一种基于半监督学习的2DPCA人脸识别方法
2013-10-28李凯徐治平
李凯,徐治平
(河北大学 数学与计算机学院,河北 保定 071002)
一种基于半监督学习的2DPCA人脸识别方法
李凯,徐治平
(河北大学 数学与计算机学院,河北 保定 071002)
结合半监督学习中的自学习技术以及二维主成分分析 (two-dimensional principal component analysis-2DPCA)方法,提出了一种基于半监督学习的人脸识别方法.在二维主成分分析的基础上,利用少量具有类别标签的样本训练分类器,然后利用半监督学习中的自学习技术,对未知类别标签的人脸样本进行分类,并将具有高置信度的人脸样本加入到训练集中,以此增加训练集中的人脸样本数量.在ORL人脸库和Yale人脸库的实验结果,表明了提出方法的有效性.
人脸识别;半监督学习;二维主成分分析法(2DPCA);特征提取
人脸识别是模式识别领域的重要应用之一,与其他的生物特征识别技术相比,人脸识别具有直观、识别速度快、非侵扰性等特点,在视频监控、门禁考勤系统、犯罪调查等领域都有着重要的应用.人脸识别技术的关键步骤是人脸特征提取,到目前为止,研究者们提出了很多特征提取方法,其中主成分分析(principal components analysis, PCA)[1]是最为经典的特征提取方法之一,不但可以有效地降低人脸图像的维数,同时也能保留主要的识别信息,目前仍然被广泛地应用在人脸识别等模式识别领域.但在PCA方法中,为了提取人脸图像的特征,需要将人脸图像转化为一维向量,从而导致出现高维数据所无法避免的小样本问题和运算复杂度高的问题[2];实际上,人脸图像的本质是一个二维矩阵,矩阵的行(列)向量间的相互关系也蕴含着一定的特征信息,而PCA方法在将图像矩阵转换成一维向量的过程中,将每个像素作为一个独立点来看待,这就丢失了图像的部分空间特征[3].针对这些问题,研究者们提出了一些新的基于张量表示的特征提取方法,如二维主成分分析(2DPCA)[4]方法.该方法利用原始图像的二维像素矩阵直接计算协方差矩阵,然后对其特征分解以求取特征空间,它不需要将图像矩阵转化为一维向量,有效降低了协方差矩阵的维数,并且减少了计算复杂性;同时,由于该方法对整个原始图像直接映射到特征空间,所以在特征提取过程中,这种方法的特征信息损失较小,并且具有较高的识别率.最近,研究人员开始将半监督学习方法用于模式识别问题[5-7],以便充分利用实际问题中大量无类别标签的数据,并获得了好的识别效果.本文对半监督学习的人脸识别方法进行了研究,结合二维主成分分析方法,提出了一种半监督学习的2DPCA人脸识别方法,它不仅能够利用已知类别标签的人脸样本数据,而且更能充分利用大量未知类别标签的人脸数据对分类器进行学习,从而使得该方法具有了自学习能力.
1 二维主成分分析(2DPCA)方法
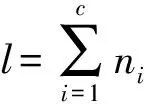
2DPCA的基本思想是通过求解目标函数为广义离散度准则的优化问题,获得d个特征轴Xk(k=1,2,…,d),其中特征轴Xk为n维单位列向量;然后,将训练集中的每个人脸图像A通过线性变换Yk=AXk(k=1,2,…,d)投影到特征轴X1,X2,…,Xd上,从而获得每幅人脸的特征图像B=[Y1,Y2,…,Yd];最后利用最近邻方法确定被测人脸Bj的类别.下面给出有监督2DPCA的人脸识别的算法:
步骤1 利用训练集求解特征轴
2)计算矩阵S的M个最大特征值所对应的标准正交特征向量X1,X2,…,XM,即为所求的特征轴.
步骤2 将训练集图像投影到特征轴得到特征图像
1)将样本集中的每个人脸图像Ai(i=1,2,…,l)利用线性变换Yk=AXk(k=1,2,…,M)投影到各个特征轴,其中投影特征向量Y1,Y2,…,YM称为图像样本A的主成分;
2)将图像的每个主成分Y1,Y2,…,YM组合在一起,获得训练样本中每个人脸的特征图像F=[Y1,Y2,…,YM],假设通过此方法获得的特征图像分别为F1,F2,…,Fl.
步骤3 确定被测试人脸图像B∈Du所属类别
1)使用Yk=AXk(k=1,2,…,M)对被测试人脸图像进行线性变换,以此获得该人脸的特征图像B′=[Y1,Y2,…,YM];
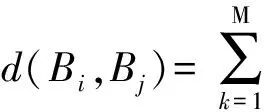
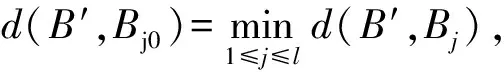
2 具有半监督学习的2DPCA算法
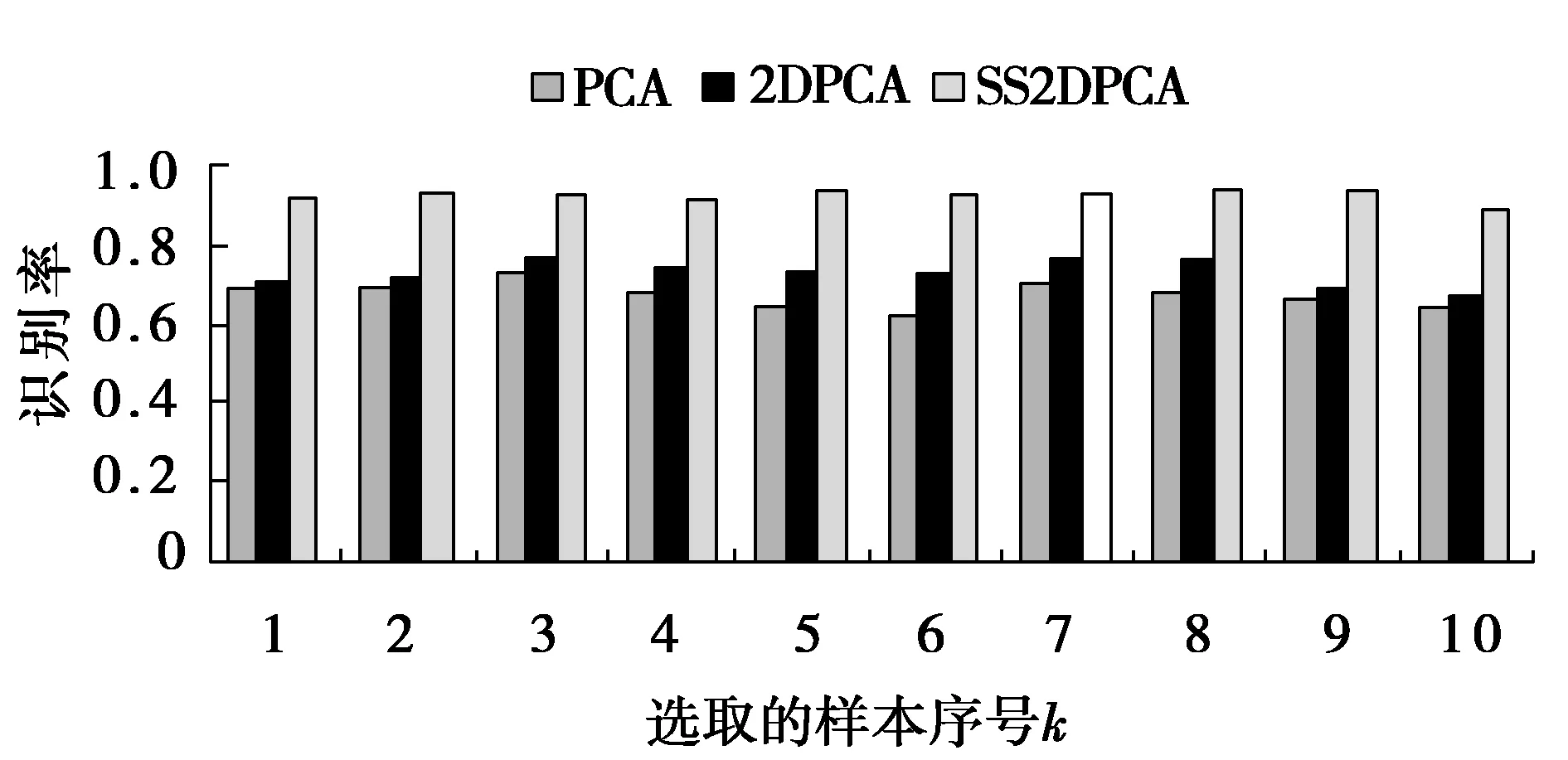
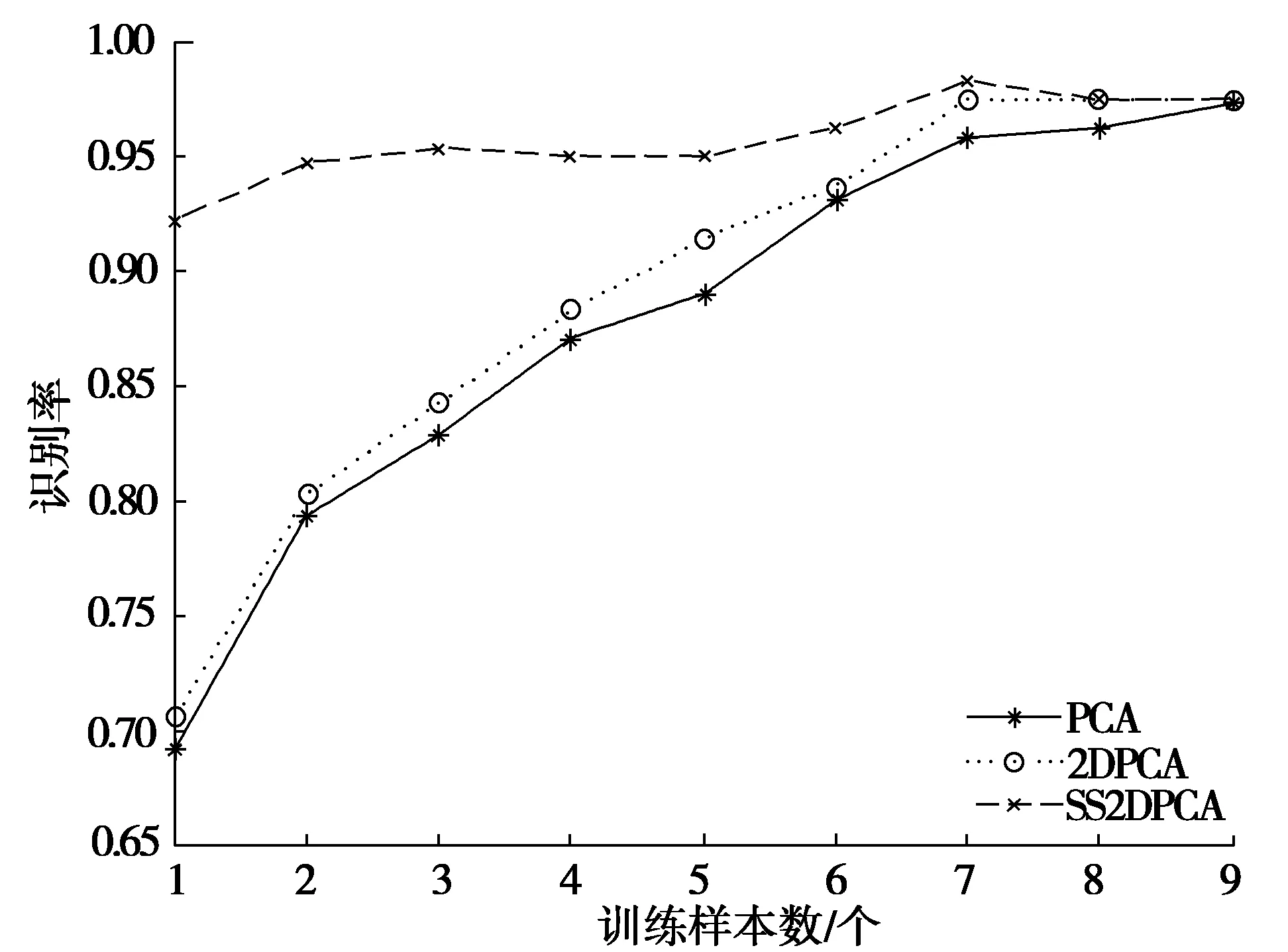
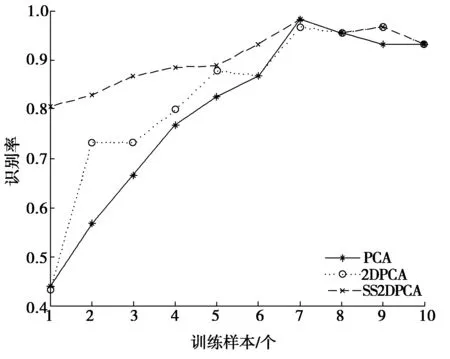
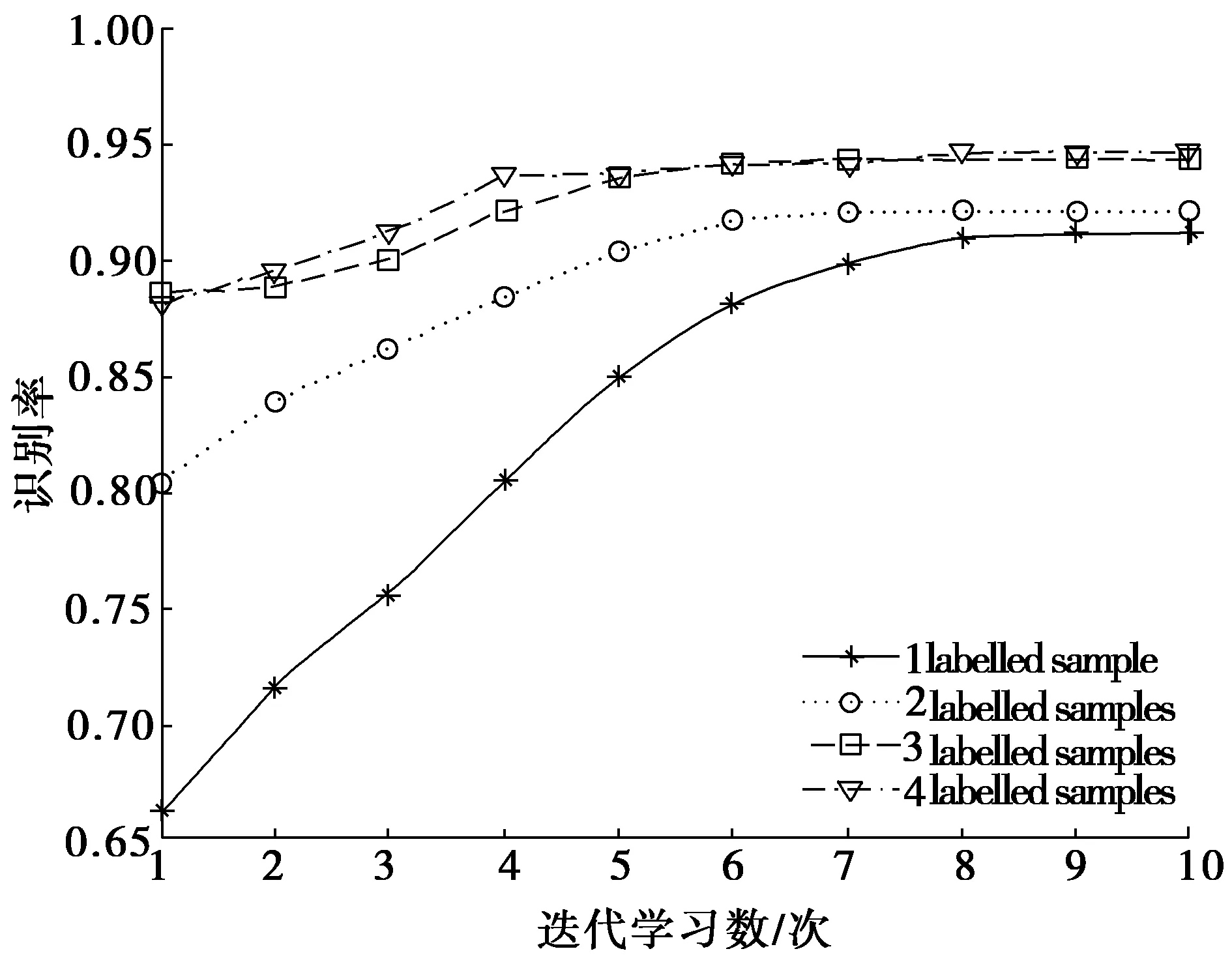
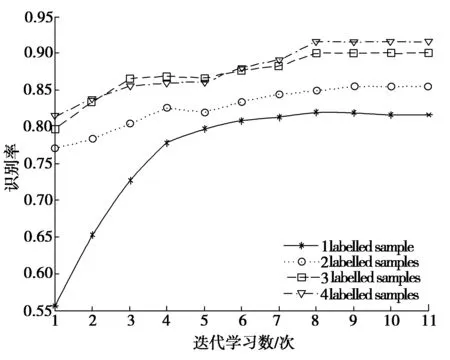
假设给定具有类别标签的数据Dl和无类别标签的数据Du,通常l< 在本文中,提出了一种基于半监督学习的2DPCA人脸识别方法,主要将自学习技术引入到2DPCA方法中,使人脸识别系统能够同时利用少量有类别标签的人脸图像Dl和大量易于获取的无类别标签人脸图像Du对分类器进行训练,从而提高人脸的识别率,特别是在训练样本不足的情况下能够取得较好的识别效果.下面给出半监督学习的2DPCA人脸识别算法,并将此算法命名为SS2DPCA(self-trainingsemi-supervised2DPCA): 步骤1 根据训练数据集Dl,计算训练样本的散度矩阵S及该矩阵的特征值和特征向量,然后选取矩阵S的前M个最大特征值所对应的标准正交特征向量X1,X2,…,XM,并将这些向量组成特征矩阵W=[X1,X2,…,XM]. 步骤4 对获得的每类模式Pk(k=1,2,…,c),从中选取置信度最高(即距离该类人脸模板最近)的样本,并将其伪类别标签Ik置信,也就是将其类别标签Ik赋予Du中相对应的的样本Bi,同时将Bi从无类别标签集Du中移至具有类别标签的人脸数据集Dl中,即Dl=Dl∪{Bi}且Du=Du-{Bi}. 步骤5 判定是否满足结束条件?若满足结束条件,则对Pk中的所有伪类别标签置信,并输出识别结果;否则,将扩展的数据集Dl作为训练集,返回步骤1执行. 为了使得算法能够正常结束,通常事先指定半监督学习算法的迭代执行次数,或规定其他的结束条件,例如全部测试样本是否已被置信等.在每次迭代过程中,通过选取每一类的置信度最高的测试样本来逐渐扩大训练数据集;另外,为了提高算法的执行效率,也可以一次性选择每一类中置信度最高的多个测试样本来扩大训练数据集. 为了验证提出的人脸识别算法SS2DPCA的有效性,选取了ORL与Yale人脸数据库进行了实验,并与常用的人脸识别算法PCA与2DPCA进行了实验比较. ORL(olivetti research laboratory)人脸数据库是由剑桥大学Olivetti 研究所创建,主要用于人脸识别算法的性能测试.该数据库共有400幅分辨率为112×92的256个灰度级的人脸图像,包含40个人,每人都有10幅不同的图像,这些图像分别是在不同的时间、不同的视角下采集的,且包含了各种不同的变化,如睁眼与闭眼、戴眼镜与不戴眼镜、张嘴与闭嘴以及笑与不笑等,该数据库中的部分人脸图像如图1所示;而Yale人脸数据库由耶鲁大学计算视觉与控制中心创建,共有15个人的165张灰度图像(每人具有11张不同的人脸图像),这些图像反映了光源的不同光照变化、不同的表情变化以及是否佩戴眼镜等情况,该数据库中的部分图像如图2所示. 图1 ORL人脸数据库中的部分人脸图像 图2 Yale人脸数据库中的部分人脸图像 首先,针对人脸图像库中的每类选取一个样本进行实验,为此,从每个人的Q幅人脸图像中选取一幅人脸作为训练样本,将剩余的Q-1幅人脸图像作为测试样本,其中迭代学习次数N的值选为(Q-1)-1,实验结果如图3和图4所示.可以看到,当在每类样本中只取一个训练样本时,PCA和2DPCA算法的识别效果并不理想.特别是在光照、姿态与表情有较大变化的Yale库中,PCA方法的识别率只有40%~50%,说明了该方法易受光照、姿态与表情的影响,在人脸识别时并不能获得满意的结果;对于2DPCA方法,其识别率很不稳定,尤其是选取s4(左侧光源方向样本)和s7(右侧光源方向样本)作为训练样本时,其识别率只有30%左右,可见该方法对光照过于敏感,并不能满足人脸识别的要求;而本文提出的方法SS2DPCA的识别率保持在80%左右,其识别性能优于2DPCA方法,几乎是PCA方法识别率的2倍,并且提出的方法SS2DPCA的识别率浮动范围较小,说明SS2DPCA方法能充分适应各种光照、姿态与表情变化的样本图像,具有较好的鲁棒性.并且,由于该算法能有效的利用无类别标签的测试样本中所包含的信息,单样本条件下其识别率要远大于PCA和2DPCA算法. 图3 ORL人脸数据库中依次选取第k个训练样本时的识别率 图4 Yale人脸数据库中依次选取第k个训练样本时的识别率 然后,分别从每个人的Q幅人脸图像中随机选取k(k=1,2,3,…,9)幅人脸图像作为训练样本,剩余的Q-k幅人脸作为测试样本,实验结果如图5和图6所示,其中在SS2DPCA算法中的迭代学习次数N选为(Q-k)-1. 图5 ORL人脸数据库中随机选取不同数量的训练样本时的识别率 图6 Yale人脸数据库中随机选取不同数量的训练样本时的识别率 可以看到,当测试人脸图像的数量大于训练人脸图像时,SS2DPCA算法的识别率要远大于PCA和2DPCA算法.当测试样本越多,训练样本越少时,这种优势就表现的越明显;而随着训练人脸图像样本的增加和测试图像样本的减少,SS2DPCA算法的识别率逐渐与PCA和2DPCA算法的识别率开始接近,最后与2DPCA算法的识别率相等.实际上,当训练图像样本数为9,测试图像样本数为1时,SS2DPCA方法与2DPCA方法是没有差别的. 为了进一步分析迭代学习次数的变化对算法SS2DPCA的影响,在ORL和Yale人脸数据库中随机选取每个人的1至4幅图像作为训练样本,以每个人的剩余图像作为测试样本,在算法SS2DPCA中选取不同的迭代次数,将该实验重复5次,并计算它们的平均识别率,实验结果如图7和图8所示.可以看到,当选取的自学习迭代次数较小时,在2个数据库上的识别率普遍较低,而随着迭代次数的增加,SS2DPCA算法的识别率有了显著的提高.这是因为在自学习过程中,随着训练样本的增加,则分类器的性能将会有所提升;当迭代次数接近于每类的无标签数据个数时,已加入到训练集的无标签数据增多,用于识别的人脸样本数据有所减少,所以分类器的识别率逐渐趋于稳定. 图7 ORL人脸库中使用不同训练样本数的迭代次数与识别率间的关系 图8 Yale人脸库中使用不同训练样本数的迭代次数与识别率间的关系 针对人脸识别中典型的小样本问题,将半监督学习技术引入到2DPCA方法中,提出一种半监督学习的2DPCA人脸识别方法.该方法充分利用大量无类别标签的样本所蕴含的信息对分类器进行训练,弥补了传统的人脸识别方法由于样本不足带来的缺陷.通过在ORL人脸库和Yale人脸库上的实验,表明了本文提出的方法优于传统的PCA和2DPCA,且具有抗光照、姿态与表情的变化,特别是在训练样本数量较少的情况下,能够提高人脸识别系统的性能. [1]TURK M A, PENTLAND A P. Face recognition using eigenfaces[Z]. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, 1991. [2]曾岳, 冯大政. 一种基于加权变形的2DPCA 的人脸特征提取方法[J]. 电子与信息学报, 2011, 33(4):769-774. ZENG Yue, FENG Dazheng. An algorithm of feature extraction of face based on the weighted variation of 2DPCA[J]. Journal of Electronics&Information Technology, 2011, 33(4):769-774. [3]KWAK K C, PEDRYCZ W. Face recognition using an enhanced independent component analysis approach [J]. IEEE Transactions on Neural Networks, 2007, 18(2):530-541. [4]YANG Jian, ZHANG D, FRANGI A F, et al. Two-dimensional PCA: a new approach to appearance-based face representation and recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1):131-137. [5]HUANG Hong, LI Jianwei, LIU Jiamin. Enhanced semi-supervised local Fisher discriminant analysis for face recognition [J]. Future Generation Computer Systems, 2012, 28(1):244-253. [6]ZHANG Tianzhu, LIU Si, XU Changsheng, et al. Boosted multi-class semi-supervised learning for human action recognition [J]. Pattern Recognition, 2011, 44(10-11):2334-2342. [7]ZHANG Shanwen, LEI Yingke, WU Yanhua. Semi-supervised locally discriminant projection for classification and recognition [J]. Knowledge-Based Systems, 2011, 24(2):341-346. [8]ZHU Xiaojin. Semi-supervised learning literature survey[R]. Madison: University of Wisconsin-Madison, 2008. Asemi-supervisedlearningbased2DPCAfacerecognitionmethod LIKai,XUZhiping (College of Mathematic and Computer Science, Hebei University, Baoding 071002, China) By combining self-training method of the semi-supervised learning with two-dimensional principal component analysis (2DPCA), a semi-supervised learning based face recognition method was proposed. On the basis of two-dimensional principal component analysis, few labeled samples were used to obtain classifier. Then unlabeled samples were classified through the classifier. And according to the self-training method of semi-supervised learning, the face samples with the highest confidence were added to the training set in order to increase the number of face samples in training set. Experimental results on ORL face database and Yale face database showed the effectiveness of the presented method. face recognition; semi-supervised learning; two-dimensional principal component analysis(2DPCA);feature extraction 10.3969/j.issn.1000-1565.2013.04.014 2012-09-26 国家自然科学基金资助项目(61073121);河北省自然科学基金资助项目(F2012201014) 李凯(1963-),男,河北满城人,河北大学教授,博士,主要从事机器学习、数据挖掘、模式识别等方向研究. E-mail:likai@hbu.edu.cn TP391 A 1000-1565(2013)04-0413-07 (责任编辑孟素兰)
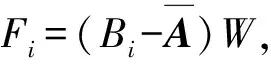
3 实验结果与分析



4 结论
