面向Hadoop的云计算核心技术分析
2013-09-17吴岳忠周训志
吴岳忠,周训志
(湖南工业大学 研究生处,湖南 株洲 412007)
在当今这个信息爆炸的时代,无论是传统企业,还是互联网企业都越来越重视对所有与企业相关的各种数据的分析和利用,对海量数据的处理能力已成为现代企业的核心竞争力之一。云计算(cloud computing)技术的出现为海量数据的处理提供了良好的解决方案[1]。云计算是分布式计算(distributed computing)、并行计算(parallel computing)、效用计算(utility computing)、网络存储(network storage technologies)、虚拟化(virtualization)、负载均衡(load balance)等传统计算机和网络技术发展融合的产物。它是一种通过网络统一组织和灵活调用各种ICT(information communication technology,ICT)信息资源,实现大规模计算的信息处理方式。它利用分布式计算和虚拟资源管理等技术,通过网络将分散的ICT资源(包括计算与存储、应用运行呢平台、软件等)集中起来形成共享的资源池,并以动态按需和可度量的方式向用户提供服务。用户可以使用各种形式的终端(如PC、平板电脑、智能手机甚至智能电视等)通过网络获取ICT资源服务[2]。而Hadoop是云计算技术的一种开源实现,具有高容错、跨平台等优势,用户可以利用Hadoop轻松地组织计算机资源来搭建自己的分布式云计算平台,从而充分地利用集群的计算和存储能力,完成对海量数据的处理工作。
1 Hadoop的平台概述
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台[3]。它的高容错性、高扩展性等优点可以让用户在普通廉价硬件设备上搭建成分布式系统,实现对集群的控制和管理,同时其提供了系统底层细节透明的分布式基础架构,允许用户轻松快捷开发并行应用程序,实现海量数据的管理和分布式数据处理。
Hadoop核心内容为:分布式系统文件(Hadoop distributed file system,HDFS)和MapReduce(Google MapReduce的开源实现)算法模型。HDFS是分布式计算中数据存储管理的基础。它所具有的高容错高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集的应用带来了很多便利。MapReduce是一种编程模型,主要用于对大规模数据集(通常大于1 TB)的并行运算。它借用了函数式编程语言Map(映射)和Reduce(化简)概念,极大地方便软件开发者编写自己的程序并在分布式系统上运行。
Hadoop还包括为子项目提供支持的常用工具Common、用于数据序列化的系统Avro、开源的数据收集系统Chukwa、数据仓库的基础设施Hive、分布式并面向列的开源数据库HBase、对大型数据集进行分析和评估的平台Pig等子项目。 图1展现了Hadoop的项目结构图。

图1 Hadoop的项目结构图Fig.1 Project structure of Hadoop
2 面向Hadoop的云计算核心技术分析
2.1 分布式文件系统HDFS
HDFS是一个分布式文件系统,开始是开源的Apache项目Nutch的基础结构,最后成为了Hadoop的基础架构之一。其设计前提和目标[4]:1)硬件错误是常态而不是异常;2)流式数据访问;3)大规模数据集;4)简单一致性模型;5)移动计算比移动数据更划算。
HDFS是一个主从(Master/Slave)结构模型,见图2。一个HDFS集群是由一个NameNode和若干个DataNode组成。其中NameNode作为主服务器,是整个文件系统的管理节点,负责管理文件系统的命名空间,记录文件数据块在每个DataNode上的位置和副本信息,协调客户端对文件的访问,以及记录命名空间内的改动或命名空间本身属性的改动;集群中的DataNode提供真实文件数据的存储服务,管理其所在物理节点上的数据存储,并负责处理客户的读写请求,依照NameNode的命令,执行数据块的创建、复制、删除等工作。从最终用户的角度来看,HDFS就像传统文件系统一样,可以通过目录路径对文件执行CRUD(create, read, update和delete)操作。而根据分布式存储特性,实际上客户端访问文件系统是通过与NameNode和DataNode的交互实现。例如客户端要访问一个文件,首先,客户端会从NameNode中获得组成该文件的数据块位置详细列表,即可知道数据块被存储在哪些DataNode上;然后,客户端就直接从DataNode上读取文件数据。NameNode在整个过程中不参与文件的传输。
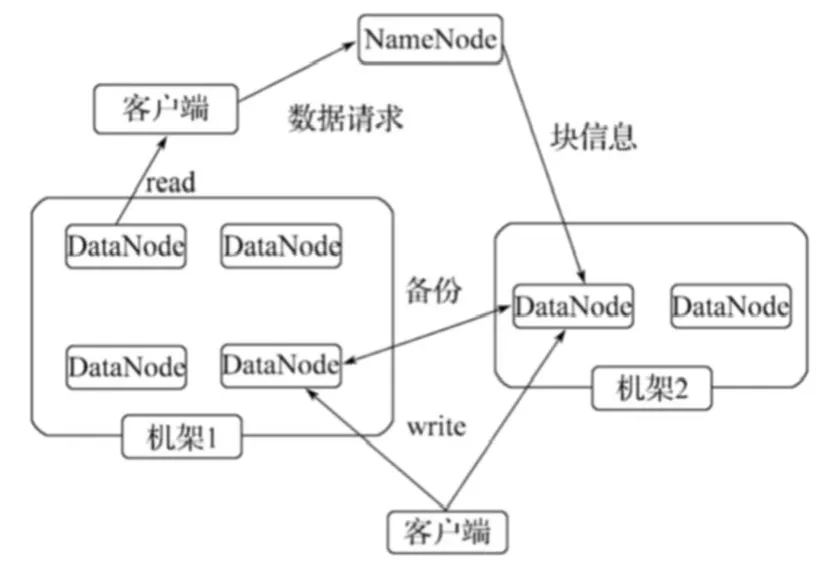
图2 HDFS的体系结构图Fig.2 Architecture of HDFS
2.2 MapReduce计算模型
MapReduce是一种处理海量数据的并行编程模型和计算框架。MapReduce框架由一个单独运行在主节点上的Master JobTracker和运行在每个集群从节点上的Slave TaskTracker共同组成。主节点负责调度构成一个作业的分布在不同从节点上的所有任务。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。当1个Job被提交时,JobTracker接收到提交作业和配置信息后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。MapReduce编程模型的原理是:利用1个输入的key/value对集合产生1个输出的key/value对集合。MapReduce高度抽象出2个函数来表达这个计算:Map和Reduce,Map负责把1个任务分解成多个任务,Reduce负责把分解后的多任务处理结果汇总起来。这2个函数的具体功能可以由用户根据需要自己设计实现,只要能够按照用户自定义的规则,将输入的
在Map阶段,MapReduce框架将任务的输入大数据集分割成固定大小的小数据集片段(splits),随后将每一个split进一步分解成一批键值对
在Reduce阶段,Reducer把从不同Mapper接收来的数据整合在一起并进行排序,然后调用用户自定义的Reduce函数,对输入的
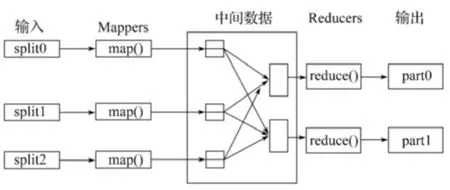
图3 MapReduce大数据集处理过程Fig.3 Large data sef processing of MapReduce
3 面向Hadoop的云计算实例分析
3.1 试验环境
3.1.1 环境及工具
根据前面分析的Hadoop开源平台,Hadoop集群分为两大角色类:Master和Slave,Master主要是部署配置NameNode和JobTracker节点;Slave是部署配置DataNode和TaskTracker节点。在试验中,一共使用3台普通PC机来搭建Hadoop集群,其中1台部署为Master的NameNode和JobTracker。主机上安装的操作系统为Ubuntu 10.04 LTS,Java运行环境为jdk1.6.0_24,Hadoop为Hadoop-0.20.2版本,程序开发平台为eclipse-SDK-3.7.2-linux版本。
3.1.2 环境搭建
1)基础环境。3台PC机,安装好Ubuntu10.04系统、JDK1.6.0_24, openssh-server,设置文件/etc/hosts,/etc/hostname, /etc/profile,定义主机名和IP地址之间的关系及JDK环境变量。
2)实现Master和Slave主机间的SSH无密码登录。3台主机建立同一个用户,然后在Master主机上进行SSH密钥生成,并复制给2台Slave,实现无密码登录。
3)Hadoop安装和配置。在Master主机上安装hadoop-0.20.2, 设置文件conf/Hadoop-env.sh, conf/coresite.xml, conf/hdfs-site.xml, conf/mapred-site.xml, conf/masters和conf/slaves,配置环境变量、hdfs和mapreduce常用的i/o设置、hadoop守护进程,然后把整个Hadoop安装文件复制到2台Slave上。
4)Hadoop运行。先格式化分布式文件系统,然后启动Hadoop守护进程。通过http://master:50030及http://master:50070查看集群状态(master是指NameNode主机IP地址)。
3.2 程序实现
3.2.1 Eclipse开发平台
在1台Slave主机上安装eclipse-SDK-3.7.2-linux,并使用Hadoop在Eclipse中的插件,配置好Hadoop Location(见图4)。这样就可以看到搭建好的Hadoop云计算平台的分布式文件系统,并可以进行文件的上传、下载等操作。
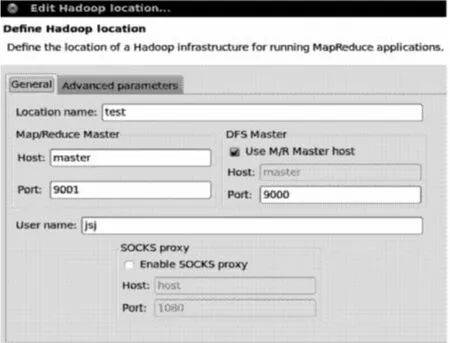
图4 Hadoop Location 配置Fig.4 Configuration of Hadoop Location
本实例中,建立名字为test的Hadoop Location是一个完整的分布式文件系统,分home和user两块。鼠标右击user下的jsj,新建文件夹in,鼠标右击in上传文件text1.txt(内容为:hello hadoop)和text2.txt(内容为:hello world)(见图5)。

图5 Hadoop云计算平台的分布式文件系统Fig.5 Distributed file system of Hadoop-Based computing platform
3.2.2 编译实例
创建一个工程Proj,建立一个WordCount类(见图6),然后进行运行参数设置(见图7),运行程序,完成WordCount实例,计算出单词的数量并排序输出,结果存储在文件夹out(结果为:1个hadoop 1,2个hello,1个world)(见图8)。
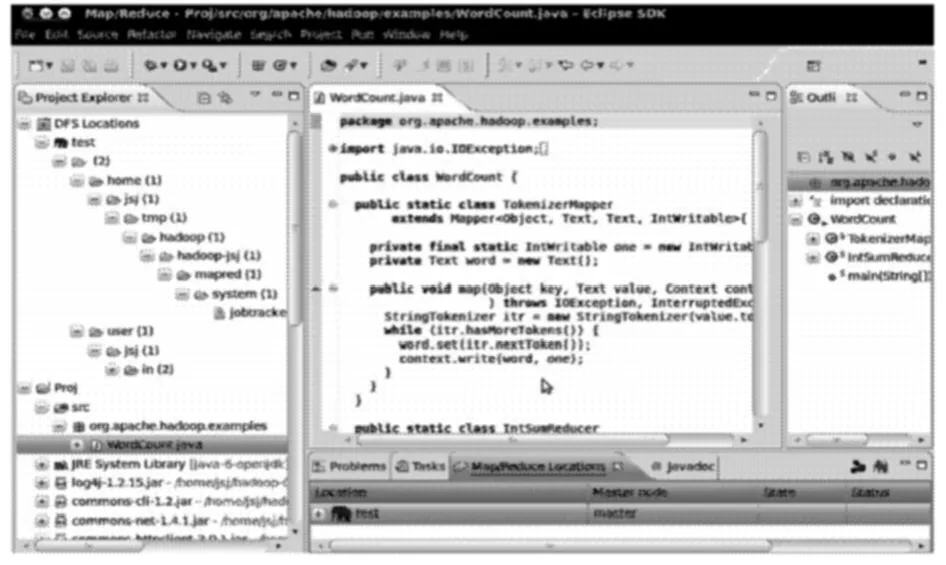
图6 创建工程和WordCount类Fig.6 Create project and WordCount class
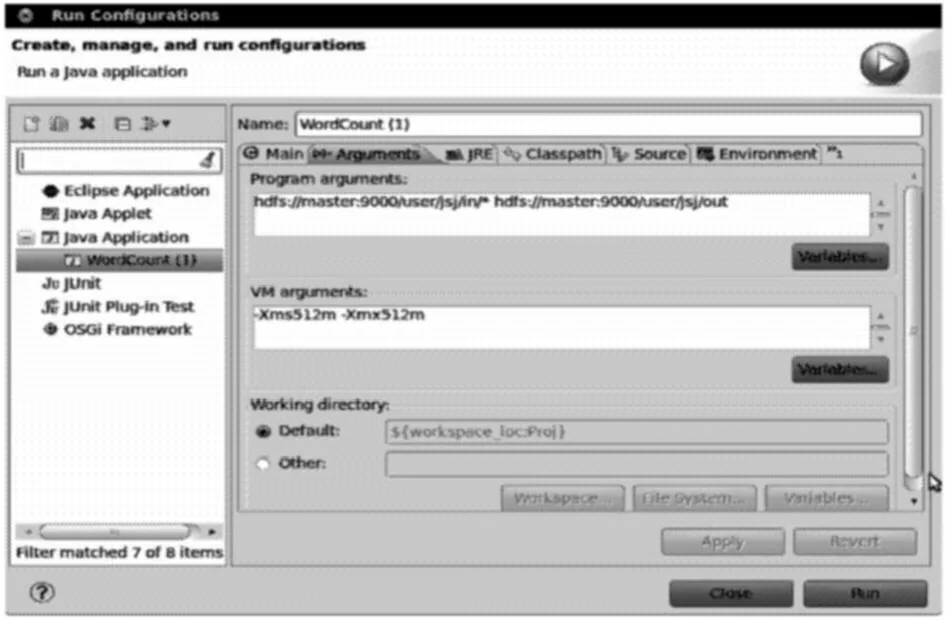
图7 运行参数设置Fig.7 Operation parameters setting
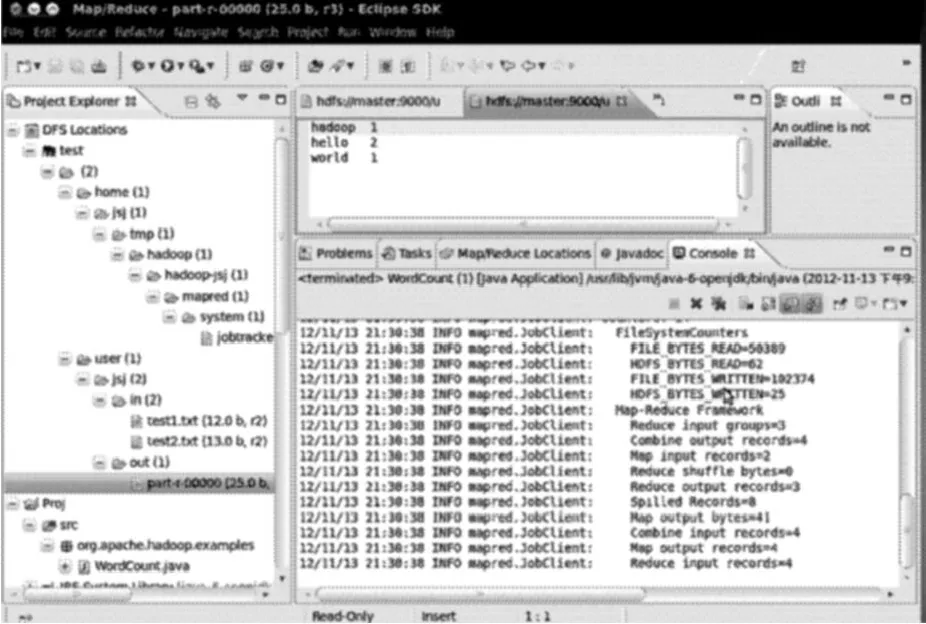
图8 运行结果Fig.8 Operation result
4 结语
本文介绍了云计算的定义和Hadoop核心技术,详细分析了HDFS和MapReduce的工作机制,并阐述了面向Hadoop的云计算平台建立过程,实现了面向Hadoop的云计算架构应用开发,展现了云计算存储和处理数据的能力。随着云计算业务的日益发展,Hadoop平台的研究也会越来越深入,这对Hadoop的高可用性和高效性挑战也会越来越高,如NameNode单点故障、资源管理、作业调度、筛选优化机制等多个方面,这些内容将是下一步的研究工作。
[1] 陈 全,邓倩妮. 云计算及其关键技术[J]. 计算机应用,2009,29(9): 2562-2567.Chen Quan,Deng Qianni. Cloud Computing and Its Key Techniques[J]. Journal of Computer Applications,2009,29(9): 2562-2567.
[2] [佚 名]. 云计算白皮书:2012年[R]. 北京:工业和信息化部电信研究院,2012:1-2.[Anon]. The White Paper of Cloud Computing:2012[R].Beijing:China Academy of Telecommunication Research of MIIT,2012,1-2.
[3] 陆嘉恒. Hadoop实战[M]. 北京:机械工业出版社,2011:2-33.Lu Jiaheng. Hadoop in Action[M]. Beijing:China Machine Press,2011:2-33.
[4] 刘 鹏. 实战Hadoop:开启通向云计算的捷径[M]. 北京:电子工业出版社,2011:2-83.Liu Peng. Practicing Hadoop:The Shortcut for Opening to Cloud Computing[M]. Beijing:Publishing House of Electronics Industry,2011:2-83.
