Unicore架构下的Dalvik虚拟机优化
2013-09-17武建平龙兴闻世
武建平 时 龙兴 凌 明 曹 闻世
(东南大学国家专用集成电路系统工程技术研究中心,南京 210096)
Unicore架构下的Dalvik虚拟机优化
武建平 时 龙兴 凌 明 曹 闻世
(东南大学国家专用集成电路系统工程技术研究中心,南京 210096)
基于Unicore架构,对Dalvik虚拟机进行了移植优化.通过分析Unicore架构下应用程序二进制接口与Dalvik虚拟机的平台相关性,设计实现了jniArgInfo变量字段的布局以及与Dalvik虚拟机平台相关的本地方法调用桥.在设计完成Unicore架构下的快速型解释器入口函数、别名寄存器、汇编宏定义以及汇编版本快速型解释器架构等组件的基础上,结合虚拟机快速型解释器的混合实现机制对Dalvik虚拟机进行了优化,并对优化后Dalvik虚拟机的兼容性、功能、性能进行了测试验证.实验结果表明,优化后的Dalvik虚拟机符合Android系统规范,虚拟机核心部件及Dalvik解释器性能稳定,与优化前相比,系统每秒执行的字节码数目提升达147%.与同类平台的对比测试结果验证了Dalvik虚拟机性能提升的合理性.
Dalvik虚拟机;Unicore;Android;本地方法调用桥;解释器
近年来,随着以智能手机[1]为代表的移动互联终端的飞速发展,与之配套的智能操作系统(如Windows CE和Windows Mobile系列、苹果公司的iOS等)开创了移动智能终端发展的新方向.2007年,Google公司正式发布了第一款 Android系统[2],它是为移动互联终端打造的第一个开放性移动软件平台.为了创建更加开放的开发环境,Google公司组建了开放手机联盟(open handset alliance,OHA)[3],使得设备制造商、处理器原厂、第三方应用开发商等业界产业链围绕Android系统持续发展.从第一款Android手机发布至今不到5年的时间,Android系统已在移动智能终端领域占据了绝对领导地位.
当前,Android系统绝大部分是基于ARM处理器架构的,其主要原因在于:ARM处理器架构功耗较低,Android系统可基于ARM处理器架构进行全面的支持和优化.基于国产 Unicore架构的SoC(system on chip)芯片 SEP6200[4]面向嵌入式移动互联设备,以Android系统为基础软件平台.然而,Android系统并未针对Unicore架构进行支持和优化.
Dalvik虚拟机是Android系统应用程序运行的基础,它通过执行特有的字节码格式——Dalvik字节码来完成对象生命周期、堆栈、线程、安全异常的管理以及垃圾回收等功能.它依赖于Linux内核的部分功能——线程机制和内存管理机制,能高效使用内存,且在CPU低速运行时性能良好.每个Android应用在底层均对应一个独立的Dalvik虚拟机实例.虚拟机的执行引擎负责Dalvik字节码流的解释执行[5].Dalvik虚拟机的解释器提供了多种实现方式,其中快速型解释器提供了一种允许混合使用汇编语言和C语言来实现解释例程的机制.与传统Java虚拟机相比,Dalvik虚拟机的最大特点是拥有专用的Dex文件[6];相对于Class文件,Dex文件更紧凑,内存占用更小,同时Dalvik字节码在执行性能上比Class字节码更胜一筹.从执行流程分析,Dalvik虚拟机主要由加载器子系统、执行引擎和内存管理模块组成.Dalvik虚拟机的实现离不开Dx工具、Dalvik字节码指令集、运行时常量区等部分.
本文基于Unicore架构进行Android系统中核心模块 Dalvik[7]虚拟机的移植与优化,使得 Android系统能够流畅运行于SEP6200处理器平台,主要围绕Dalvik虚拟机的实现与优化2个方面展开.首先,通过分析Unicore架构下应用程序的二进制接口和Dalvik虚拟机的平台相关性,设计了jniArgInfo变量字段的布局.然后,结合Unicore架构的特点,实现了本地方法调用桥.设计实现了基于Unicore架构的汇编版本快速型解释器的多个组件,主要包括快速型解释器入口函数、别名寄存器、汇编宏定义以及汇编版本快速型解释器架构,并利用快速型解释器的混合编程机制,通过别名寄存器、数据布局以及汇编型快速解释器的构建,完成Dalvik虚拟机的优化.
1 Dalvik在Unicore架构下的实现
Java语言本身具备平台无关性,但Dalvik虚拟机引入的 JNI(Java native interface)机制[8-9]使得虚拟机的实现与平台紧密关联.Dalvik虚拟机可屏蔽平台间的差异性,故Java语言编写的Android应用程序可以在任何平台上运行.在Dalvik虚拟机中,当Java方法通过JNI机制调用本地方法时,需要将Java方法中的参数传递给本地方法,而本地方法参数的传递在不同平台下存在着各自的约束[10].为了在不同平台上实现本地方法参数的传递,在JNI架构中设计了本地方法调用桥.
Unicore架构下,Dalvik虚拟机的移植实现关键在于本地方法调用桥的实现.它隶属于JNI机制,与数据类型在内存中的对齐要求和函数调用规范相关.本节主要围绕本地方法调用桥的实现展开,简单介绍了 JNI机制及 Unicore架构下 ABI(application binary interface)中的数据类型布局、寄存器使用和函数调用规范.
1.1 JNI机制
Android应用框架层中的API(application port interface)通过 JNI机制与系统动态库或 HAL(hardware abstract level)等本地代码相关联.这些本地方法通过Dalvik虚拟机中的一个工具库nativehelper注册到系统,在Java程序中调用这些本地方法时用native关键字声明即可.
JNI机制的调用方法包括以下2个方面:Android系统提供的本地方法和应用程序中性能关键部分使用的本地方法.前者以系统动态库的形式存在,后者以应用自带动态库的形式存在于 APK(Android package)中.JNI机制在 Android系统中的调用方法如图1所示.
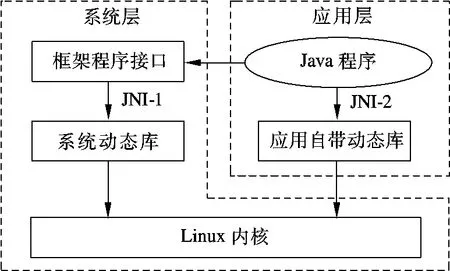
图1 JNI机制在Android系统中的调用流程
JNI机制实现的核心数据结构是 JNINative-Method.该结构体包含JNI函数的名称、参数和返回值的类型签名以及JNI函数对应的本地语言(C/C++)的函数指针等重要成员.多个JNINativeMethod结构体变量组成的数组可以完整地描述一组本地方法,是连接Java方法和本地方法的桥梁.本地方法列表将作为参数传递给registerNativeMethods函数,该函数通过调用JNI机制提供的jniRegisterNativeMethods函数对本地方法进行注册.至此,本地方法已注册到系统,可供基于Java语言编写的上层应用程序直接调用.
1.2 Unicore架构下的ABI
通过定制Unicore架构下的ABI,使得独立编译、汇编得到的代码可以被正确地链接、执行.ABI主要包括存储布局(数据类型布局)、寄存器的使用和函数调用规范3个方面的内容.
1.2.1 数据类型布局
Unicore采用小端(小印地安序)存储,定义8 bit为 byte(字节)、16 bit为 half-word(半字)、32 bit为word(字),可寻址最小单位为byte.它采用load/store体系结构,对 byte,half-word,word数据的读取和存储分别由 ldb/std,ldh/sth,dw/stw等指令完成.除基本数据类型外,结构体、联合、枚举、数组等数据类型在内存中的布局也有各自的要求.对Unicore架构下的基本数据类型在内存中的对齐方式进行以下说明:所有数据类型对齐方式最大为4 byte对齐,包括大小为8 byte(64 bit)的 long long和double双精度类型数据.与此对应的函数栈起始地址也是4 byte对齐.
1.2.2 寄存器的使用
Unicore体系结构提供了46个通用寄存器、1个程序计数器和6个状态寄存器.与ARM体系结构相同,这些寄存器并非同时可见,不同操作模式决定着哪些寄存器可见.
同一时刻一种模式下可见的寄存器包括31个通用寄存器、1个程序计数器(PC)和1个或 2个状态寄存器,宽度均为 32 bit.Unicore架构下的寄存器比ARM架构多一倍,这在 RISC(reduced instruction set computing)体系架构中占据一定的优势.但这种优势也是相对的.例如,在15个寄存器足够使用的情况下,并不能体现31个寄存器的优势.特定情况下可利用寄存器数目多的优势为Unicore架构作进一步优化.各种模式下寄存器的使用由硬件决定,软件层同样存在着寄存器的使用规则[4].
1.2.3 函数调用规范
Unicore架构中的栈采用满递减栈,数据的对齐依赖于其在内存中的对齐方式.保存在栈中的局部变量会按照对齐方式对变量存放的位置进行调整,使其占用的空间最小.最佳方式是将局部变量存放在变量寄存器(R17~R25)中,此时,保存在寄存器中的变量读取效率要比存放在栈中的变量高很多.
Unicore架构提供了若干指令以支持函数调用.最方便的方式是采用BL指令,它会自动将返回地址(当前PC地址后的第4个地址)压入LR(连接寄存器)中,PC寄存器会得到即将被调用的函数的入口地址.使用BL的结果是将控制权转交给被调用函数,栈和所有变量寄存器均为被调用函数服务.LR作为隐式参数传递给被调用函数,以保证函数的正确返回.
调用函数时应遵循相应的传参规则,类似于ARM架构的ATPCS(ARM-thumb procedure call standard).在Unicore架构下,总是使用R0~R3传递前16 byte数据,其他参数则通过栈进行传递.传参类型按以下规则进行:小于4 byte的类型提升为4 byte,保证符号位不变.将64 bit数据作为2个32 bit数据进行处理,并将这2个数据存放在连续的存参空间(依次为 R0,R1,R2,R3和栈)中,高 32 bit数据在后,低32 bit数据在前.存参空间被视为一段连续的地址空间,由寄存器和本地栈部分构成.将函数参数按照上述参数类型转换规则转换成以32 bit为单位的参数数据流,按由低到高的顺序依次填充即可.
基本类型的最大数据宽度为64 bit,将它作为返回值时最多需要2个寄存器.在Unicore架构下,将标量类型作为返回值时的规则如下:小于或等于1 word的整形数据返回时,使用R0寄存器;64 bit整形数使用R0,R1寄存器,其中高32 bit数据在R1中;单精度数据使用f0返回;双精度数据使用f0,f1返回,高32 bit数据在f1中.
1.3 本地方法调用桥的设计与实现
利用JNI机制调用本地方法,实现参数传递的机制被称为本地方法调用桥.其实现的关键在于如何填充jniArgInfo变量字段以得到准确的栈空间大小以及如何将参数传递给本地方法.填充好的jniArgInfo变量将被作为参数传递给dvmPlatformInvoke函数,该函数用于处理参数传递并完成本地方法调用.
jniArgInfo变量携带了参数传递时本地栈需要预留的空间大小信息,它的设计与Unicore架构下栈入口地址的对齐方式以及数据在栈中的对齐方式相关.Unicore架构下栈入口地址为4 byte对齐,jniArgInfo只需要记录3类信息:参数个数是否合法、返回值类型和参数个数.jniArgInfo变量字段的布局如图2所示.图中每个字母代表1 bit,具体定义如下.
S位(bit31):该位为符号位,用来标识参数个数是否合法.受Dex文件限制,参数个数不能大于0xFFFF.当参数个数超过0xFFFF时,S位会被写入“1”而被置位;
R位(bit28~bit30):用来表示本地方法返回类型.
H位(bit0~bit27):用来记录参数在存参空间的本地栈部分所占空间大小(以32 bit为单位).由于参数个数最大为0xFFFF,因此需要将H位重新布局.重新布局后的结果如图3所示.

图2 jniArgInfo布局

图3 H bit布局
图3中,Z位为预留位,可以清零;A位记录了传递参数时本地栈需要预留的空间.jniArgInfo变量字段的填充在dvmPlatformInvokeHints函数中进行,实现的核心是解析signature类型签名(表示调用方法的返回值类型、参数类型等信息)以得到jniArgInfo变量的S位、R位和A位.当参数个数大于0xFFFF时,则会调用dvmAbort异常函数中止虚拟机,其原因是当一个本地方法的参数数目超过0xFFFF时,即使符合语法规则也已经不是一个正常的本地方法.
实现本地方法调用桥的关键部分包括参数传递、本地方法调用及返回,这些功能均由dvmPlatformInvoke函数实现.实现流程如图4所示.

图4 dvmPlatformInvoke函数的实现流程
本地方法调用桥的核心功能是将解释器栈中的参数传递给本地方法栈,进行本地方法调用.参数的传递过程如图5所示.
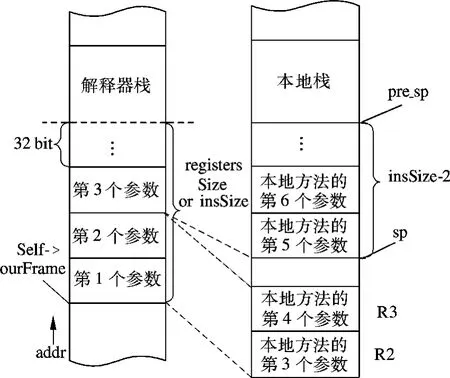
图5 本地方法的参数传递示意图
2 Dalvik虚拟机的优化
Mterp解释器[11]是Dalvik虚拟机执行引擎的核心.在没有实现JIT时,Mterp解释器充当了执行引擎的角色.Dalvik虚拟机为Mterp解释器提供了多种实现方式,包括调试型、可移植型和快速型解释器.本文主要通过别名寄存器来存储关键的变量数据;构建汇编宏定义以表示具有特定意义的常用操作;构建汇编版本的解释例程以实现汇编版本快速型解释器,对Dalvik虚拟机进行优化.
2.1 别名寄存器
在Unicore架构下,使用汇编实现快速型解释器时,寄存器需要遵守EABI(embedded application binary interface)使用规则.在Mterp解释器中,需要经常使用几个特定的变量或数据,可以利用EABI寄存器使用规则为它们分配空闲、合适的寄存器,最大限度地减少内存访问.这些变量并不在同一函数内,因为如果它们在同一函数内,编译器即可为它们分配更加合理的寄存器,而无需利用EABI规则.因此,将与这些变量相关的函数采用汇编语言重写,可以提升解释执行的效率.事实上,以dvm-MterpStdRun函数作为入口函数的Mterp解释器,采用汇编语言重新编写,可以最大限度地利用别名寄存器的优势,将所需要的数据直接写入指定寄存器或从指定寄存器中读取.此时,别名寄存器充当着全局变量的角色.
2.2 汇编宏定义
汇编版本快速型解释器构建了一系列汇编宏定义,以表示特定的常用操作,这些操作构成了解释例程的基本功能.汇编宏的构建为编写汇编解释例程带来了极大便利,使得在实现解释例程时可以更多地关注解释例程本身的功能.部分汇编宏的定义见表1.
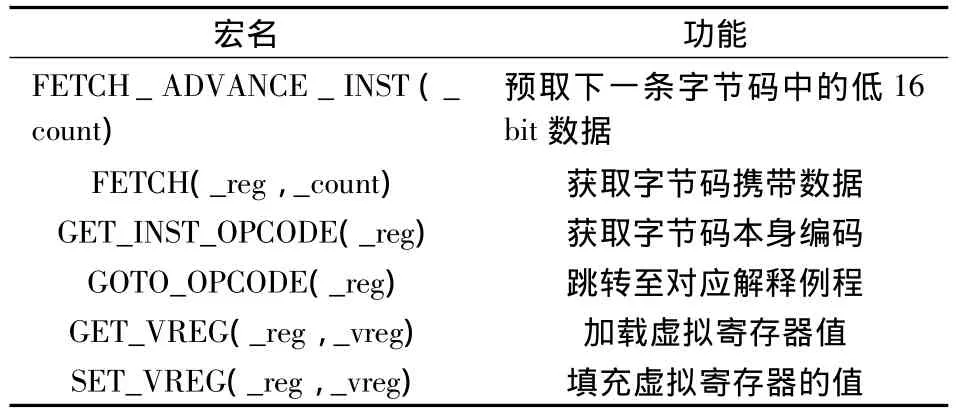
表1 汇编宏定义表
2.3 汇编版本快速型解释器的构建
汇编版本快速型解释器的入口函数与C语言版本的入口函数保持一致,均为dvmMterpStdRun函数.汇编版本中的入口函数需要完成以下操作:①本地栈入栈,保存现场;② 将本地栈堆栈指针SP保存到glue结构体中的bailPtr变量中,作为返回地址;③ 初始化rGLUE,rPC,rFP,rIBASE别名寄存器;④ 检测glue结构体中的entryPoint成员,判断是否为常规字节码,若不是则进行返回、异常等相应处理,若是则从rPC指向的字节码开始加载、解释执行.对于入口函数,汇编版本快速型解释器必须实现其出口函数,当执行到return等字节码时则会调用出口函数,从而使解释器退出连续解释执行的状态.出口函数完成如下操作:①恢复本地栈堆栈指针SP;②将第2个参数作为返回值返回;③本地栈出栈,恢复现场.
在汇编版本快速型解释器中,为了使字节码连续执行,在每个解释例程的尾部都会对下一条字节码进行预取操作,这与其他解释器的实现一致.但其他解释器是通过调用解释例程、查表来确定入口地址的,查表意味着内存存取操作.在汇编版本快速型解释器中,则可以通过巧妙的设计跳过此操作(见图6).汇编版本快速型解释器的解释例程限制在64 byte空间内.若64 byte无法完成解释例程功能,则在dvmAsmSisterStart函数开始的地方(即附加段)继续解释工作,2段代码间通过条件或无条件跳转连接.256个解释例程按照编码大小从dvmAsmInstructionStart函数的地址开始依次排列,其中dvmAsmSisterStart函数的起始地址为64 byte对齐,不足64 byte的解释例程用空指令填充至64 byte.每一个解释例程的起始地址均为64 byte对齐,这种对齐方式与Cache行大小相匹配,可以加速解释例程的执行.与可移植型解释器和C语言快速型解释器相比,汇编版本快速型解释器具有如下优势:①可利用别名寄存器加速常用变量的存取;②解释例程描述的功能与汇编语言描述的功能接近,存在大量位段数据的存取操作,使得汇编语言的执行效率明显高于高级语言;③ 通过对解释例程巧妙设计,避免了确定入口地址时的查表操作,利用代码段缓冲行对齐的特点,最大限度提升了解释执行效率.
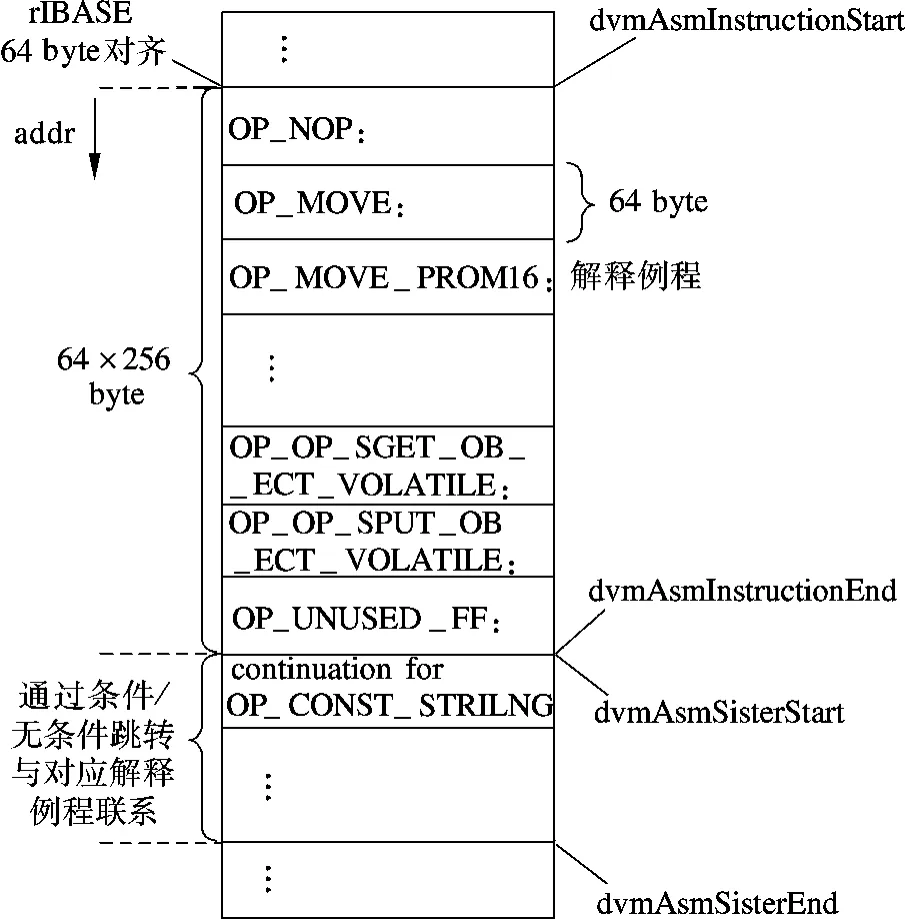
图6 汇编版本快速型解释器的解释例程框架
3 实验与分析
下面从2个方面对Unicore架构下的Dalvik虚拟机性能进行测试验证.首先,将汇编版本快速型解释器与C语言版本快速型解释器、可移植型解释器的性能进行比较,分析性能差异的原因.然后,将SEP6200处理器和S3C6410平台[12]下Dalvik虚拟机优化前后的性能进行对比分析.测试硬件平台参数见表2.测试软件选用专业虚拟机性能测试软件 CaffeineMark[13].测试项目包括 Sieve,Loop,Logic,String,Float,Method 和 Overall[14].测试结果与CPU主频相关,与内存大小无关.所有测试结果均为多次测试结果的平均值.

表2 对比测试软硬件平台参数
3.1 优化前后的性能分析
表3列出了可移植型解释器、C语言版本快速型解释器和汇编版本快速型解释器三者的对比数据.由表可知,可移植型解释器与C语言版本快速型解释器均为thread分发机制,两者均需通过查表确定下一个解释例程的入口地址.但前者的每个解释例程入口地址为标签,解释例程之间通过goto语句直接跳转至标签;后者的每个解释例程对应一个函数,解释例程之间通过函数调用首尾相连.由于函数调用比goto语句执行耗时更长,因此,后者的性能略低于前者.从测试结果来看,前者比后者整体性能提高约6%.
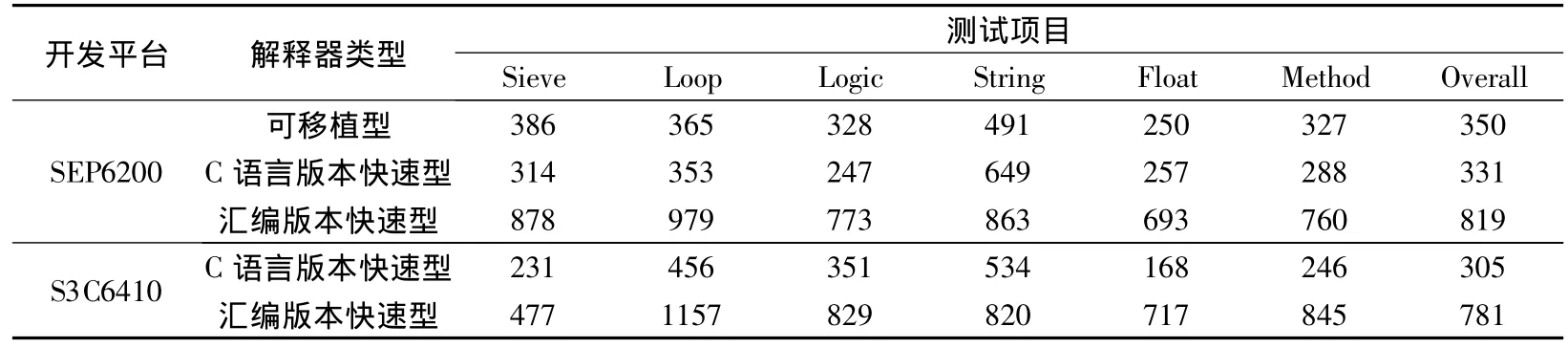
表3 Dalvik虚拟机解释器的性能对比 字节码/s
汇编版本快速型解释器的执行速度是C语言版本的2.47倍,其原因在于:① 别名寄存器的使用可以减少对内存的访问次数,提升解释例程的性能.②汇编版本解释器架构下,可以不经过查表就能获取下一个解释例程的入口地址;而在C语言版本快速型解释器中,则需通过查表操作才能确定下一个解释例程的入口地址.
3.2 优化后的虚拟机性能
对比测试平台为S3C6410平台.软、硬件平台参数信息对比见表2.
测试数据包括C语言版本快速型解释器和汇编版本快速型解释器在2个平台下Dalvik虚拟机的性能数据以及优化前后性能的对比数据.
由表3可知,与C语言版本快速型解释器相比,Unicore架构下的Dalvik虚拟机采用汇编优化后,整体性能提升高达147%.2款平台的对比实验结果显示:基于S3C6410平台,与C语言版本快速型解释器相比,汇编版本快速型解释器可实现2.56倍的性能(即程序执行速度)加速比.该结果比在SEP6200平台下采用汇编优化后,与C语言版本快速型解释器相比能达到的性能加速比(2.47倍)略高.与C语言版本快速型解释器的性能进行对比是为了具体量化基于SEP6200平台优化前后Dalvik虚拟机的性能提升幅度.与S3C6410平台下汇编版本快速型解释器的性能数据进行对比,是为了验证SEP6200平台下优化后的Dalvik虚拟机的性能提升是否合理.优化前SEP6200平台下虚拟机的性能较S3C6410平台下虚拟机的性能略高,尤其是Sieve,Float子项数据更为明显,说明SEP6200平台下虚拟机的整点、浮点运算性能更高.鉴于Unicore汇编指令集的因素,汇编优化后并没有延续优化前的所有优势,但SEP6200平台下虚拟机的总体性能与S3C6410平台下虚拟机的总体性能相当,充分验证了本文针对Unicore架构下Dalvik虚拟机提出的优化方案的有效性.
4 结语
本文在Unicore架构下完成了Dalvik虚拟机的移植.重点分析了Dalvik虚拟机与CPU处理器架构相关的部分,包括虚拟机的 JNI机制以及Unicore架构的ABI.实现了本地方法调用桥,构建了Unicore架构下汇编版本快速型解释器的各个组件,并利用快速型解释器提供的汇编语言和C语言的混合解释机制,对Unicore架构下的Dalvik虚拟机进行了性能优化.实验结果显示,无论是优化前后的纵向对比还是与同类平台的横向对比,本文提出的Dalvik虚拟机优化方案均能明显提升虚拟机性能.
[1]Wikipedia.Mobile operating system[EB/OL].(2011-06-10)[2011-11-15].http://en.wikipedia.org/wiki/Mobile_operating_system.
[2]Wikipedia.Android(operating system)[EB/OL].(2011-06-10)[2012-01-13].http://en.wikipedia.org/wiki/Android_(operating_system).
[3]Open Handset Alliance.Open handset alliance[EB/OL].(2010-09-20)[2011-12-14].http://en.wikipedia.org/wiki/Open_Handset_Alliance.
[4]Prochip Corporation.SEP6200 设计文档[EB/OL].(2010-12-11)[2012-01-14].http://www.prochip.com.cn/product_show.asp?detailid=27.
[5]Lee Y M,Tak B C,Maeng H S,et.al.Real-time Java virtual machine for information appliances[J].IEEE Transactions on Consumer Electronics,2000,46(4):949-957.
[6]Google Corporation..dex—Dalvik executable format[EB/OL]. (2011-06-10)[2011-11-25].http://source.android.com/tech/dalvik/dex-format.html.
[7]Chang C W,Lin C Y,King C T,et al.Implementation of JVM tool interface on Dalvik virtual machine[C]//Proceedings of2010International Symposium on VLSI Design Automation and Test(VLSI-DAT).Hsin Chu,Korea,2010:143-146.
[8]Vladislav Tcheprasov.Template-generated JNI[J].Journal of C&C++Users,2004,22(8):38-39.
[9]Bi Lingyan,Wang Weining,Zhong Haobin,et al.Design and application of remote control system using mobile phone with JNI interface[C]//Proceedings of2008International Conference on Embedded Software and Systems Symposia.Beijing,China,2008:416-419.
[10]Qi Minglong,Guo Qingping.Implementing and invoking a remote object calling native methods via RMI-IIOP and JNI[C]//Proceedings of2004International Symposium on Distributed Computing and Applications to Business,Engineering and Science.Wuhan,China,2004:451-456.
[11]Ogata Kazunori,Komatsu Hideaki,Nakatani Toshio.Bytecode fetch optimization for a Java interpreter[C]//Proceedings of the10th International Conference on Architectural Support for Programming Languages and Operating Systems.New York,USA,2002:58-67.
[12]Samsung Corporation.S3C6410 application processor[DB/OL].(2008-04-01)[2011-12-16].http://www. samsung. com/global/business/semiconductor/product/application.
[13]Pendragon Software Corporation.CaffeineMark 3.0 information[EB/OL].(1997)[2011-11-21].http://www.benchmarkhq.ru/cm30/info.html#Overview.
[14]Google Corporation.Compatibility test suite[EB/OL].(2011-06-10)[2012-01-11].http://source.android.com/compatibility/cts-intro.html.
Optimization of Dalvik virtual machine based on Unicore architecture
Wu Jianping Shi Longxing Ling Ming Cao Wenshi
(National ASIC System Engineering Research Center,Southeast University,Nanjing 210096,China)
Based on the Unicore architecture,the Dalvik VM(virtual machine)is transplanted and optimized.First,the relationships between the application binary interfaces of Unicore and Dalvik VM platform are analyzed,and the layout of jniArglnfo's variable field and JNICallbridge(Java native interface Callbridge)which relates with the Dalvik VM are implemented.After several components of the fast interpreter,which includes the entry functions,alias registers,key assembly macro definitions and architecture in assembly version based on Unicore,are implemented,the Dalvik VM is optimized with the mixed mechanism advantage of the fast interpreter.The compatibility,function and performance of the optimized Dalvik VM are tested and verified.The experimental results show that,compared with the system before optimization,the Dalvik VM based on the Unicore architecture fully complies with the Android system.The core partitions and the whole Dalvik interpreter are robust and run steadily.The number of executed bytecode is speedup by 147%per second,and the rationality of the performance gains are verified by comparing with other similar platforms.
Dalvik virtual machine;Unicore;Android;native interface Callbridge;interpreter
TN302
A
1001-0505(2013)01-0017-07
10.3969/j.issn.1001-0505.2013.01.004
2012-05-22.
武建平(1977—),男,博士生;凌明(联系人),男,博士,副教授,trio@seu.edu.cn.
国家科技重大专项资助项目(2009ZX01031)、江苏省"青蓝工程"资助项目.
武建平,时龙兴,凌明,等.Unicore架构下的Dalvik虚拟机优化[J].东南大学学报:自然科学版,2013,43(1):17-23.[doi:10.3969/j.issn.1001-0505.2013.01.004]
