融入注意力机制的越南语组块识别方法
2019-12-30王闻慧毕玉德雷树杰
王闻慧,毕玉德,雷树杰
(1. 信息工程大学 洛阳校区,河南 洛阳 471003;2. 复旦大学 外国语言文学学院,上海 200433)
0 引言
句法分析在自然语言处理任务中占据着重要位置,是机器翻译(machine translation)、自动问答(automatic question answering)等更复杂任务的基础。由于语言自身的复杂性,尤其对于像越南语这样缺乏形态标记、以字为单位的孤立语而言,实现完全的句法分析十分困难。为此,Abney[1]提出了组块分析理论,该理论采取先将句子中的组块识别出,再寻找组块之间关系的方法,降低了句法分析的复杂度。自此,组块识别成为研究者长期关注的重要课题。
对于越南语组块识别而言,其主要面临着以下三大难题: 一是越南语缺乏形态标记,并与汉语一样主要通过虚词和词序来表示语法信息,这使得在越南语组块识别中可利用的标记信息较少;二是越南语存在定语后置的现象,这增加了越南语名词组块内部构成的复杂性,同时也加大了越南语名词组块识别的难度;三是在越南语中,动词作定语与动词作谓语在形式上完全一样,这增加了名词组块与动词组块之间的辨识难度。
对于组块识别而言,早期的识别方法主要基于规则,如基于有限状态机的方法[2]、基于转换学习与错误驱动的方法[3-4]等。从21世纪初开始,基于MBL[5]、SVM[6]、CRF[7]等传统统计模型以及规则与统计模型相结合的方法[8-10]被广泛应用在组块识别任务中。近年来,随着深度学习的兴起,该方法也开始应用于组块识别任务中[11]。而对于越南语的组块识别而言,主要有Lê Minh Nguyên等[12]采用CRF、SVM、Online Passive-Aggressive Learning(在线被动攻击学习,一种增量学习算法)等模型对越南语名词组块进行识别,实验结果显示CRF模型的识别效果最好。Nguyen Thi Huong Thao等[13]将词性特征融入到CRF模型中对越南语名词短语进行识别,实验结果显示词性对越南语名词短语的识别效果有提升作用。郭剑毅等[14]分析总结出了越南语名词组块词性组合特征,并将其作为约束条件融入到CRF模型中,得到了较好的识别效果。李佳[11]使用字符级的词向量作为输入,并将词性特征融入到Bi-LSTM+CRF模型中对越南语组块进行识别,取得了较好的识别效果。
综合来看,目前对越南语组块识别的研究还较少,识别效果还有很大的提升空间,所使用的模型也主要集中在CRF等传统统计模型上。而在深度学习方法的应用方面,目前所采用的模型也较为单一,主要为Bi-LSTM+CRF模型,缺乏对如注意力机制等深度学习技术最新发展的应用。此外,在深度学习方法中,当前研究所采用的融入特征的方法也较为机械,大多采用向量之间直接串联拼接的方法,不能够根据输入灵活确定词向量与特征向量各自的权重,这些都限制了对越南语组块的识别效果。为此,本文主要针对深度学习方法进行改进: 一是将注意力机制引入神经网络的输入层,使得模型能够灵活决定词向量与特征向量各自的权重;二是将注意力机制融入到Bi-LSTM+CRF模型中,从而使模型能够有选择地聚焦于对识别有效的信息上。
1 越南语组块内部结构
1.1 越南语组块
关于越南语组块的界定,从目前来看并没有形成统一的标准,本文以越南语及语音处理会议(Vietnamese language and speech processing,VLSP)网站公布的越南语组块语料为调查语料库,将越南语组块定义为内部可以嵌套同类型组块的词语序列。在VLSP语料中,涉及到的组块类型共有八类,如表1所示。
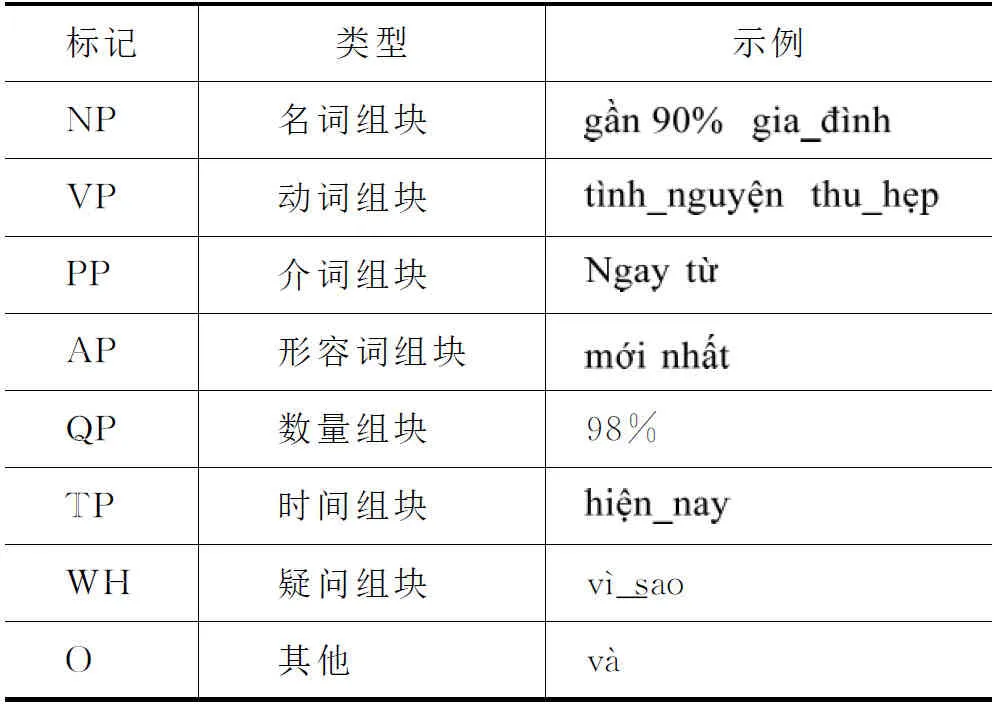
表1 本文组块类型及示例
1.2 越南语组块内部词性组合模式
以VLSP公布的组块标注语料(语料已经进行了词性标注)为调查语料库,本文对各类型组块的内部词性组合模式进行了统计。表1所示的八种越南语组块类型中,名词组块、动词组块、介词组块和形容词组块所占比率最高,共占到了语料中全部组块的99.94%,为此本文主要对调查语料库中的名词组块、动词组块、介词组块和形容词组块四种类型组块的内部词性组合模式进行调查统计。其中,对名词组块、动词组块、介词组块与形容词组块频数排名前十位的内部词性组合模式的统计结果分别如表2~表5所示。
表2~表5中,以“+”作为词性之间的连接符。从四种组块类型的内部词性组合模式来看,介词组块内频数排名前十位的词性组合模式所对应的组块占到了全部介词组块的99%以上,动词组块与形容词组块在该项统计指标上也分别达到了93.56%与96.06%,而名词组块中频数排名前十位的词性组合模式所对应的组块占全部名词组块的比例最低,为81.36%。
从以上数据可看出,越南语组块内部词性构成模式规律性明显且分布较为集中,因此将词性特征融入到组块识别任务中能够为组块识别提供更多的信息。这是本文在模型中融入词性特征的语言学依据。
从模型的角度讲,由于多头注意力机制能够更好地捕获输入序列中各输入值之间的内在联系[15],因此将多头注意力机制应用于越南语组块识别任务能够使模型更有效地利用组块的内部构成信息,并通过赋予其相应的权重,有效提升模型对组块的识别效果。这是本文将多头注意力机制融入 Bi-LSTM+CRF模型的语言学基础。
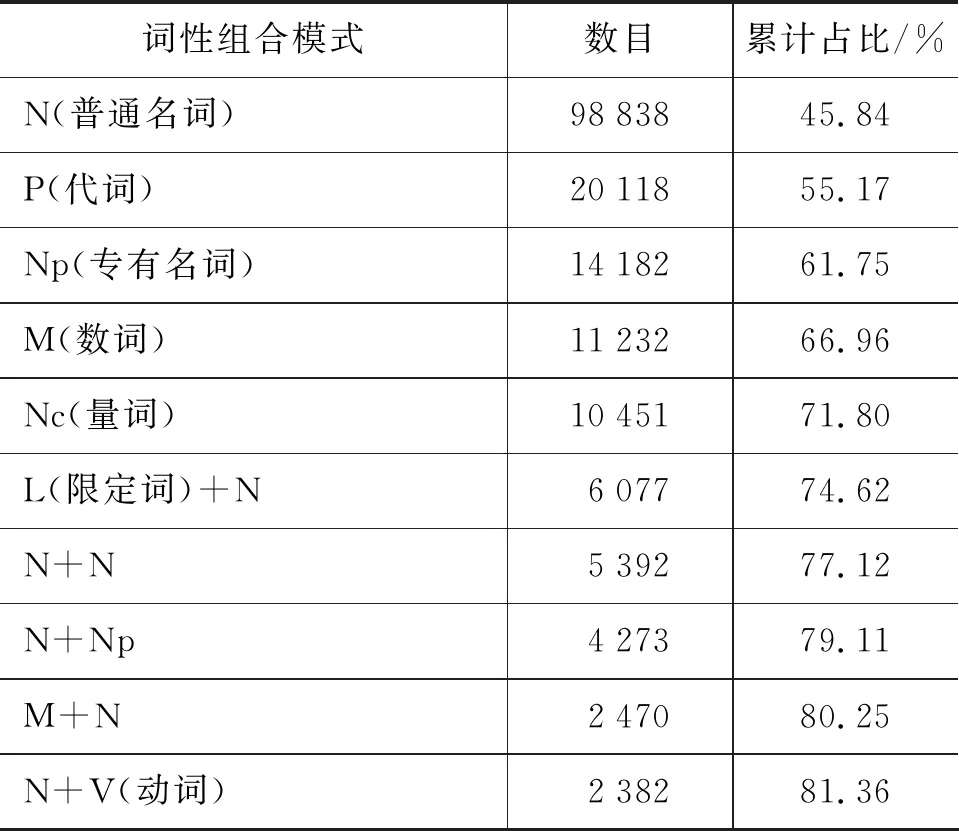
表2 名词组块词性组合模式统计
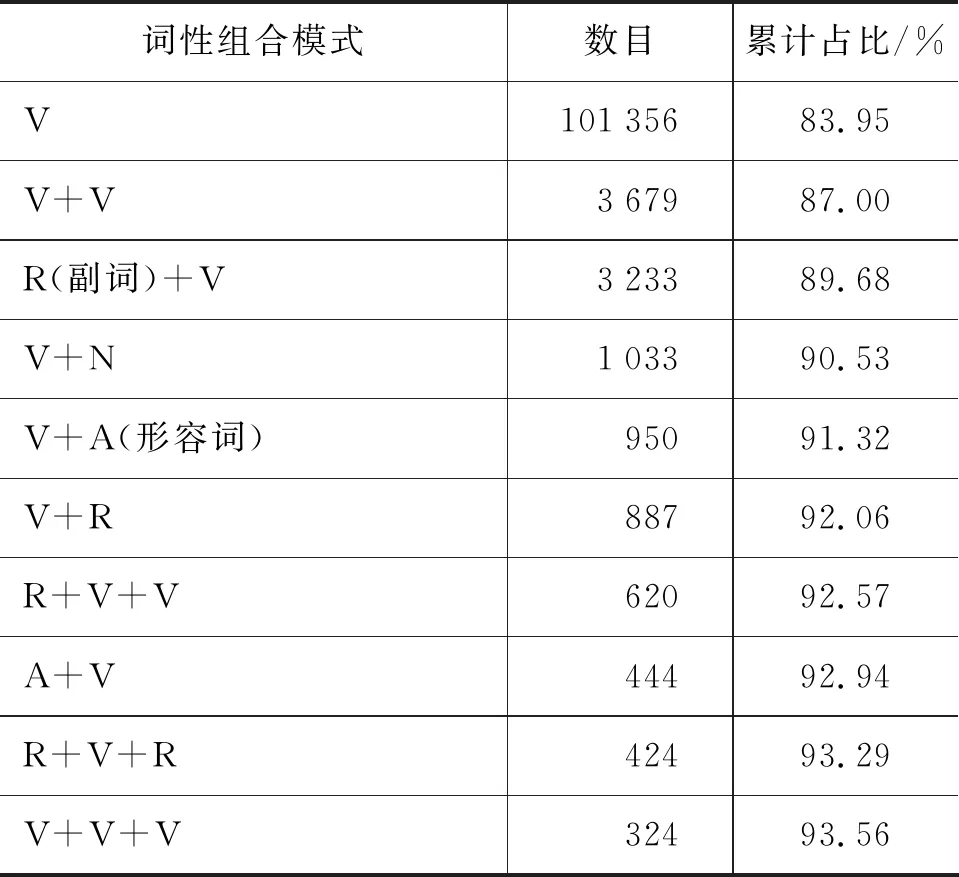
表3 动词组块词性组合模式统计
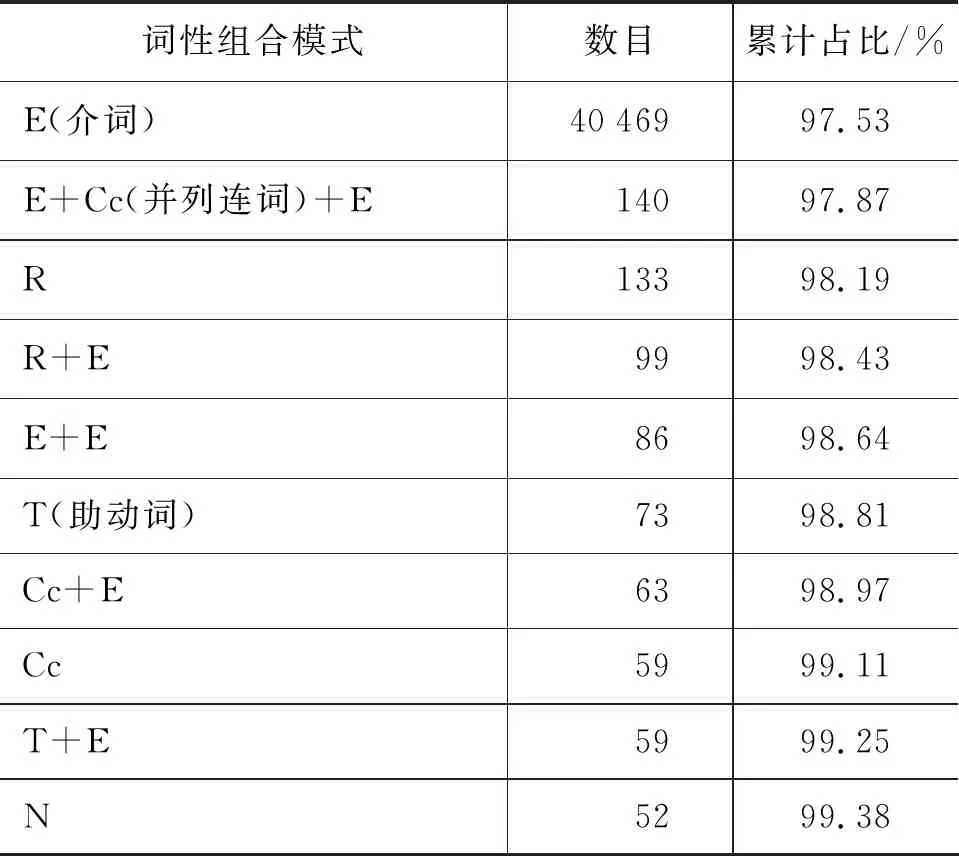
表4 介词组块词性组合模式统计
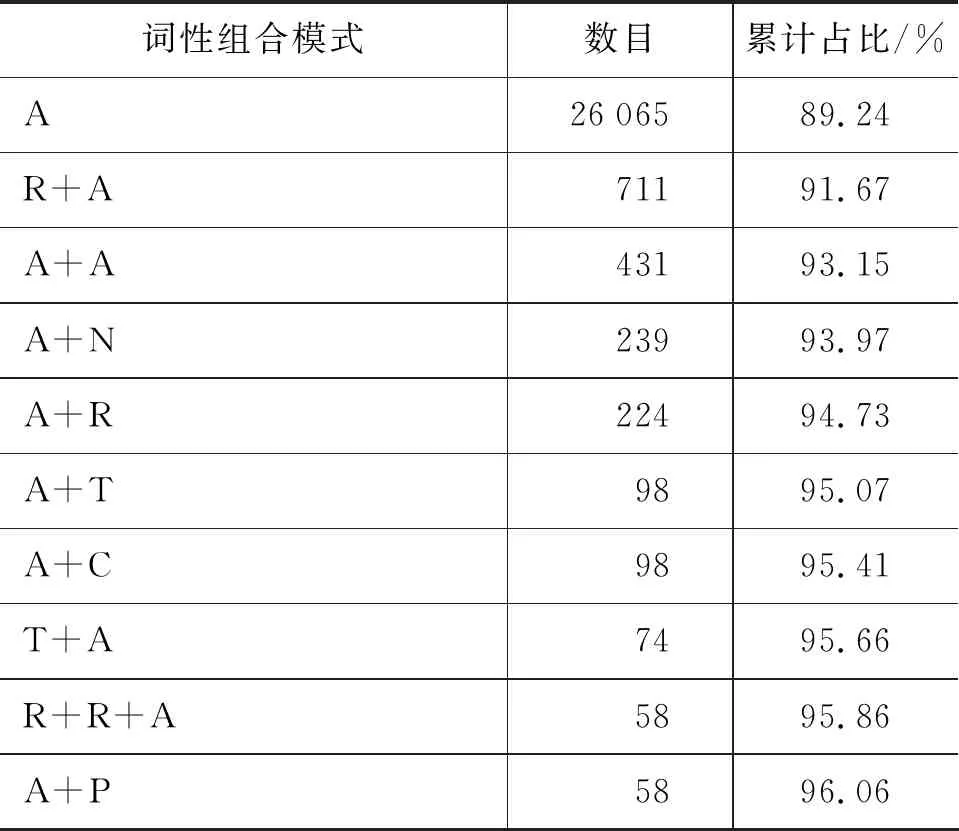
表5 形容词组块词性组合模式统计
从对未登录越南语组块识别的角度讲,使模型能够在遇到未登录越南语组块时相应地增加词性特征信息的权重,并相应地减少词汇信息的权重,则能够提升模型对未登录越南语组块的识别效果。这是本文在深度学习模型输入层融入注意力机制的语言学依据。
2 融入注意力机制的Bi-LSTM+CRF模型
2.1 越南语词向量与词性特征向量获取
词的分布式表示[16]是一种将词向量化的有效方法,能够在一定程度上表示词的语义信息,是深度学习技术应用于自然语言处理领域的基础。本文通过Word2Vec开源工具获取词向量,其包含有CBOW与Skip-gram两种模型,其中CBOW模型通过上下文来预测当前词,Skip-gram模型则通过当前词来预测上下文。本文选取CBOW模型作为词向量的训练模型,对于CBOW模型而言,其训练目标是最大化如下函数,如式(1)所示。
其中,C表示语料中所有词的集合,w表示属于C的某个词,Context(w)表示词w的上下文。
本文使用VnCoreNLP[17]工具对来自维基百科的大规模无监督越南语语料进行分词和词性标注,分别形成与维基百科语料相对应的分词语料与词性语料。其中,分词语料为维基百科语料所对应的词序列,而词性语料为分词语料所对应的词性序列。通过使用Word2Vec模型分别对分词语料与词性语料进行训练,获取预训练的越南语词向量与词性特征向量。
2.2 注意力机制
自2017年Bahdanau等[18]在英法机器翻译任务中应用注意力机制以来,注意力机制被广泛使用在自然语言处理的各项任务中。虽然注意力机制通常使用在Seq2Seq模型中,并作为Encoder-Decoder的一种机制来使用,但注意力机制作为一种思想,可以用来支持各种类型的自然语言处理任务。注意力机制的核心思想在于通过计算权重矩阵使得模型有选择地聚焦于重要信息上,其本质是一个查询到一系列(键-值)对的映射,计算如式(2)~式(4)所示。
其中,Q表示查询,K与V组成(键—值)对。式(2)用来计算Q与K的相似度,相似度的获取除了式(2)中所示的点乘法以外,还可以通过余弦相似性或引入额外的神经网络来获取。一般而言,式(2)~式(4)中的K与V相等,而在自注意力机制中,Q、K、V均相等。
作为一种较为成熟的序列标注模型,Bi-LSTM+CRF被广泛地应用在各种自然语言处理任务中。针对Bi-LSTM+CRF模型,本文使用了两种融入注意力机制的方法: 一是在Bi-LSTM层上添加了一层多头注意力机制,详见2.3;二是将注意力机制融入到Bi-LSTM+CRF模型的输入层中,以获取加入了相应权重的联合向量表示,详见2.4。
2.3 Bi-LSTM+Multi-Head Attention+CRF
长短时记忆网络(long-short-term memory,LSTM)是循环神经网络(recurrent neural network,RNN)的一种变体,其通过加入门限机制在一定程度上缓解了RNN面临的梯度弥散和梯度爆炸问题。Bi-LSTM层利用了LSTM正向与反向两个序列方向上的信息来对输入信息进行处理,而CRF层则通过计算输出值之间的转移概率,进而将输出值间的转移信息融入到模型中,从而提升模型的效果。Bi-LSTM+CRF模型的整体架构如图1所示。

图1 Bi-LSTM+CRF模型框架
多头注意力机制由Vaswani等[15]在2017年提出,其由多个放缩点积注意力机制(scaled dot-product attention)组成,内部结构如图2所示。
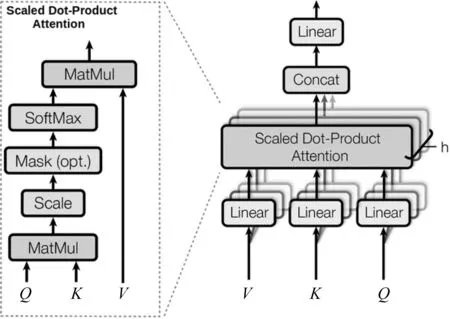
图2 多头注意力机制内部结构
由图2可知,在放缩点积注意力机制中,通过对查询Q与(键—值)对中的键K进行相似度运算等一系列操作,可以获得权重矩阵,进而使模型有选择地聚焦于重要信息上。而在多头注意力机制中,在对输入进行线性变换以后,要进行h次放缩点积注意力操作。之后,将h次放缩点积注意力操作后的向量进行串联拼接,并进行线性变换后作为多头注意力机制的输出。根据Vaswani等人的研究成果,进行多次放缩点积操作的好处在于可以使模型在不同的表示子空间里学到更多的信息[15]。
由1.2节可知,越南语组块内部构成的规律性较为明显, 而多头注意力机制有着较强的利用输入序列中各输入值间规律和关系的能力,因此将多头注意力机制加入识别模型可以增强模型利用其内部构成信息的能力。为此,本文在Bi-LSTM+CRF模型的基础上加入了多头注意力机制。融入了多头注意力机制的Bi-LSTM+CRF模型的整体架构如图3所示。
图3中,模型由输入层、Bi-LSTM层、Attention层与CRF层组成。其中,输入层将输入的词与词性特征转化为相应的向量表示,并采用首尾串联拼接的方式组合为联合向量输入到Bi-LSTM层中。Attention层在接收Bi-LSTM层的输出后,通过计算权重矩阵,增强了模型利用重要信息的能力,从而获得识别效果的提升。
2.4 融入注意力机制的联合向量表示
在以往基于深度学习的序列标注任务中,特征向量的加入一般通过与词向量的首尾串联拼接获得,如图4所示。
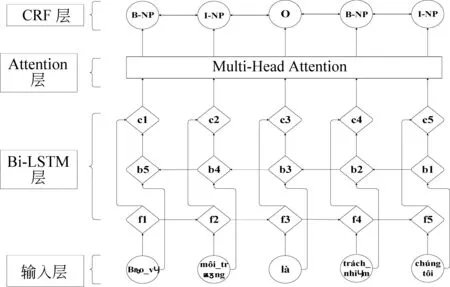
图3 Bi-LSTM+Multi-Head Attention+CRF模型
图4中,通过将预训练的词向量与预训练的词性特征向量首尾串联拼接,得到了融入词性信息的联合向量表示,并作为模型的输入层参与到序列标注任务中。但这种获取联合向量表示的方式较为机械, 且不能够对词向量与特征向量在联合向量中的权重进行灵活调整。受Rei等[19]工作的启发,本文提出了融入注意力机制的联合向量表示方法,计算方法如式(5)~式(7)所示。
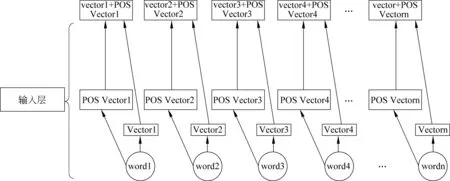
图4 直接串联的联合向量表示
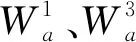
通过在输入层加入注意力机制, 可以使 模型灵活地调整输入的词向量与词性特征向量的权重,进而能够更好地处理序列标注任务,如图5所示。
图5中,预训练的词向量与预训练的词性特征向量被分别输入一层神经网络,并在激活函数的激活下获得各自的权重(词向量的权重为α,词性特征向量的权重为β)。之后,词向量与词性特征向量分别与各自的权重相乘,相乘获得的两个向量通过首尾串联拼接的方式组合为联合向量输入Bi-LSTM+CRF模型。与Rei等人的方法不同,本文的方法不要求词性特征向量的维度必须与词向量相同,也不要求α与β的和为1,这进一步增强了本文模型的灵活性。

图5 基于注意力机制的联合向量表示
3 实验及结果分析
3.1 实验数据
本文使用VLSP网站公布的组块标注语料为实验数据,语料总规模超过70万词。语料中包含8种类型的组块,其中名词组块215 620个、动词组块120 733个、介词组块41 492个、形容词组块29 208个,其余4种组块共641个。本文按照5∶1的比例将语料划分为训练集与测试集。在测试语料中,含有各类型组块 68 988个,其中未登录组块14 108个,未登录组块占比为20.45%。
本文使用IOB2标注规范,每一类型组块包含“B-组块类型”与“I-组块类型”两种标注类别,其中“B-组块类型”用来标注该类型组块的开头部分,“I-组块类型”则用来标注该类型组块的中间部分与结尾部分,而对于非组块组成成分,统一标注为“O”。本文所使用语料共包含8种组块类型,共计17种标注类别。
3.2 评测指标
为了全面评价模型对组块识别的情况,本文设置了6个评价指标,如表6所示。

表6 评测指标

续表
表6中,准确率P是指标签标注准确率,用来评价整体识别情况;越南语组块识别准确率PC是指对越南语组块整体的识别准确率,只有对整个越南语组块内的所有组成词标注正确才算对该组块识别正确;越南语组块识别召回率RC是对越南语组块整体识别的召回率;越南语组块识别F值则综合评价对越南语组块整体的识别效果;未登录越南语组块识别召回率RUKC则用来评价模型对未登录组块的识别效果,是评价模型泛化能力的重要指标,由于对越南语组块的识别难点和关键点都在于对未登录组块的识别,所以指标也是反映模型识别效果的重要指标;未登录越南语组块类别召回率RUKTC则排除了对同一未登录越南语组块的反复识别造成的RUKC虚高的情况,从类别的角度评价模型对未登录越南语组块的识别效果,该指标同样也是评价模型泛化能力的重要指标。
此外,本文还分别对测试语料中含有的名词组块、动词组块、介词组块和形容词组块的识别情况进行了统计。为了在文中更加清晰直观地反映模型对不同类型组块的识别情况,并对识别情况进行全面的评价,本文对各类型组块识别情况的评价指标设为F值,以名词组块为例,其评价指标表示为FNP。在计算各类型组块的相应指标时,只有对组块整体包含的各个组成词都标注正确才算作对组块识别正确。
3.3 模型设置
本文的模型在训练过程中全部使用自适应学习率优化函数Adam作为模型用优化函数。为了避免学习率过高导致的损失值loss出现大幅度的震荡,本文在多次实验调整后将模型的learning rate设置为0.001。此外,本文也多次调整batch size的大小以达到效果的最优,最终将batch size设置为128。为防止模型出现过拟合现象,本文采用了Dropout的方法,并将dropout值设置为0.5,即在每一个迭代训练过程中随机去除50%的数据量。
为了避免参数设置不同对模型识别效果造成的影响,在本文进行的实验中,模型的上述超参数设置完全一致,从而验证本文提出的两种将注意力机制融入Bi-LSTM+CRF模型方法的有效性。
3.4 实验设计
本文使用了VLSP网站公布的VietChunker[13]作为本文实验的基准模型,使用其在本文测试集上的测试结果作为本文实验的基线标准。
本文的实验分为五个部分,第一部分使用VietChunker进行测试;第二部分使用Bi-LSTM+CRF模型,并采用预训练的词向量作为输入;第三部分使用Bi-LSTM+CRF模型,并采用预训练的词向量与词性特征向量首尾串联拼接形成的联合向量作为模型输入;第四部分使用Bi-LSTM+Multi-Head Attention+CRF模型,采用预训练的词向量与词性特征向量首尾串联拼接形成的联合向量作为模型输入;第五部分使用Bi-LSTM+CRF模型,并采用融入注意力机制的联合向量作为模型输入,形成Attention-over-Input Layer+Bi-LSTM+CRF架构。
通过五部分实验结果的对比,可以验证本文提出的两种融入注意力机制方法的有效性。
3.5 实验结果与分析
本文在五种实验条件下对全部越南语组块的识别情况如表7所示。
由表7可知,本文使用的模型绝大多数评测指标上都要优于VietChunker(虽然以词向量为输入的Bi-LSTM+CRF模型在PC上低于VietChunker 0.83%,但其在RC上高出VietChunker 4.69%),这体现了本文方法的有效性。

表7 全部越南语组块识别情况统计
在Bi-LSTM+CRF内部,在加入词性特征向量后,模型对越南语组块的识别效果有了显著提升。其中,在准确率P上提升了5.54%,在越南语组块识别准确率PC上提升了6.97%,在越南语组块识别召回率RC上提升了7.91%,在FC上提升了7.48%,可以看出词性特征对越南语组块识别的提升作用非常明显。
相对于加入词性特征向量的Bi-LSTM+CRF模型,在加入多头注意力机制后,模型的识别效果得到了进一步的提升,在准确率P上提升了2.89%,在越南语组块识别准确率PC上提升了2.69%,在越南语组块识别召回率RC上提升了6.25%,在FC上提升了4.56%。这些数据表明,多头注意力机制的加入显著提升了模型对越南语组块的识别效果。
而对于Attention-over-Input-Layer+Bi-LSTM+CRF方法而言,相对于加入词性特征向量的Bi-LSTM+CRF模型,其在准确率P上提升了2.16%,在越南语组块识别准确率PC上提升了1.67%,在越南语组块识别召回率RC上提升了4.35%,在FC上提升了3.08%,这证实了在输入层融入注意力机制方法的有效性。但相对于融入多头注意力机制的方法而言,在输入层融入注意力机制的方法在越南语组块的识别效果上要相对差一些,其在准确率P上要低于前者0.73%,在FC上低于前者1.48%。
本文在五种实验条件下对越南语名词组块、动词组块、介词组块与形容词组块的识别效果如表8所示。
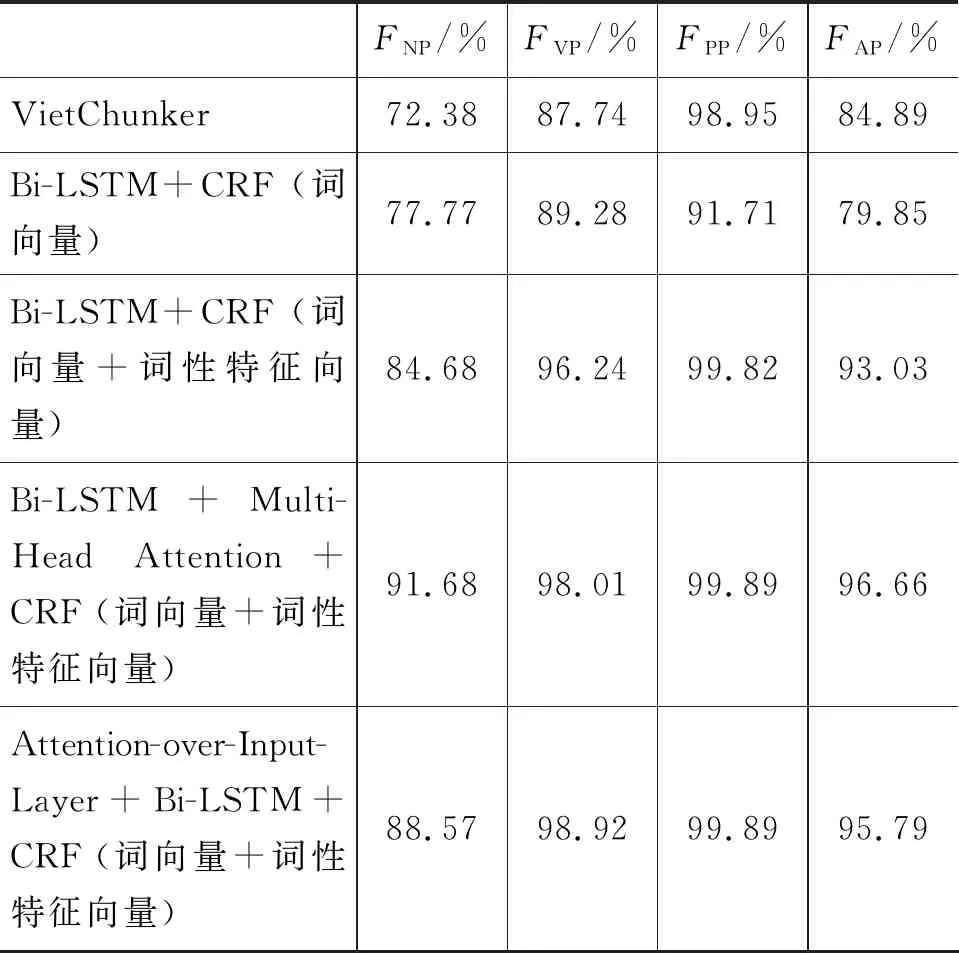
表8 各类型越南语组块识别情况统计
由表8可知,在五种实验条件下,模型对四种越南语组块的识别情况与表7中所示的对全部越南语组块的识别情况大体一致。而从四种组块类别的角度分析,在五种实验条件下,模型对介词组块的识别效果最好,对名词组块的识别效果最差,这一定程度上反映出这四种不同组块类别内部构成的复杂性不同。其中,名词组块因其内部构成最为复杂、歧义性最为显著,从而使得模型对其识别效果最差。从统计学的角度分析,由1.2节可知,在这四种越南语组块类型中,内部词性组合模式规律性最为明显的就是介词组块,其前十位词性组合模式所对应的组块就占到了全部介词组块的99.38%,而名词组块的前十位内部词性组合模式所对应的组块仅占到全部名词组块的81.36%,这在一定程度上解释了表8所示的实验结果。
作为评价模型识别效果的重要指标,未登录组块识别召回率能够在一定程度上反映模型的泛化能力,本文在五种实验条件下对未登录越南语组块的识别效果如表9所示。

表9 未登录越南语组块识别情况统计

续表
从表9可以看到,相对于VietChunker,本文所使用模型在对未登录越南语组块识别方面的表现要更加优异。而在Bi-LSTM+CRF内部,在加入词性特征向量后,Bi-LSTM+CRF模型对未登录越南语组块的识别效果有了极大的提升,其在未登录越南语组块识别召回率RUKC上提升了26.89%,在未登录越南语组块类型识别召回率RUKTC上提升了27.68%,这反映了词性信息对未登录越南语组块识别的重要性。
相对于加入词性特征向量的Bi-LSTM+CRF模型,在加入多头注意力机制后,模型对未登录越南语组块的识别效果有了进一步提升,其在未登录越南语组块识别召回率RUKC上提升了7.19%,在未登录越南语组块类型识别召回率RUKTC上提升了3.98%,这些数据表明多头注意力机制能够提升模型的泛化能力。
与表7和表8中所示的识别效果不同,Attention-over-Input-Layer+Bi-LSTM+CRF模型在对未登录越南语组块的识别效果方面要优于Bi-LSTM+Multi-Head Attention+CRF模型,其在未登录越南语组块识别召回率RUKC上高于后者0.02%,在未登录越南语组块类型识别召回率RUKTC上高于后者2.42%。这表明,在输入层融入注意力机制的方法能够更好地调整词向量与词性特征向量在识别过程中所占的比重,使得模型在遇到未登录越南语组块时能够加大词性特征向量所占的权重。考虑到词性信息在模型对未登录组块的预测上的重要作用,这样可以使得模型更好地处理未登录越南语组块,从而增强模型的泛化能力。
5 结论
针对越南语组块识别任务,本文在前期对越南语组块内部词性构成模式进行统计调查的基础上,发现其内部词性构成模式具有很强的规律性,因此提出了融入注意力机制的思路,从而使得模型能够更多地聚焦于组块的内部构成信息。在Bi-LSTM+CRF模型的基础上,本文使用了两种融入注意力机制的方法,一是在Bi-LSTM之上加入多头注意力机制,二是在输入层融入注意力机制。实验结果表明,两种融入注意力机制方法都能够有效提升模型对越南语组块的识别效果,且两种方法有着各自的优势和特点。其中,在对越南语组块的整体识别情况上,加入多头注意力机制的方法要好于在输入层融入注意力机制的方法,但在对未登录越南语组块的识别情况上,在输入层融入注意力机制的方法要好于在Bi-LSTM之上加入多头注意力机制的方法。
