大数据下的基于深度神经网的相似汉字识别
2014-01-01杨钊陶大鹏张树业金连文
杨钊,陶大鹏,张树业,金连文
(华南理工大学 电子与信息学院,广东 广州 510641)
1 引言
手写汉字识别技术已取得了较大的进步,然而无约束的手写汉字识别仍然是汉字识别领域有待解决的问题之一[1]。其中影响识别率的一个重要因素是手写汉字中存在大量的相似字,如“夫”,“失”和“天”以及“看”,“着”和“春”等,书写随意性引起的不规则变形更增加了识别的困难。因此,研究相似汉字识别,是提升无约束手写汉字识别率的关键,该问题的研究最近几年引起了广泛关注,例如有学者在梯度特征提取的基础上采用两级手写汉字识别架构来改善系统识别性能[2~4]。第一级采用简单快速的分类器进行粗分类,分类结果需要以很高的概率测试样本的正确类别,即获得相似字表;第二级分类器采用一个速度较慢但性能更好的分类器进行精细分类,即从候选相似字集中挑出正确的标注。Leung针对“相似字对”增加额外的关键区域特征来改善二级分类性能[2],Gao提出利用基于复合距离的线性判别分析(LDA, linear discriminant analysis)增强相似字之间的判别信息[3],Tao首次将流形学习算法引入相似字特征选择,极大地改善了小样本训练情况下相似字识别率[4]。然而上述方法都是在经典的梯度特征提取基础上进行的,且传统的梯度特征提取方法容易丢失相似字之间细微的鉴别信息,这样直接制约着后续特征选择方法以及分类器的性能。
深度神经网(DNN, deep neural network)[5,6]的巨大成功,提供了避免人工设计特征缺陷的方法。深度神经网是一种含有多隐含层且具有特定结构和训练方法的神经网络,受大脑对信息层次处理方式的启发,从低层向上逐层学习更高层次的语义特征,近两年引起了机器学习领域的广泛关注[7]。常见的深度神经网包括由多层受限玻尔兹曼机组成的深度信念网(DBN, deep belief network)[8],以及具有卷积结构的深度神经网(CNN, convolutional neural network)[9]。相对于深度信念网,卷积神经网更适合于二维视觉图像,它直接从原始的像素出发,分布式地提取具有平移和扭曲不变性的特征并实现分类[10]。
卷积神经网是由美国学者 LeCun提出的一种层与层之间局部连接的深度神经网络[9],在许多领域已取得了成功的应用,如手写数字、英文字符的识别等。LeCun提出一种 5层的卷积神经网结构(LeNet-5),相比于传统的神经网络,极大地改进了手写数字的识别率[11]。在 LeNet-5的基础上,Deng[12]、Yuan[13]等人进行输出错误纠正编码改进(outputs with error-correcting codes)分别用于光学字符和大小写英文字母识别。除此之外,研究人员还成功地将卷积神经网用于自然场景中的数字[14,15]和字符识别[16,17],并指出卷积神经网能够学习出优于人工设计的特征。
相比之下,深度卷积神经网在手写汉字上的研究报道非常少,这是因为卷积神经网是一种深层且复杂的网络结构,需要大量的训练样本[18,19]。与英文、数字这一类的问题相比,汉字属于大类别,难以针对每一个字收集到大量样本。然而随着互联网的快速发展,云计算技术普及[20],用户已经能够享受到越来越多基于云计算的服务。本文利用作者所在实验室设计的手写识别云服务平台,在用户授权许可的情况下,通过基于云端服务平台自动获取海量手写数据,使得设计基于大数据的手写识别研究成为可能[21]。
基于上述分析,本文提出了使用具有卷积结构的深度神经网用于相似手写汉字特征学习和识别,如图1所示,相对于传统的方法,它能够有效避免人工设计梯度特征的缺陷。同时采用云平台获取的大数据集更好地训练深度模型,整个系统可以通过以下步骤实现:1)利用第一级分类器生成相似字表;2)利用大量手写样本构成相似字集来训练卷积神经网;3)在云端采用卷积神经网进行精细分类并返回识别结果到客户端。

图1 基于特征提取和基于深度神经网的方法用于相似字识别
2 相似字集生成
2.1 相似字表生成
相似字表生成方法包括基于距离的相似字和基于频度统计的相似字[22]。基于距离的相似方法认为,相似汉字的特征向量模板在特征空间中“距离”也很近。因此选定一个目标汉字集合后,将特征空间中“距离”最近的K个汉字作为其相似字。该方法生成相似字简单,但它仅考虑每一类汉字的平均情况,并不能反映各类字体的变形情况。某些汉字类别的样本离散度很高,此时基于距离的相似字方法有不足之处。所以本文采用基于频度统计的相似字生成方法来进行相似字的生成[22],其基本原理是将目标字的一些样本送入分类器,通过分类器的输出得分排序生成K个候选字。通过统计训练子集中所有汉字的识别结果,计算识别成目标汉字的频率,频率高的汉字类别就是该目标字的相似字。
2.2 相似字样本生成
云计算为手写识别提供了新的应用框架,通过云平台可以建立基于云计算的云手写识别系统[21]。手写汉字识别作为一个服务(HCRaaS, handwritten character recognition as a service)驻留云端,客户端的手写笔迹通过无线网络发送到云服务器,云服务器进行识别并将结果返回给客户端。借助于已有的云手写平台,可以获得大量的手写数据。利用文献[21]所述的手写识别云服务器收集了10组相似字数据,每组10个汉字类别,每个字10 000个样本,从中分别选择2组(G1, G2)书写较工整和2组(G3,G4)书写相对随意的手写汉字样本做对比实验,部分手写样本如表1所示。

表1 相似字集以及相应的手写样本
3 卷积神经网
卷积神经网是一种主要用于二维数据(如图像视频)的深度神经网络模型,可以直接对如原始的图像等处理对象进行特征学习和分类,需要较少的预处理工作,且有效地避免了人工特征提取方法的缺陷。本文采用的卷积神经网通过共享权值和网络结构重组将特征学习融入到多层神经网络中,同时使得整个网络可以通过反向传播算法得到很好的训练并用于分类。卷积神经网由卷积层和采样层交替组成,每一层都由多个特征图(feature map)组成,如图 2所示。卷积层的每一个像素(神经元)与上一层的一个局部区域相连,可以看做一个局部特征检测器,每个神经元可以提取初级的视觉特征如方向线段、角点等。同时这种局部连接使得网络具有更少的参数,有利于训练。卷积层后面通常是一个采样层,以降低图像的分辨率,同时使得网络具有一定的位移、缩放和扭曲不变性。
对于卷积层,前一层的特征图与多组卷积模板进行卷积运算然后通过激活函数得到该层的特征图,卷积层的计算形式如下
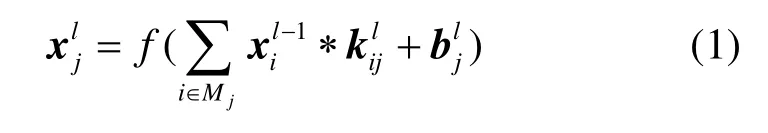
其中,l代表卷积层所在的层数,k是卷积核,通常是 5×5的模板,b为偏置,f代表激活函数,为1/(1+e-x),Mj表示上一层的一个输入特征图。
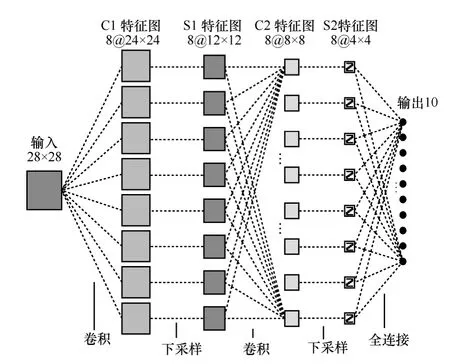
图2 卷积神经网结构
采样层就是对上一卷积层的特征图做下采样,得到相同数目的特征图,计算形式如下
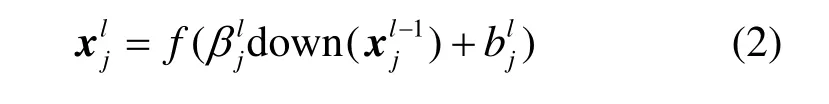
其中,down(·)表示下采样函数,β表示下采样系数,同样b为偏置,f为激活函数1/(1+e-x)。
卷积神经网采用误差反向传播来训练,训练的参数包括卷积层的卷积核模板k和偏置b,以及采样层的采样系数β(本文中取常量0.25)和偏置b。卷积神经网与传统的神经网络训练一样,采用随机梯度下降。设误差函数为:E(k,β,b),则网络训练的实质就是梯度∂E/∂k、∂E/∂β、∂E/∂b的计算,具体推导过程见文献[23]。
本文采用的卷积神经网如图2所示,输入层是28×28手写汉字图像。C1层是第一个卷积层,该层有8个24×24的特征图,每个特征图中的一个像素(节点或神经元)与输入层相对应的一个 5×5的区域相互连接,共(5×5+1)×8=208个训练参数。S1层是含有8个大小为12×12特征图的下采样层,特征图中的每一个节点与C1层中相应的特征图以2×2的区域相互连接,共 1×8=8个偏置参数。C2是第 2个卷积层,具有8个特征图且每个特征图的大小为8×8,共(5×5+1)×8×8=1 664 个参数。S1 与 C2 层的连接在特征提取中取了重要的作用。S2是第2个采样层,具有8个特征图且每个特征图的大小为4×4,共1×8=8个偏置参数。最后一层是含有10个节点的输出层,对应着输出类别,与S2层进行全连接,共 4×4×8×10=1 280个参数。整个 CNN 模型含有208+8+1 664+8+1 280=3 168个参数。
4 实验结果及分析
4.1 实验数据
对于从云平台上整理得到的相似手写汉字数据,考虑到汉字书写的随意程度直接影响着最终的识别率,本文分别选择2组书写较工整和2组书写相对随意无约束的手写汉字样本进行对比实验。每一组相似字包含10个汉字类别,每个汉字有10 000个样本。表1列出了该4组相似字以及相应的手写样本,其中G1、G2书写相对工整,G3、G4书写相对随意。
为了验证卷积神经网在相似字识别中的性能,将卷积神经网与基于特征提取的支持向量机(SVM,support vector machine)和最近邻分类器(1-NN,1-nearest neighbors)进行对比。对于SVM和1-NN,首先将所有样本转化为64×64的脱机图像,然后提取梯度特征[24],得到每个样本为512维的特征向量。而对于CNN,将手写数字图像直接压缩到28×28,这样减少CNN的参数,从而提高训练速度。
4.2 实验结果
实验采用如图2所示的卷积神经网结构,采用Liblinear[25]用于SVM分类实验,1-NN采用最小欧氏距离进行分类。为了分析 CNN的性能并考虑到训练样本对分类结果的影响,实验中分别使用了不同大小的训练样本做对比实验(“Tr-Ts”分别表示每个字的训练样本和测试样本个数)。表 2中列出了几种方法的错误识别率,其中最后一列“错误率减少”指标是指本文所提出的CNN方法相对1-NN和SVM的错误率下降的百分比。
相似字识别作为手写汉字识别系统的一个重要部分,其模型运行速度以及存储量大小值得考虑。实验中以“Tr-Ts”分别为1 000~200和3 000~200的情形下所有测试样本(10类汉字,所以测试样本大小均为2 000)的分类时间来评估算法的运行速度(实验机器,Intel i7-2600 CPU, 3.4 GHz, 16.0 G RAM),以模型的参数个数来计算模型的存储量。统计结果如表3所示。
4.3 实验结果分析及讨论
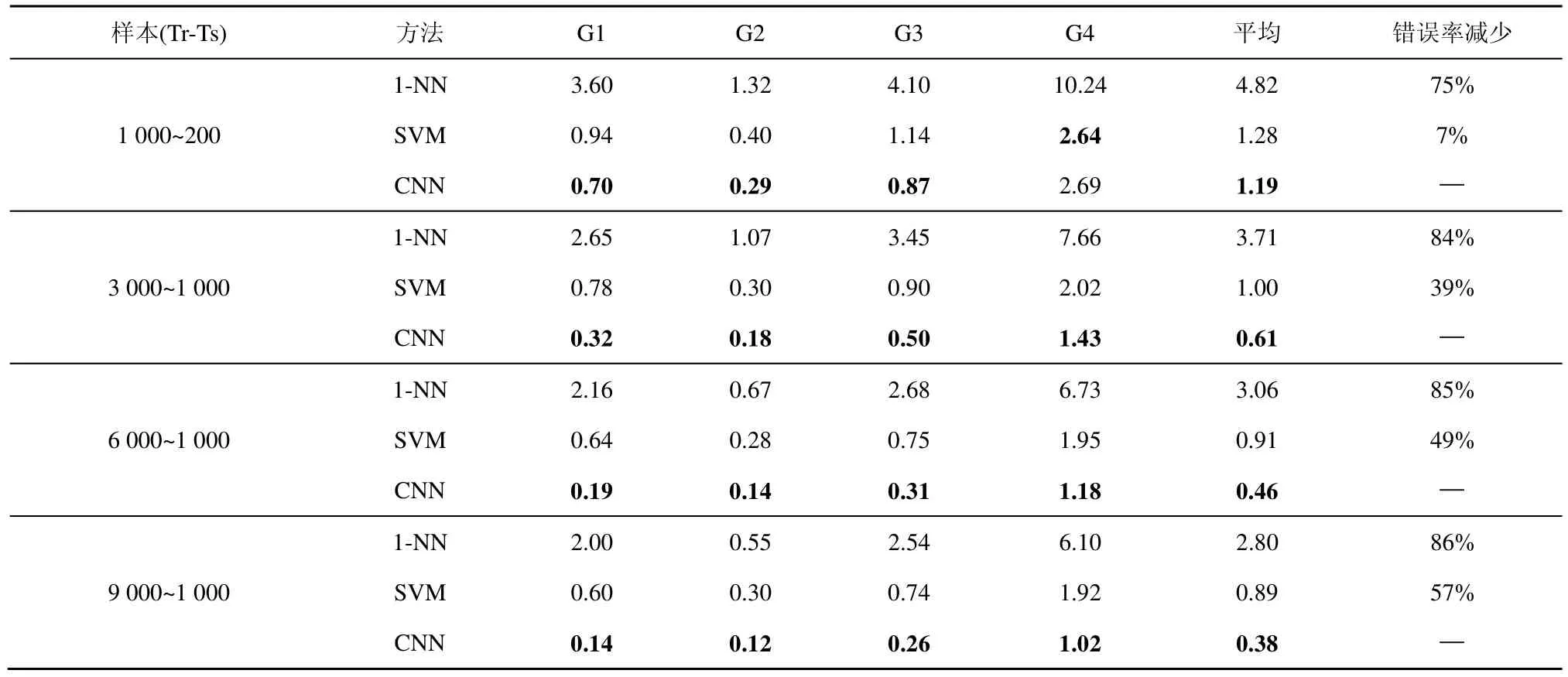
表2 几种方法错误率对比实验结果
对比表2中的数据,当训练样本增加时,1-NN、SVM、CNN的错误率都整体下降,且本文采用的CNN模型具有更低的错误率。特别是在书写较为随意的情况下,随着训练样本的增加,CNN错误率下降更为明显。这表明大数据对深度卷积神经网络的性能提升是十分关键的,因为随着样本的增加,CNN能够更好地进行分布式的深度学习,自动学习特征并进行分类。SVM和1-NN性能较差的原因是在特征提取过程中丢失了细微的鉴别信息,相比而言,1-NN的识别性能最差,这主要是因为1-NN分类器是基于欧氏空间距离最小的假设,然而实际特征空间并不完全与欧氏空间一致。
从表3可以看出,在运算效率方面SVM最优,CNN其次,这是因为CNN是一种深层的神经网络,而SVM是一种两层的浅层网络结构,且SVM所用的输入特征(512维)比 CNN所用的输入特征(28×28=784维)维数要明显低。相比之下,1-NN最慢,且1-NN会随着训练样本的增加变得更慢,其中SVM和CNN都在合理的时间范围内;在存储量上,线性SVM的参数主要由特征维数和类别数决定(512×10=5 120),相比之下CNN存储量更低,有明显的优势。
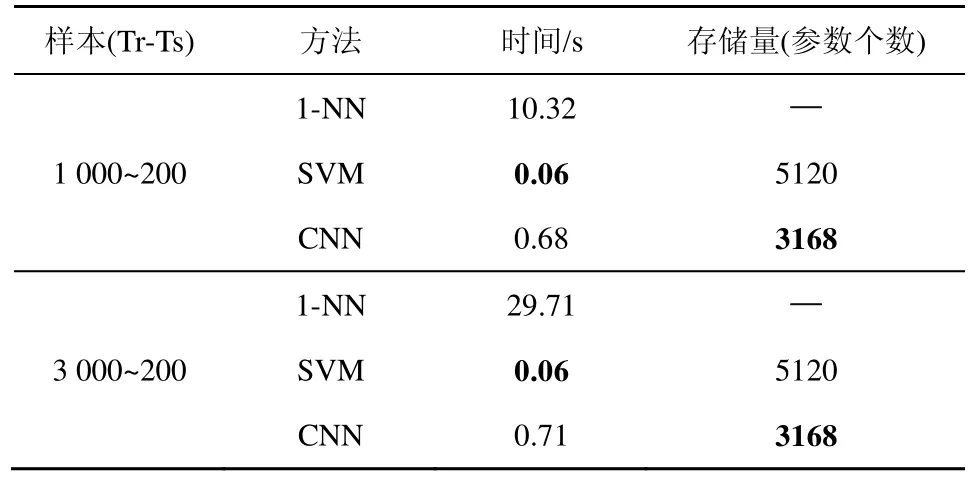
表3 几种方法运算效率(每2 000个汉字)与存储量对比
为了进一步分析CNN的性能,图3给出G3组相似字在每个字训练样本为1 000、测试样本为200、和训练样本为3 000、测试样本为1 000时的训练误差、训练集错误率、测试集错误率曲线。可以看出,CNN在相似字识别上具有较好的性能,随着迭代次数的增加,训练误差减少的同时,训练集和测试集的错误率均平稳下降,没有出现过拟合现象。
5 结束语
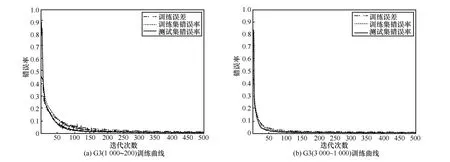
图3 卷积神经网的训练误差、训练集错误率和测试集错误率曲线
本文提出利用深度卷积神经网自动学习相似手写汉字特征并进行识别,同时采用相似汉字的大数据集来训练模型参数以进一步提高识别率。实验结果表明,相比传统方法而言:1) 深度卷积神经网能够自动学习有效特征并进行识别,避免了人工设计特征的缺陷;2) 随着训练数据的增大,深度卷积神经网在降低错误识别率方面表现得更为显著,大数据训练对提升深度神经网络的识别率作用明显;3) 深度神经网应对书写随意性的能力强,在汉字书写较随意的情况下,有较好的识别结果;4) 与SVM相比,深度神经网在保证合理的运算效率的同时,存储量指标有较大优势。
[1] LIU C L, YIN F, WANG Q F,et al. ICDAR 2011 Chinese handwriting recognition competition[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C]. Beijing, China,2011. 1464-1469.
[2] LEUNG K C, LEUNG C H. Recognition of handwritten Chinese characters by critical region analysis[J]. Pattern Recognition, 2010,43(3): 949-961.
[3] GAO T F, LIU C L. High accuracy handwritten Chinese character recognition using LDA-based compound distances[J]. Pattern Recognition, 2008, 41(11): 3442-3451.
[4] TAO D P, LIANG L Y, JIN L W,et al. Similar handwritten Chinese character recognition by kernel discriminative locality alignment[J].Pattern Recognition Letters, 2014, 35(1): 186-194.
[5] BENGIO Y. Learning deep architectures for AI[J]. Foundations and trends in Machine Learning, 2009, 2(1):1-127.
[6] BENGIO Y, COURVILLE A. Deep Learning of Representations[M].Handbook on Neural Information Processing. Springer Berlin Heidelberg, 2013.
[7] DENG L, HINTON G, KINGSBURY B. New types of deep neural network learning for speech recognition and related applications: an overview[A]. Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing[C]. Vancouver, Canada,2013.
[8] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[9] LECUN Y, BOSERB, DENKER J S,et al. Handwritten digit recognition with a back-propagation network[A]. Advances in neural information processing systems[C]. Denver, United States, 1990. 396-404.
[10] LECUN Y, KAVUKCUOGLU K, FARABET C. Convolutional networks and applications in vision[A]. Proceedings of IEEE International Symposium onCircuits and Systems[C]. Paris, France, 2010.253-256.
[11] LECUN Y, BOTTOU L, BENGIO Y,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324.
[12] DENG H, STATHOPOULOS G, SUEN C Y. Error-correcting output coding for the convolutional neural network for optical character recognition[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C].Barcelona, Spain, 2009.581-585.
[13] YUAN A, BAI G, JIAO L,et al. Offline handwritten English character recognition based on convolutional neural network[A]. Proceedings of IAPR International Workshop on Document Analysis Systems[C].Gold Cost, QLD, 2012. 125-129.
[14] NETZER Y, WANG T, COATES A,et al. Reading digits in natural images with unsupervised feature learning[A]. NIPS Workshop on Deep Learning and Unsupervised Feature Learning[C]. Granada, Spain,2011.
[15] SERMANET P, CHINTALA S, LECUN Y. Convolutional neural networks applied to house numbers digit classification[A].Proceedings of IEEE International Conference on Pattern Recognition[C].Tsukuba,Japan, 2012. 3288-3291.
[16] COATES A, CARPENTER B, CASE C,et al. Text detection and character recognition in scene images with unsupervised feature learning[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C]. Beijing, China, 2011. 440-445.
[17] WANG T, WU D J, COATES A,et al. End-to-end text recognition with convolutional neural networks[A]. Proceedings of IEEE International Conference on Pattern Recognition[C].Tsukuba, Japan, 2012.3304-3308.
[18] SIMARD P, STEINKRAUS D, PLATT J C. Best practices for convolutional neural networks applied to visual document analysis[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C]. Edinburgh, UK, 2003.958-963.
[19] CIRESAN D C, MEIER U, GAMBARDELLA L M,et al. Convolutional neural network committees for handwritten character classification[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C]. Beijing, China, 2011. 1135-1139.
[20] VAQUERO L M, CACERES J, MORAN D. The challenge of service level scalability for the cloud[J]. International Journal of Cloud Applications and Computing (IJCAC), 2011, 1(1):34-44.
[21] GAO Y, JIN L W, HE C,et al. Handwriting character recognition as a service: a new handwriting recognition system based on cloud computing[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C]. Beijing, China, 2011. 885-889.
[22] LIU Z B, JIN L W. A static candidates generation technique and its application in two-stage LDA Chinese character recognition[A]. Proceedings of Chinese Control Conference[C]. Hunan, China, 2007.571-575.
[23] BOUVRIE J. Notes on Convolution Neural networks[R]. MIT CBCL,2006.
[24] BAI Z L, HUO Q. A study on the use of 8-directional features for online handwritten Chinese character recognition[A]. Proceedings of IEEE International Conference on Document Analysis and Recognition[C]. Seoul, Korea, 2005. 262-266.
[25] FAN R E, CHANG K W, HSIEH C J,et al. LIBLINEAR: a library for large linear classification[J]. The Journal of Machine Learning Research, 2008, 9: 1871-1874.
