基于决策树方法的糖尿病并发症分类研究*
2013-11-07聂斌林剑鸣杜建强王卓何万生叶青熊玲珠朱明峰李智彪吴友平
★ 聂斌 林剑鸣 杜建强*** 王卓 何万生 叶青 熊玲珠 朱明峰 李智彪 吴友平
(1.江西中医学院南昌 330006;2.南昌大学软件学院 南昌 330047;3.江西省峡江县水边卫生院 331409)
1.引言
决策树[1-2]是用于分类和预测的一种类似于流程图的树结构。决策树学习是以实例为基础的归纳学习算法。它着眼于从一组无序、无规则的实例中推理出决策表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较并根据不同属性判断从该结点向下的分支,在决策树的叶结点得到结论。从根结点就对应着一条合取规则,整棵树就对应一组析取表达式。其分类研究及应用如[3-9]。其特点是分类速度快,计算量相对较小,容易转化成分类规则;分类准确性高且便于理解。其缺乏伸缩性,处理大训练集时算法的额外开销大,降低了分类的准确性;一般的算法分类时,只根据某个字段来分类;当类别过多时,错误可能就会较快增加。
2.决策树方法C5.1、CART、QUEST、CHAID简介
2.1 C5.1
C5.1模型(PASW Modeler helptext)的工作原理:根据提供最大信息增益的字段分割样本,并递进分割由上次分割定义的每个子样本,直到无法分割为止。重新检查最底层分割,并删除或修剪对模型值没有显著贡献的分割。
规则集源自决策树,并且在某种程度上表示在决策树中建立的经简化或提取的信息版本。通常,规则集可保留完整的决策树中的大部分重要信息,但其使用的模型比较简单。其与其它决策树最重要的区别是,使用规则集时,可以为任意特定记录应用多个规则,也可以不应用任何规则。其优点:对有缺失数据和输入字段较多的问题时非常稳健;通常训练次数不是很长则可进行估计;模型易于理解,规则可直观解释。
2.2 CART
CART分类和回归树(PASW Modeler helptext)节点是一种基于树的分类和预测方法。其原理:使用递归分区将训练记录分割为具有相似输出字段值的段,通过检查输入字段找到最佳分割来启动CART树,并根据由分割导致的纯度指数降低情况进行测量。分割可定义两个子组,每个子组递归被分割为两个子组,直到触发其中一个停止标准为止。其优点可自动选择对目标变量有贡献的属性变量;对有缺失数据和输入字段较多的问题时非常稳健;估计模型通常训练时间不长;推理过程完全依据属性变量的取值特点;根据目标是定类变量和定距变量分别为分类树和回归树。
2.3 QUEST
QUEST(PASW Modeler helptext),是一种用于构建决策树的二元分类法。此方法的主要目的是:减少包含很多变量或观测值的大型CART分析所需的处理时间,连续预测变量或具有多个类别的预测变量。QUEST与CART和CHAID都不同的是,在评估预测变量以供选择时不会检验类别组合,因此可加快分析的速度。通过使用由目标类别形成的组中选定的预测变量来运行二次判别分析可以确定分割。使用此方法可再次使速度较穷举搜索(CART)得到提高以便确定最优分割。优点:运算过程比CART更简单有效,QUEST节点可提供用于构建决策树的二元分类法,可减少处理时间等。
2.4 CHAID
CHAID也称为卡方自动交互效应检测(PASW Modeler helptext)是一种通过使用卡方统计量识别最优分割来构建决策树的分类方法。
CHAID首先检查每个预测变量和结果之间的交叉列表,然后使用卡方独立性测试来检验显著性。如果以上多个关系具有显著的统计意义,则CHAID将选择最重要(P值最小)的预测变量。如果预测变量具有两个以上的类别,将会对这些类别进行比较,然后将结果中未显示出差异的类别合并在一起。此操作通过将显示的显著性差异最低的类别对相继合并在一起来实现。当所有剩余类别在指定的检验级别上存在差异时,此类别合并过程将终止。对于集合预测变量,可以合并任何类别;对于有序集合预测变量,只能合并连续的类别。优点:可产生多分支的决策树;可以定距或定类目标变量;从统计角度优化树的分支过程。
3 糖尿病并发症数据获取及预处理
从确诊病例数据库中获取了3 969例糖尿病并发症病例,包括诊断结果在内共80个字段,12种并发症。在医学专家指导下,通过字段合并筛选以及统计方法预处理后,共得84条病例诊断信息。如图1为诊断信息表截图。

图1 部分诊断信息表
4 决策树方法对糖尿病并发症数据分类
将数据导入PASW13,通过自动分类,如图2表明,4种决策树构造时间都小于1分钟,精确性都大于66%,使用字段分别为10号喝酒、23号肾病、20号肝病史、6号饮食。通过PASW可获取4种决策树方法的决策规则和决策树,经专家确认,虽然诊断过程先后有出入,但吻合不同临床专家的诊断思维。在本实例分类中,后3种方法的结果不能完全给出所有12种并发症的诊断规则和诊断结果,而C5.1方法效果最好,其能对12种并发症给出诊断树及诊断规则。结果如图2-8,在图3中,结果先是定糖尿病足,再从下往后辩识。考虑决策树图过大,故分成5部分,上下相接,接口分别为“皮肤病”、“渗透压”、“尿酮”、“糖尿病史”字段,图中,类别指并发症;%在待诊部分表明各占比例,%在已诊结果部分表明通过上一字段作为依据时在总类别中所占比例;n表明病例个数。分类决策过程如图4,有“溃疡”则为糖尿病足,84个信息库中,有8例,占所有糖尿病足的100%,占所有84个病例中的9.524%,其它分类结果见图2-8。

图2 决策树分类模型
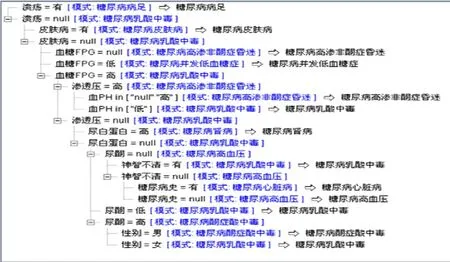
图3 C5.1诊断规则

图4 C5.1决策树结果(1)

图5 C5.1决策树结果(2)

图6 C5.1决策树结果(3)

图7 C5.1决策树结果(4)

图8 C5.1决策树结果(5)
4.结论
经提取临床确诊病例信息后,用4种决策树方法对其分类,得到了诊断规则和决策树,其诊断过程吻合临床专家的诊断思维,对于本实例C5.1效果最好。包括中医西医在内的确诊病例数据库有待进一步完善,字段有待进一步规范,方法有待进一步研究和改进,以期辅助临床诊断。
[1]杨淑莹,模式识别与智能计算——MATLAB技术实现[M].北京:电子工业出版社,2008.
[2]范明,孟小峰.数据挖掘概念与技术[M].北京:机械工业出版社,2007.
[3]左思强,冯少荣.决策树C5算法在教学实践中的应用[J].福建电脑,2011,4:140-142.
[4]方俊群,罗家有,姚宽保,等.C5.0决策树法在出生缺陷预测中的应用[J].中国卫生统计,2009,26(5):473-476.
[5]黄奇.基于CHAID决策树的个人收入分析.数学理论与应用[J],2009,29(4):33-37.:
[6]Wozniak,Michal.A hybrid decision tree training method using data streams[J].Knowledge And Information Systems.2011,29(2):335-347.
[7]Liangxiao Jiang,Chaoqun Li.An Empirical Study on Class Probability Estimates in Decision Tree Learning[J].Journal of Software.2011,6(7):1 368-1 373.
[8]Aviad,Barak,Roy,Gelbard.Classification by clustering decision tree-like classifier based on adjusted clusters[J].Expert Systems With Applications.2011,38(7):8 220-8 228.
[9]Meng Yi-cheng,Liu Wen-qi,Li Yue-qiu.Optimized decision treealgorithm based on rough set theory[J].Journal of Kunming University of Science and Technology(Science and Technology).2009,34(2):95-97.
