基于语料库的高校网页英文简介对比研究
2013-11-15程张根
程张根,何 琼
(武汉科技大学 外国语学院,湖北 武汉430081)
随着国际交流日趋频繁和我国文化软实力提升,越来越多的国内高校都在网站增设了英文界面。其目的主要是加强对外宣传,提高国际知名度,寻求合作办学,促进学术交流与合作。尤其是对于一些知名大学来说,英文网站不仅是有意来校深造的国外学生了解本校的窗口,也是向海外科研机构及学者传达信息的主要方式。
一、基于高校简介语料库的对比研究
(一)研究问题
本研究拟通过对比分析国内外高校英文简介的词汇难度、词频、词块、主题词、词性分布等措辞特征,以回答如下问题:中国财经类知名高校与商科排名靠前的英语国家高校的英文简介在词汇层面上各自有何特征,这些词汇特征有何语篇意义,其背后原因是什么。
(二)语料库建设
为了回答上述问题,笔者自建了两个语料库即中国高校简介语料库 AUMC(About University in Mainland China)和英语国家高校简介语料库 AUEC(About University in English-speaking Countries),各含20所高校的英文简介文本,均采自各高校校园网英文版的类似“About the University”部分。本研究将对象锁定为财经类高校,国内高校选取各种排名靠前的 20所财经类高校,包括上海财经大学, 中央财经大学等;因国外少见中国式的财经类大学,故国外高校选取2011年度QS经济类专业世界排名的前25位高校,包括哈佛大学,麻省理工等,但是只保留以英语为母语国家的20所高校,剔除东京大学等本族语为非英语的国家高校,以保证语料库语言的纯正性和地道性。
(三)研究工具
词汇难度分析工具采用AntWordProfiler,该软件的基本原理是“将某一个文本中的词汇与某一词汇表进行比较,通过观察哪些词出现或未出现在该词汇表中以及出现在该词汇表中词汇的比率,就可以知道该文本的用词情况了”(凤群,2011)。AntWordProfiler内置了三个词汇表,这三级词汇表代表了英语中出现频率较高的词汇,每一级词汇难度递增。运行该软件,它会将所分析的文本中的词汇与上述三级常用词汇表做比较,用以衡量文本的词汇难度。文本可读性分析采用中国外语教育研究中心的许家金博士与贾云龙老师研发的 Readability Analyzer。该软件能统计文本的词次、词形、词目、平均词长、平均句长,并提供文本易度、难度、水平等数据。测试结果表明(侯广旭等,2009),在文体、题材、风格相近的情况下,尤其是对于说明文和论述文体,该软件对文本难度分析的结果具有较强的真实性。此外,本研究使用 AntConc对词频、词块、主题词、词性分布等词汇特征进行研究。AntConc具有生词词表,词块,提取主题词和索引等多项词汇分析功能,信度效度已得到语言学界的普遍认可。AntWordProfiler和AntConc均由日本早稻田大学Antony教授研发,二者皆为免费软件。
(四)研究方法
本研究首先使用 AntWordProfiler和 Readability Analyzer量化分析比较两个语料库的用词难度和文本可读性(难度),用以对国内外高校简介的文本特征进行分析和比较。其次,利用 AntConc生成词表和词块表,用以分析比较两个语料库的重点信息有何差异;然后,借助AntConc生成主题词表,考察两个语料库的主题差异;最后,对两个语料库进行词性赋码,借助AntConc的词表和索引行功能揭示两个语料库的词性分布,句法特征以及主题差异。
二、数据分析与讨论
(一)文本特征对比分析
1. 总体文本特征
利用 AntConc的词表功能可以得出两个语料库的形符数和类符数,据此可以计算出标准化类符/形符比。如表 1所示,AUEC形符数为 6051,AUMC形符数达到11708,说明中国高校英文简介的平均篇幅明显大于国外高校简介,字数相差近一倍。国外高校简介特点是简明扼要,重点突出,浏览原始网页发现,次要信息常通过超链接等形式进行补充说明;而中国高校多半将所有信息不分轻重缓急以一篇文本的形式进行罗列,追求大而全,容易使读者产生阅读倦怠和信息迷失,不利于重点信息的传达。从标准化类符/形符比来看,AUEC和AUMC分别是45.33和42.55。标准化类符/形符比常用来衡量语料库的词汇密度,而“词汇密度在一定程度上反映出文本用词的多样性”。由此可以推断中国高校简介用词变化较小,不如国外高校简介用词丰富。
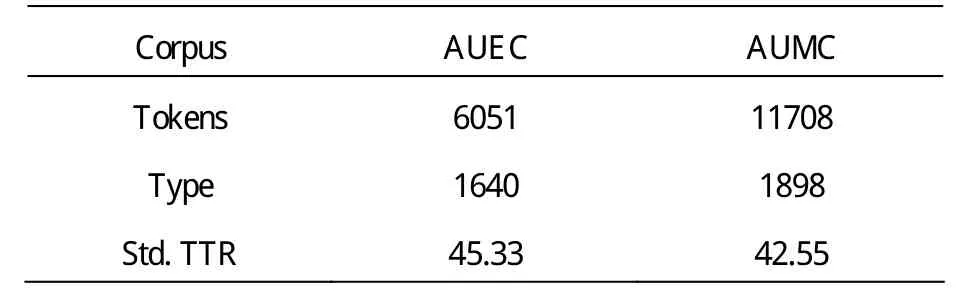
表1 国内外高校简介语料库的总体文本特征
2. 词汇难度
借助AntWordProfiler,分别得出国内外高校简介用词难度的量化数据,结果如表2。
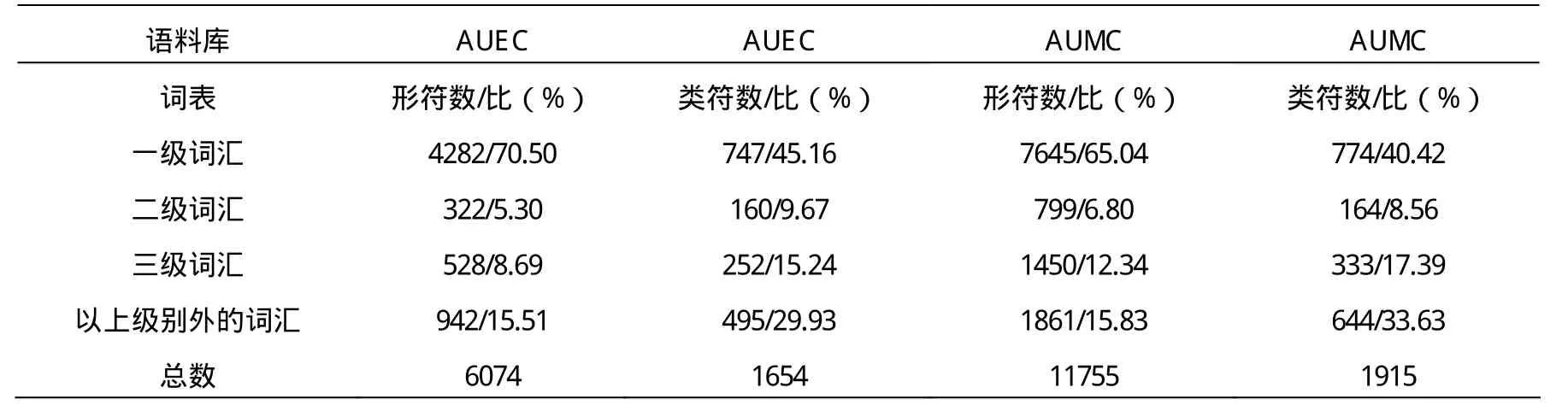
表2 国内外高校简介的词汇难度
如表2所示,AUEC文本中一级词汇形符数为4282,类符数为747,分别占总词数的70.50%和45.16%。AUMC文本中一级词汇形符数为7645,类符数为774,分别占总词数的65.04%和40.42%。可以看出,无论从形符数还是类符数来看,代表难度系数最低的一级词汇在国外高校简介中比例均高于中国高校简介(相差约 5个百分点),即国外高校简介中用的简单词汇比例更大。以同样的方法对二级词汇、三级词汇以及不在这三级的词汇进行分析,得出结论:二级词汇,两个语料库差别不大;代表难度系数较大的三级词汇以及不在这三级的词汇在国外高校简介中比例明显低于中国高校简介,即国外高校简介中使用的高难词汇比例较小。总而言之,与国外高校相比较,中国高校简介中使用的词汇偏难、用词更正式。
3. 文本难度(可读性)

表3 国内外高校简介文本可读性参数
表3显示,AUEC的易读性指数(Reading Ease)为23.50,而AUMC为10.00,可见国外高校简介阅读起来更为舒适,换言之,其文本综合难度低于中国高校简介文本。易读性指数是基于平均词长、平均句长、标准化词目/形符比等参数得出来的。从Flesch-Kincaid等级水平(Grade Level)来看,AUMC(17.30)大于 AUEC(15.10),即中国高校简介文本的阅读难度系数更高,这主要是基于文本的平均词长(AWL)和平均句长(ASL)决定的。中国高校简介平均词长和平均句长都大于国外高校简介,尤其是平均句长的差异(27.50:20.70)从某种程度上反映出中国高校简介遣词造句的复杂。就标准化词目/形符比(Lemma STTR)来看,AUMC(0.17)小于AUEC(0.24),说明中国高校简介用词丰富度偏低,即用词单一,不如国外高校简介灵活多变,这与前文标准化类符/形符比得出的结论一致。
(二)词(块)表对比分析
1. 词表
词表是一个语料库的高频词列表,即语料库文本大篇幅使用到哪些词汇,重点传达出什么样的语篇信息。运行AntConc,依次生成两个与语料库的词表。AUEC 的前 20 个高频词汇依次为:the,and,of,in,a,to,university,students,is ,’s,for,its,are,as,research,world,with,by,on,that,at,from,all,campus,an,was,teaching,one,more,than。AUMC的前20个高频词汇依次是:and,the,of,in,university,a,to,research,economics,has,is,for,with,students,as,are,education,’s,finance,school,center,china,level,management,programs,by,over,its,key,international。两个语料库的前20高频词汇大部分相同或类似,尤其是功能词,实词部分重复的是 university,student和 research,说明国内外高校简介都重视招生和科研。划线部分词汇为两个语料库之间不重复的实词。国外高校简介中高频实词是world, campus和teaching,参照索引行,能发现国外高校在篇幅有限的简介中注重强调自身的世界顶尖级别,重视介绍教学和校园建筑特色和配套服务。国内高校则强调自身在经济学(economics)、金融学(finance)和管理(management)等学科中的优势。因为所选的国内高校都是财经类大学,而国外高校多是综合性大学,所以这不难理解。此外,国内高校还习惯在简介中罗列下属各个学院(school)以及各种合作办学项目(program),尤其是国际性的(international)。
2. 词块
比较不同文本试图传达的重点信息有何差异,除了观察高频词表,还可以分析高频词块。使用AntConc的N元组(N-Gram)功能,分别提取两个语料库的高频三词词块(3-Gram)。AUEC 的前20个高频词块依次为:one of the,the world ’s,The University of,undergraduate and graduate,the University ’s,ANU College of,of the University,of the world,the University of,around the world,world ’s leading,both undergraduate and,is one of,members of the ,research and teaching,teaching and research ,the United States,University of California,University of Chicago,as well as。AUMC的前20个高频词块依次是:of Finance and,Ministry of Education,the Ministry of,Finance and Economics,one of the,University of Finance,as well as,by the Ministry,economics and management,of Economics and,the university has,In recent years,’s degrees in,an area of,of the top,the State Council,is ranked No,of Applied Sciences,Research Institute of,University of Applied。同词表分析一样,能凸显信息差异的词块分别标注下划线,然后参照索引行进行分析总结。得出结论是,国外高校普遍惯于交代自己是世界级名校(the world ’s,around the world,world ’s leading,),拥有院士级别的教授(members of the)和强大的教学和科研实力(research and teaching,teaching and research)。国内高校大篇幅强调自身在财经类学科方面的优势(Finance and Economics,economics and management),具备授予各种学位的资质(’s degrees in),近些年(In recent years)取得的各种成就和荣誉,以及学校校区面积(an area of)等。尤其值得注意的是,国内高校普遍热衷强调自身与政府各级行政机构的隶属关系(Ministry of Education,the State Council),以此彰显自己的实力和地位。这与中国高校的教育体制密切相关。
(三)主题词对比分析
基本词表统计能提供一个语料库文本的词语频率和分布信息,却难以说明词语在语境中的用法与词语之间的关系;而“主题词统计能提供语篇层面词语的分布与文本主题的关系以及词语之间的关系”[6]。为了揭示两个语料库文本的主题差异,本研究进行了主题词对比分析。由于AUEC和AUMC两个语料库属于可比语料库,即主题和体裁相同,而且后者库容相当于前者的近两倍,因此本研究中将AUEC作为观察语料库,将AUMC作为参照语料库,利用 AntConc的主题词功能同时生成正负关键词表。其中,正关键词表是指在国外大学简介中出现频率明显高于中国大学简介的词汇,负关键词表所列词汇在中国大学简介中出现频率显著高于国外大学简介。限于篇幅,本研究截取关键性值keyness大于10的关键词进行分析讨论。
从词义角度分析,正关键词表的词汇主要分六大类:(1)国外高校校名,如ANU,Oxford,Berkeley等;(2)与学习相关的词汇,如knowledge,intellectual,discovery,scholarship;(3)配套设施和服务方面,如accommodation,museum,service等;(4)体育运动,如athletic,sport;(5)学术文化特征,如original,diverse等;(6)女性(女学生),women;(7)其他,如 community,opportunities等。由于正关键词表反映的是国外高校简介的主题特色,可以看出:有别于中国高校,国外高校在简介中内容侧重学习和学术,强调学生对未知的探索和发现;除了学术科研,高校亦注重自身对社会社区的服务功能,将服务社会视为办学宗旨中不可或缺的组成部分。此外,简介中务实地介绍学校食宿、体育运动设施、奖学金、各种成长成才机会、文化的多元性、甚至男女平等理念,以“人性化”的设施、服务和理念吸引莘莘学子前来就读。
负关键词主要分以下六大类:(1)专业设置,如economics,management,business,administration,disciplines等;(2)学校级别和档次,如 key,level等;(3)师资力量,如teacher,professor等;(4)学位,如doctoral,master等;(5)下设研究所,如 institute,center;(6)学校的发展,如development。参照索引行,可以推断:与国外高校相比较,中国高校简介的主题特色在于详细介绍所设专业和学位授予权,强调学校在政府机构的级别和师资力量(尤其是教授比例),以此彰显自身实力。
(四)词性分布对比分析
使用tree tagger对两个语料库进行自动词性赋码,然后分别加载两个赋码语料库到AntConc,利用其词表功能对高频词性进行排序。通过观察对比两个语料库的高频词性的差异,并借助索引行可以窥探国内外高校简介使用词汇手段来传达语篇意义的差异,统计结果见表4。

表4 国内外高校简介中词类频次及千分率

续表4
如表4所示,AUEC的高频词性依次为:专有名词,名词单数,介词,名词复数,形容词,限定词,并列连词,基数词,过去分词,副词,现在分词,三单,人称代词,has,am/is,are,动词原形,所有格,过去式,比较级,关系代词,was/were。AUMC的高频词性依次是:名词单数,介词,专有名词,限定词,形容词,名词复数,并列连词,基数词,副词,过去分词,人称代词,动词原形,过去式,现在分词,am/is,三单,are,所有格,动词复数,关系代词,比较级,was/were 。表4中,两个语料库出现比例差别较大的词性词类分别加粗并标注下划线,可以看出:相比较而言,国内高校简介较多使用专有名词,基数词,has;国外高校简介更多使用人称代词,动词原形和动词过去式。
(1)专有名词。AUMC的专有名词使用率明显高于AUEC,说明中国高校简介中专有名词使用比国外高校明显更多、更频繁。观察索引行发现,国内外高校简介中均使用专有名词表示“校名,学校地理位置,下设的科研机构,与知名学术团体的关系”等,但中国高校简介中专有名词还大量表示“学校下设院系、专业和科研机构,与政府行政部门的关系,国家领导人名字,荣誉奖项”, 凸显出鲜明的“高校管理行政化”特征,而国外高校简介中的专有名词少见或未见传达这些信息。
(2)基数词。AUMC的基数词使用率明显高于AUEC,说明较国外高校,中国高校简介更多、更频繁地采用量化数据介绍学校信息。通过观察索引行发现,国内高校使用基数词主要用来介绍学校重点学科、一级或二级学科数目,硕士点或博士点数量,学校面积,教师(尤其是教授)数量,学生人数,下设学院或研究中心数量,藏书数量。不同的是,国外高校的简介中出现的数字主要是年份,用以介绍校史,学校重大事件发生的年份。
(3)Has。通过对索引行的观察,发现国内外高校简介中 has的主语基本上都是校名或指代校名的第三人称代词“it”。区别在于国内高校更多使用第三人称视角进行自我介绍。
(4)人称代词。AUEC的人称代词使用比例是AUMC的两倍(22:11),说明国外高校简介中更多采用人称代词。载入赋码语料库,使用 AntConc的单词列表功能,在检索项输入“*_PP”,发现两个语料库均使用到“Its,it,their,them,itself”等介词。不同的是,AUEC还普遍使用“we,our,you”,据此可以初步推断国外高校简介中惯于使用第一人称的叙事视角。为了明确国内外高校简介中第一、二人称代词使用频率的差异,利用AntConc的索引行功能,输入检索项“we|our|you|us|your|yours|ours”,发现AUEC出现23次,AUMC出现9次。借助SPSS16.0进行卡方检验,得出卡方值 Chi-Square=93.9670,P=0.000,可见两个语料库中第一、二人称代词的出现频率的差异具有统计学意义上的显著性。说明,较中国高校,国外高校在简介中明显更多使用第一人称的叙事视角,叙述过程中暗示受众 you的存在,强调互动,注重与读者建立起亲近的关系,拉近大学与读者之间的心理距离。
(5)动词原形和动词过去式。AUEC动词原形和过去式的使用率明显高于 AUMC。观察索引行发现,两个语料库的动词原形主要用于“情态动词+动词”和动词不定式两种结构,用法差异不大。从语义角度分析,AUEC中动词过去式主要用来描述学校历史变迁,如founded,established,became等;而AUMC中动词不定式比例较少,并侧重于表述学校获取的各种成就,如 achieved,awarded,ranked等。
三、结论与启示
借助语料库的各种统计手段,研究发现,国内外高校英文简介的用词差异主要体现在三个方面,即文本特征,语篇信息和叙事视角。文本特征方面,中国高校简介篇幅更大,用词更难,句子更长,结构也更为复杂,文本难度更大;国外高校简介短小精悍,用词难度和句长适中。语篇信息方面,中国高校简介中惯于详细地列举各种教科研信息,如下设院系、学科、专业、硕士点或博士点、科研机构、教授比例乃至所获的各种荣誉奖项,而且一再强调自身与官方、政府机构的关系,如211院校、省级重点专业等,以此说明自己的实力和地位;国外高校侧重介绍自身和社会、社区的紧密联系,鼓励学生对未知的探索,并提供食宿、体育运动设施、奖学金、各种成长成才机会、文化的多元性、甚至男女平等理念等“人性化”信息,借此打动和吸引学生前来求学。叙事视角方面,中国高校简介主要采用第三人称叙事视角,刻板地描述各种信息;国外高校惯于采用第一人称的叙事视角,注重拉近与读者的距离,文本偏向“促销”体裁。
高校英文简介,乃至其他的英文外宣材料都是功能性很强的文本。由于国内高校的英文简介主要源于对中文版本的翻译,因此建议翻译时以国外高校简介为平行文本,做到译文符合目的语读者的思维习惯,认知特点甚至兴趣偏好。利用各种免费的语料库工具,可以深度挖掘文本潜在的单词、句子、语篇、信息等层面的特点,帮助研究者准确、高效地把握平行文本的特征,以便更好仿照平行文本进行翻译,提高翻译的质量和效率。
[1]Hunston, S.Starting with the small words: patterns,lexis and semantic sequences[J]. International Journal of Corpus Linguistics,2008, (3): 271~295.
[2]陈隽,黄玉虹. 高校英文网页的翻译失误探析---以福建重点本科院校为例[J]. 福建农林大学学报, 2012,(6).
[3]凤群. 基于语料库的中美大学生英语演讲词汇特征研究[J]. 合肥工业大学学报, 2011,(2).
[4]郭虹字.中国大学介绍辞汉英翻译原则研究… 评部分“211工程"大学网站英译[D]. 南京:杭州:浙江工商大学,2010.
[5]侯广旭,等. 用ReadabilityAnalyzer1.0 分析《大学英语综合教程》课文难度的循序渐进性[J]. 考试周刊,2009,(41).
[6]李文中. 基于英语学习者语料库的主题词研究[J]. 现代外语,2003,(3): 283-293.
[7]梁茂成,等. 语料库应用教程[M]. 北京:外语教学与研究出版社,2010.
[8]杨惠中. 语料库语言学导论[M]. 上海:上海外语教育出版社,2002.
