,并且获得了更好的纠错效果(实验结果见3.2节)。在时间复杂度方面,该算法的时间复杂度可以分为两部分计算,其中,CRF++进行单层标注的时间复杂度为O(T2n),T为所有候选标记个数,n为句子中的词数,当最坏情况下每次都执行步骤3,标注时间复杂度变为O(2T2n),而计算标注结点分数差及合并标注序列的操作都是线性时间的O(n),算法2整体时间复杂度为O((2T2+3)n),另外,由于每句至多分析n层,所以系统最终的时间复杂度为O((2T2+3)n2),要优于线图分析法的O(n3)。
下面本文将介绍纠错算法在实例中的应用。以句子“即/v 对/p 档案/n 实体/n 管理/vN 系统/n 、/wD 档案/n 信息/n 开发/vN 系统/n 及/cC 其/rN 反馈/vN 系统/n 整个/b 过程/n 的/uJDE 研究/vN 。/wE ”的部分句法树为例,其中图4为未加入纠错算法的部分句法树,图5为应用算法2纠错后的部分句法树,图中框内为产生歧义的子树。在进行第二层组块分析时,“[np 档案/n 信息/n]”识别为Other分数为0.518,识别为np_Start分数为0.395,其差值0.123是该层最小差并小于阈值0.5,则被认定为存在歧义,在分别合并两种结果进入第三层后,获得各自父结点的分数为0.508和0.624,线性插值后的最终分数为0.511和0.555,所以“[np 档案/n 信息/n]”在第二层的标记选择np_Start,纠正了底层组块的标注错误,部分句法树从图4的形式转换成图5的形式。
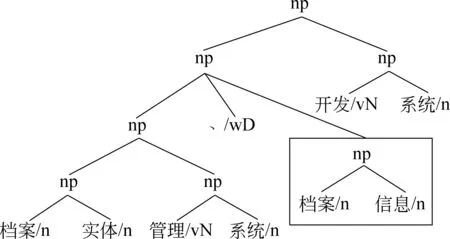
图4 未加入纠错算法的部分句法树

图5 应用算法2纠错后的部分句法树
3 实验及分析
3.1 实验设置
为了方便与基线比较并确定系统参数,我们使用CLP2010任务2-2训练语料进行训练和测试,对该语料按每5句进行一次划分,前4句形成14 023句的训练集,对后1句形成的语料集进一步划分,其中前1 752句作为调试集,后1 753句作为测试集。在结果评价方面,我们采用传统的准确率、召回率及F1值作为评价标准,以常用的Evalb*http://nlp.cs.nyu.edu/evalb/作为评价工具,其中:
3.2 实验结果及分析
为了确定纠错算法的最优参数,我们在调试语料上设置不同的α和β值,实验结果如图6所示,在不同参数下系统F1值呈凸曲线走势,当α=0.75,β=0.25时达到最高点说明纠错算法以父结点为主、子结点起适度辅助作用时效果最好。
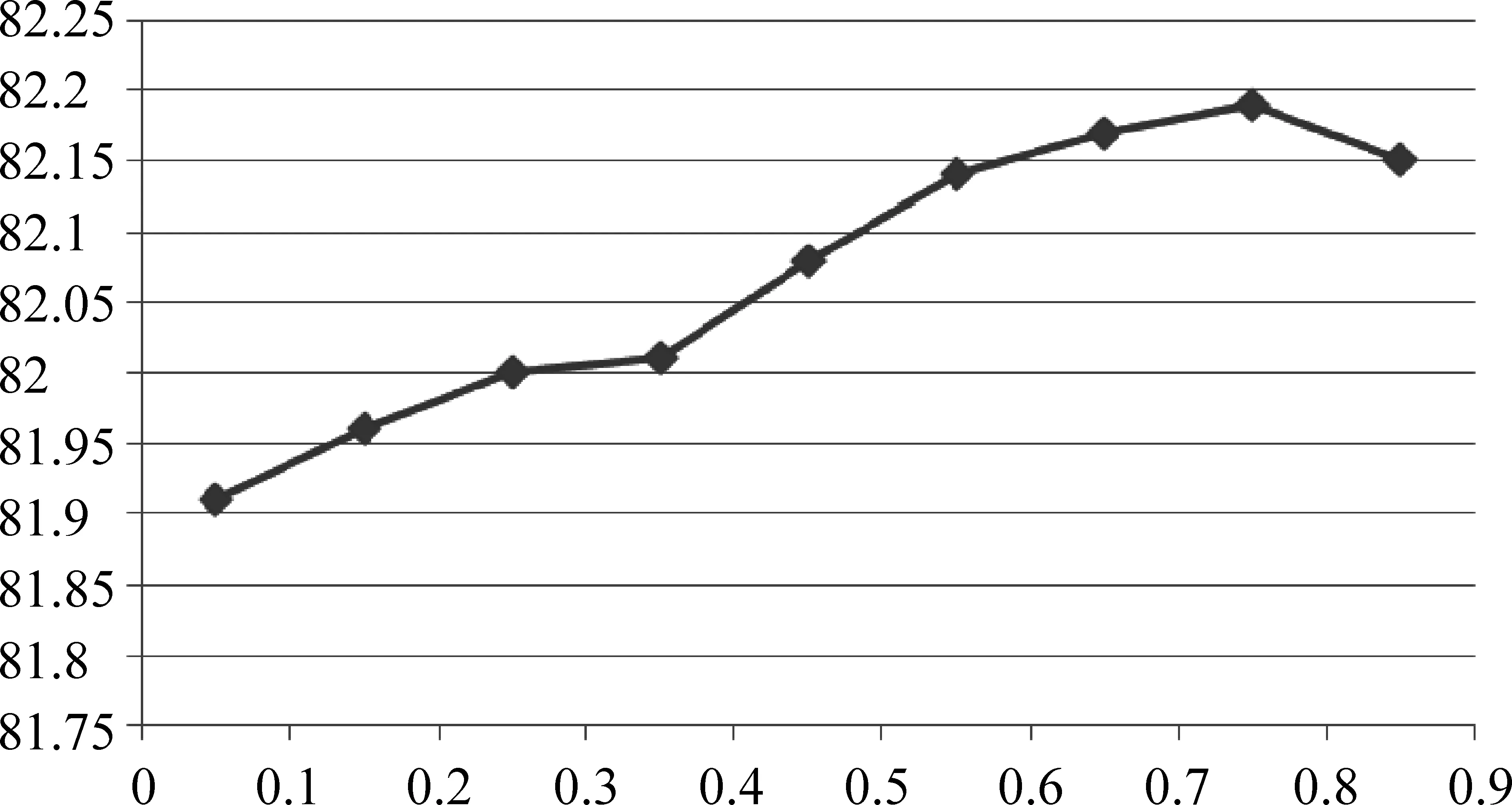
图6 α不同取值下的系统F1值分布
表3为完整测试语料上的实验结果,以Berkeley parser作为比较对象。Berkeley parser利用基于层次状态分裂的PCFG进行无词汇化句法分析,是目前中文上最好的开源句法分析器[20]。但是由于其自身的鲁棒性问题,在3.1节的测试语料上部分句子会出现错误输出,包括空输出及破折号错误等,F1值仅为76.26%,而本文加入算法2的系统(CLP-2)能够正常运行,F1达到80.34%。另外,从测试时间上可以看出,本文的方法比Berkeley parser节省了近1/3的时间。
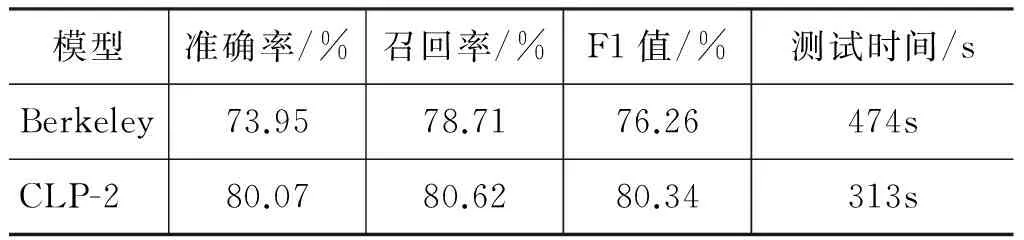
表3 完整语料实验结果
为了使对比结果更具说服力,我们将出现错误的测试句子删除,保留剩余的1 622句语料重新测试(Berkeley parser成功分析所有语料)。表4给出了在削减后语料上加入不同纠错算法后的实验结果,其中CLP-0表示基线结果,CLP-1和CLP-2分别表示新系统加入算法1和算法2后的结果。为了扩大纠错规模,本文实现了CLP-3算法,该算法不是仅仅对CRF中的1-Best结果纠错,而是每层保留N-Best组块进入下一层(CRF预测分数大于0.5的组块),与各自父组块的分数进行线性求和,最终选择分数最高的组合方式。另外,本文在纠错算法中加入Berkeley的结果进行过滤,实验证明这种简单的模型融合能够进一步提高解析精度,F1值超过了单独使用Berkeley parser。
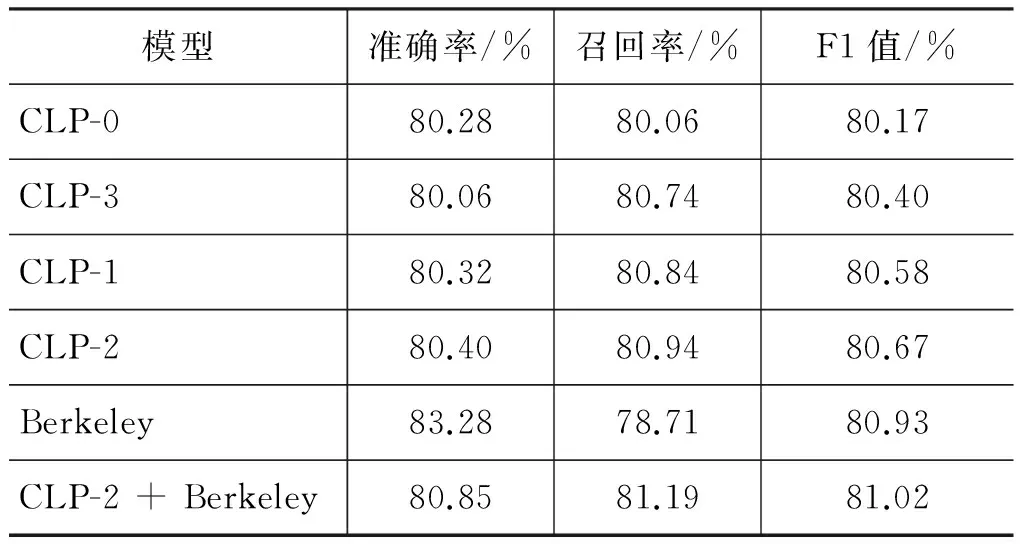
表4 削减后语料实验结果
本文使用的CLP2010评测语料来自清华中文树库(TCT ver1.0),无论训练还是测试语料规模都要大于公认的宾州中文树库语料(CTB 2.0),实验结果具有较高的可信度。从实验结果可以看出,CLP-1和CLP-2的效果要优于CLP-0,证明这两种纠错算法在层次系统中是有效的,并且局部预测分数具有更好的纠错能力。通过对CLP-3的结果进行分析,我们发现N-Best的约束条件(例如,候选组块个数及分数阈值)难以确定,很可能引入额外的错误组块,导致纠错结果并不十分理想。
4 结论与展望
本文在层次句法分析的框架下,比较了不同分层方式、模型选择及句子压缩方式对句法分析结果的影响,确定了最适合层次句法分析的系统架构,并针对该框架错误累积问题,提出了一种多层协同判定的纠错算法,在损失较少解析效率的同时,提高了层间标注结果的正确性,使得层次句法分析准确率和召回率分别达到了80.40%和80.94%,成为一种兼具较高解析速度及精度的句法分析方法。
由于本文只是初步实现了该纠错算法,每次只是处理层间概率差最小的候选结果,我们在下一步的研究中将扩展该算法,探索N-Best的约束条件,在保证纠错精度的同时提高纠错召回率。另外,我们还会深入研究错误结果的预判工作,排除引入深层次信息后带来的非歧义干扰,进一步提高算法纠错准确率。
致谢感谢沈阳航空航天大学的周俏丽老师给予的宝贵意见,并提供特征模板作为实验基线,为我们的实验带来了很大帮助;感谢苏州大学的周国栋老师在中文层次句法分析方面的基础性研究,感谢实验室各位同学对本文工作的支持。
[1] 刘挺, 马金山. 汉语自动句法分析的理论与方法[J]. 当代语言学, 2009,11(2): 100-112.
[2] 孟遥,李生,赵铁军, 等.四种基本统计句法分析模型在汉语句法分析中的性能比较[J]. 中文信息学报, 2003, 17 (3): 1-8.
[3] S Abney. Parsing by Chunks [J]. Principle-Based Parsing, 1991: 257-278.
[4] Lance A Ramshaw, Mitchell P Marcus. Text Chunking Using Transformation-Based Learning[C]//Proceedings of the Third ACL Workshop on Very Large Corpora, 1995: 87-88.
[5] Adwait Ratnaparkhi. Learning to Parse Natural Language with Maximum Entropy Models [J]. Machine Learning, 1999, 34(1-3): 151-175.
[6] K Sagae, A Lavie. A classifier-based parser with linear run-time complexity[C]//Proceedings of the IWPT’05, 2005: 125-132.
[7] Pascale Fung, Grace Ngai, YongSheng Yang, and BenFeng Chen. A Maximum-Entropy Chinese Parser Augmented by Transformation-Based Learning[C]//Proceedings of the ACM Transactions on Asian Language Information Processing, 2004: 4-8.
[8] Mengqiu Wang,Kenji Sagae,and Teruko Mitamura. A fast, accurate deterministic parser for Chinese[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, 2006: 425-432.
[9] 李军辉, 周国栋, 朱巧明, 等. 一种改进的中文层次句法分析模型研究[C]//第十届全国计算语言学学术会议, 2009: 123-129.
[10] Qiaoli Zhou, Wenjing Lang, Yingying Wang, Yan Wang, and Dongfeng Cai. The SAU Report for the 1st CIPS-SIGHAN-ParsEval-2010[C]//Proceedings of CIPS-SIGHAN Joint Conference on Chinese Language Processing (CLP2010), 2010: 304-311.
[11] Collins M, Koo T. Discriminative reranking for natural language parsing [J]. Computational Linguistics, 2005, 31(1): 25-70.
[12] Huang L. Forest reranking: Discriminative parsing with non-local features [C]//Proceedings of the ACL 2008, 2008: 1067-1075.
[13] 王志国, 宗成庆. 基于高阶词汇依存的短语结构树重排序模型 [J]. 软件学报, 2012, 23(10): 2628-2642.
[14] Enrique Henestroza Anguiano, Marie Candito. Parse Correction with Specialized Models for Difficult Attachment Types[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2011: 1222-1233.
[15] Eneko Agirre, Timothy Baldwin, and David Martinez. Improving Parsing and PP attachment Performance with Sense Information [C]//Proceeding of the ACL 2008, 2008: 317-325.
[16] Yoon-Hyung Roh, Ki-Young Lee, and Young-Gil Kim. Improving PP Attachment Disambiguation in a Rule-based Parser[C]//Proceedings of the 25th Pacific Asia Conference on Language, Information and Computation, 2011: 559-566.
[17] 王锦, 陈群秀. 现代汉语语义资源用于短语歧义模式消歧研究 [J]. 中文信息学报,2007, 21(5): 80-86.
[18] Xiaorui Yang, Bingquan Liu, Chengjie Sun, and Lei Lin. InsunPOS: a CRF-based POS Tagging System [C]//Proceedings of the CIPS-ParsEval-2009, 2009: 4-6.
[19] 詹卫东, 常宝宝, 俞士汶. 汉语短语结构定界歧义类型分析及分布统计 [J]. 中文信息学报,1999, 13(3): 9-17.
[20] Xiao Chen, Changning Huang , Mu Li, et al. Better Parser Combination[C]//Proceedings of the CIPS-ParsEval-2009, 2009.
[21] John Lafferty, Andrew McCallum, and Fernando Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the Eighteenth International Conference on Machine Learning, 2001: 282-289.
