基于改进K均值的图像分割算法
2013-10-16蒋大宇
蒋大宇
(哈尔滨工程大学信息与通信工程学院,哈尔滨150001)
图像分割技术在图像工程中占有重要的地位,是处于图像分析和图像处理之间的重要步骤,也为后续的处理奠定基础.图像分割是指依据灰度、彩色、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域,使得这些特征在同一个区域内,表现出一致性或相似性,而在不同的区域间表现出明显的不同[1].多年来经过诸多学者的不懈努力,已经提出上千种的图像分割算法,并且每年还不断有新的算法产生,尽管已经提出了很多用于图像分割和特征提取的方法,但由于图像的种类繁多和复杂多样性,设计一种通用和有效的分割算法仍然具有重要的意义.目前图像分割方法主要有:阈值法、区域提取法、聚类法和边缘检测法四类[2].
在聚类法的图像分割中,K均值算法的应用的最为广泛,因其算法具有很好的伸缩性,可以处理大像素的图像,然而缺点也十分突出,聚类结果受初值的影响而变得不稳定[3].为了让KM获得稳定的聚类,学者们提出了许多改进方案,其中以高质量的层次聚类算法为K均值提供初值是最受认可的策略,可是高质量的层次聚类往往是因为较高的计算复杂度而使得改进的K均值失去了伸缩性,不再适合处理规模稍大的数据[4].本文设计了一个新的KM改进方案——并行二分K-Means(Parallel Bisecting K-Means,PBKM),该方法既可以保留K均值的伸缩性,又能大幅提高KM的算法效率.
1 并行二分K均值
1.1 并行二分思想
首先将数据集一分为二得到两个簇,然后以每个簇为起点再一分为二,如此重复,第r次获得2r个簇.这个切分过程与细胞在分裂过程中的增长速度一样,最底层的数据称之为叶子节点.细胞分裂式的二分给予每个簇均等的切分机会,在每次迭代过程都要对所有的簇进行切分,这个过程具有并行的特点.PBKM采用二分思想对数据对象进行聚类,其过程在于每次迭代需要更新待切分簇的数量和大小,算法描述如下:
1)输入待聚类数据集,并初始化n、k;
2)计算迭代的次数R=[lg k/lg2]+1;
3)for r=1 to R
计算并更新待切分簇的数量M=2r-1;
计算并更新待切分簇的大小nd=n/2r-1;form=1toM
调用K-means(nd,2)对簇进行二分;
4)计算叶子结点数量M=2R;
5)把M个叶子结点合并到k个;
6)输出数据对象的类别标签.
虽然PBKM算法在聚类过程中调用了KM算法,但整个过程仍然简洁明了,容易程序实现.
1.2 PBKM的时间复杂度分析
PBKM第r次切分给出 m个簇,m=2r,令2R-1≤ k≤2R,R为迭代的次数.通常完全二叉树的叶子结点数m >k,此时需要将叶子结点进行部分合并,是叶子节点数降到k即可完成聚类.
对于PBKM的时间复杂度分析需要考虑二分的迭代计算和叶子结点合并等两个过程的时间开销.
第r次的并行切分,需要切分m个簇,此时待切分簇的大小为nd,时间开销为:

因为二分时m=2r-1,nd= n/2r-1,k'=2,有:

执行R次迭代的时间为:
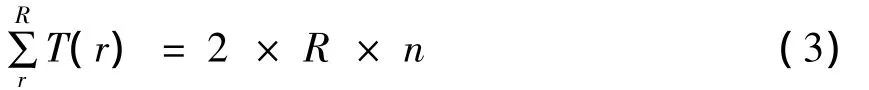
当k<nd时,需要将叶子结点部分合并,所以PBKM算法的总体时间开销为:
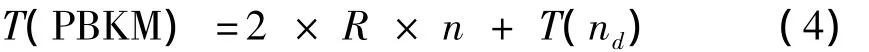
nd=2R,nd比k略大,需要合并的叶子结点并不多,因此合并的时间开销T(nd)也不大.当n很大时,例如对大规模数据进行聚类,T(nd)可以忽略不计.
因为需要合并的叶子结点不多,也就是nd和k差别不大,此时合并的时间复杂度接近于 O(nd2).当2×R×n≫nd2,有:

也就是说,n≫2R/(2×R)时,叶子结点合并的时间相对很少,可以忽略T(nd).式(6)给出的条件是十分宽松的,通常规模的数据集都可以满足因此可以说PBKM算法中的叶子结点合并不会显著增加整个聚类过程的时间开销.R的计算如下:

2 基于PBKM的图像分割算法
在描述像素点的时候我们希望尽可能的不丢失像素信息,这里把每一个像素点分别用其在RGB和HIS颜色空间上进行描述,为了更全面的描述像素的特征,在对像素特性进行描述时还加入了灰度值.这样每一个像素点就拥有了7个属性,我们就用这7维的行向量来代表该像素点.
对于一个像素为256×256的小图片,其像素点已达到216,按照提出的预处理方法,实际聚类的数据规模达到了216×7.这样看来图像的像素数据对于聚类问题来说属于大规模的数据集.
用聚类的法进行图像分割,首先将图像中的像素点用一个多维的向量表示,也就是将每个像素点映射到多维的特征空间中,然后根据这些像素点在特征空间的聚集情况对特征空间进行聚类,达到分割的目的,再把多维特征空间中的分割结果映射回原图像空间,进而得到原图像的分割结果.
基于PBKM的图像分割的过程如下:
1)对于原始的图像I0进行预处理,I0含有m×n个像素点,经预处理后变成了待聚类的数据I1,I1的数据规模达到了m×n×7;
2)对待聚类数据I1进行PBKM聚类,得到一组聚类标签 Idex[m×n,1]
3)将得到的聚类标签Idex,还原回原图像大小m×n;
4)对还原的图像进行边缘检测得到图像分割的轮廓,从而实现图像分割.
需要指出的是在第3步结束后,根据实际问题的需要可以添加一些后续的优化处理,例如开、闭运算、膨胀、腐蚀等,然后在进行边缘检测,可以得到更好的分割结果.
3 对比试验与结果分析
3.1 试验设计与数据源
本文以自然彩色图像作为试验的对象来研究图像分割.试验的硬件环境为:CPU Core 2 Quad Q6600 2.4G,Internal memory 4G,Hard disk Hitachi HDP 725050GLA360 500G.软件环境为:Windows 2003+Matlab2007b.本文在上述环境中实现了实验算法和实验验证工作.测试图全部取自Berkeley图像分割库[5-6].为了对本文图像分割算法的性能进行评测,本文进行了两组实验,对PBKM算法的有效性和高效性进行了验证.
3.2 算法的有效性验证
为了验证PBKM算法在图像分割领域的有效性,本文将基于PBKM图像分割算法的分割结果和人工分割结果进行了比对,为了更直观的看到分割过程及效果,在图1中列出了原始图像、基于PBKM方法的聚类结果、边缘检测得到的轮廓还有人工分割的结果.
其中第一行的三幅图像是在Berkeley分割库中随机抽取的大小为481×321的原始图像;第二行为原始图像经过PBKM聚类算法得到的聚类标签,通过灰度的方式显示的分割结果;第三行是图像聚类结果经边缘检测得到的分割轮廓;第四行是人工分割得到的轮廓,是检验分割算法好坏的一个重要参考指标.
从图1中三幅图像的分割情况对比可以看出:1)PBKM算法的分割结果和人工分割的结果具有较强的相似性,说明了PBKM算法对于图像的分割结果和人的主观视觉感知具有较强的一致性;2)三幅图在图像主体的分割上与人工分割几乎完全吻合,第1幅图中房子的轮廓、棱角、门窗、屋顶的十字架,第二幅图中鸟的轮廓、树枝的形状,第三幅图中两只鸟的轮廓等都得到了较好的分割,这说明PBKM方法用于图像分割能较好的识别图像中的主体,能满足图像后续处理的要求(图像理解、图像识别等).3)在图像的细节部分的分割中,该算法得到的轮廓和人工分割得到的轮廓有一定的出入.例如在第一幅图圆顶屋旁边的电线,在人工分割中体现出来了,但本文方法没有进行分割;第2幅图,在分割时对鸟的胸部和脚进行了分割,而人工分割只分割鸟的轮廓,不对细节进行分割;在第3幅图中,本文算法在大鸟的尾部进行的分割和人工分割有出入.这些差异的存在恰好体现了图像分割的难度所在.人工分割只是作为检验图像分割算法的一个参考并不是标准答案,其中人的主观因素占很大部分.总体上来讲PBKM算法的分割结果和多数人的视觉感知想吻合,证明了PBKM的有效性.

图1 三幅真实图像的分割结果人工分割的对比
3.3 对比试验
为了对PBKM算法用于图像分割的性能、分割效率给出评价,将PBKM算法和K-均值算法进行了对比,PBKM算法和K-均值都能处理大规模的数据,我们在图像库中找到了一个1 024×768像素的图像,对图像进行对比试验得到的分割结果如图2所示,两种方法的运行时间由表1给出.
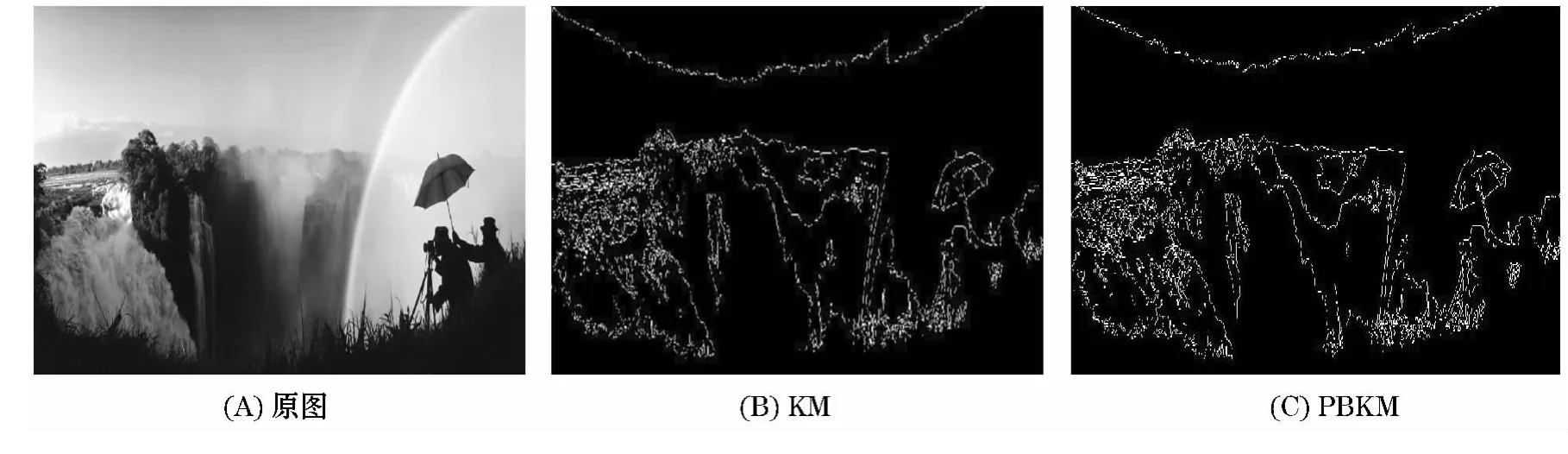
图2 两种算法分割的轮廓对比图

表1 两种分割算法的运行时间对比
从图2中可以看出两种方法在大像素的图像上都可以应用,充分说明了两种方法都适合处理大规模的数据集,从图2中可以看出两种方法对于原图的分割几乎一样,无论是云的形状、雨伞、照相的人还是山的形状.并且两种方法对于图像细节处的分割进行的很好,从(B)、(C)中可以看出雨伞的形状、照相人的轮廓、几乎连山的大概形状都分割出来了,最难能可贵的是就连雨伞上面的小头都能分割出来,说明了两种方法都可以应用在大像素的图像分割上.
从表1中能直观的发现,我们的方法PBKM在分割质量上和K均值几乎一样,但是所消耗的时间只占K均值方法的64%左右,这样的结果充分的体现出了PBKM算法在处理大规模像素图像分割时的优势.
4 结 语
本文针对K均值方法在图像分割中的不足,提出了一种基于改进K均值算法的PBKM算法,通过实验证实PBKM算法在图像分割领域具有很强的应用性,特别是对大规模像素图像的分割,能得到很好的结果,并且耗时较少.
[1]CHENG H D,JIANGX H,SUNH,etal.Color image segmentation;advances and prospects[J].Pattern Recognition,2001,34(12):2259-2281.
[2]何 俊,葛 红,王玉峰.图像分割算法研究综述[J].计算机工程与科学,2009,31(12):58-61.
[3]TAN P N,STEINBACH M,KUMAR V.Introduction to Data Mining[M].北京:机械工业出版社,2010:492-495.
[4]CUTTING D R,PEDERSEN JO,KARGER D,etal.Scatter/Gather:A Cluster-based Approach to Browsing Large Document Collections[C]//Proceedings of the Fifteenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,[S.l.]:[s.n.],1992:318 -329.
[5]MARTIN D,FOWLKESC,TAL D,etal.A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceeding of the International Conference on Computer Vision,Los Alamitos,California:IEEE Society Press,2001,416 -423.
[6]肖 刚.基于小波域软阈值的指纹分割方法研究[J].哈尔滨商业大学学报:自然科学版,2012,28(2):231-234.
