海量连续运行参考站网数据云存储模型
2014-01-10李林阳吕志平陈正生樊黎晖
李林阳,吕志平,陈正生,樊黎晖
(1.信息工程大学 地理空间信息学院,郑州 450052;2.成都测绘信息中心,成都 610000)
1 引言
20世纪80年代,加拿大首先提出 “主动控制系统”概念,并于1995年建成了第一个全球定位系统(global positioning system,GPS)连续运行参考站网(continuous operating reference station system,CORS)。随着差分技术、网络实时动态差分法(real-time kinematic,RTK)技术的出现与逐步普及以及计算机技术、网络通信技术的飞速发展,CORS得到了不断发展和壮大,世界上很多国家纷纷建成了国家级、区域级、城市级的CORS[1-4]。面对规模庞大的 CORS站网及其连续观测,如何对CORS数据进行高效地存储、组织、管理与发布,提高处理和分发的效率,缓解海量数据与有限的计算、存储能力的矛盾 成为一个迫切需要解决的问题。
目前已建成的CORS数据管理系统大部分基于FTP文件格式存储原始数据,如国际全球卫星导航系统国际服务协会(international global navigation satellite system service,IGS)和中国大陆构造环境监测网络简称陆态网(crustal movement observation network of China,CMONOC),用户通过FTP下载数据产品。这种管理模式技术成熟,但存在如下缺点:结构简单,缺乏统一管理机制;信息安全性、完整性低,不具备并发控制与故障恢复的功能;实时性差,用户不能实时地获取数据。
2006年投入使用的北京全球定位综合应用服务系统(BGIAS)采用基于关系数据库技术的实时数据存储与应用服务方案[6]。文献 [7]在关系数据库的基础上,提出适用于实时服务的数据预处理结合Huffman编码的压缩方法和事后数据服务的Huffman和LZ77编码结合的压缩方法,实现了CORS数据的无损压缩。该方式组织灵活,检索管理方便;但其对服务器性能要求高,随数据量的增加检索速度降低,并发共享和抗灾容错能力较差。
综上所述,以上三种存储模型均采用集中式存储,随着CORS数据的几何倍数增长[1]以及单个节点硬件设备的限制[8],这些方式在管理海量数据(Tbit甚至Pbit级)方面存在诸多限制[9],集中存储策略已不能满足大规模存储应用的需要。大型CORS网具有基站数量多、观测数据多、数据共享关系复杂的特点,基站与各数据中心相连,各数据中心又可互相通信,其本身就是一个天然的分布式系统[10]。本文对CORS站网的数据量进行了分析,指出了集中式数据存储管理海量CORS数据的问题;研究了CORS数据云存储模型,提出了CORS数据云存储集群、组织和访问架构;基于分布式数据处理平台Hadoop,采用多台存储节点分担存储负荷,突破了CORS数据集中存储方式不易扩展、可靠性差等缺点,具有管理方便、组织灵活、高抗灾容错性、高扩展性、高数据读取性能,支持大吞吐量数据的并发访问,适于海量CORS数据的高性能应用。
2 CORS数据量分析
CORS站每天主要采集的数据类型有三种:观测数据文件、导航星历文件和气象文件。观测数据文件主要包括低采样率(15s30s 和高采样率(1s)的数据。1s采样率的数据量较大,受限于数据中心的存储空间,一般存储时间短,目前只存储1a或2a,15s或30s采样率数据永久存储;星历文件一般为几十kbit,个别包含了格洛纳斯卫星导航系统(global navigation satellite system,GLONASS)星历的文件较大,达到几百kbit;气象文件一般也为几十kbit。CORS数据量估算如表1。
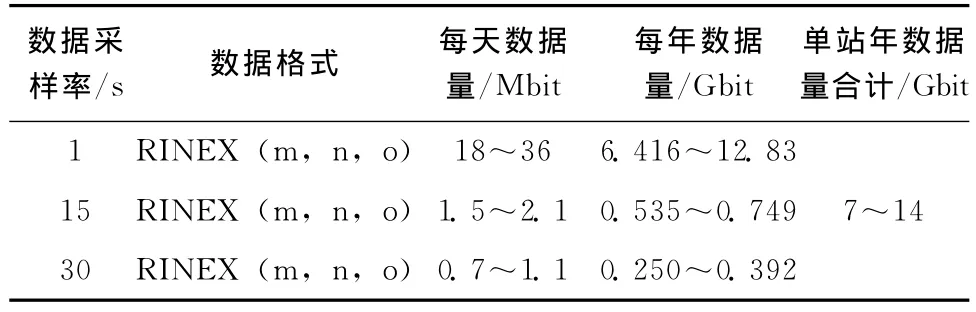
表1 一个CORS站的数据量估算(仅观测GPS卫星)
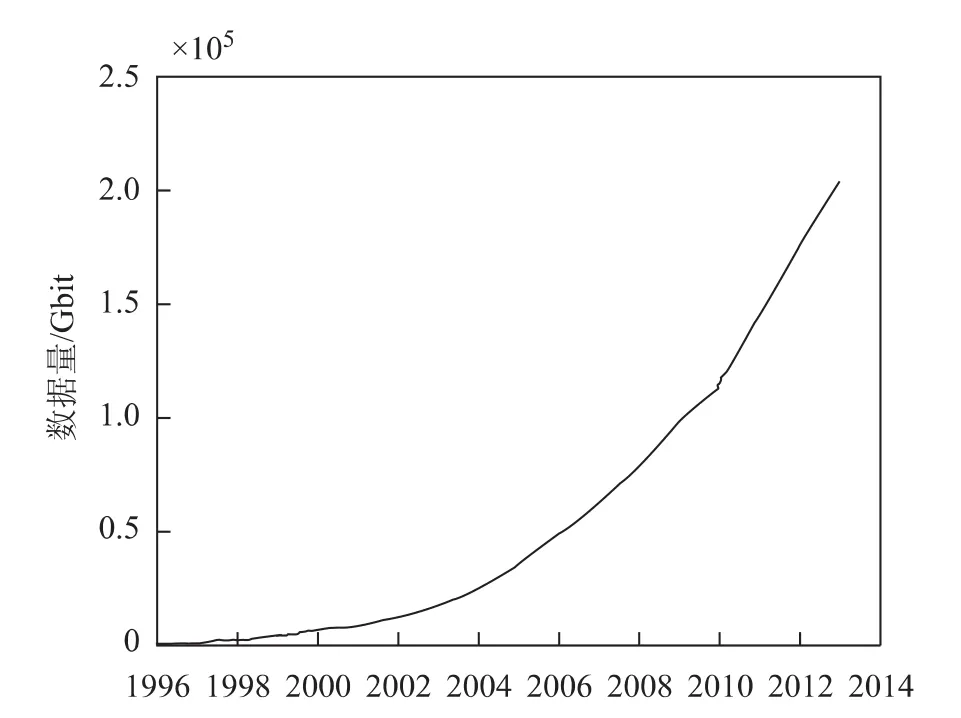
图1 SOPAC的数据量统计
以IGS站为例,截止至2014年4月,全球共有495个IGS站,假定每个站点采集了高采样率的数据,每站每年共接收7~14Gbit的卫星数据,全网每年共产生3.4~6.8Tbit的数据量,再加上数据分析中心发布及提供的各项产品和服务,数据存储服务器需要管理海量的数据和产品。斯克里普斯轨道和常驻阵列中心(scripps orbit and permanent array center,SOPAC)作为IGS数据操作中心之一,自1996年以来其存储和管理的数据量如图1所示。已建成的陆态网由260个连续观测和2 000个不定期观测站点构成,单站单天30s采样率的数据文件(d文件)大约为600kbit,2013全年30s采样率的数据达到48Gbit。BGIAS每天观测产生的数据量约为600Mbit,全年约为214Gbit。
随着GPS现代化进程加快、GLONASS系统恢复使用、伽利略卫星导航系统(Galileo navigation satellite system,Galileo)和我国北斗卫星导航系统(BeiDou navigation satellite systemBDS的投入使用,各个卫星系统之间稳步实现的兼容互操作为用户提供了大量可用卫星数,CORS站观测数据量的大小将成倍增加。目前部分IGS站和全部陆态网参考站采集了GLONASS数据,每天接收的数据量至少增加了一倍。
面对海量CORS数据及发布的产品,集中式CORS数据存储策略采用 “存储服务器+独立磁盘冗余阵列(redundant array of independent disk,RAID)”的方式管理CORS数据和产品,受单节点服务器性能和网络带宽的限制,中心节点成为系统的瓶颈,系统的扩展性、可靠性和抗灾容错性能不足,存在用户访问延迟大、数据下载速率慢等问题。
3 CORS数据云存储模型架构设计
3.1 CORS数据云存储的定义及平台架构
CORS数据云存储是指通过集群应用、网格技术或分布式文件系统等功能,将CORS系统中大量不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供CORS数据存储、产品服务和用户访问的系统。
CORS数据云储存平台架构可以划分为:CORS数据存储层、系统基础管理层、CORS应用接口层、CORS用户访问层,如图2所示。
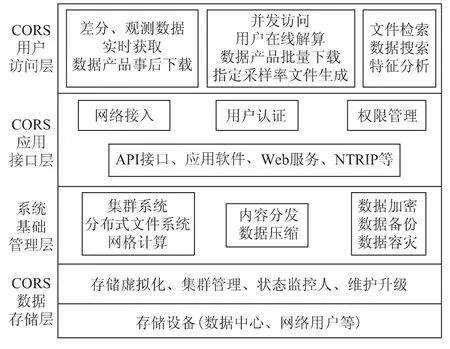
图2 CORS数据云存储平台架构
CORS数据存储层是云存储最基础的部分。存储设备为每个数据中心的硬件设备,每个数据中心构成独立的云存储集群,分布在不同的地域,集群之间通过互联网连接,进行数据交换。统一的存储设备管理层通过存储虚拟化和集群管理技术,对存储硬件资源进行抽象化表现,实现数据和存储设备的统一管理[[11-13]。
系统基础管理层是云存储最核心、最难实现的部分。通过集群系统、分布式文件系统和网格计算等技术,实现云存储设备之间的协同工作,提供同一种服务和更强的数据访问性能[14];内容分发系统保证CORS数据不会被未授权的用户所访问[15];通过数据备份、加密、容灾技术可以提高CORS数据的可靠性。
CORS应用接口层是云存储最灵活多变的部分,它面向用户的各种需求。根据CORS的建设、维护和升级及各类用户的需求,开发不同的应用服务类型,提供不同的应用程序编程接口(application programming interface,API)及应用软件,采用不同的CORS数据传输协议。例如在差分数据传输中,可采用国际海运事业无线电技术委员会(radio technical commission for maritime services,RTCM)数据传输协议[16](networked transport of RTCM via internet protocol,NTRIP)。
CORS用户访问层包括各类通过授权的用户,通过标准的公用接口接入CORS数据云存储系统,进行实时差分定位,下载数据和产品等,享受云存储提供的服务。
3.2 CORS数据云存储集群架构
在云存储和计算方面,Hadoop是一个可以对海量数据进行分布式处理的软件框架[17-18],具有可靠、高效、可扩展这三大特性,加上Hadoop开源免费的特性,Hadoop技术迅猛发展。Hadoop采用主/从(Master/Slave)架构,其重要组成部分是分布式文件系统(hadoop distributed file system,HDFS),一个HDFS由一个NameNode、一个Secondary NameNode和若干个DataNode这三个守护进程组成。
基于HDFS的运行体系,设计了CORS云存储集群体系架构,将一个CORS数据中心定义为一个集群,若有多个数据中心则建设多个集群。体系架构如图3所示。
1)数据中心的NameNode节点负责管理该数据中心的DataNode节点,并以 “文件路径/CORS数据块集合”的形式记录集群内CORS数据的存储位置;
2)Secondary NameNode节点是辅助Name-Node节点,运行在数据中心的一台计算机上,与NameNode节点保持通信,按照一定时间间隔保持CORS云存储集群元数据的快照,以备NameNode节点发生故障时进行CORS数据恢复。
3)数据中心的其它硬件设备为DataNode节点,在本地文件系统中以数据块的形式存储CORS数据产品,响应用户对CORS数据块和元数据的请求,周期性地向NameNode报告所存储的CORS数据块信息。
相比传统的集中式CORS数据存储,图3所示的CORS数据云存储架构具有以下技术特点:
1)数据存储在各数据中心的硬件设备中,各数据中心之间相互通信、独立运行、互相兼容,任何存储单元均可作为存储节点加入到CORS集群,大大提高了集群存储和计算容量的扩展性。
2)CORS数据流入、流出DataNode节点,对数据中心的服务器要求较低,不会成为系统的瓶颈。
3)采用机架感知[19](rack awareness)的策略,NameNode节点可以确定每个DataNode节点所属的机架ID,改进了数据的可用性、可靠性和网络带宽的利用率;
4)集群启动时,自动进入安全模式,计算CORS数据块数量、集群内的可用节点数、可用存储空间等,保证了CORS数据的完整性和可靠性。
5)集群运行时,通过DataNode节点的块报告(block report)和心跳检测(heartbeat)机制,数据中心NameNode节点监控各DataNode节点的运行状态、磁盘利用率、网络带宽等,均衡集群中各个计算机的存储负载,优化集群的运行。
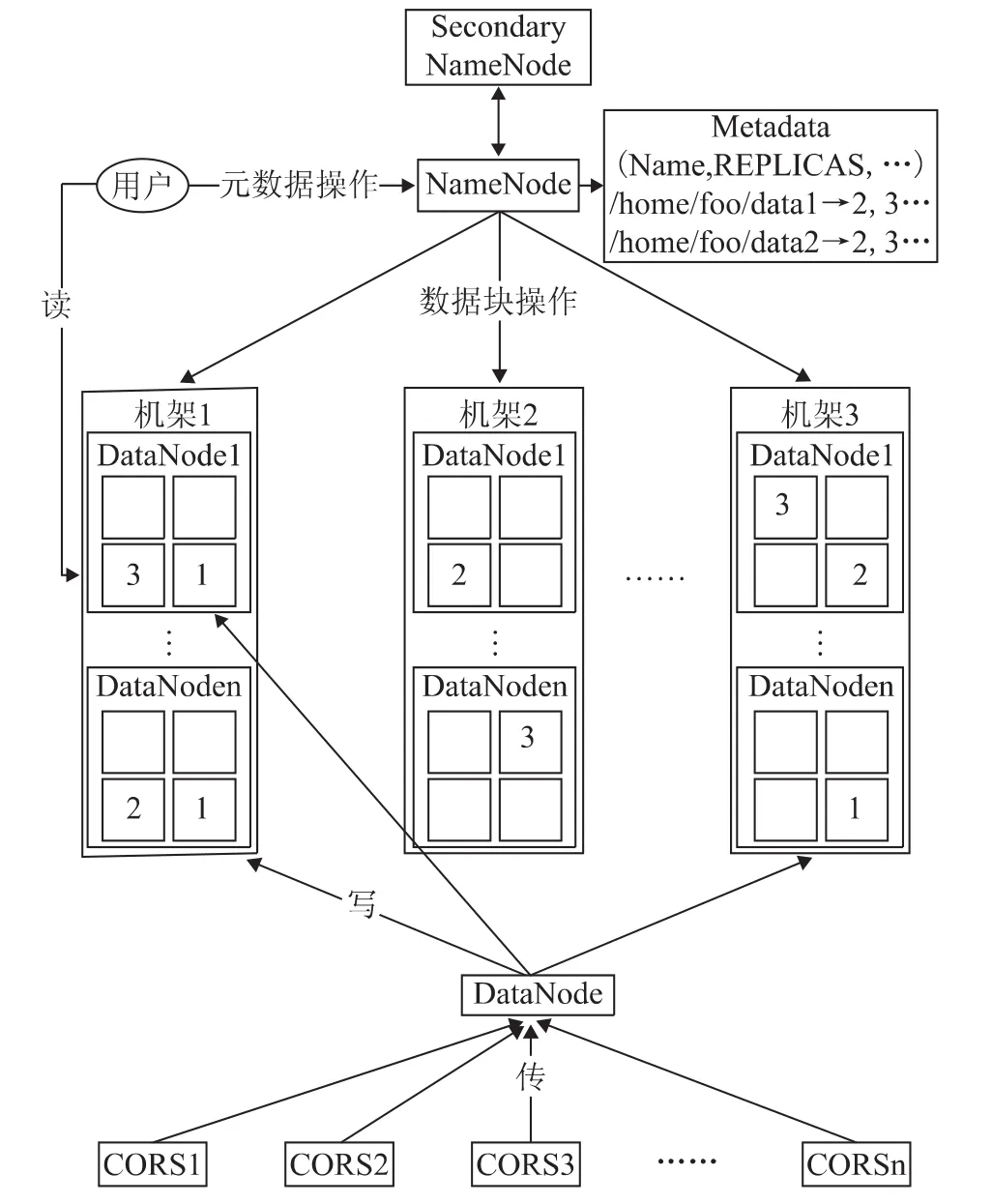
图3 数据中心CORS数据云存储逻辑框架
6)Secondary NameNode保持对CORS数据系统元数据的快照,在NameNode节点发生故障时进行数据恢复,提高了系统的健壮性。
3.3 CORS数据云存储组织架构
数据中心发布的产品,建立products存储目录,再依据产品种类,如轨道和钟差(预报、快速、精密)、对流层天顶延迟、电离层格网图、地球自转参数、参考站坐标及速率等,分别建立子目录。由于发布的产品种类较多、类型各异,各产品大小不一,最小的只有几kbit,最大的达到数Gbit。Hadoop在存储大文件方面,采取数据块存储的方式,将每个大文件分成若干个数据块,存储在不同的DataNode节点,数据块的尺寸可以调整为默认值128Mbit(Hadoop 2.0的默认值)的整数倍;在小文件存储方面,可以使用Archive工具、CombineFileInputFormat类、SequenceFile格式,分别将许多小文件归为一个HAR文件、将多个文件打包到一个分片、利用key-value合并文件,降低了集群的存储容量开销和总数据中心的内存开销。
CORS站实时采集高采样率数据文件,实时传输到数据中心,进行质量检核并转换为RINEX格式,数据中心的DataNode节点执行数据写入集群操作,即可实现数据的实时共享;CORS数据写入的过程是即时、动态的,满足网络RTK等实时定位技术的需求,同时实现了CORS数据的完全备份。CORS观测数据的存储目录按年积日进行排列,建立与观测日期对应的文件夹,存放观测当天所有CORS站的观测数据。
当数据副本数(dfs.replication)为3h(可设置为更大参数),部署策略是将第一个副本存放在本节点,第二个副本放在同一机架的另一个Data-Node节点,最后一个副本放在另一个机架的DataNode节点。数据文件1的3个副本的存放位置如上图3所示。通过副本存放策略,集群具备了抗灾性和容错性;机架的错误远比DataNode节点的错误少,这个策略可以防止数据中心内的整个机架因故障失效时,不会影响到CORS数据和产品的可靠、可用性。
利用Hadoop的分布式数据处理模块MapReduce,可生成采样率是1s整数倍的观测数据文件。因此在年积日的目录下,可建立1s、15s、30s采样率的文件夹,授权用户可以下载指定采样率和指定时间段的观测数据文件。生成30s采样率数据文件的流程如下图4,分为输入分片(input splitmapreduce和输出(output 四个步骤。分片是将RINEX观测文件按照测站名和观测日期划分为数据块;map函数对每一分片的数据逐行进行过滤,转换为由文件头信息和观测历元的数据组成的键/值对;reduce函数根据指定的采样率和采样时间,变更文件头信息,提取观测历元,排序后生成新的观测数据文件。多个节点的map和reduce共同完成整个CORS网观测数据的处理。
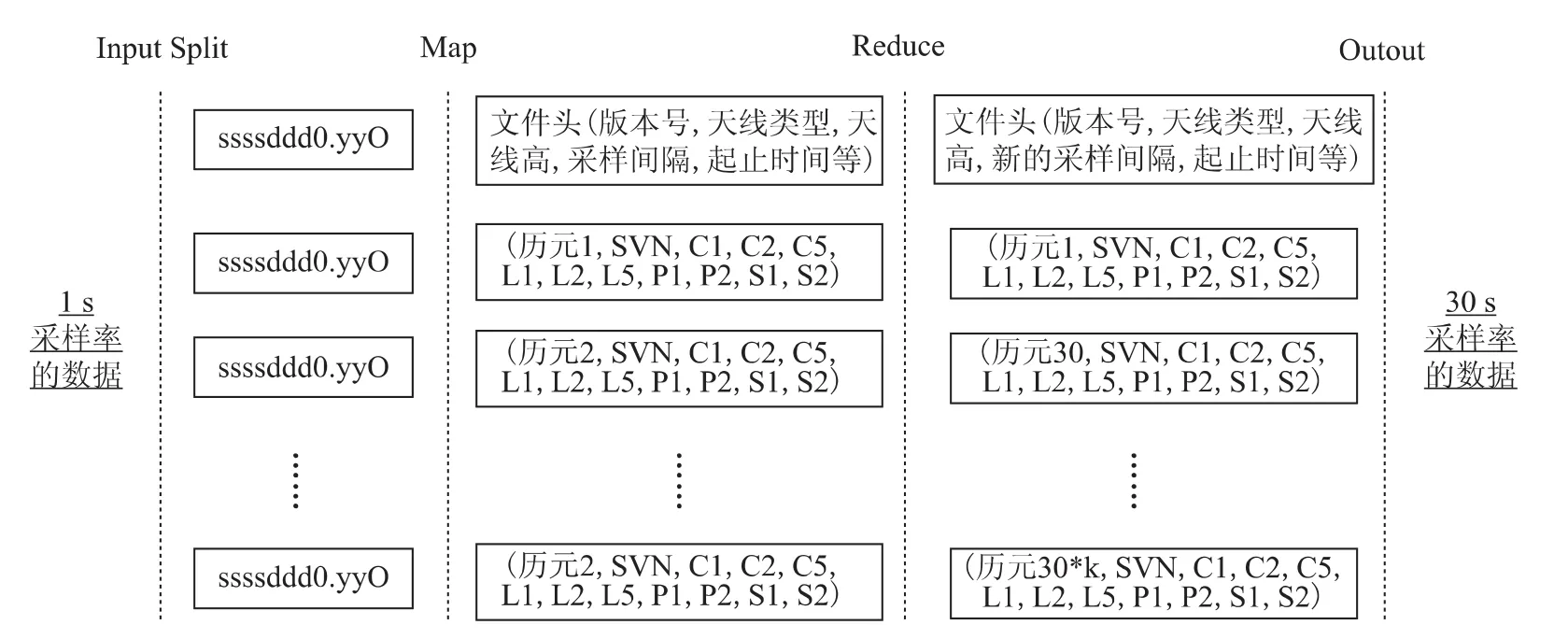
图4 30s采样率文件生成流程
3.4 CORS数据云存储访问架构
基于Hadoop的CORS数据云存储技术为用户提供了便捷的共享机制,通过访问NameNode节点的50070端口进入分布式文件系统,可以查看集群的存储容量、集群内可用和失效节点数、集群运行日志、集群配置和部署情况、CORS数据和产品总量、CORS数据文件位置等,在被授权之后,用户可以下载CORS数据和产品,下载时通过检验文件创建时的校验和提高了数据传输的完整性和可靠性。
由于CORS数据分布地存储在各个DataNode节点,Hadoop实现了树形的网络拓扑结构[20],通过网络节点的规划机制,NameNode节点会根据存储节点与用户之间的 “距离”和网络带宽对多个DataNode进行排序后返回给用户,以便从最快的存储节点读取数据,减少CORS数据的传输时间。
为了支持在线用户同时进行的大吞吐量数据的并发访问(满足较多网络RTK用户实时需求和支持大量用户的并发数据下载),采用了支持并发常用的多服务队列机制,包括:
1)NameNode服务队列。用户接受差分定位服务和下载CORS数据产品时,需要从NameNode节点获取文件的元数据,根据系统访问量合理设置dfs.namenode.handler.count参数控制的线程数量,来响应大量用户的并发访问请求。
2)DataNode服务队列。用户在线服务以及数据的读取均发生在各数据中心的DataNode节点,可以启动dfs.datanode.handler.count参数控制的线程数量,应对CORS数据块读取操作。
3)用户请求队列等待。从1)和2)看,NameNode和DataNode都采用了服务队列机制处理并发请求,当用户并发请求数超过总线程数时,请求会在队列中等待。
通过合理配置以上3个服务队列的数量,会有效提高CORS数据云存储集群的服务效率。
4 实验分析
实验环境:虚拟机选择VMware Workstation10.0.1build-1379776,操作系统选择Ubuntu 13.10。实验搭建了Hadoop完全分布式集群,由一台NameNode(同时作为Secondary NameNode)和三台DataNode节点组成,IP地址设置如下:NameNode:192.168.100.129,DataNode1: 192.168.100.130,DataNode2: 192.168.100.131,DataNode3:192.168.100.141。以陆态网2013年的观测数据为例,通过HDFS API建立了存储目录,将全年的观测数据写入到集群中。集群搭建情况如图5所示。
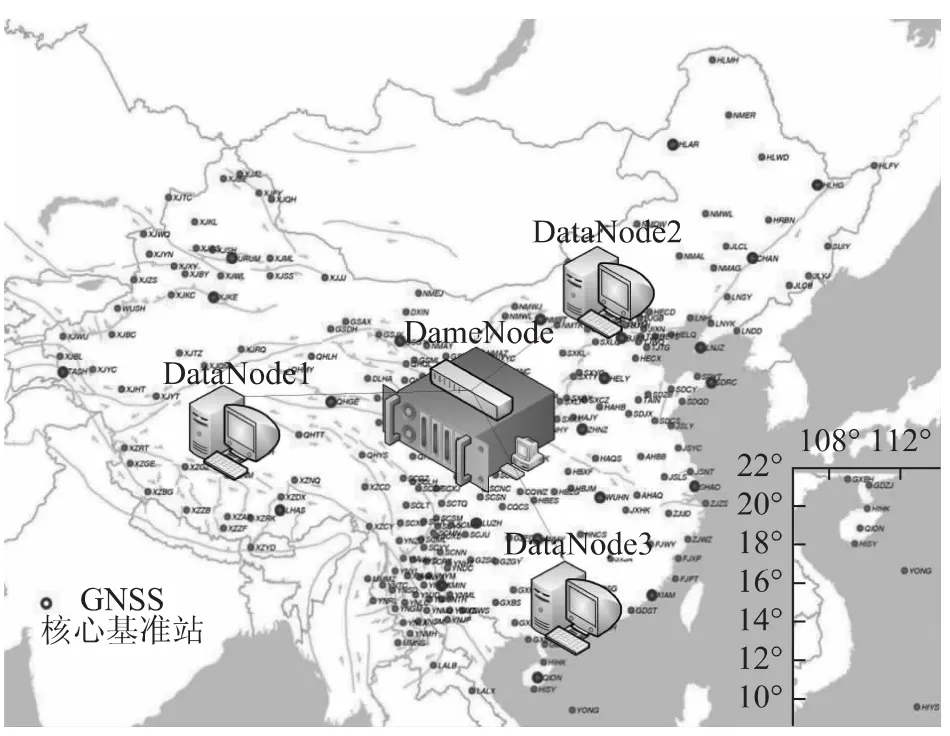
图5 实验搭建的云存储集群
4.1 集群可靠安全性
在启动集群,首先启动NameNode节点,不启动任何DataNode节点,通过http访问192.168.100.129的50070端口,看到live node数为0,集群一开始会自动进入安全模式。
随着DataNode节点的启动,当NameNode监测到足够数量的数据块,集群才会退出安全模式;本实验中三台DataNode节点启动后,才退出安全模式。集群运行过程中,每隔1h,DataNode都会向NameNode发送一个心跳报告和块报告(对应日志文件),包含了全部DataNode磁盘中所有CORS数据块的信息,NameNode可以跟踪监测数据块的变化。
4.2 集群抗灾容错性
为了测试在存储节点失效的时,CORS数据的完整性,在设置副本数为2的前提下,关闭某一存储节点。如图6的最下端所示,中国周边IGS站.txt存储在DataNode1和DataNode2节点。将DataNode2节点关闭,如图7所示,中国周边IGS站.txt存储在DataNode1和DataNode3节点中。在关闭DataNode2节点的整个过程中,集群正常运行,并未受到DataNode2节点失效的影响。
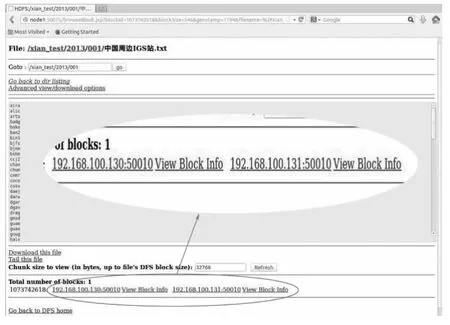
图6 DataNode2节点关闭前文件存储位置
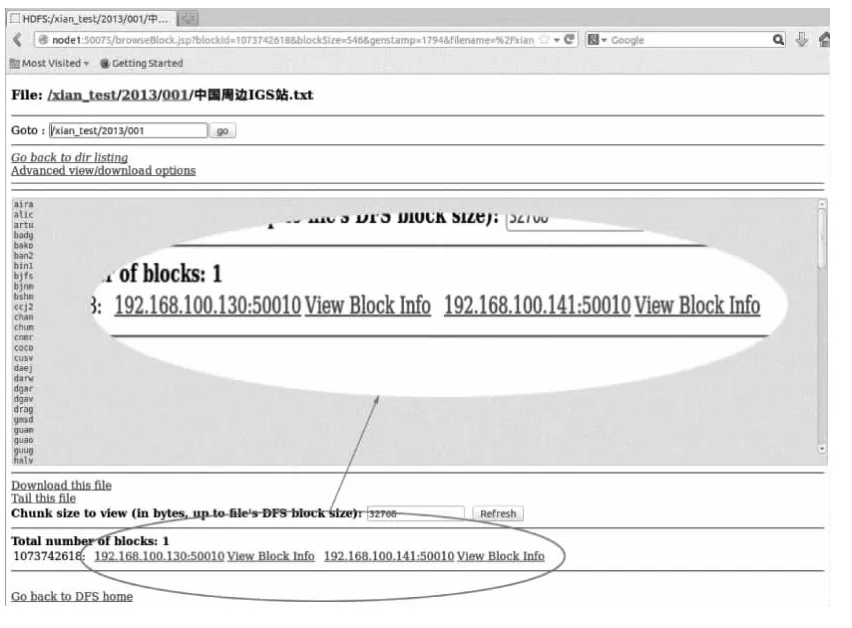
图7 DataNode2节点关闭后文件存储位置
4.3 集群扩展性
随CORS数据量的增长,需要对集群的存储容量和计算能力进行扩充,如图8所示,只需四个步骤即可实现集群扩容。

图8 集群扩容示意图
同时,Ambari作为Hadoop的集群部署与监控集成工具,最多可在1h内安装1 000个节点的存储集群,全部操作采用界面呈现的形式,易于操作,可迅速实现展集群的扩展。
4.4 下载速率
将陆态网2013年前8d的观测数据文件(d文件)合并,压缩后大小约为1Gbit,前16d约为2Gbit,前32d约为4Gbit。分别测试了云存储集群的下载时间和VSFTP(Ubuntu系统下的FTP软件)的下载时间,下载时间取五次下载的平均值,如下图9所示,横轴为数据文件大小,纵轴为下载时间。
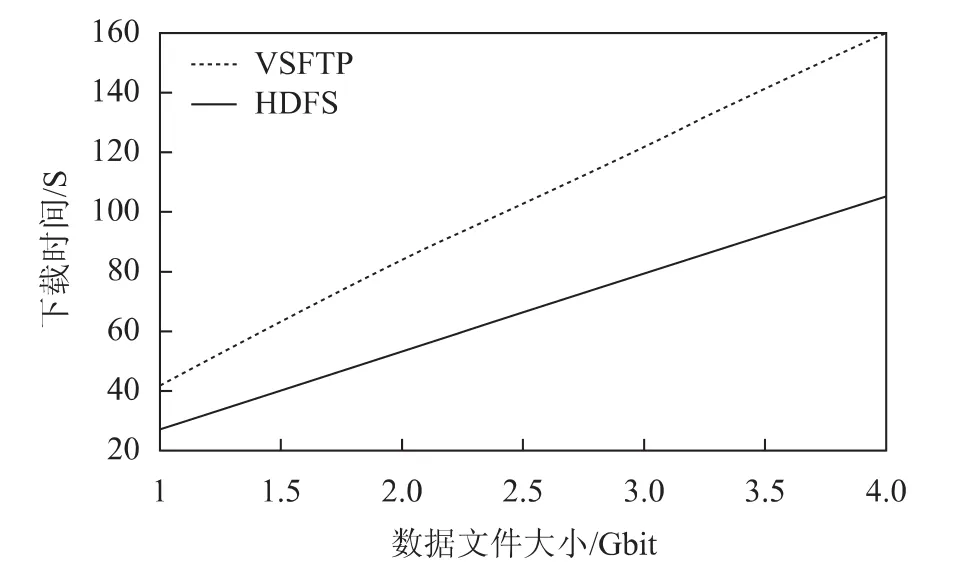
图9 FTP和HDFS的下载时间比对
从上图可以看出,较FTP下载方式,采用支持并发常用的多服务队列机制的云存储下载机制更快,更节约时间。
随CORS数据集群规模的扩大,当存在大量用户进行并发访问请求时,由于云存储突破了单节点访问下载的限制,可以实现网络带宽的最优化利用,从而用户的访问延迟更小,可从最快的存储节点获取CORS数据和产品。
5 结束语
随着国家、区域、行业型CORS的建成及连续观测,CORS数据规模迅速增长,本文对CORS站网的数据量进行了分析,针对当前CORS数据管理系统普遍采用的集中管理策略,指出了其存在的问题;提出了CORS数据云存储,设计了CORS数据云存储集群、组织和访问架构;可将已建成的各个参考站、数据中心纳入到云存储集群中。在虚拟机环境下搭建了Hadoop集群,分析了CORS数据云存储的可靠性、抗灾容错性、扩展性和下载速率。CORS数据云存储突破了传统集中式数据存储技术的局限,可提高CORS数据产品组织、管理和发布的效率和可靠性。云存储为CORS数据分布式计算提供了源数据基础和保障,为用户在线解算提供了基础平台。
[1] 黄俊华,陈文森.连续运行卫星定位综合服务系统建设与应用[M].北京:科学出版社,2009:51-85.
[2] 刘经南,刘晖.建立我国卫星定位连续运行参考站网的若干思考[J].武汉大学学报:信息科学版,2003,28(特刊):27-31.
[3] 陈俊勇.构建全球导航卫星中国国家级连续运行站网[J].测绘通报,2009(9):6-8.
[4] 陈俊勇,张鹏,武军郦,等.关于在中国构建全球导航卫星国家级连续运行站系统的思考[J].测绘学报,2007,36(4):16-19.
[5] 崔阳,吕志平,陈正生.Web Services分布式计算在大规模网平差中的应用[J].大地测量与地球动力学,2013,33(2):136-139.
[6] 谭志彬,戴连君,过静珺,等.GPS连续运行参考站网数据存储[J].测绘通报,2003(11):8-10.
[7] 徐冬晨.基于CORS系统的数据存储的研究[D].南京:东南大学,2010:5-6.
[8] 崔阳,吕志平,陈正生,等.多核环境下的 GNSS网平差数据并行处理研究[J].测绘学报,2013,42(5):661-667.
[9] 岳利群.基于分布式存储的虚拟地理环境关键技术研究[D].郑州:解放军信息工程大学,2011:106-112.
[10] 吕志平,陈正生,崔阳.大型CORS网基线向量的分布式处理[J].测绘科学技术学报,2013,30(4):109-114.
[11] 刘琨,李爱菊,董龙江.基于 Hadoop的云存储的研究及实现[J].微计算机信息,2011,27(7):228-229.
[12] 张龙立.云存储技术探讨[J].电信科学,2010(增刊):77-80.
[13] 周可,王桦,李春花.云存储技术及其应用[J].中兴通讯技术,2010,16(4):29-32.
[14] 晏强,张晓峰,丁蕊.云存储技术研究[J].计算机信息技术,2011(12):26-28.
[15] 唐箭.云存储系统的分析与应用研究[J].电脑知识与技术,2009,5(20):13-14.
[16] 祁芳,林鸿.Ntrip协议在 CORS系统中的应用[J].城市测绘,2008(1):85-88.
[17] DEAN J,GHEMAWAT S.Mapreduce:Simplified Data Processing on Large Clusters[EB/OL].[2014-02-18].http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf.
[18] GHEMAWAT S,GOBIOFF H,LEUNG S T.The Google File System[EB/OL].[2014-02-18].http://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf.
[19] 刘敏,麦耀峰,李冀蕾.Hadoop技术内幕[M].北京:人民邮电出版社,2013:19-28.
[20] 徐文强.基于HDFS的云存储系统研究-分布式架构REPERA设计与实现[D].上海:上海交通大学,2011:13-17.
