客户价值关联分析的应用研究——以某零售企业为例
2013-09-18陈忠仁王淑华马淑艳
陈忠仁,王淑华,马淑艳
客户价值关联分析的应用研究
——以某零售企业为例
陈忠仁,王淑华,马淑艳
在如今激烈的市场竞争中,如何赢得客户是很多企业追求的目标。本文从RFM分析入手,通过聚类方法划分出对企业具有不同价值的客户群,通过关联分析找出主要群体所消费产品的品牌之间的关联关系,以分析不同品牌对于不同类型客户的重要性。以期这种方法能为零售企业商品的布局及商品品牌的管理等方面提供一定的决策信息,从而增加企业的盈利能力和客户的满意度,进而达到双赢的目的。
客户价值;关联分析;聚类
陈忠仁/吉林大学工会常务副主席(吉林长春130012);王淑华/吉林大学数量经济研究中心副主任(吉林长春130012);马淑艳/吉林大学研究生院副研究员,硕士(吉林长春130012)。
一、引言
在现今激烈的市场竞争中,对于商业企业来说,仅靠商品本身已很难取胜,企业之间的竞争已更多地转变成如何赢取客户的竞争。因此如何更好地识别出对企业具有不同价值的客户,并根据客户各自不同的特点挖掘其感兴趣的商品信息,从而有针对性地对客户进行营销和管理,尽量增加客户的购买机率并努力维系与最有价值客户之间的关系是许多商家不断追求并努力实现的目标,而基于客户价值的关联分析是实现此目标的有效方式之一。
一些研究表明:客户生命周期值是一种有效地识别不同价值客户的方法,它对于发展针对目标客户的战略具有一定的实际意义,而RFM(R:最近消费时间,F:单位时间内消费频次,M:单位时间内消费金额)模型[1]是衡量客户生命周期的一种有效方法,该模型主要是通过对客户过去消费行为的研究来分析和总结客户的购买特性并预测客户今后的消费行为,从而为企业的决策提供支持。
基于此,本文从RFM分析入手,首先用聚类方法划分出对企业具有不同价值的客户群,通过关联分析找出主要群体所消费产品的品牌之间的关联关系,以分析不同品牌对于不同类型客户的重要性。以期这种方法能为零售企业商品的布局及商品品牌的管理等方面提供一定的决策信息,从而增加企业的盈利能力和客户的满意度,进而达到双赢的目的。最后,本文通过某零售企业2008.06.30—2009.06.29一年的销售数据进行了应用研究。
二、客户价值关联分析
1.客户价值衡量指标:RFM。RFM模型最早是1994年由Stone[2]等学者提出的,Stone等学者认为R、F和M是影响客户价值的三个主要因素,R表示客户最近一次购买时间,为了计量方便,也可以把R当作是客户最近一次购买的时间到统计当日为止这段时间内所持续的天数/周数/月数等,即近度,该值越小,预示着客户再次购买的可能性就越大;也可以把R看做是统计周期的起始日到最近一次购买日期为止这段时间内所持续的天数/周数/月数,即持续采购的时间,该值越大,预示着客户在未来再次购买的可能性就越大。F表示客户在统计周期内购买的次数(频度),客户的购买频度越高就表示该客户越忠诚。M代表客户在统计周期内的消费总额(值度),该值越大,意味着客户对企业的利润贡献越大,企业越应重点关注该客户。因此,企业在衡量客户价值的过程中,需要把R、F和M三个指标综合起来进行考虑。基于此,本文根据这三个指标进行聚类分析来划分出具有不同价值的客户,进而找出不同类别客户的消费产品之间的关联关系,以期能为企业的营销策略提供支撑。
2.基于客户价值的客户分类。客户分类是根据客户的一些购买行为和人口统计特性等把具有相同特征的客户聚集到一起,不同类别中的客户具有显著的差异。本文中所采用的方法是k-均值聚类法,该方法的基本思想是首先随机地从样本数据中选取k个值作为初始聚类中心,然后计算其它样本到每个类中心的距离,进而把其它样本分到离它最近的聚类中心所在的类,这样就完成了一次迭代。接下来重新计算每类的中心,该中心为毎类中所包含样本数据的平均值,若相邻两类的聚类中心没有什么变化,则算法结束。一般来说k的取值范围在2到20之间,对每组样本数据来说,具体的k值可以通过实验的方法来确定,即要选取所有可能的聚类结果中平均方差最小的k,毎个类的方差为该类中每一个样本值与均值之差的平方和。本文首先把反映客户价值的R、F、M三个指标分别聚成k类,然后对聚类后的R、F、M指标进行组合,从而可以得到类客户,不同类别的客户对企业的价值是不同的,在此类客户中有一类客户的R、F、M指标分别都是最佳的,即来店频率高、购买金额多、最近来店时间短,这类客户是最有价值的,他们应该是企业需要重点关注的对象。
3.关联分析。按照上面所述的方法,企业的客户按其价值可以被划分成不同的类,对毎类客户群,由于其购买习惯等特征具有一定的差异,因此本文把Agrawal[3]等人在1993年提出的关联规则方法应用到不同类别的客户群中,以此来寻找不同类别客户所购买产品之间的关联关系,从而有助于企业进行有针对性的营销。关联规则的基本思想[4]是,对于某个企业的交易数据库D来说,设I={i1,i2,…,in}是企业所有商品项的集合,I中的每一个元素都称为项(item),客户的每一次交易都是项的集合T(TI),而且客户的每次交易都有唯一的标识符如TID(Transaction ID)与之相对应。关联规则就是要寻找形如XY的蕴涵式,其中XI,YI,X与Y的交集为空,并且该蕴涵式的支持度和置信度要满足最小支持度(minsupp)和最小可信度(minconf)的条件,最小支持度和最小可信度的阈值都是人为设定的。所说的支持度是指交易数据库集合D中同时包含事务X和事务Y的百分比,该值反映了事务X和事务Y同时出现在交易事务中的频繁程度,支持度较高意味着商品项之间的关联性也比较强;置信度是包含X的事务中同时又包含事务Y的百分比,该值是代表关联规则可靠性的一个参数,置信度较高意味着商品交易项之间的关联显著性[5][6]也比较高。Apriori算法是寻找关联规则的经典算法,运用该算法可以得出商品之间的网络依赖图,从图中可以看出商品之间的关联并可以分析出哪些商品处于核心地位。当然,也可以根据商品品类或商品品牌进行关联。本文下面就是以商品品牌之间的关联关系为例来进行分析的。
三、客户价值关联分析在零售企业的应用
本文从某零售企业2008.06.30—2009.06.29数据出发,对前面文中所述的基于客户价值的不同客户群体消费商品的品牌关联进行了分析。
1.数据清理。在数据收集过程中,原始数据中经常会存在大量的不规范、不合理的数据,这些数据会对正常信息和知识的挖掘造成严重干扰,从而使分析结果偏离真实或不可用,因此,在进行数据分析之前,通常要对数据进行噪声清理,也就是通过数据预处理,清除掉不规范的数据,使分析结果接近真实情况。本次清理过程中,发现数据中存在客户名为空、一人多卡、证件号相同但客户名不同等多种情况,把这些数据通过程序和人工清理后得到在这一年内有消费记录的客户共138305人。
2.聚类。根据企业的交易数据统计出2008.06.30—2009.06.29这个交易周期内每个客户的R、F和M值,进而分别对R、F和M值依次进行聚类,毎个指标都分为三个等级,然后把三个指标组合在一起,得到27类,在此27类中,最有价值的一类客户为1617人,价值最低的一类客户为10454人。
3.基于客户价值的关联分析
本部分分别对前面得出的最有价值、价值最低客户以及全部客户所消费产品的品牌进行关联分析,得出如下的结果。
1)将聚类所得的最有价值的1617人的消费记录取出,把他们所消费商品按品牌进行关联,本文得出如图1所示网络依赖关系(鉴于所得图形较大,本文只给出局部示意图)。
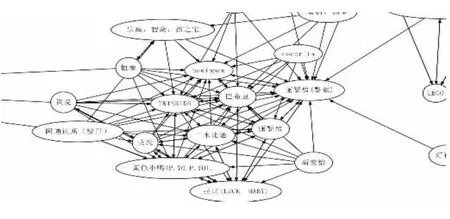
图1 最有价值客户消费产品的品牌网络依赖关系局部示意图
2)将价值最低的一类客户消费商品按品牌进行关联,当最小支持度和最小可信度按常规设置时,几乎没有得到所消费产品的品牌之间的关联,只有当这两个参数值调得非常低时,才得到如下的网络依赖关系,见图2。

图2 最低价值客户消费产品的品牌网络依赖关系
3)将所有客户作为一个整体,对其在消费周期内消费的商品按品牌进行关联分析,设定好最小支持度与最小可信度后,本文得出所有客户的消费商品的品牌之间的网络依赖关系,局部示意如图3和图4所示。
从不同客户群体的消费情况得出的品牌网络依赖图中可以看出,在所有客户消费产品的品牌关联结果中,曼妮芬(MANIFORM)、阿迪达斯(体服)、与欧莱雅共同处于核心地位;在最有价值客户消费产品的品牌关联结果中,巴布豆、丽婴房以及黄色小鸭(P.YO.P.YO)等品牌更多与其他品牌有所关联;对于最低价值客户群,当最小支持度、最小可信度等参数调至极低时,才得出一些规则,关联项目较少。由以上对比可以看出,对于不同特性的客户群,其所需要的商品及品牌是有着明显区别的。了解这些差异可以使企业更好地对商品进行管理,如为了重点关注最有价值的客户群,对于一些儿童品牌企业要引起足够的重视等。同时,针对这些有趣的、有意义的模式,企业可以制定出有效的客户服务和营销策略并在品牌的引进和商品的布局管理等方面有所依据。

图3 所有客户消费产品的品牌网络依赖关系局部示意图

图4 所有客户消费产品的品牌网络依赖关系局部示意图
四、结论
商品和客户一直是零售企业管理中备受重视的领域,如何识别出不同价值的客户群以便进行有针对性的商品促销,如何运用数据库中的数据进行商品的交叉销售,如何对商品的布局管理等提供支持等都是企业所关注的重点。本文利用某企业2008.06.30—2009.06.29一年的销售数据,从RFM分析入手,通过聚类方法划分出对企业具有不同价值的客户群,通过关联分析找出了主要群体所消费产品品牌之间的关联。结果表明:不同价值的客户群所消费的产品品牌之间具有一定差异,这种差异为零售企业在品牌的引进、商品的布局管理等方面的有效决策提供了依据。
:
[1]David Goldberg,David Nichos,Brain M.Oki,and Douglas Terry,Using Collaborative Filtering to Weave an Information Tapestry[J],Communications of the ACM,1992,35(12)61-70
[2]Stone,Bob.Successful Direct Marketing Methods[M].Lincolnwood:NTC Business Books,1994
[3]Agrawal,T.Imielinski,and A.Swami.,Mining Association Rules between Sets of Items in Large Databases.Proceedings of the ACM SIGMODConferenceonManagementofdata,pp.207-216,1993
[4]Sarwar,B.M.,Karvpis,G.,Konstan,J.A.,and Riedl,J.Application of DimensionalitvReductioninRecommenderSystem-ACaseStudy[C].In ACMWebKDDWebMiningforE-Commenceworkshop,2000
[5]蔡伟杰,张晓辉,朱建秋,朱杨勇.关联规则挖掘综述[J].计算机工程,2001(5)
[6]何小东,刘卫国.数据挖掘中关联规则挖掘算法比较研究[J].计算机工程与设计,2005(5)
C931
A
1671-6531(2013)18-0041-02
吉林省科技发展计划项目 (项目编号:20120616)吉林省光电子产业发展态势分析及对策研究
责任编辑:姚 旺
