基于Logistic回归的模具行业订单流失分析*
2014-02-11胡常伟
胡常伟,危 虎
(1.巨轮股份有限公司,广东揭阳 515500;2.广东工业大学广东省计算机集成制造重点实验室,广东广州 510006)
基于Logistic回归的模具行业订单流失分析*
胡常伟1,危 虎2
(1.巨轮股份有限公司,广东揭阳 515500;2.广东工业大学广东省计算机集成制造重点实验室,广东广州 510006)
模具行业客户数量相对较少但订单较多,针对用客户人口学数据进行客户流失分析的不足,基于订单信息建立模具业的订单流失预测模型。针对模具业订单样本分布极不平衡及其产生的不同错分代价的问题,提出一种基于Logistic回归的多元分类器方法,将此方法应用于某大型模具企业的订单流失分析,并与传统的Logistic回归预测算法进行比较,实验结果表明该方法能有效解决模具行业的订单流失分析问题。
模具行业;订单流失;Logistic回归;多元分类器
0 前言
模具行业产品更新频繁,随着技术的进步客户对产品要求也在不断提高,多元化的市场需求使得模具企业对客户的争夺也越来越激烈[1]。对模具企业而言,开发一个新客户的成本往往比保留一个老客户的成本要大得多,因此减少客户流失对模具企业至关重要。另一方面,模具产品大多是定制的,模具企业在实际生产过程中积累了大量的订单信息(主要包括客户的合同信息和生产过程中的业务数据),它们实时地反映了市场需求的变动和企业的运营情况。基于这些数据从企业内部挖掘出导致客户流失的因素对模具企业赢得市场具有十分重要的意义。
数据挖掘是为了建立商务决策支持系统,从大型数据库中抽取以前未知的、有效的和可控的模式或知识的过程[2]。分类作为数据挖掘中的一种重要技术,已被广泛用于金融、电信等行业的客户流失预测,且都取得了较好的预测效果[3]。这类研究主要采用决策树、Logistic回归、神经网络、支持向量机等方法建立客户流失模型。然而采用这些方法建立模具行业客户流失模型则会存在一些不足。首先,不同于常见的金融、电信等行业,模具企业客户数量往往比较少,但一个客户往往会带来多个订单;且模具客户流失往往不会是一次性彻底终止往来,通常是逐渐减少订单,降低订单交易的频率和金额,此时,同一个客户不同订单流失的可能性往往大不相同,因而导致对客户流失状态的划分很难准确。其次,模具企业对客户的人口学信息收集得较少,而且很多都不精准(如客户的区域分布、客户的信誉等级等),因此,基于客户信息来进行数据挖掘很难找出对模具业客户流失有着显著影响的因素。最后,客户流失预测是二分类问题,上述方法在追求较高预测精度的同时往往忽略两类样本数据分布不平衡的差异,而普适分类方法对这种不平衡数据集进行预测时会产生较大的错分代价[4]。
考虑客户人口学数据建立模具业客户流失预测模型的不足,基于模具业大量的合同信息和业务数据建立订单流失预测模型,帮助模具企业从内部分析导致订单流失的原因。另外针对模具订单中流失样本与非流失样本分布极不平衡的问题,在Logistic回归算法的基础上提出一种多元分类器方法,以降低Logistic回归模型在进行订单流失预测时的错分代价,将该方法应用于某大型模具企业的订单流失分析,并通过与传统的Logistic回归分类方法进行对比来验证此改进方法的有效性。
1 模具业的订单流失分析及定义
模具企业客户往往针对不同模具产品选择不同的供应商,并依据各供应商在交货期、质量等方面提供的服务质量来不断调整订单的分配。对模具企业而言,从企业内部分析客户订单流失的原因,提高自身服务质量对赢得订单十分重要。模具制造业是典型的订单式小批量生产行业[5],模具企业在生产过程中积累了大量的订单信息,这些订单信息实时反映了客户的需求变化和企业本身对订单的完成情况[6]。因此考虑基于模具企业大量订单数据建立模具业订单流失预测模型,基于客户合同信息和业务数据预测订单在未来发生流失的概率,为模具企业减少订单流失提供决策依据。图1为本文进行模具业订单流失分析的架构,包括数据输入、模型、分类输出和决策支持四个部分。
模具可重复性制造程度较低且产品种类繁多,企业通常基于产品特征将订单分为若干类型,比如可将订单类型分为全套类型、部件类型、配件类型、返修类型等,并根据实际情况可进一步细分为若干小类。各个行业对客户流失的定义都有所不同,结合模具业客户的特点,在模具专家的指导下,基于模具订单的产品类型将订单状态划分为2个类别:“未流失的订单”和“流失的订单”。其中流失的订单包括:①与当前年同比,上一年出现过,当前年没有再出现的订单类型;②与上一年同比,当前年订单的数量减少50%以上的订单类型。

图1 订单流失分析架构
本文以国内某大型模具企业为研究对象,采取分层抽样的方式从其ERP系统中抽取某个5年期共5 000条订单数据作为研究样本。基于订单属性预测订单发生流失的概率,因变量为订单的流失状态,该订单流失预测是一个二分类问题。若订单状态为未流失取值为1,订单状态为流失取值为0,则根据之前对流失订单的定义,抽取的5 000个样本中订单状态取值为1的占85.5%(共4 275条订单),取值为0的占14.5%(共725条订单),可以看到数据集中流失样本与非流失样本的分布是极不平衡的。
2 改进Logistic回归方法
2.1 Logistic回归方法
本文以订单属性为输入变量来预测订单的流失状态,因此选用分类算法来建立模型,在常用建模方法中,神经网络和支持向量机虽然预测精度较高,但其得到的规则可解释性太差,需要借助合适的规则抽取算法才能提取易于理解的知识[7]。决策树算法由于采取贪心算法而得到较多的规则集[8],模具订单根据实际业务需要往往对订单属性进行较多的划分,如果用决策树算法会基于属性的分裂对样本大量的划分,而这种划分可能对于订单分类是没有用的。Logistic回归不仅能有效地处理二值因变量问题,还可以进行模型精确度和拟合优度的检验[9]。这样不仅可以方便了解属性变量对订单流失的预测能力,而且还能分析订单流失状态对属性变量的响应程度,因此本文使用Logistic回归方法建模。
若用第1类错分率表示模型将流失的订单错分为未流失的订单的比例,第2类错分率表示模型将未流失的订单错分为流失的订单的比例。对于建立的订单流失预测模型,如果第1类错分率较高,则会增加模具企业挽留具有较高流失风险订单的机会成本,如果第2类错分率较高,则可能导致模具企业针对未流失的订单增加一些不必要的成本。而对模具企业来说,开发一个新客户来新增订单和挽留一个老客户来减少订单流失,前者的成本要大得多。因此,从模具企业实际出发,所建立的订单流失预测模型应该将第2类错分率控制在合理范围内的同时,尽可能降低第1类错分率。然而,传统的Logistic回归算法在分类过程中假设这两种分类错误的代价是相等的,处理模具订单这种样本分布极不平衡的数据集可能会产生较大的错分代价。
2.2 多元分类器方法
针对模具行业订单样本分布不平衡的特点,以及传统的Logistic回归算法在处理模具订单流失分析问题上的不足,本文借鉴文献[10]的方法,提出一种多元分类器的方法来降低流失预测模型的错分率以及由此产生的错分代价。该方法的描述如下。
(1)对于一个包含N个样本的训练集S,若其中少数样本与多数样本的数量之比为1∶x,则产生一个期望的分类比1∶y来将多数样本均匀、随机的划分为x/y个部分。此时,由每个部分的多数样本加上S中所有的少数样本组成一个训练集,则可将S划分为x/y个训练集,每个训练集包含N/(1+x)个少数样本和(N×y)/(1+x)个多数样本。
(2)对于划分后得到的每一个训练集,分别用分类算法建立流失预测模型。对一个新的测试样本每个预测模型都能独立输出一个分类结果,再用多元分类器来组合分类结果就可实现对测试样本的全面预测。由于研究旨在尽可能识别流失风险较高的订单,因此本文考虑使用加权的策略来组建多元分类器,对于未流失的订单C1和流失的订单C2,给C1赋予一个权重w1,则C2的权重为w2(w2=1-w1)。用n1和n2分别表示x/y个模型中将样本订单状态预测为未流失和流失的模型个数,当w1×n1>w2×n2时,多元分类器将测试样本预测为未流失的订单,反之则为流失的订单。
(3)随着权重w1的不断变化(单调递增或递减),多元分类器的第1类错分率和第2类错分率也将随之变化。
本文提出的多元分类器通过调整权重w1的大小可得到不同的错分率,基于两类错分率不断变化的数值可以绘制一条检测误差权衡曲线。模具企业可根据实际错分代价的不同从曲线中确定合适的错分平衡点,以建立更切合实际的订单流失预测模型。
3 方法应用和结果分析
3.1 变量分析
在本文样本数据库中,有关订单的属性有近50个,由于属性过多会增加计算的复杂程度并降低模型的有效性,故属性数量需要精减。因此应用专家评判法来挑选最为关键的主要属性,并参考其他相关研究最后确定表1所示的共12个属性变量用于建模分析。

表1 有关的属性变量
表1中,编号X1到X5是从客户合同信息中挑选出来的属性变量。其中,合同所含的产品类型分为全套类型(A类)、零部件类型(B类)、返修类型(C类)共3个大类;结算方式指客户支付货款的方式,包括现金、电汇和其他抵押方式等;订单来源是指订单对应的客户是来自境内还是境外;收款类型指客户所支付款项的用途,基于客户支付款项中是否含质保金来对收款类型分别取值。
X6到X12的共7个属性来自订单生产过程中产生的业务数据。其中,加工方法是指根据订单的产品类型和技术要求,模具企业所采取的生产加工手段,一般包含精铸、电火花加工、直接雕刻等;质量统计指订单在生产过程中,是否出现了与订单要求不相符合的不一致品(如次品、废品等);催款次数指由于客户没能按合同付款,业务员对其进行催款的频率;客户投诉指客户对订单完成情况进行的反馈,投诉途径主要分直接投诉和间接投诉两种,投诉问题主要包含产品加工不良、图纸信息不够等。
3.2 数据预处理
对于挑选出来的12个属性变量,用交叉表可进一步分析每个属性变量对订单流失影响的程度。将全部样本放在SPSS11.0上用交叉表技术进行分析,得到每一个属性变量各自识别流失订单的概率大小如表2所示。表2中,“全部样本的百分比”指在全部样本中实际拥有某一个属性的订单的比重,“流失样本的百分比”指已经流失的订单中由该属性识别的订单所占的比重。比如,在全部订单样本中,有16.2%的订单没有准时交货,而已经流失的订单样本中,交货期取值为不准时的占82.7%。用各行的“流失样本的百分比”除以“全部样本的百分比”可以得到“比率”,这个“比率”值可以有效地反应各属性对流失样本的识别能力[8]。从比率排名可以看到产品类型、交货期是否准时、客户对订单的投诉次数这三个属性的“比率”值较高,表明这些属性能从具有这一属性的所有订单中识别出很大比重的流失订单。因此研究将这3个属性作为能够显著影响订单流失的变量,其他属性由于不能显著地识别将要流失的订单而在分析中被排除。

表2 各属性对订单流失的影响情况
3.3 建立订单流失预测模型
将5 000条样本随机分为两部分,其中的3 500条样本(其中508个为流失订单)用做训练集,1 500条样本(其中217个为流失订单)用做测试集。根据Logistic函数的定义,设订单不流失(订单状态取值为1)的概率为P,订单发生流失(订单状态取值为0)的概率为1-P,则P与影响订单流失的各变量Xi之间的关系可用下列Logistic回归模型表示:
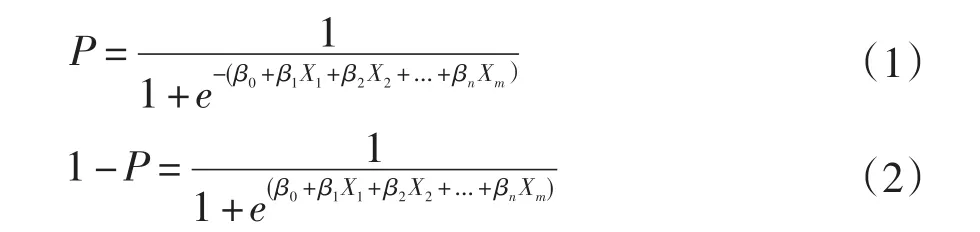
其中β0为变量无关的常数项,β1,β2,βn是回归系数,订单不流失与发生流失的概率之比为:

这个比就是事件的发生比,将它取自然对数可得到一个线性方程:
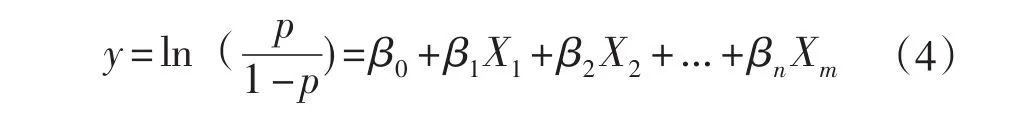
对于训练集数据,将交货期(JHQ)、产品类型(CPLX)、投诉次数(TSCS)作为输入变量,订单的流失状态(LSZT)作为输出变量,在SPSS软件上使用Logistic回归分析方法得到以下模型:

由于产品类型分为A、B、C三个大类,故对应三个不同的回归系数。此时模型输出的卡方统计检验值X2为12.725,显著性值Sig=0.000 5<0.001,因此可认为模型中这三个属性对因变量有显著影响。此时选用10折交叉验证法得到模型的分类准确率为79.32%,第1类错分率为52.44%,第2类错分率为18.82%。用训练集数据得到模型的具体参数之后,对于测试样本将其对应的参数代入方程(1)或(2)便可预测每个订单发生流失的概率,从而得到订单流失状态的输出。
为解决样本分布极不平衡的问题,研究使用多元分类器方法。数据集中流失样本与非流失样本的比例接近1∶6,为平衡两类样本分布可将期望的分类比设为1∶1。此时,未流失的样本被均匀、随机地分成6个部分,加上流失的样本可构成6个训练集。对6个训练集分别建立Logistic回归模型,将测试集的新样本分别输入这6个模型,则每个样本都可得到6个分类预测结果。当赋给未流失订单的权重以0.01的增量从0.01增加到0.99时,根据之前的多元分类器算法可得到一条基于两种错分率的检测误差权衡曲线,如图2所示。从图2可以看到,随着未流失订单权重的增加,第1类错分率在不断上升而第2类错分率在不断下降。
3.4 结果与分析
将订单的相关属性作为输入变量,应用交叉表技术进行分析,发现在模具企业运营过程中交货期、订单的产品类型、客户的投诉次数对订单流失有着显著的影响。研究建立的回归分析模型反映了这些属性与订单流失之间的相关性,根据模型识别出的流失订单特征,模具企业可以采取相应的管理策略来预防订单流失。
另外,在图2中标示用传统单个分类器建模时获得的第1类错分率和第2类错分率,可以看到对于多元分类器建立的模型,在第1类错分率为52.44%的时候第2类错分率为15.67%,第2类错分率为18.82%的时候第1类错分率为43.82%。由此可见本文的多元分类器方法对降低预测模型的两类错分率都取得了较好的效果。通过图2所示的检测误差权衡曲线,模具企业可根据实际来选取合适的错分率,从而得到更有效的订单流失预测模型。
Response图和Lift指标可用来评价模型的性能,如图3所示,Response图横轴表示抽取的样本占订单总数的百分比,纵轴表示所抽取样本中的流失订单占流失订单总数的百分比,对角线表示不用模型随机抽取的预测效果。用本文的Logis⁃tic回归模型对测试集数据进行预测时得到图3模型1所示的Lift曲线,当横轴抽取10%总订单数时,Logistic回归模型能识别出45.85%的流失订单,此时模型的Lift指标为:45.85%/10%= 4.585,由此可见与随机抽取相比预测效果有了较大提升。为方便与其它普适分类方法进行对比,研究假定预测模型的两类错分代价相等,在多元分类器中给流失订单和未流失订单赋予相同的权重(即w1=w2),此时用多元分类器模型对测试集进行预测得到图3模型2所示的Lift曲线。显然,模型2比模型1获得了更高的Lift指标,实证结果表明,本文提出的基于Logistic回归的多元分类器方法对模具行业的订单流失分析取得了较好的预测效果。
4 结论
针对模具行业用客户人口学数据进行客户流失分析的局限性,本文基于客户合同信息和业务数据建立了模具业的订单流失预测模型,对模具企业的订单流失现象进行了分析。另外研究在Logistic回归算法基础上提出了一种多元分类器的建模方法,以解决模具订单样本分布极不平衡及其产生不同错分代价的问题。该方法在建立流失预测模型时能够为模型的两类错分率找到一个平衡点,在一定程度上弥补了传统分类算法建模时默认两种错分代价相同的不足,提高了模型在实际应用中的有效性。将该方法应用于某大型模具企业的订单流失分析问题,获得了较好的预测效果。
[1]鲍明飞.模具企业转型发展的挑战和机遇[J].模具工业,2012,38(10):1-4.
[2]Berry M J A,Linoff G.Data mining techniques:for marketing,sales,and customer support[M].New York:Wiley,1997.
[3]刘志妩.基于决策树算法的学生成绩的预测分析[J].计算机应用与软件,2012,29(11):312-315.
[4] Elkan C.The foundations of cost-sensitive learning[A].Proceeding of the Seventeenth International Joint Conference on Artifi⁃cial Intelligence [C]. 200l:973-978.
[5]胡钰松,胡常伟.模具制造企业备件库存分类方法研究[J].机械设计与制造,2012(11):236-238.
[6]陈少镇,陈庆新,毛宁,等.考虑进度协调的模具订单投放控制策略[J].机电工程技术,
2012(10):17-22.
[7]张旭梅,石瀚凌.基于分类挖掘方法的商业银行个人理财业务客户流失分析[J].工业工程,2011,14(6):126-132.
[8]Jiawei Han,Micheline Kamber.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.
[9]蒙肖莲,蔡淑琴,杜宽旗,等.商业银行客户流失预测模型研究[J].系统工程,2004,22(12):67-71.
[10]Chan P K,Fan W,Prodromidis A L,Stolfo S J.Dis⁃tributed data mining in credit card fraud detection[J]. IEEE Intelligent Systems,1999,14(6):67-74.
Order Churn Analysis in Mold Industry Based on Logistic Regression
HU Chang-wei1,WEI Hu2
(1.Greatoo Inc.,Jieyang515500,China;2.Guangdong Provincial Key Lab of Computer Integrated Manufacturing System,Guangdong University of Technology,Guangzhou510006,China)
The number of customers in the mold industry are limit but the orders are adequate,in response to the unavailability of customer demographics while doing customer churn analysis in the mold industry,order churn prediction model of mold industry based on customer contractual information and business data was set up.To deal with the challenge of a highly skewed class distribution between churn and non-churn and different classification cost it cause,a multi-classifier approach based on logistic regression was proposed. Then,the proposed method was applied to a mold enterprise,by comparing with the model build by traditional logistic regression,results suggest that the proposed method exhibits satisfactory predictive effectiveness in the mold industry.
mold industry;order churn;logistic regression;multi-classifier
TH166
A
1009-9492(2014)08-0062-06
10.3969/j.issn.1009-9492.2014.08.018
胡常伟,男,1978年生,湖北仙桃人,博士后。研究领域:企业信息化、项目管理、智能制造。
(编辑:向 飞)
*国家科技支撑计划项目(编号:2012BAF12B10)
2014-06-30
