音素关联的多文种语音融合编码方法
2013-07-19孙广武戴永喻世东李璇
孙广武,戴永,喻世东,李璇
湘潭大学智能计算与信息处理教育部重点实验室,湖南湘潭 411105
音素关联的多文种语音融合编码方法
孙广武,戴永,喻世东,李璇
湘潭大学智能计算与信息处理教育部重点实验室,湖南湘潭 411105
1 引言
多文种兼容是多文种信息处理的发展方向[1-6],多文种语音融合编码成为这类系统能否具有实用性的重要研究内容,如文献[3]利用嵌入式技术发明的多文种文字书写教学系统,主要受众是低龄用户,多文种语音表达指导意见是必备功能。迄今的语音编码研究集中在单文种,涉及方法主要有小波变换和矢量量化[7]、SPIHT[8]、多频带编码[9]、ADPCM、MELPC、PSELP等。将单文种语音编码方法直接用于多文种系统,不仅导致语音库容量膨胀,索引逻辑复杂,而且不利于系统性能优化。本文以汉语、英语等文种为例,依据语种内部和语种间基本字词音素数据关联特性,提出多文种语音融合编码方法。音素关联分析过程为:根据异类文种音素数据存在的相同段块结构,按段块模板截取语音样本序列,对序列进行小波变换,提取变换序列的特征,生成共享模板序列集合;基于音素关联分析的语音库构建规则为:任意字音或语句音串均依据共享模板序列集合元素进行编码与解码,相应的语音记录库由(音节、音素)进行二级检索。实验表明,本文方法在单字语音数据压缩比、语音数据存储量、语音还原分段信噪比等方面均明显优于已有方法,语音还原质量达到实用要求。
2 异类文种音素关联分析
图1线框所围为汉字“书”中“u”和英语音标“u:”的发音音谱,“书”和“u:”的语音数据长度分别为8 664字节和8 544字节,在数据开始部分和结尾部分,二者均有一定长度的无声样本点,“书”和“u:”中发音相似的样本点序列(框中所示)长度分别为4 740字节和4 696字节;图2线框中为汉语韵母“a(阿)”与英文音标“ʌ”的音谱,“a”、“ʌ”发音相似的音频段块长度分别为3 976字节与3 465字节。
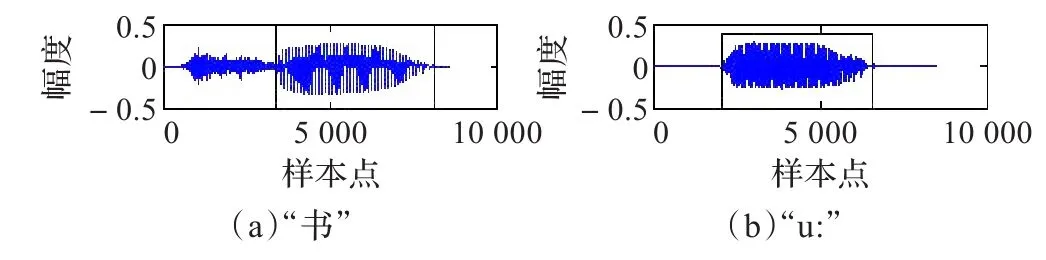
图1 “书”与“u:”的音谱(x轴:0~10 000)

图2 “a”与“ʌ”的音谱(x轴:0~6 000)
字词语音数据结构表明,同语种内不同字音之间、不同语种字词之间,音频段块发音相似现象较为普遍。在语言学中,相同、相似的语音段块往往以一个特定发音基元表征。以声韵母作为汉语语音分析基元,称为汉语音素;以英语音标发音作为英文分析基元,称为英文音素。
用P表示音素,s表示语音样本点,P为相关s的有序集合,即P={s1,s2,…}。
3 融合处理与编码
基于音素数据结构进行多文种语音融合编码,关键在于建立多文种通用的音素数据链接结构模板序列集合,简称为共享模板集,被编码语音是共享模板集中相关元素的数据序列。
3.1 截取语音样本序列

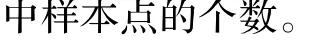
式(1)、(2)分别计算语音帧ν的短时能量E(ν)和短时过零率Z(ν):


f为帧内变量,以maxCorr(ν)表示帧ν自相关函数的峰值。
由语音帧能零比、能零积、自相关函数峰值3个参量组合进行清浊音音素的判别。
依据浊音音素在浊音段的时长比例和浊音段的总帧数计算第d个浊音音素的帧数:
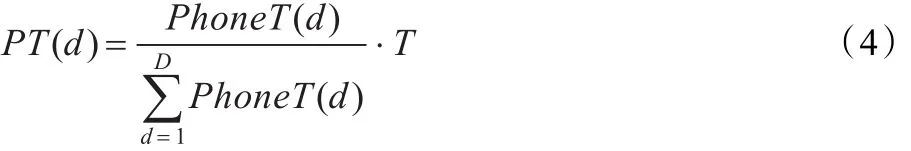
PT(0)=0,T为浊音段帧数,T=νfe-νfs+1,νfs、νfe表示浊音段的起、止帧号,D和d为浊音音素个数与编号,PhoneT(d)为d音素的相对时长。
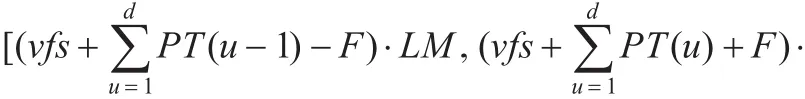
算法1单字音素样本序列截取


任意Pi对于所选mi个训练字,算法1执行mi次,分别获得Pi1,Pi2,…,Pimi。
3.2 序列小波变换与特征矢量提取
基于声音信号的非平稳时变特点,对Pi1,Pi2,…,Pimi分别进行小波变换[10-11],相应变换模型为:

xJ(η)、yJ(η)分别为第J层的尺度系数和细节系数;h、g为低通和高通分解滤波器;H、G为低通和高通重构滤波器。小波变换后生成的系数序列记为由于低频系数对信号还原影响较大且不同尺度间系数具有相关性,分别提取的低频成分和跨频带成分,构成Pi的两类特征矢量集VAi1[p]和VAi2[q],包含矢量个数分别为VNi1、VNi2。
算法2Pi特征矢量提取

3.3 共享模板集生成
从矢量总体中,划分出若干类,每一类生成适当的矢量作为这一类的代表,称之为共享矢量,所有的共享矢量构成共享矢量集。对于Pi,记VBi1为与VAi1对应的p维共享矢量集,VBi1中矢量个数为Ni1,VAi1生成VBi1算法的主要步骤如下所示。

(2)初始化:Yt=Xr(r=t·(Mi1/Ni1)),为初始共享矢量,设置迭代次数最大值Max_Round,初始失真值d′,迭代结束的阈值e。
(3)计算VAi1中矢量与VBi1中所有矢量的失真度,公式为:

3.4 编码与解码
任意字音及语句音串均依据共享模板集T(i)的元素进行编码与解码,字音编码分解为字音中若干音素的编码,语句音串可看做单个字音的拼接。编码语音数据特征集VA中输入矢量X与共享集VB中Yt(t=1,2,…,N)以式(8)比较失真度,输出与X失真度最小的矢量Yf′的编号f′作为X的编码值。
解码是编码的逆过程。首先,读取字音中第一个音素的编码结果,根据T(i)生成该音素的两类矢量;其次,把两类矢量组合成初始小波系数形式;然后,进行与编码过程同级的小波逆变换,截取准确长度的数据序列作为该音素的还原音素,对字音包含的音素都执行上述解码过程,得到全部解码音素;最后,将各音素依次组合,加入格式与长度信息,形成可播放的字音文件。
4 语音重构检索逻辑
4.1 整体结构设计
被练习字的描述字[3]根据教材按(文种号、学期号、课号、课内字号)保存,4个字段组合构成被练习文字的检索码。由(音节、音素)构成的语音记录库索引是描述字的字段之一。
语音体系由音素记录库与(音节、音素)记录库组成,系统通过检索码在(音节、音素)记录库中查询(音节、音素),由(音节、音素)查询音素记录库中相关音素模板串记录进行相应的语音重构。此机理从根本上摆脱文种、文字、语句等差异的影响。
4.2 检索码与音节、音素码的映射关系
检索码与(音节、音素)的映射逻辑关系,有多种方法实现,查表法是基本方法之一。表1是针对人民教育出版社新版小学语文教材部分被练习文字的检索码与(音节、音素)映射结构示例。检索码(L00,1,4,2)中,L00表示大陆汉语文种,其余3项解读为第1学期第4课的第2个字,被练习字为“入”。通过(L00,1,4,2)得到“入”的语音库索引码为(ru4,(31,124,r)(83,332,u)),其中音素用于索引音素库中的音素数据段块进行拼接实现语音重构;音素码的三元结构对应(VA1编码长度,VA2编码长度,音素名)。
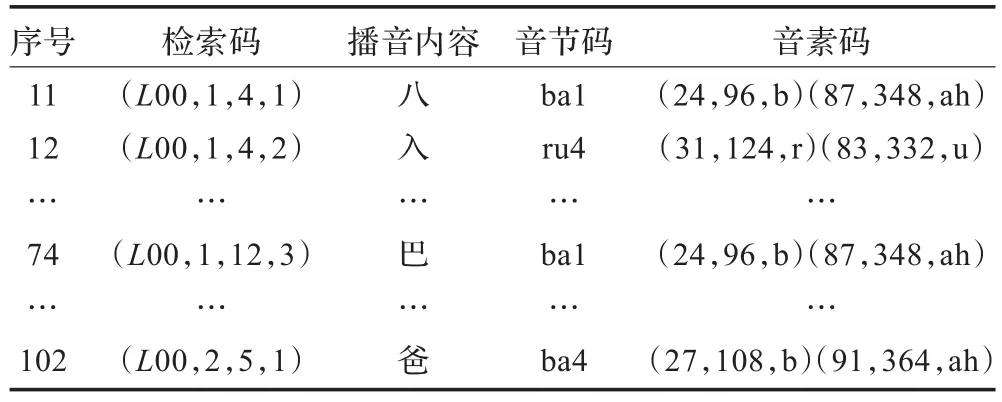
表1 检索码与音节、音素码映射关系
5 实验及效果分析
实验平台为嵌入式开发系统YC2440,设备SDRAM为36.76 MB,NandFlash容量为30.8 MB。
汉语中声韵母音素个数为47个,英语中音标音素个数为48个,综合后音素集合中保留的音素个数为55个,即“b,p,m,f,…,ai,uw,jh,….in,ang”,其中,“uw”音素代表了汉语声母“w”,韵母“u”与英语音标“w”、“v”、“u:”、“u”。以“ai”为例进行模板训练,“ai”在音素序列中排序为25,记为P25;以“zai4.wav(在)”为例进行语音编码,“zai4.wav”的原始语音数据长度为8 358 Byte。
训练过程:挑选含有“ai”发音的字音,共66个,为“埃,挨,……,债,寨,ai,e,æ”(最后3个训练字为英文音标),即m25=66,设置CA[m25],CB[m25]分别保存每个训练字的A值和相应的β值,m25个训练字均执行算法1后,得到样本序列P25,1,P25,2,…,P25,66,以算法2对样本序列提取特征矢量,其中waνname=“bior1.5”,W=4,p=4,q=15,执行后VN25,1=3 022,VN25,2=12 088;共享模板集T(25)= {VB25,1,VB25,2}生成,N25,1=N25,2=256。
编码过程:对于算法1,A=2,β=2,执行后得到音素“z”和“ai”的起止区间分别为[1,2 400],[2 241,8 358];以算法2中方法对“z”进行特征矢量提取,waνname,W,p,q取值与训练过程相同,算法执行后,“z”的VN1=38,VN2=152,其编码后的数据长度为190 Byte,同理,对“ai”进行矢量提取后,其VN1=96,VN2=384,编码后数据长度为480 Byte。在编码文件“zai4.dev”中,先加入音素位置信息(1,2 400,“z”),(2 241,8 358,“ai”),然后依次存储音素编码数据,编码文件总长度为694 Byte,原始数据与编码数据的压缩比例为8 358∶694=12.04∶1。
本文方法与文献[7]和文献[8]方法的编码结果的比较分析,见表2。实验1和2分别为文献[7-8]的运行效果;实验3为本文方法运行效果。表2表明本文方法在数据编码的三项重要指标上均优势明显。

表2 文字语音编码效果分析例表
以“在”字读音为例,图3为其原始与还原音谱,图4为原始与还原频谱;图5是第11条语音串“S11”(“笔画的起始书写方向出错”)的自然与拼接还原音谱。
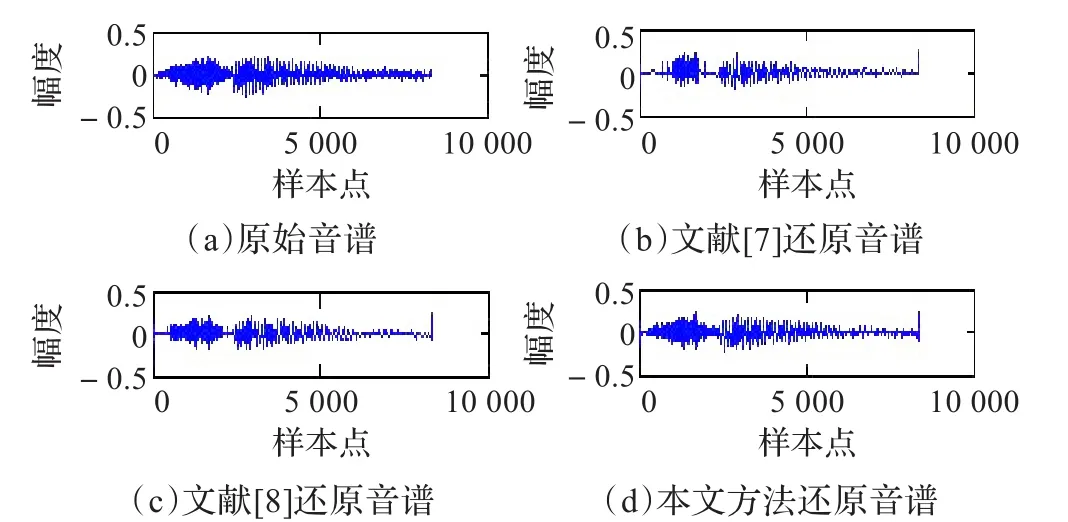
图3 “在”字原始音谱与还原音谱

图5 语音串“S11”的自然音谱与拼接还原音谱
图3、4、5说明本文方法有着高质量的语音还原效果。
本文方法已实用于文献[3]系统,使得35.9 MB的原始语音数据降为3.04 MB。
6 结束语
多文种共处的相关系统越来越多,如何实现异类文种数据的融合,减轻系统容量压力以避免系统性能受影响是必须面对的重要问题。数据段块处理技术是当前研究热点[12],本文对具有代表性的数据段块拼接技术进行研究,具体实现了汉语、英文等文种的语音融合编码、融汇建库,其机理适用于进一步扩展文种,也可借鉴于其他多文种语音的融合;本文方法不仅适用于多文种文字书写教学系统语音数据结构优化,也可推广到多种类图形识别[13-14】、图形绘制等指导系统,或其他含语音库系统的语音库记录及其记录数据结构优化。面向低龄用户的嵌入式多文种文字书写教学系统,在研究语音数据结构优化的同时,MC/OS改进及主成分时间序列等的研究[15-17]需进一步跟进。
[1]Herve B,John D,Mathew M,et al.Current trends in multilingual speech processing[J].Sadhana,2011,36(5):885-915.
[2]王心觉,戴永,张维静,等.面向指导的自由式英文字母书写跟踪[J].湘潭大学自然科学学报,2012,34(2):85-89.
[3]戴永.可联网交互的多功能规定格式习字系统及方法:中国,ZL201010149767.2[P].2010-09-01.
[4]Fung P,Schultz T.Multilingual spoken language processing[J]. IEEE Signal Processing Magazine,2008,25(3):89-97.
[5]Polyákova T,Bonafonte A.Introducing nativization to Spanish TTS systems[J].Speech Communication,2011,53(8):1025-1041.
[6]Bojan I,Zdravko K,Bogomir H,et al.Clustering of triphones using phoneme similarity estimation for the definition of a multilingual set of triphones[J].Speech Communication,2003,39(3/4):353-366.
[7]李淑红,桑恩方.基于小波变换和矢量量化的语音压缩编码方案[J].声学学报,2000,25(1):50-55.
[8]赵丹,马胜前,郑杰.基于SPIHT编码的语音信号压缩算法[J].计算机工程与应用,2011,47(9):142-145.
[9]Kulkarni P N,Pandey P C,Jangamashetti D S.Multi-band frequency compression for improving speech perception by listeners with moderate sensorineural hearing loss[J].Speech Communication,2012,54(3):341-350.
[10]Joseph S M,Anto P B.Speech compression using wavelet transform[C]//Proceedings of the International Conferenceon Recent Trends in Information Technology,2011:754-758.
[11]Hamid R T,Seyyed A S,Hossein B,et al.A new representationforspeechframerecognitionbasedonredundant wavelet filter banks[J].Speech Communication,2012,54(2):256-271.
[12]徐友武,吴云.P_skip模式提前判决的帧间编码算法优化[J].湘潭大学自然科学学报,2011,33(3):119-122.
[13]倪问尹,王建新.多媒体数据内容检测系统关键技术研究[J].湘潭大学自然科学学报,2012,34(2):107-110.
[14]戴永,曾艳艳.基于RBF神经网络的手绘电气草图分类研究[J].湘潭大学自然科学学报,2010,32(4):102-107.
[15]简岩,许道云.实时操作系统μC/OS—II子任务扩展的一种改进方法[J].湘潭大学自然科学学报,2009,31(1):121-124.
[16]彭景斌,姜小奇.一种基于主成分分析的时间序列趋势预测方法[J].湘潭大学自然科学学报,2010,32(2):123-126.
[17]张欣,梁宗保.多分类器融合算法研究与应用[J].湘潭大学自然科学学报,2011,33(2):99-103.
SUN Guangwu,DAI Yong,YU Shidong,LI Xuan
Key Laboratory of Intelligent Computing and Information Processing,Ministry of Education,Xiangtan University,Xiangtan, Hunan 411105,China
Multilingual speech data fusion coding method is proposed according to the phoneme data correlation properties, which exist among heterogeneous languages and different words in the same language.Voice sample sequences of the same phoneme data segment in different languages are intercepted according to the segment templates,wavelet transform is done to those sequences,then feature vectors is extracted to generate shared template sets.Speech data of any word or sentence are coded or decoded according to the template sets.The speech record database made up of template phoneme sets is indexed according to(syllable,phoneme)structure.The single word compression ratio,speech data size,segmental signal-to-noise ratio(SNRS)and score of subjective evaluation(MOS)are significantly better than existing methods,also the voice restoration is of good quality. Key wards:speech;phoneme;correlation;multilingual;fusion coding
依据异类文种之间、同类文种不同语音之间存在音素数据关联的特性,提出多文种语音数据融合编码方法。将不同文种存在的相同音素数据段块按段块模板截取语音样本序列,小波变换,提取特征矢量,生成共享模板集;任意字音或语句音串均按共享模板集提供的元素进行编码与解码;以模板音素串构成的语音记录库按(音节、音素)索引。实验结果表明,单字语音数据压缩比、语音数据存储量、语音还原分段信噪比、主观评价得分等参数均明显优于已有方法,语音还原质量良好。
语音;音素;关联;多文种;融合编码
A
TP391
10.3778/j.issn.1002-8331.1302-0065
SUN Guangwu,DAI Yong,YU Shidong,et al.Phonemes associated multilingual speech fusion coding method.Computer Engineering and Applications,2013,49(19):217-221.
湖南省高校创新平台开放基金(No.09K040);湖南省“十二五”重点学科建设项目。
孙广武(1988—),男,硕士研究生,主要研究方向为模式识别,信号处理;戴永(1956—),男,教授,主要研究方向为人工智能,信号处理;喻世东(1989—),男,硕士研究生,主要研究方向为知识处理与智能系统;李璇(1989—),女,硕士研究生,主要研究方向为信号处理。E-mail:sunguangwu123@163.com
2013-02-09
2013-04-11
1002-8331(2013)19-0217-05
CNKI出版日期:2013-04-26http://www.cnki.net/kcms/detail/11.2127.TP.20130426.1018.002.html
