CVE漏洞分类框架下的SVM学习模型构建*
2013-09-12莫礼平唐赞玉
彭 华,莫礼平,唐赞玉
(吉首大学信息科学与工程学院,湖南吉首 416000)
CVE漏洞分类框架下的SVM学习模型构建*
彭 华,莫礼平,唐赞玉
(吉首大学信息科学与工程学院,湖南吉首 416000)
在CVE漏洞分类框架中,构建了基于支持向量机的学习模型,实现了根据不同的分类特征对CVE进行分类.
支持向量机(SVM);公共漏洞和暴露(CVE);分类特征;分类准确性
CVE漏洞分类框架下的SVM对多种漏洞数据库(如BID,X-Force,Secunia等)中的分类特征进行自动集成,使得该框架能够以分类特征为基础实现CVE漏洞分类,从而成为一个拥有分类和归纳能力的CVE漏洞分类器.关于基于SVM的CVE漏洞分类框架的详细内容见文献[1].笔者分析了该框架下使用SVM为分类特征构造学习模型的方法,设计了数据融合和清理过程,从而消除训练数据的不一致性,使用所建立的学习模型对无标记的CVE漏洞进行分类,最后采用n倍交叉验证方法对学习模型的效果进行了评估.
1 分类特征训练数据的产生
为分类特征产生训练数据的学习模型使用T={¯xi,yi}的形式来表达,其中i=1,...,m.第i个数据点的特征向量和其真标记表示为¯xi∈Rd,yi∈Y={l1,...,lk}.显然,如果手动地对T进行搜集和标记,将会费时费力.因此,该框架通过使用每个CVE条目中的引用池来自动产生训练数据.一方面,CVE中大量的引用为CVE分类器提供了搜集分类信息的丰富资源;另一方面,不同资源中私有的数据格式、冲突的分类模式以及不一致的特征含义使整个信息抽取过程复杂化.考虑到特征数据的引用次数和质量,该框架主要使用漏洞数据库BID,X-Force和Secunia作为来源产生训练数据,见表1.

表1 Secunia漏洞数据库中SA-11066和SA-24893条目

续表
创建Secunia的条目所使用的模板由3个部分组成,即General,Vulnerable和Description.其中,General部分包含了描述性标题及其基本特征,Vulnerable部分说明了有此漏洞的系统或产品,Description部分则是对该漏洞进行的详细说明.与BID比较而言,Secunia漏洞数据库也通过一定的特征对安全漏洞进行分类,如表1中SA-11066和SA-24893条目所示,分别对应着CVE-2004-0445和CVE-2007-2151.Secunia中的Impact部分提供了在Vulnerability Impact特征上的分类信息,而Critical则指明了漏洞的严重性,与Vulnerability Severity特征对应.在该框架下,相同的分类特征可以融合,而不同的分类特征可以互补,共同对漏洞进行统一分类.
来自不同来源的互补的分类特征也许会限制构建训练数据的来源,与分类特征Vulnerability Cause相关的信息只能从BID获得,而分类特征Vulnerability Severity的训练数据只能从Secunia获得.因此,与某些分类特征相关的训练数据数量也许对于建立一个可信赖的学习模型来说是不充足的,究其原因有如下几点:(1)并不是每个CVE条目都有对漏洞数据库BID,X-Force和Secunia的引用;(2)漏洞数据库BID,X-Force和Secunia中的条目也许不能提供指定分类特征上的信息;(3)来自漏洞数据库BID,XForce和Secunia中的数据也许是雷同的、重叠的或冲突的,减少了它们的可用性.
该框架被配置成使用CVE进一步扩大某分类特征的训练数据集,能够匹配问题中分类特征的任一唯一性关键词,与一个分类特征相关的关键词由领域专家使用n-gram产生器(该框架使用自然语言处理工具)进行创建.框架中支持使用正则表达式的模式,关键词匹配过程仅被应用于CVE条目,该CVE条目并不在BID,X-Force或Secunia搜集来的训练数据中,若一个CVE条目匹配任一指定的关键词模式串,该条目被放入训练数据中.
2 数据的合并与清理
X-Force漏洞数据库中XF-16132和XF-33730条目见表2.

表2 X-Force漏洞数据库中XF-16132和XF-33730条目

续表
为获得足够的对应某分类特征的已标记样例,该框架从多个漏洞数据库中取得信息.不幸的是,不同来源的数据可能在分类特征的内涵、外延或粒度上存在不一致,因此要求在构建训练数据时进行数据合并和清理.例如,在为CVE-2004-0445搜集与分类特征Vulnerability Impact的相关信息时,从表1中SA-11066的Impact字段可以获得DoS和system access,然而,在表2中XF-16132的Consequences字段仅能获得DoS.显而易见,在数据合并之前,需要解决不同来源的命名上的不一致.Secunia和X-Force对相同的分类使用不同的名字.例如前者中使用DoS和system access,后者中使用gain access.对于相同的分类特征,一些漏洞数据库将其作为一元分类特征,另外一些将其作为多元分类特征.结果在CVE-2004-0445中描述的安全漏洞,对于Vulnerability Impact特征被X-Force赋予单一的分类DoS,在Secunia中同时被描述为DoS和system access.所以建立分类映射模式来解决不同来源的分类特征维度上的不一致,例如,X-Force和Secunia分别为分类特征Vulnerability Impact定义了10个和11个分类.来自多个来源的分类信息的不兼容也对数据合并提出了更大的挑战.例如分类特征Vulnerability Severity上,在Secunia上有5级度量标准,而在X-Force上只有3级度量标准.另外,CVE-2004-0445安全漏洞被Secunia认为是极端严重的,但在X-Force中被认为只是较严重的.
来自不同来源的漏洞的不同定义和扩展,使得在一个CVE条目中描述的一个安全漏洞被当做不同漏洞数据库中的多个漏洞,导致同一个漏洞数据库中存在与一个CVE条目相关的多个引用.例如,CVE-2004-0452可能由于其一元特征Vulnerability Severity被放入冲突的分类,因为该漏洞同时被Secunia中的SA-12991和SA-18517引用,它们分别具有less critical和highly critical的严重性.显而易见,分类信息的不一致产生有噪声的训练数据,并且影响了所构造学习模型的分类准确性.在训练数据产生期间进行数据合并和清理时,该框架遵守下列原则:(1)对于多元分类特征,若取自多重来源的数据能兼容并且能够建立一个分类映射模式,这些数据可以合并在一起;(2)对于一元分类特征,如果特征的分类能够排序的话,拥有最大值的信息来源将被使用;(3)对于不同来源间以不兼容方式定义的分类特征,CVE分类器更倾向于使用拥有最好粒度的来源或拥有最大标记数量的来源.为搜集某特征对应的训练数据的算法如下所示.
算法1
1:T和Y分别是某分类特征的训练数据集和标记集,L是该特征的二类分类器的集合;
2:for(标记集Y中每个分类c)do
3:初始化正例集Tp和负例集Tn为空集;
4:for(训练数据集T中的每个条目e)do
5:若e有标记c,则将e放入Tp,否则放入Tn;
6:end for
7:基于正例和负例训练集——Tp和Tn,为分类c构建一个SVM二类分类器;
8:将产生的二类分类器放入L;
9:end for
10:if(分类特征是univariate且其维度>2)then
11:将该学习任务作为一个约束优化问题,并建立一个多类模型.
12:返回依赖于分类准确性的该多类模型或二类分类器集合L
13:else
14:返回二类分类器集合L作为学习模型;
15:end if
算法1中描绘的过程用来为一个分类特征产生训练数据.为了一个CVE搜集分类信息,算法1首先标识了其对BID,Secunia和X-Force的引用,然后从每个引用来源处抽取数据并根据上述数据合并和清理的原则检测所取得数据的兼容性.例如,针对分类特征Vulnerability Impact,来自X-Force和Secunia的数据是兼容的,因为这2个来源的分类是可转换的.相反,针对分类特征Vulnerability Severity,X-Force和Secunia的分类模式却是不兼容的,这是因为它们使用不同的度量标准.算法1也试图确定分类特征是单元的还是多元的,由于一个CVE能被赋予多个分类,因此分类特征Vulnerability Impact被标识为多元的.
3 SVM学习模型的构造
当分类特征的维度(标记集Y的大小)等于2时,学习模型就是一个SVM二类分类器.对于|Y|>2的分类特征,学习问题使用多类到二类削减方法被分解成|Y|个二类分类任务.[2]使用一对多的训练方法建立|Y|个二类分类器:通过将训练数据中具有li标记的数据点作为正例,剩余的数据点作为负例,将Y的li标记的学习任务转换为2个分类.如System Access是分类特征Vulnerability Impact中11个分类中的1个.在其训练数据之中,CVE-2004-0445记为正例,而CVE-2007-2151虽然拥有DoS的真标记,仍然被记为负例.当分类特征是一元的情况下,该框架也为其创建1个多类分类器而不是将其削减为2类分类任务[1].为某个指定的分类特征构造学习模型的过程如下所示.
算法2
1:初始化某分类特征的训练数据集T;
2:初始化特征的分类集Y,特征类型type赋为univariate(一元特征)
3:for(CVE字典中的每个条目e)do
4:取得e的引用池,把对BID,Secunia和X-Force的引用放入集合P.
5:初始化e的分类集A
6:for(引用池P中的每一项p)do
7:抽取来自p的特征信息,检查它与A中数据的兼容性,若兼容的话,则加入集合A中.
8:end for
9:for(每一个(关键词,分类)对(k,c))do
10:找到与关键词k匹配的CVE条目,然后把c放入集合A
11:end for
12:把(e,A)对放入训练数据集T中,把分类信息A放入Y,若|A|>1,type赋为multivariate(多元特征)
13:end for
14:输出训练数据集T、标记集Y和特征类型type.
某分类特征的训练数据可能不会覆盖到CVE字典中所有条目,这就使得一些CVE条目无标记.漏洞数量的快速增长要求最新发现的漏洞需要被分类[3].该框架除了使用算法2为所有分类特征建立学习模型外,还使用它们对无标记CVE条目或新发现的漏洞进行分类.标记不可见数据点的过程如下所示.
算法3
1:S是无标记样例的测试集;L和Y分别是学习模型和分类特征的标记集;type是特征类型(univariate或multivariate);
2:for(S的每个样例s)do
3:if(L是一个多类学习模型)then
4:将L的计算结果作为s的标记;
5:else
6:初始化由L赋给s的标记集B;
7:for(学习模型L中每个二类分类器l)do
8:使用l对s进行分类并将输出放入B中;
9:end for
10:if(特征类型是univariate)then
11:找到B的最大值,并将其对应的分类作为s的标记.
12:end if
13:end if
14:end for
对于一个多元分类特征,只要无标记CVE的二类分类器对该CVE输出正值,该无标记CVE就可能被赋予多个分类.而对于一个一元分类特征,算法3仅仅将无标记CVE放入有最高输出的分类中.例如,假定一元分类特征Vulnerability Severity包含5个分类,并且其学习模型由5个二类分类器组成,如果第2个二类分类器输出正值而其余4个分类器输出的是负值,那么CVE-2005-1993将归属第2个分类.
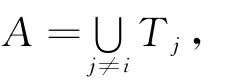
分类准确性定义为分类准确性=正确分类的样例数/验证集的样例数,该框架还使用了Fβ来计算精度P和回归R的加权调合平均值,其公式为Fβ=(1+β2)PR/(β2P+R).一个类的精度P定义为P=正确标记的样例数/归属该分类中的样例总数,回归R的定义为R=正确标记的样例数/实际属于该分类中的样例总数.通过设置β=1,精度P和回归R被认为是同等重要,可以获得F1,且F1=2PR/(P+R).通过学习模型得到的形如分类准确度和精度的度量效果是交叉验证过程的n次迭代获得的度量结果的平均值.经验证,该学习模型具有较好的性能.
4 结语
在CVE漏洞分类框架下设计并构造了基于SVM的学习模型,加强和完善了该框架对CVE漏洞分类的能力.为进一步完善该框架的功能和灵活性,下一步,笔者拟使用带决定性属性和特殊性属性的分类特征集合进行研究,并集成包含隐Markov模型和条件随机场在内的建模方法来提高分类性能.
[1] 彭 华,李宗寿.基于SVM的CVE漏洞分类框架构造[J].吉首大学学报:自然科学版,2013,34(1):66-71.
[2] 刘奇旭,张翀斌,张玉清,等.安全漏洞等级划分关键技术研究[J].通信学报.2012,33(S1):79-87.
[3] 廖晓锋,王永吉,范修斌,等.基于LDA主题模型的安全漏洞分类[J].清华大学学报:自然科学版,2012,52(10):1 351-1 355.
(责任编辑 陈炳权)
Construction of a SVM Learning Model in the Categorization Framework for CVE
PENG Hua,MO Li-ping,TANG Zan-yu
(College of Information Science and Engineering,Jishou University,Jishou,416000,Hunan China)
In the categorization framework for CVE,this paper designs and constructs a learning model based on SVM,so that it can categorize the CVE according to the different taxonomic features.In the process of constructing a learning model based on SVM,first of all,the training data is generated according to the different taxonomic features in the several vulnerability databases,then a data fusion and cleansing process are designed to eliminate the inconsistencies of data,and finally the n-fold cross-validation method is used to evaluate the effect of the model.The learning model has been verified to have better performance of CVE classification.
support vector machine(SVM);common vulnerabilities and exposures(CVE);taxonomic feature,classification accuracy
TP39
A
10.3969/j.issn.1007-2985.2013.03.014
1007-2985(2013)03-0062-05
2013-03-12
湖南省科技厅科技计划资助项目(2011FJ3209);湖南省教育厅一般科学研究资助项目(11C1025)
彭 华(1980-),男,湖南吉首人,吉首大学信息科学与工程学院讲师,硕士,主要从事网络安全、嵌入式系统研究.
