一种面向云计算环境的制造文本分类算法的研究
2013-11-06刘刊,刘中
刘 刊,刘 中
(太原科技大学机械工程学院,山西 太原 030024)
随着互联网通道能力和运算能力的增强以及互联网整合技术和应用服务的演进,云计算作为一种新的互联网模式应运而生。云计算带来了3种服务方式:Iaas、Paas和Saas,这3种服务方式最大的特点是可使制造企业在软件方面变买为租,且省去本地安装与维护,也不用购买好的硬件,存储资料可以放到云端,设计开发产品时根据需要租用云网上的计算能力即可,并且还能决定在本地还是在云端运行所用的软件开发平台以及搜索和分类应用程序[1]。这样的云端办公室可为制造企业节省大量的人力、物力和财力,省下的这些支出和时间若用到扩大再生产上将会大大增加制造企业对制造资源的需求,同时云计算带来的3种服务方式使得Web上的信息量真正实现了几何级数的增长。一边是制造企业对制造资源的大量需求,一边是制造资源的大规模积累,怎样对浩如烟海的制造资源进行分类检索和管理已成为一个很重要的研究课题。
本文提出了一种制造资源文本分类算法,对制造资源的分类准确有效,可方便研究人员整理资料和构建制造资源本体库,从而为制造资源的语义发现打好基础。同时制造企业也能迅速地找到所需的资源,降低产品的开发周期,提高产品和企业的竞争能力。
1 制造资源文本的分类方法
本文的研究对象是云网(云计算网络,即Cloud Web)上的机械制造资源,其类别有广义和狭义之分,本文只对狭义的制造资源进行研究。狭义的制造资源是指加工制造一个产品所需要的物质元素,它主要包括各种机床、刀夹具、量具和材料等[2]。
制造资源文本的分类是基于数据的机器学习方法,该方法以训练样本为出发点来发现规律,从而实现对未知样本的识别分类。文本分类的形式化描述是:训练和分类时赋予样本一定的主题特征,并将其特征用数据模型表示为(x,c),x∈Rn,其中,x表示样本特征信息向量,c表示类别[3]。
2 制造资源文本分类算法
在云网上获得较好制造资源文本分类效果的前提是选择合适的机器学习算法。分类算法根据其依据的数学原理可划分为2类:基于统计的文本分类算法和基于规则的分类算法。常见的基于统计的文本分类算法包括朴素贝叶斯(Naïve Bayes,NB),支持向量机,k最近邻,神经网络、多层感知器和Rocchio算法等;常见的基于规则的分类算法包括基于决策树的分类算法、基于粗糙集的分类算法和基于模糊集合的分类算法等[4]。
在制造资源的Cloud web分类研究中,制造资源文本包括两分类问题和多分类问题,前者是指将文本集合分为制造文本类和非制造文本类,后者要分类的文本都是制造文本,把这些待分类的制造文本划分为机械制造领域内的小类。本文证明了SVM有很好的分类精度,但分类速度太慢;NB的分类速度较快,但分类精度较差,这和前人实验得出的结论是一致的。因此,本文提出的是综合NB和SVM的算法,先用NB算法对云网上的文本进行多分类处理,再用SVM算法剔除掉每类中和机械制造类文本距离远的文本。这样结合两者的优点可使分类效果既快又准。
2.1 NB 算法概述
NB算法是基于Bayes全概率公式的算法,Bayes公式为
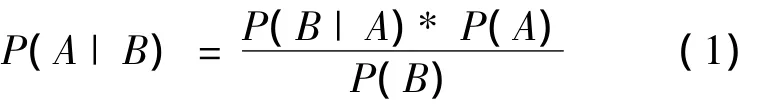
给定一个类 c 以及文本 d(a1,a2,…,ai,…,an),其中ai表示文本中出现的第i个特征项,n为文本中出现的特征项的总数。依据全概率公式(1),可以得到公式(2):
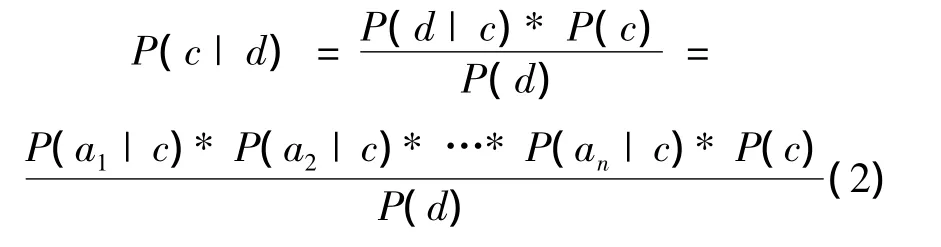
式中:P(c|d)表示文本d属于类别c的概率;P(c)表示待分类的文本现在所处的位置属于这个类别的概率;P(ai|c)表示在类别c中特征项ai出现的概率。
NB算法分类速度快,原因是事先假设各文本之间的特征项都是彼此独立的,这样的假设缺乏严格的理论推导,故该算法无法保证它的准确性,所以导致其分类精度较差[5]。
2.2 SVM算法概述
SVM算法是针对二分类问题的,通过在高维空间中构造一个超平面作为样本的最优分割面。对于二分类(c1,c2)问题,其分类面可表示为一个线性分类器,表达式如下:
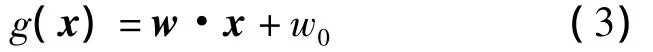
其把样本空间划分为2个子空间。当g(x)≥0时,样本属于类别c1;当g(x)<0时,样本属于类别c2。
SVM算法的理论基础很成熟,分类文本时有很好的效果。
2.3 制造文本分类的NB-SVM算法
制造资源文本分类对分类算法的效率和准确率提出了很高的要求,对于实际制造资源领域的文本分类,本文提出了一种基于NB和SVM融合的NB-SVM分类算法。这种算法的思想是首先利用NB来进行样本的分类,这样会过滤掉很大一部分非机械制造文本,再用相似度阈值的高低来评价剩下分好类的文本,若样本的相似度阈值高,则以其作为分类结果。对相似度阈值一般或差的样本则采用SVM再进行二分类,并作为最终的分类结果。这种仅挑选相似度阈值评价不高的样本再进行SVM分类,可以提高最终分类的准确度和速度。
机械制造文本分类包括训练和分类2个过程。
a.训练过程。
训练样本中有主题样本也有非主题样本。先定义文本分类的主题,然后从网上搜索相关制造文本作为训练样本。对文本进行解析,建立主题特征库,从而确定训练样本的特征向量,用分类器反复训练,调整分类参数,以达到最佳的分类效果。
具体训练步骤:
(1)训练NB分类器,以调整参数的选取。
(2)训练SVM分类器,以调整惩罚系数等参数。
(3)设置NB-SVM相似度阈值。
(4)用NB算法计算每个训练文本属于0,1到第n个类的可能性:P0(非制造文本类),P1,P2,…,Pn。
(5)分别找出 P1,P2,…,Pn中分好类的所有样本,设 Pi中的样本为 Xi1,Xi2,…,Xin。
(6)用相似度阈值来分别评价Xij,对相似度阈值高的样本认为NB分类正确,同时把相似度阈值评价不高的样本传递给SVM分类器。
(7)使用SVM再进行分类,以SVM的分类结果作为最终分类结果。
(8)用评估程序对相似度阈值进行反馈调整。
b.分类过程。
用爬虫程序深入测试样本内部,搜集相关的文本,并下载。服务器端解析制造文本,然后与特征词库匹配,提取特征词,建立特征向量集合,用分类器对样本的主题类别进行判断。
具体分类步骤(T为待分类的样本集合,R表示相似度阈值,C表示文本的主题类别):
(1)用NB算法计算待分类文本T属于0,1到第n个类的可能性:P0(非制造文本类),P1,P2,…,Pn。
(2)分别找出 P1,P2,…,Pn中分好类的所有样本,设 Pi中的样本为 Xi1,Xi2,…,Xin。
(3)用相似度阈值R来分别评价Xij,对相似度阈值高的样本认为NB分类正确,同时把相似度阈值评价不高的样本传递给SVM分类器。
(4)用SVM再进行分类,以SVM的分类结果作为最终分类结果,这时确定Xij属于Ci。
3 NB-SVM算法的实验测评与结果分析
3.1 评价标准
采用召回率、正确率、F测试值来评价NBSVM算法,tp(真正确,true positive)表示分类器正确分类的样本数目,tn(真错误,true negative)表示将样本正确地排除在某类之外的个数,fp(假正确,false positive)表示将样本错误地分类到某类的个数,fn(假错误,false negative)表示将样本错误地排除在某类之外的个数。
该分类算法的召回率R、正确率P和F测试值分别用公式(4)、(5)、(6)来计算,公式如下:
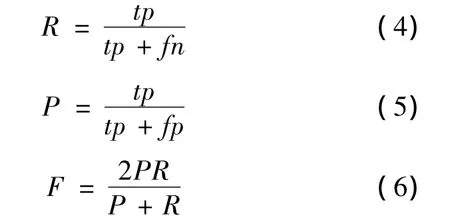
3.2 实验结果与分析
为了检验NB-SVM算法对制造资源文本的分类性能,本实验的分类对象是机械制造资源网站上的文本,网络爬虫的搜索、文本内容的解析和分类算法的设计等模块都是用Java语言开发的。由于机械制造文本分类实验没有统一公共的测试样本库,针对具体的实验内容,本文预先从中国机械网、中国机械设备网、中国工程机械网等网站中提取样本网址,来保证样本的主题分类正确。网络搜索的测试语料样本数目为3600篇,其中,机械制造样本2880篇;非制造样本数720篇。
本文分别采用NB算法、SVM算法以及NBSVM算法来实现分类。实验统计结果,NB的F值是0.785,SVM 的 F 值是0.882,而 NB-SVM 的 F值是0.944,从而得到的SVM的分类效果要优于NB算法,而NB-SVM算法的分类效果最好。
4 结束语
在相同的文本训练集和测试集的前提下,本文对NB、SVM和NB-SVM算法进行了比较研究。主要的实验结果有:(1)SVM的分类效果优于NB。(2)NB-SVM的分类效果比单独的NB和SVM都好。本文下一步的工作有:(1)用NB-SVM算法同其他算法(如KNN等)进行比较。(2)针对机械领域网页的特性,继续增加样本数量进行训练,从而获得最佳训练参数。(3)目前的分类器只考虑了机械领域的分类对象,因此笔者的进一步工作是将该算法运用到其他领域进行测试。(4)根据反馈信息,增量训练分类器,逐步提高分类器的分类效果。
[1] 蔺华,杨东日,刘龙庚.云计算推动商业与技术变革[M].北京:电子工业出版社,2011:10-26.
[2] 苏是.基于语义的网络化制造资源搜索技术研究[D].太原:太原科技大学,2012.
[3] 董宝力.Web制造资源的语义发现关键技术研究[D].杭州:浙江大学,2006.
[4] 张志华.中文文本分类算法的研究与实现[D].北京:北京工业大学,2004.
[5] 董丽丽.一种面向机械领域文本分类器的设计[J].微电子学与计算机,2012,29(4):142-145.
