基于演化超网络的中文文本分类方法
2013-10-09金理雄孙开伟
王 进,金理雄,孙开伟
(1.重庆邮电大学计算机科学与技术学院,重庆400065;2.计算智能重庆市重点实验室,重庆400065)
随着Internet应用的普及,互联网上电子文档的数量正在高速增长.为从海量电子文档中快速、准确、全面地查找和获取有效信息,近年来,文本分类技术得到了学术界的广泛关注.国外对英文文本分类技术的研究始于1950年,经过数十年的发展已经比较成熟.当前比较流行的英文文本分类方法包括:朴素贝叶斯(Naïve Bayes)[1],K 最近邻(k-nearest neighbor,KNN)[2],支持向量机(support vector machine,SVM)[3],最大熵模型[4]等方法.而国内对中文文本分类的研究起步较晚,始于20世纪80年代初期,近年来也取得了显著进展[5-7].
受生物分子网络的启发,演化超网络(evolutionary hypernetworks)最初是作为一种并行联想记忆模型被提出[8],并通过 DNA 计算实现[9].超网络由大量的超边(hyperedges)组成,具有流体性、可重置的分子结构,是学习友好的[10].超网络的结构(超边的组成)和参数(超边的权值)通过分子演化学习得到.近年来,Zhang B.T.[10]从超图的视角定义了超网络这一新颖的认知学习和记忆模型,并已将其成功应用于手写数字图像重建[9]、癌症基因挖掘[11]、证券价格预测[12]、心血管疾病诊断[13]等诸多领域.
为了建立一个高效、准确的中文文本分类系统,文中拟提出一种基于演化超网络的中文文本分类算法.对所获的中文语料进行文本预处理、特征选择和权值计算,建立演化超网络模式识别模型;给出超网络的演化算法,实现模型的识别功能;并通过与SVM,KNN两种传统的文本分类方法的对比试验,验证演化超网络拥有较好的分类性能.
1 中文文本分类的前期处理
中文文本分类的前期数据处理流程包括:文本预处理、特征选择、权重计算.
1.1 文本预处理
文本预处理主要包括分词处理、去停用词两个步骤.为将文本进行形式化表示,把中文文本表示成基于词条的N维向量.中文是连续的字符串,为了抽取文本中的词条,需对中文文本进行分词处理.而去停用词主要是去除那些对文本内容没有意义的词.文中采用中国科学院计算技术研究所的汉语词法分析系统(Institute of Computing Technology,Chinese Lexical Analysis System,ICTCLAS)进行分词和词性标记.通过词性标记,文中可以去除无实际意义的词条(助词、数词、语气词等),从而保留了最能体现文本主题的词条(名词、动词、形容词).
1.2 特征选择
文中采用χ2统计方法进行文本特征选择以降低文本信息特征向量空间维度,提高分类效率.χ2统计方法是通过计算词条t和文档类别c的相关程度来实现:
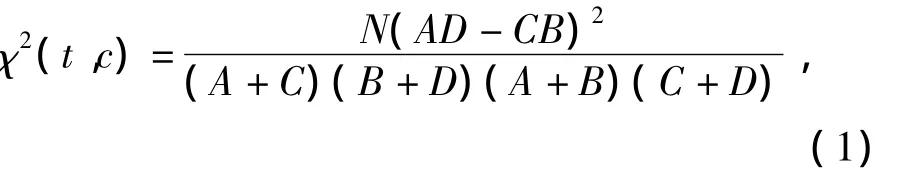
式中:N为训练文本总数;A为t,c同时出现的次数;B为t出现而c未出现的次数;C为c出现而t未出现的次数;D为二者都未出现的次数.χ2统计值越大,则词条t对文档类别c的相关度越高.对多类文本分类问题,χ2统计方法有最大值法和平均值法两种方法来确定词条t对整个语料的χ2值.文中采用最大值方法:
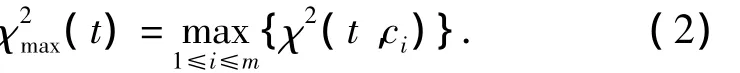
式中:m为文档类别数.文中根据χ2值从大到小选出前n个词条作为特征向量.
1.3 权重计算
由于不同的特征项对于中文文本的重要程度和区分度不同,因此在对文本进行向量空间模型处理的时候,需对特征向量进行赋权值.文中采用布尔权重计算特征向量的权值:如果特征词条在文本中出现则权重为1,如果特征词条没出现则权重为0.
2 超网络中文文本分类
演化超网络模型在模式识别方面已经有了成功的应用,文中把超网络用于中文文本分类.超网络文本分类包括两个步骤:① 超网络演化学习;②超网络分类.超网络学习过程中,采用超边替代的策略,进行超网络的更新.学习后的超网络通过逐一给出输入样本属于每个类别的条件概率进行分类.
2.1 超图的定义
超图是每条边连接非零个顶点的无向图.在一般意义上的图论模型中,图的每条边最多连接两个顶点.但是,超图的边所连接顶点个数可以大于2.
设G={X,E}是一个超图,其中X={x1,x2,…,xn}是超图G的顶点集合,表示该超图有n个顶点;E={e1,e2,…,en}是超边的集合,E中的每个元素ei={xi1,xi2,…xic}是一个连接c个顶点的超边.图1给出了一个包含6个顶点4条超边的超图.
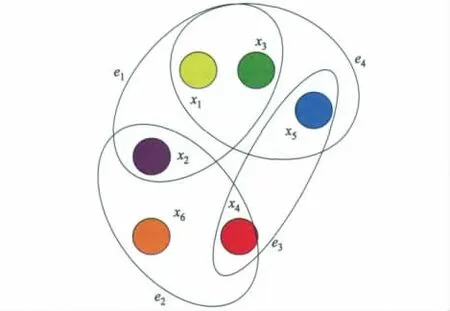
图1 超图模型
2.2 超网络模式识别模型
超网络是一个每条超边都被赋予了权值的超图.超网络可被定义为一个3元组H={X,E,W},其中X,E,W分别表示超网络的顶点集合、超边集合以及超边权值的集合.超网络中一条超边所连接的顶点数被称作该超边的阶数(order),其取值可以大于2,因此超边能够表示顶点的高阶关联[10].如果一个超网络的所有超边阶数均为k,则这个超网络被称为k阶超网络.图2为超网络模型图.
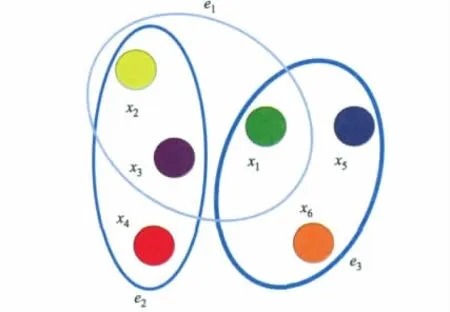
图2 超网络模型
图2所示的超网络H={X,E,W},顶点集合X={x1,x2,x3,x4,x5,x6},超边集合E={e1={x1,x2,x3},e2={x2,x3,x4},e3={x1,x5,x6}},超边权值集合W={w1=1,w2=2,w3=4}.说明此超网络拥有6个顶点3类超边.超网络超边线条的粗细代表了超边的权值大小:线条越粗,其权值越大.文中超边的权值就是边的拷贝(copies)的数目.例如,超边e3的权值w3为4,则超网络中共有4条和e3完全相同的超边,即超边e3有4个拷贝.
在演化超网络文本分类应用中,每个特征选择后的词条被看作超网络中的一个顶点.文中可以把超网络看作一个决策分类系统f,给定一个输入模式X={x1,x2,…,xn},它能输出该模式所对应的类别.决策分类系统f通过使用输入输出对组成的训练集D进行演化学习生成,训练集D具有以下形式:
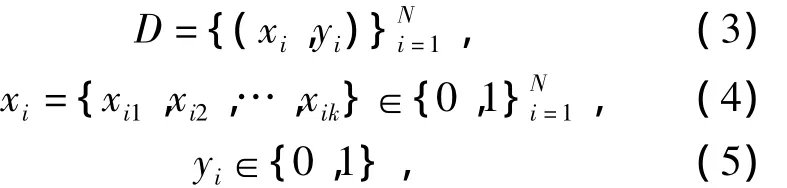
式中:N表示训练集中样本的数量;k为每个样本的维数;yi为样本xi的类别标识.
超网络中,每条超边构成一个决策分类规则,超边所关联的顶点称作决策属性.例如,超边Z={x1=0,x2=0,x3=1,y=1}的阶数为 3,类别为1.超网络允许超边的复制,超边权值的大小决定了该超边对分类的重要性.
实际上,超网络代表了输入模式X和它可能的类别Y的联合概率P(X,Y),其中Y∈{1,2,…,m}.联合概率P(X,Y)可以解释为模式X被检索为类别Y的概率.给定一个样本,超网络将所有的超边与样本进行匹配,并把匹配成功次数最多的类别作为分类输出.用超网络进行文本分类,可以理解为:求输入文本属于每个类别的条件概率,并取拥有最大条件概率的类别作为分类结果:
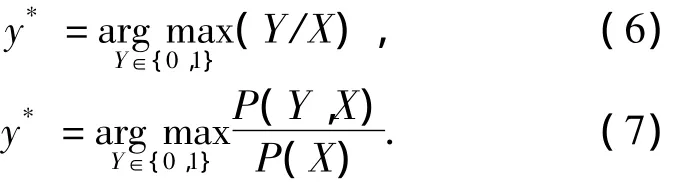
经验概率P(X,Y)可以根据超网络的超边进行点估计得到:
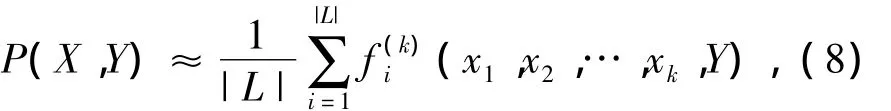
式中:|L|表示超边总数(x1,x2,…,xk,Y)为第i条超边;k为超边的阶数.如果该超边与输入模式X相匹配,则(x1,x2,…,xk,Y)=1,否则(x1,
x2,…,xk,Y)=0.例如,输入模式X=(x1=1,x2=0,
x3=1),某一超边(x1,x2,…,xk,Y),当且仅当超边中顶点x1,x2,x3的取值分别为 1,0,1 时,两者匹配.超网络文本分类过程的具体描述如下:
1)根据超网络的超边集合L进行点估计,得到经验概率分布P(X,Y).
2)输入一个文本Xi.
3)分类文本Xi.
①从L中提取所有与Xi匹配的超边,并加入到集合M中表示所有与X匹配的超i边所占比例,也即是样本Xi被记忆并存储的概率.
②根据类别,将M中的超边分类:将类别为Y的超边归类到)表示样本Xi属于Y类的概率.
③计算y*=
2.3 超网络演化学习
超网络的演化学习是一个不断地对超边进行匹配、选择和放大的过程.由于文中将超边的权值设为其拷贝的数量,因此,给定一个训练集,就可以创建一个由带权值的超边组成的初始化超网络.这些初始的超边经过不断地匹配、替代和放大等演化学习操作,最终形成一种能够准确地拟合训练集数据的概率分布.超网络可以通过演化学习找到一个合适的概率分布,以准确地拟合训练集数据.超网络演化学习的具体步骤如下:
1)初始化.
初始化超边集合为空集L,设置每次迭代被替代超边的最大值为m(m=20 000).对于训练集中的每个样本,随机生成10条阶数为k的超边,初始化超边的适应值为fw=0,fc=0(fw表示超边不能正确分类训练样本时的适应值,fc表示超边正确分类训练样本时的适应值),并加入到集合L中.
2)分类.
用步骤1)初始化得到的超网络对训练样本分类,然后将分类正确的样本加入到集合XC中,分类不正确的样本加入到集合XW中.
3)计算超边适应值.
对于每条超边li,计算它对于XW中的样本xi的适应值.如果该边可以正确分类xi则将适应值设为fw(li)=fw(li)+|Y|-1,否则将适应值设置为fw(li)=fw(li)-1;同样,也计算超边li对于XC中的样本xi的适应值,如果该边可以正确分类样本xi则将适应值设置为fc(li)=fc(li)+|Y|-1,否则将其适应值设置为fc(li)=fc(li)-1.在这里,正确分类时对适应值加|Y|-1,其中|Y|为类别总数.因为随着类别的增加,正确分类样本的超边比例会下降,从而避免很少分类正确的超边获得更高的适应值.
4)排序.
对于所有的超边,先按照fw降序排序,对于有相同fw的超边,按照fc降序排序.
5)计算被替代的超边数目.
s=wr|L|,其中超边替代控制参数w(通过系统试验,文中取w=0.8)用于控制被替代的超边数目,r为步骤 2)中分类不正确的样本比例表示训练集样本数量 )表示超边的总数.如果s大于m,则s=m,且m=0.8s.
6)替代.
根据排序的结果,选取最后s个超边,用与之关联的模式重新产生超边并代替原超边.
7)返回步骤2),直到s=0.
从上述超网络的演化学习过程可以看出超网络的最大超边数是2k×C(n,k),其中n是输入空间维数,k为超边阶数.
3 试验
为了验证演化超网络中文文本分类方法的有效性,文中选用两个目前国内公开的中文语料库.
3.1 试验数据集
试验数据集1来自复旦大学计算机信息与技术系国际数据库中心自然语言处理小组搜集的文本分类语料库(http:∥www.nlp.org.cn/categories/default.php?cat-id=16).该语料库包含20个类别,其中训练语料和测试语料的文档数分别为9 804篇和9 833篇.由于每个类别的文档数分布不均匀,其中少的类别才十几个文档而多的可达几千个,因此文中选取复旦语料库中文档数最多的9个类别进行试验.从这9个类别的训练集中,每类随机选取450个文档,构成包含4 050个文档的训练集;同时也从这9个类别的测试集中,每类随机选取450个文档,构成包含4 050个文档的测试集.
试验数据集2来自搜狐新闻网站保存和整理的新闻语料(http:∥www.sogou.com/labs/dl/c.html).文中使用其中的精简版.此版本包含9个类别,每个类别的文档数都为1 990个.文中把每类中前450个文档作为训练集,再从剩余文档中选取前450个文档作为测试集.因此文中的训练集和测试集文档数都为4 050个.
3.2 分类性能评价
文本分类器的性能通常采用3个指标进行评估:准确率(precision,P)、召回率(recall,R)和F1值,且有:

式中:a为正确判为该类的文本数目;b为错误判为该类的文本数目;c为原本属于该类但是错判的文本数目.以上评价指标只能针对某一类,为了表示分类器在全部类别上的综合分类性能,通常有宏平均和微平均两种方法.文中使用宏平均进行试验数据评价,即在类别之间求取平均值.
3.3 试验结果
演化超网络模型中,超边的阶数设定对分类器的性能有很大影响.为在特定数据集上选取合适的超边阶数,文中分别在数据集1下设置了6组不同的超边阶数(分别为 15,20,25,30,35,40),在数据集2下也设置6组不同的超边阶数(分别为25,30,35,40,45,50).
图3,4分别给出了在数据集1和数据集2中,不同超边阶数设定下的试验结果.两图中的宏准确率、宏召回率、宏F1值均为超网络在不同设定下独立进行20次演化学习的平均测试结果.
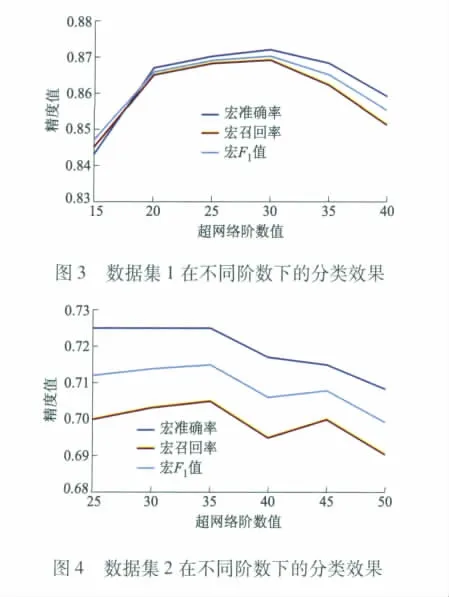
由图3可见,当超边阶数值设置在30左右时,超网络文本分类器的宏准确率、宏回率和宏F1值都是最高的.而当超边阶数小于20或者大于35时,分类性能急剧下滑.图4中,当宏准确率,宏召回率和宏F1值都为最高值时,超边阶数设置是在35左右,小于30或者大于45时,超网络文本分类器的宏准确率、宏回率和宏F1值都有所下滑.上述情况是因为,阶数较小的超边表示信息的一般性能力较强,而阶数较大的超边表示信息的特殊性能力较强.当超边阶数过大或者过小时,都无法兼顾到信息的局部性和全局性.依据试验结果,在数据集1和数据集2上,阶数分别设为30和35时,演化超网络分类器能较好地兼顾到信息的局部性和全局性,具有较强的泛化能力.
为了说明演化超网络模型在中文文本分类应用中的有效性,文中选择了两种传统的文本分类方法:KNN和SVM进行对比.
数据集1的对比试验:对演化超网络(用χ2统计选取400维特征,进行布尔权值计算,阶数定为30),KNN[7]和 SVM[7]进行分类试验.试验结果如表1所示.在宏准确率、宏召回率和宏F1值方面,演化超网络文本分类器分别为87.2%、86.9%和87.0%,都稍优于其他两种传统中文文本分类器.
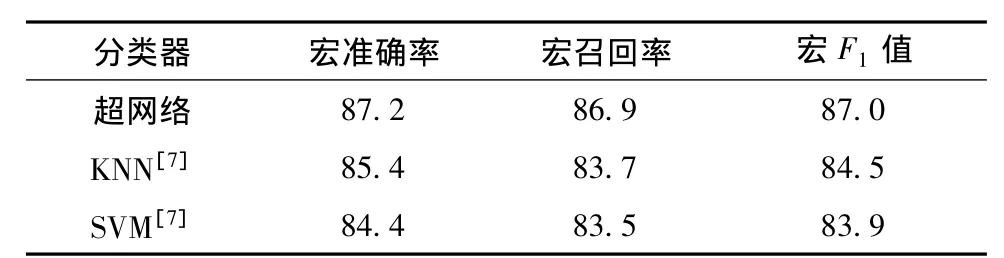
表1 数据集1的试验结果对比 %
数据集2的对比试验:演化超网络,KNN和SVM分类时都采用χ2统计做特征选择,特征数均为800维.演化超网络使用布尔权值计算方法,KNN和SVM采用tf-idf计算权值.演化超网络阶数设定为35,KNN的K值设为28,SVM采用多项式核K(xi,yi)=(xi·yi+1)d,参数d=1.试验结果如表2所示.虽然演化超网络在宏准确率方面比SVM低,但是在宏召回率和综合指标F1值方面都高于SVM和KNN.
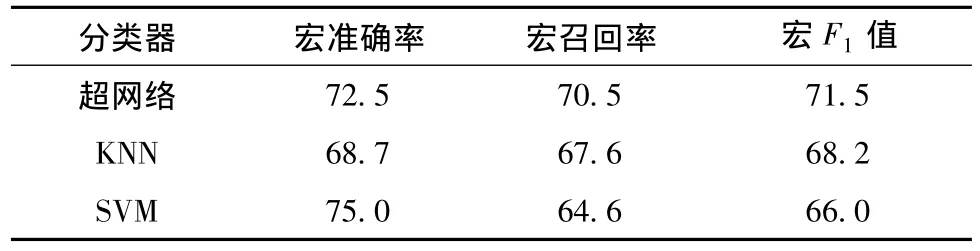
表2 数据集2的试验结果对比 %
4 结论
文中提出了一种基于演化超网络的中文文本分类方法,结论如下:
1)演化超网络文本分类器在复旦大学语料库和搜狐语料库上均取得了较好的效果,并稍优于传统的KNN和SVM分类器.
2)为了进一步提高文本分类器的性能和学习速度,演化超网络学习算法和文本特征提取方法的改进,是今后的工作重点.
References)
[1] Kulesza T,Stumpf S,Wong W K,et al.Why-oriented end-user debugging of naive bayes text classification[J].ACM Transactions on Interactive Intelligent Systems,2011,1(1),doi:10.1145/2030365.2030367.
[2] Hao Xiulan,Tao Xiaopeng,Zhang Chenghong,et al.An effective method to improve KNN text classifier[C]∥Proceedings of the8th ACIS International Conference on Software Engineering,Artificial Intelligence,NetworkingandParallel/DistributedComputing. Quebec:IEEE Computer Society,2007:379-384.
[3] Wang T Y,Chiang H M.One-against-one fuzzy support vector machine classifier:an approach to text categorization[J].Expert Systems with Applications,2009,36(6):10030-10034.
[4] Mann G,McDonald R,Mohri M.Efficient large-scale distributed training of conditional maximum entropy models[C]∥Proceedings of Advances in Neural Information Processing Systems22.Vancouver:Curran Associates,Inc.2009:1231-1239.
[5] 李 文,苗夺谦,卫志华,等.基于阻塞先验知识的文本层次分类模型[J].模式识别与人工智能,2010,23(4):456-463.LiWen,Miao Duoqian,Wei Zhihua,et al.Hierarchical text classification model based on blocking priori knowledge[J].Pattern Recognition and Artificial Intelligence,2010,23(4):456-463.(in Chinese)
[6] 王素格,李德玉,魏英杰.基于赋权粗糙隶属度的文本情感分类方法[J].计算机研究与发展,2011,48(5):855-861.Wang Suge,Li Deyu,Wei Yingjie.A method of text sentiment classification based on weighted rough membership[J].Journal of Computer Research and Development,2011,48(5):855-861.(in Chinese)
[7] 张孝飞,黄河燕.一种采用聚类技术改进的KNN文本分类方法[J].模式识别与人工智能,2009,22(6):936-940.Zhang Xiaofei,Huang Heyan.An improved KNN text categorization algorithm by adopting cluster technology[J].Pattern Recognition and Artificial Intelligence,2009,22(6):936-940.(in Chinese)
[8] Thurber K J,Wald L D.Associative and parallel processors[J].Computing Survey,1975,7(4):215-255.
[9] Lim H W,Lee SH,Yang K A,et al.In vitro molecular pattern classification via DNA-based weighted-sum operation [J].BioSystems,2010,100(1):1-7.
[10] Zhang B T.Hypernetworks:a molecular evolutionary architecture for cognitive learning and memory [J].IEEE Computational Intelligence Magazine,2008,3(3):49-63.
[11] Park C H,Kim S J,Kim S,et al.Use of evolutionary hypernetworks for mining prostate cancer data[C]∥Proceedings of8th Int Symposium on Advanced Intelligent Systems.Heidelberg:Springer-Verlag,2007:702-706.
[12] Bautu E,Kim S,Bautu A,et al.Evolving hypernetwork models of binary time series for forecasting price movements on stock markets[C]∥Proceedings of2009IEEE Congress on Evolutionary Computation.Piscataway:IEEE Computer Society,2009:166-173.
[13] Ha JW,Eom JH,Kim SC,et al.Evolutionary hypernetwork models for aptamer-based cardiovascular disease diagnosis[C]∥Proceedings of9th Annual Genetic and Evolutionary Computation Conference.New York:ACM,2007:2709-2716.
