基于SQLServer的煤炭产量统计方法设计与实现
2013-09-13李丽宏徐文举
李丽宏,徐文举
(太原理工大学 信息工程学院,太原030024)
随着国民经济的迅速发展,煤炭行业进入了前所未有的局面。煤炭行业的发展壮大带来了管理模式的改革,其采煤工作机制为每天三班循环制。一些煤矿将每班的产量作为该班绩效考核标准的一部分,这使得煤矿超能力生产问题愈演愈烈。引起超能力生产的原因主要有:各别煤矿追求利润最大化、煤炭市场混乱和恶性竞争、法制不健全、各种税费对煤矿压力过大以及治理煤矿超能力生产力度不够等。煤矿超能力生产现象的危害主要有:扰乱煤炭行业市场、设备超负荷运转、降低了税收征管质量和工作效率、影响了煤矿的安全生产状况、扰乱社会经济发展。为了更好的将煤矿的产量加以统计并且上报,设计了一种算法优良、简单高效、实用价值高的基于SQLServer的煤炭产量数据统计方法。
1 系统设计
1.1 系统整体架构
系统整体架构如图1所示,WinCE仪表计算出煤炭产量后,将产量数据通过煤炭专网上传到本地的电脑。本地所实现的功能只是针对本煤矿的产量数据,不涉及其他煤矿的产量数据。本地的数据经过计算,以班产量的形式对产量数据进行本地保存。本地电脑配有一台热备电脑,用于数据的备份和冗余。
1.2 服务软件整体设计
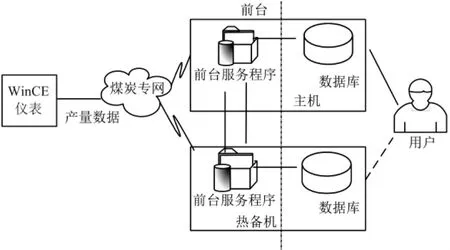
图1 系统整体架构图
系统服务软件以Microsoft Visual Basic 6.0为开发环境,以Microsoft SQL Server 2005做后台数据库支撑。软件中对称重数据及设备状态信息通过与称重仪表Winsock通信的方式获取,采用新的产量统计算法,降低了软件开发的难度;主备机之间采用Winsock通信,不仅实现了对两个工控机产量数据和设备状态信息的统一处理,而且降低了系统的复杂程度,使得煤矿工作人员更容易操作。在Microsoft Visual Basic 6.0开发环境中,利用Winsock控件来实现客户端和服务器的连接。通过网络将WinCE仪表的通讯数据进行接收,然后根据其通信协议对数据进行分解和重新组合,以实现系统的功能要求。最后将收到的数据按照三班循环机制以一定的格式保存到SQLServer2005数据库中,进而完成班、日、月、年产量的查询。服务软件具有用户管理设置、历史数据查询、报表打印等功能。软件设计流程如图2所示。
2 产量统计算法设计
2.1 基于插入排序的班次统计算法
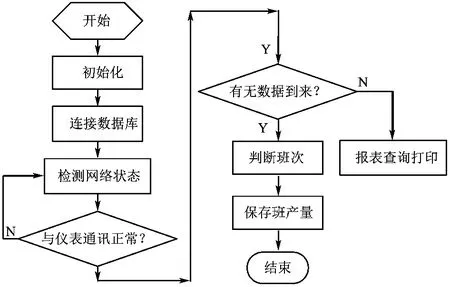
图2 服务器端软件流程图
有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序,这个时候就要用到一种新的排序方法——插入排序法,插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,是稳定的排序方法。
要统计班产量就要根据煤矿的实际情况,确定其交班时间,并计算当前时间所在的班次。由软件记录下当前班的开始时间,当交班时间到达时计算当班的产量,并把数据保存到数据库。根据煤矿不同的交班时间需要设置四个全局变量,即三个交班时间JBTime1、JBTime2和JBTime3,当前时间CurrentTime,三个交班时间可以通过软件设置,其循环机制如图3所示。即每天24h内,JBTime1、JBTime2和JBTime3循环进行。考虑到00:00这一特殊时间点可能所在的时间段,如图4所示,将当前时间所处的班次判断分为三种情况。第一种为00:00在JBTime1和JBTime2之间,第二种为00:00在JBTime2和JBTime3之间,第三种为00:00在JBTime3和JBTime1之间。
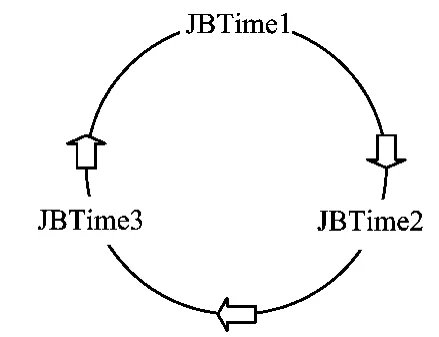
图3 交班时间循环机制图
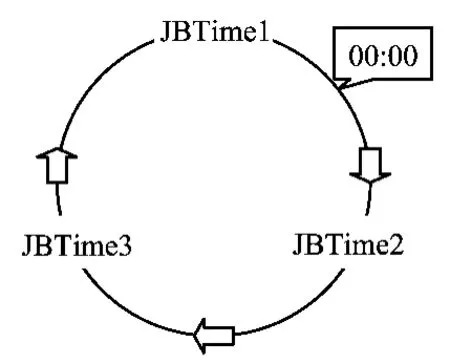
图4 加入0时刻交班时间循环机制图
并在定时器里将当前时间与此三种情况下与各交班时间比对,得出当前时间所在的班次:
1)00:00:00≤JBTime1And JBTime1<JBTime2And JBTime2<JBTime3And JBTime3≤23:59:59,此情况算法流程图如图5所示。
2)00:00:00≤JBTime3And JBTime3<JBTime1And JBTime1<JBTime2And JBTime2≤23:59:59此情况算法流程图如图6所示。
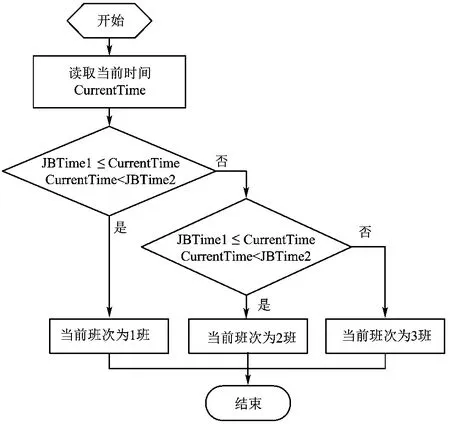
图5 第一种情况班次算法流程图
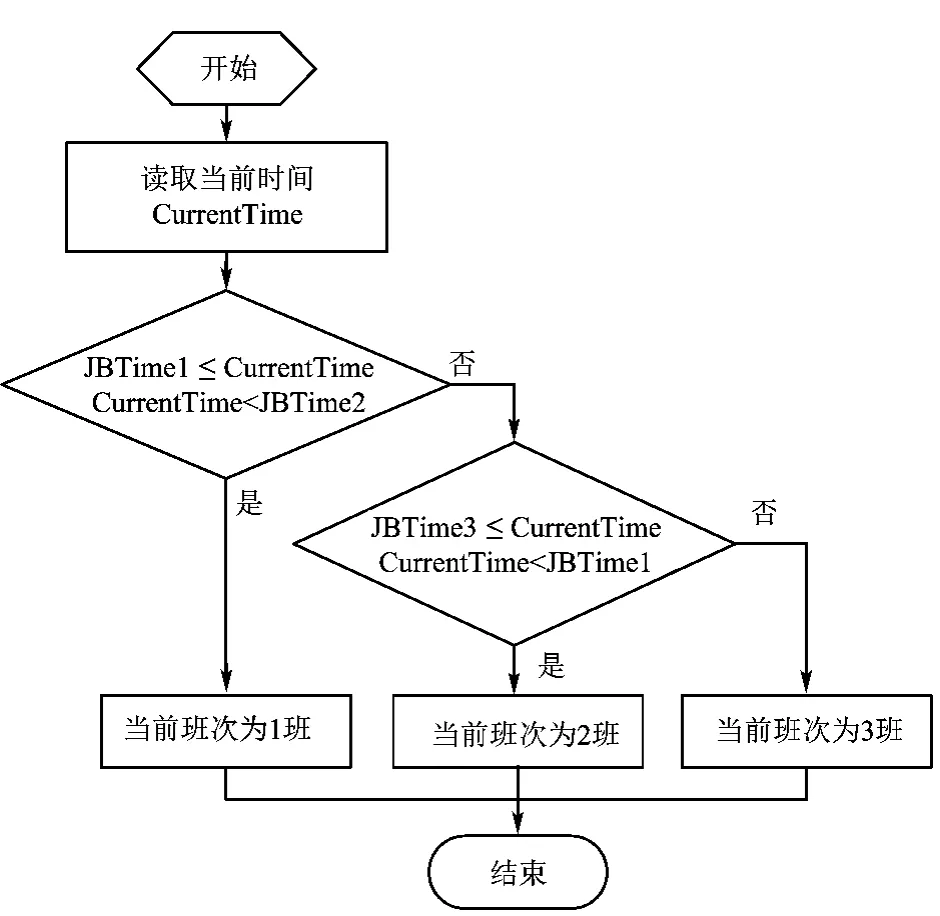
图6 第二种情况班次算法流程图
3)00:00:00≤JBTime2And JBTime2<JBTime3And JBTime3<JBTime1And JBTime1≤23:59:59此情况算法流程图如图7所示。
2.2 班产量统计方法设计
WinCE仪表每分钟发送一次数据,软件用Winsock接收仪表数据,从数据中提取瞬时流量及皮带秤总累计值,保存到数据库的shishi表中,shishi表设计如表1所示。
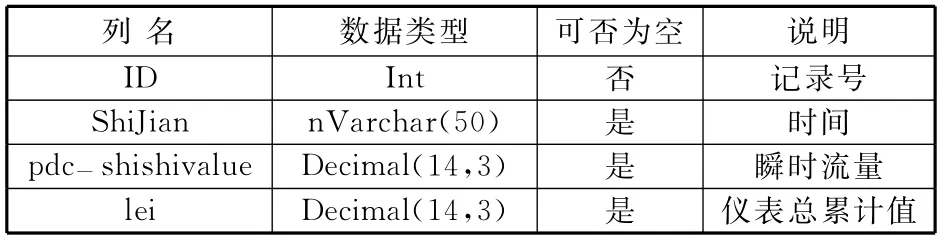
表1 实时数据表
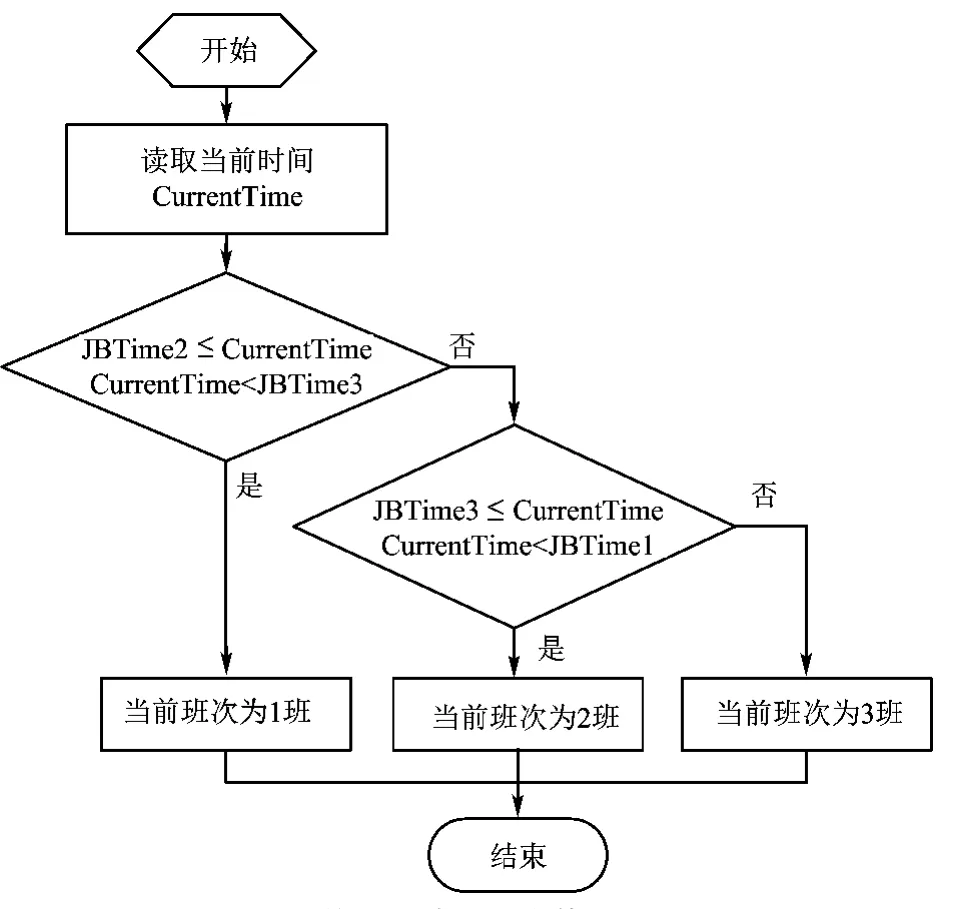
图7 第三种情况班次算法流程图
这样在shishi表中找到当前班之前累计值的最大值作为当前班产量的起始值BanLeiJi-Start,然后找到当前班最新累计值BanLeiJi-End,可得出当前班产量 BanLeiJi=BanLeiJi-End-BanLeiJi-Start。当交班时间到达时保存当前班产量到班产量数据表CL中,CL表中数据是为查询和打印报表服务,其数据是每天一条起始,且每到交班时间更新。班产量数据表设计如表2所示。
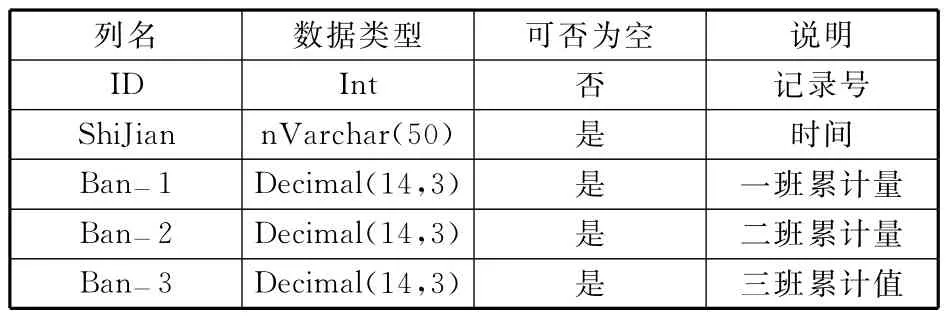
表2 班产量数据表CL
2.3 日月年产量统计方法设计
根据煤矿三班制循环工作机制,本设计只保存班产量,日月年产量查询通过相应的SQL语句利用班产量的相加来实现查询。
软件通过调用SQLServer2005数据库的SQL语句完成日月年产量的查询。并将数据显示到查询界面上。
日产量查询SQL语句,设将要查询的日期为2012-12-12:
SELECT ISNULL(Ban-1,0)+ISNULL(Ban-2,0)+ISNULL(Ban-3,0)FROM CL WHERE ShiJian=’2012-12-12’
月产量查询SQL语句,设将要查询的日期为2012-12:
SELECT SUM(ISNULL(Ban-1,0))+SUM(ISNULL(Ban-2,0))+
SUM(ISNULL(Ban-3,0))FROM CL WHERE ShiJian LIKE
’2012-12%’
年产量查询SQL语句,设将要查询的日期为2012:
SELECT SUM(ISNULL(Ban-1,0))+SUM(ISNULL(Ban-2,0))+
SUM(ISNULL(Ban-3,0))FROM CL WHERE ShiJian LIKE
’2012%’
3 实际应用

图8 整体软件系统界面图
整个软件系统不仅实现了对产量数据、视频、设备状态、超产状态等的检测,而且实现了主备机数据保存的统一和数据上传方式的转变,实现了本地数据和上传数据的统一,进而提高了整个系统的可信性,有效监测了煤矿的生产状况,取得了良好的实际应用效果。图8是监控中心上位机整体软件系统界面图。主要实现了煤矿产量数据、设备状态信息与视频信息的采集、存储。实现了对煤矿产量和视频的全自动检测,为防治煤矿超能力生产工作提供了数据支撑。图9是产量统计查询界面图。其中采用了新的产量统计算法,使得统计查询更加简单有效。按查询条件查询时,日、月和年产量都根据班产量相加得到。

图9 产量查询界面图流程图
4 结束语
本文设计的产量统计算法使得产量的统计和查询更加方便,软件的开发难度降低,煤矿工作人员更容易操作。通过分析实际煤炭产量的统计方法,设计出班产量计算算法及数据库,实现了煤炭产量监控系统对数据的有效监控、查询和历史数据打印。该方法已经成功应用在山西晋城各大煤矿煤炭产量远程监测系统软件,取得了很好的实用效果。
[1] 戴有炜.网络专业指南[M].北京:清华大学出版社,2004.
[2] 郑阿奇.SQL Server实用教程[M].北京:电子工业出版社,2002.
[3] 姚巍.Visual Basic数据库开发及工程实例[M].北京:人民邮电出版社.2004.
[4] 张宏林.Visual Basic开发ERP系统实例导航[M].北京:人民邮电出版社,2005.
[5] 国宏伟,邓君堂,等.高炉专家系统的数据采集及处理[J].冶金自动化,2008,32(3):18-22.
[6] 武梅芳,李丽宏.基于 Winsock的网络通信[J].技术交流,2009,25(1):46-47.
[7] 林陈雷.Visual Basic教育信息化系统开发实例导航[M].北京:清华大学出版社,2000.
[8] 秦戈,刘勇,等.Visual Basic编程之道与技巧指点[M].西安:电子科技大学出版社,2003.
