采用深度图像信息和SLVW的手语识别
2013-07-19杨全彭进业
杨全,彭进业
西北大学信息科学与技术学院,西安 710127
采用深度图像信息和SLVW的手语识别
杨全,彭进业
西北大学信息科学与技术学院,西安 710127
1 引言
聋人使用的手语,是一种进行信息交流、传递思想的自然方法,在聋校教学和聋人交流方面起着非常重要的作用。手语是由手的形状、手腕和手臂的运动,与之对应的人脸表情、嘴唇读音形状,以及其他身体姿态相结合的人体语言。中国手语包括手指语和手势语两类:手指语由30个手指字母构成基本单位,是用手指的变化和动作代表一个汉语拼音字母,并按照汉语拼音规则和顺序依次拼出词语构成的语言;手势语是通过指示性的形象手指姿态模拟事物形状和动作的自然手势。由于汉字本身包含的字词较多,所以使用手势很难全面准确地将其表述完整。而手指语与拼音的拼写方式一致,可以表达很多专业术语以及抽象概念,具有简明易学、手势较少的特点。因此,手语字母的识别是手语识别中非常重要的一部分。根据教育部及中国文字改革委员会等单位公布的现行中国手语实施方案,中国手语中包括30个手语字母:26个单字母(A~Z)和4个双字母(ZH、CH、SH、NG),如图1所示。
手语识别研究包括两类:(1)基于计算机视觉的手语识别[1];(2)基于佩戴式设备的手语识别。由于佩戴式位置跟踪器与数据手套的价格较高,并且穿戴方式复杂,所以很难推广到实际应用中。随着视频采集设备的普及和应用,基于计算机视觉的手语识别以其自然便捷的交互方式受到越来越多的关注,尤其是在硬件成本方面,该方式所需设备成本很低,因此非常适于普及应用,是目前手语识别的研究重点[2-3]。
哈尔滨工业大学的杨筱林、姚鸿勋利用圆形的轴对称和中心对称的几何特点,采用基于多尺度形状描述子的方法对静态中国手指语字母进行识别,识别率为94.6%[4];中国科学院计算技术研究所的张国良等人,采用CHMM对439个孤立手语词的平均识别率为92.5%[5];哈尔滨工业大学的姜峰等人采用合成数据驱动算法对离线中国手语词进行识别,平均识别率为71.6%[6];Deng[7]等人借助颜色手套简化手势分割,运用并行HMM识别192个美国手语词的识别率为93.3%。使用Harr特征并以AdaBoost作为识别分类器,文献[8]进行了24个英文手语的识别研究;Silanon等人提出了根据手势运动分析识别泰文字母的方法[9];Ong等人采用基于Sequential Pattern Trees的多级分类器方法对大词汇量单手语者手势序列和多手语者Kinect数据集进行识别[10]。

图1 手语字母表
本文采用Kinect作为手语视频采集设备,在获取彩色手语视频的同时得到相应的手语深度图像信息,在此基础上对传统的CamShift算法和Ostu算法进行了改进。通过提取手语手势的SLVW特征,构建其词包模型对手语字母进行识别,并通过实验验证了算法的准确性。
2 SLVW特征表示
BoW(Bag of Words)模型是信息检索领域常用的文档表示方法。在信息检索的时候,对于任何一个文档,BoW模型都采取忽略它的单词前后顺序、语法和上下文等要素的方法,只是将其看做词汇的集合,文档中所有单词都被看做是独立而不依赖于其他任何单词的。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语义的影响,是随机的。
以如下两个文档进行说明:

Dictionary一共包含10个不同的单词,给每个单词加索引号,以上两个文档分别用一个10维向量表示(某个单词在文档中出现的次数用整数数字0~n表示)。
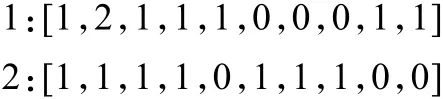
向量中每个元素表示词典中相关元素在文档中出现的次数,且未表达单词在原来句子中出现的次序。由此可知,如果存在一个巨大的文档集合D,其中一共存储M个文档,提取出文档里面的所有单词,然后由这N个单词构成词典。假设用BoW模型描述文档,则每个文档都可以用一个N维向量来表示。
将BoW模型应用于手语识别,为了表征一幅手语图像,可以将该图像看做是一个文档,是若干个手语视觉词汇的集合,且不同视觉词之间不存在次序关系。由于手语图像中的手语视觉词汇不像文本文档那样直接显式存在,所以需要从图像中提取出相互独立的手语视觉词,对手语图像构造视觉词包。该过程主要有4个步骤,如图2所示。

图2 构造词包模型的4个步骤
(1)特征检测:通过手语图像分割的方式获取手语手势的兴趣点;
(2)特征表示:采用图像的局部特征描述子来表示图像内容;
(3)生成视觉单词:把局部特征描述子表示的图像小区域量化生成手语视觉单词(SLVW);
(4)生成BoW:统计一幅手语图像中的视觉单词频率,生成视觉单词频率直方图,用BoW模型来表示手语图像。
生成SLVW词包后,通过使用K-means聚类算法,训练图像集上的所有特征,每一个聚类中心被定义为一个视觉单词,从而生成由N个视觉单词所组成的视觉单词词汇表。计算训练图像中图像块的特征与词汇表中的每个视觉单词所对应的欧式距离,与其中某个视觉单词距离最近的则被记录下来,不断重复以上过程,最终形成一组视觉单词频率统计直方图,生成视觉单词词包,用这组统计直方图代表该幅图像的特征[11-12]。SLVW特征表示方式能够很好地解决图像局部特征点个数不同的问题,具有简单和只需要少量监督的优势。这种图像表示模型将二维的图像信息映射成视觉关键词集合,既保存了图像的局部特征又有效地压缩了图像的描述,使得自然语言处理的各种技术和方法能十分有效地应用于物体识别领域[13]。
本文首先提取手语图像的SIFT特征作为图像中的手语视觉词汇,将所有的视觉词汇集合在一起,则每幅手语图像都由一个128维的特征向量集合描述。然后采用K-means聚类算法构造手语视觉词汇表。SIFT提取的视觉词汇向量之间根据距离的远近,利用K-means算法将词义相近的词汇合并,得到K个聚类中心作为视觉单词,即单词表中的基础词汇,再由视觉单词构成视觉词汇表;进而利用手语单词表中的词汇表示手语图像。利用SIFT算法,可以从每幅图像中提取128个特征点,这些特征点都可以用单词表中的单词近似代替,通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K维数值向量。
参考文档分类的启发,对每幅手语图像中的每个向量计算N个最近邻视觉单词,然后度量第k个SLVW的质量:

其中,Mi表示与视觉单词tk第i接近的特征向量数,s(fj,tk)表示特征向量fj与视觉单词tk之间的相似度,本文采用欧式距离平方进行度量。对每个视觉单词计算其质量,如果满足

则保留,否则舍去。式(2)中,h为视觉单词的质量阈值。手语字母的SIFT特征及SIFT词包特征如图3所示。

图3 手语字母的SIFT与SIFT词包特征
图4为基于SIFT词包的手语字母匹配实验,采用Squared Euclidean Distance进行计算。图4(a)为生成手语字母A的SLVW词包(基于SIFT的手语词包特征,简称为SLVW特征)后,从手语库中随机选取的静态手语字母A的图像与手语视频帧中的字母A手势的匹配成功,识别出了该视频中的手势为手语字母A。图4(b)、(c)、(d)为当视频中出现的手势是字母A时,依次选取静态手语字母B、F、W的SLVW词包与之匹配失败。图4(e)、(f)依次为手语字母B、L的正确匹配与识别。
SLVW与SIFT特征点提取匹配实验比较如图5所示。其中,图5(a)为手语视频中出现字母T时生成其SLVW特征并与手语库中字母T手势的特征匹配,共有20个特征点能够对应。图5(b)为相同帧提取SIFT特征的匹配,仅有11个特征点能够对应。图5(c)为手语字母J的SLVW特征提取匹配,共有17个对应的特征点。图5(d)为相同帧情况下SIFT只有9个对应特征的匹配。

图4 基于SLVW词包的手语匹配

图5 SLVW与SIFT特征点匹配比较
图6为相似手语手势的两种特征匹配识别比较。手语字母M与N的手势非常相似,图6(a)为提取字母M的SLVW特征,可在视频帧与手语库手势匹配时计算得到4个对应的特征点。图6(b)为提取相同视频帧的SIFT特征,仅有1个特征点对应,不能达到匹配识别要求。图6(c)为视频中的手势是M时,计算手语库中字母N的SLVW词包与之匹配失败,字母N手部的特征点部分匹配在打手语者的眼部和颈部。图6(d)为与(c)相同的视频帧,字母M与N的SIFT特征匹配误识别,共有4个特征点匹配且都对应在手部,无法区分其为两个不同的字母手势。图6(e)、(f)分别为字母V的SLVW和SIFT特征提取匹配,相同情况下SLVW比SIFT特征多识别出了5个相匹配的特征点。图6(g)为选取手语库中W手势与V匹配时,W的SLVW特征点对应到了打手语者的脸上,匹配失败。图6(h)是提取SIFT特征计算,W和V仅有1个特征点相对应,无法达到判断其异同的要求。
通过实验结果比对分析,可以发现SLVW词包是一种非常有效的手语特征。

图6 SLVW与SIFT特征匹配识别比较
3 基于SLVW的手语识别
手语识别过程需经过以下5个阶段:手语手势检测、跟踪;手势分割提取;SLVW构建;SVM训练学习;使用SVM识别手语。
3.1 基于DI_CamShift的手势跟踪
帧差法就是背景减图法中的一种,因为其背景模型就是上一帧的图,所以使用帧差法进行运动手势检测不需要建模,速度较快。由于手语视频所处场景光照情况比较稳定,所以本文选用对缓慢变换光照不敏感的帧差法进行手语手势检测可以获得较好的效果,如图7所示。

图7 手势检测
由于传统CamShift算法在彩色空间转换和运动手势跟踪方面存在不足,所以本文使用图像的深度信息改进Cam-Shift算法,即Depth Image CamShift(DI_CamShift)算法。
对于深度图像D(x,y),它的(p+q)阶二维原点矩Mpq的定义为:

其中,D(x,y)为深度图像中(x,y)位置处像素的深度值。
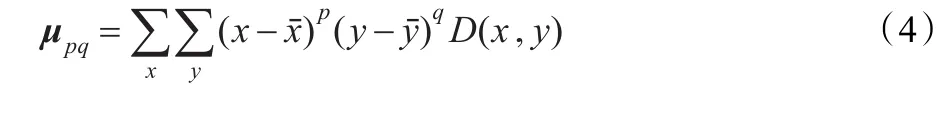
定义D(x,y)的(p+q)阶中心矩μpq为:则其二阶中心矩可以作为手语图像中手势的主轴。最大二阶矩和最小二阶矩的方向可用来确定手语手势的主轴,即长轴和短轴。手势主轴方向角θ可根据矩理论按下述公式求取:


表1 手势主轴与坐标轴的夹角
令手语手势S的主轴方向为θ,则

DI_CamShift算法具体步骤为:
(1)将整个深度图像设为搜索区域。
(2)采用帧差法检测视频中的运动人手区域,对Search Window进行初始化,定位其尺寸和位置。
(3)对Search Window区域内的部分,计算其深度直方图的概率分布。
(4)分别计算深度图像中手势的长轴和短轴的方向θ1、θ2。
(5)使用MeanShift算法计算窗口内深度手势图像的质心位置,根据质心位置和主轴方向θ1、θ2调整Search Window的尺寸。
(6)对于下一帧手语视频图像,用步骤(5)的Search Window的质心和尺寸,跳转至(3)继续运行。
(7)如果检测到多个运动目标,则真实手势为HandGesture= min{M00(Obj1),M00(Obj2),…,M00(Objn)}。因为距离摄像机远的物体具有较大的深度值,而手语识别中认为待识别手语手势是在打手语者身体之前,距离Kinect摄像机最近的目标物体,所以选取具有最小0阶矩值的Search Window,该窗口内的手势像素具有最小的深度信息值的和,可确定为最前景目标手势区域。
如图8(a)所示,视频中出现了一本黄色封面的书,由于黄色较接近手语手势的肤色,所以在人手靠近黄色封皮的书时,CamShift将跟踪窗口转移到了书的区域,将书误判为运动跟踪目标。并且,在人手运动远离书时,跟踪窗口始终停留在原处,未能对运动着的手部区域进行正确跟踪(彩色图像为手语视频中由Kinect彩色摄像头获取的彩色视频帧,下方对应的是Kinect深度摄像头同步拍摄获取的深度视频帧)。图8(b)为相同场景情况下,DI_CamShift对运动手势的正确跟踪。虽然受光线和拍摄角度影响,书皮的颜色在彩色视频帧中有时表现为深黄色,有时表现为浅黄色,但是在人手靠近、远离书的运动过程中,DI_CamShift始终将跟踪窗口定位于运动的人手区域,实现了准确的运动手势跟踪。

图8 类肤色物体干扰信息下DI_CamShift与CamShift手势跟踪比较
在进行手语手势跟踪时,认为手语手势位于人体的最前方,即当视频中出现多个运动着的人手的时候,只有处于人的身体前端且距离摄像机最近的人手为跟踪目标。图9(a)为视频中同时出现两个运动手势时CamShift的跟踪结果,虽然两个手势距离摄像头的前后位置不同,而且后方的人手为干扰因素,只有距离摄像头最近的打手语者的右手为待跟踪目标,但是由于它们都在运动,所以Cam-Shift将两个运动手势同时定位且进行了跟踪。如图9(b),是DI_CamShift在基于手势深度信息基础上正确识别跟踪的目标手势。

图9 视频中出现多个运动手势时两种算法跟踪比较
一旦在深度手势视频中确定了跟踪窗口,就同步地将该窗口绘制到彩色视频中对应的位置处,实现彩色视频中手势的跟踪。相同场景下,DI_CamShift算法具有更好的跟踪效果,不会出现跟踪中丢失手势目标的情况,也去除了距离摄像头较远的具有相同颜色信息的人手区域的误判跟踪。
3.2 手势分割
为了加快手势图像的分割计算速度,可将深度图像的积分图像用于以类间方差作为准则函数的二维Ostu算法[14-15],结合椭圆边界肤色模型,得出一种改进的基于深度积分图像的Ostu算法:
(1)g为椭圆边界手势肤色概率分布深度图,采用3×3的均值滤波算子对g进行滤波,可以得到其邻域平滑图像f;通过遍历g、f,寻找对应的像素并进行统计,其结果生成矩阵d;最后计算P(二维直方图矩阵)和它所对应的变换矩阵Pi、Pj:
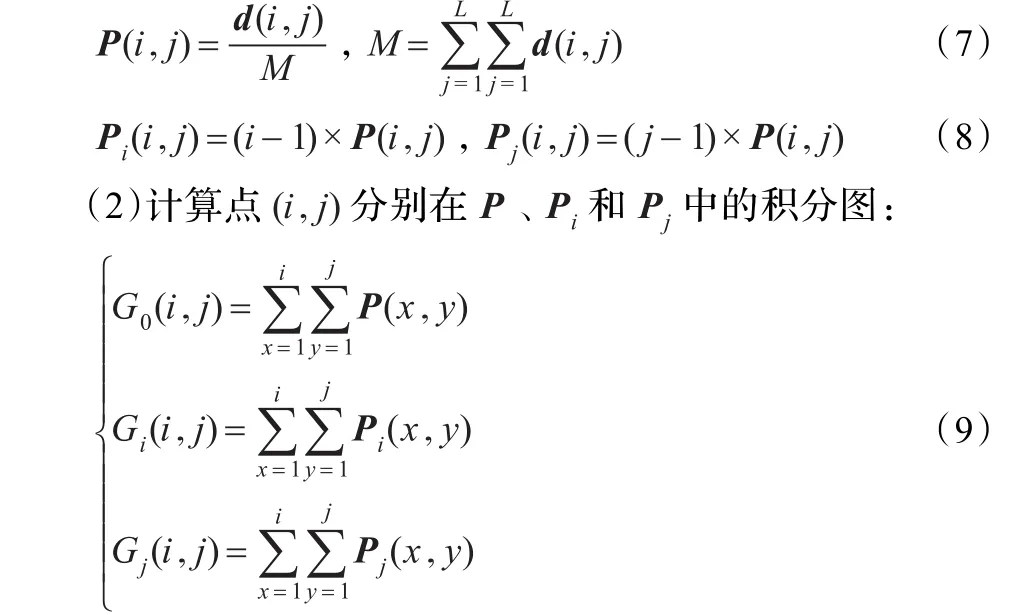
(3)计算SB和ST,它们分别为点(i,j)对应的类间离差矩阵和总离差矩阵:


(4)计算ST-SB,获得类内离差矩阵,计算min{|ST-SB|}((i,j)对应的准则函数值),然后查寻所有数据点,获取最佳分割阈值。图10为改进前后两种分割算法的效果比较。

图10 手势分割方法改进前后的效果比较
图11为在DI_CamShift跟踪窗口内进行的基于改进肤色分割算法的手势提取效果,作为深度距离最小的肤色物体,人手被较好地从背景中提取出来,未受视频中其他肤色物体或类肤色物体的影响。

图11 复杂背景视频中手势的分割
4 手语识别实验
实验运行环境:CPU为Intel Core i5-2300(双核2.8 GHz),内存4 GB;操作系统:Win7 x64,安装NET Framework 4.5,Kinect for Xbox 360 Sensor和Xbox 360 Kinect AC Adapter/ Power Supply;开发环境:vs2010 x64,Kinect SDK v1.7,OpenCV 2.4.4,OpenNI2.2 64 bit。
手语字母视频由Kinect采集,在白天自然光照,复杂背景下录制。由两位打手语者面向Kinect打出30个手语字母,视频包括打手语者的上半身区域和周围复杂环境场景。每个手语字母录制时长为3 min,分别采集彩色视频和深度视频,两类视频的30个分段视频,共计360 min,如图12所示。
本文实验首先使用Kinect采集手语视频图像,然后用帧差法进行手语手势的检测和初步定位,并应用DI_Cam-Shift算法进行手势跟踪。在手势分割提取时,用改进的肤色分割方法提取目标手势,并进行特征提取和SLVW词包构建,最后采用径向基核函数(Radical Basis Function,RBF)SVM分类器进行训练[16]:

图12 手语视频

实验中,从360 min自然光照复杂背景手语视频中间隔采样,针对每位打手语者,每个手语字母手势分别提取50幅彩色图像和50幅深度图像,共计6 000幅手语图像作为训练样本。从手语视频中的非训练样本部分,选取30个手语字母中的各50幅彩色图像和50幅深度图像作为测试对象,基于RBF的SVM分类器识别结果如表2所示,平均识别率为96.21%。
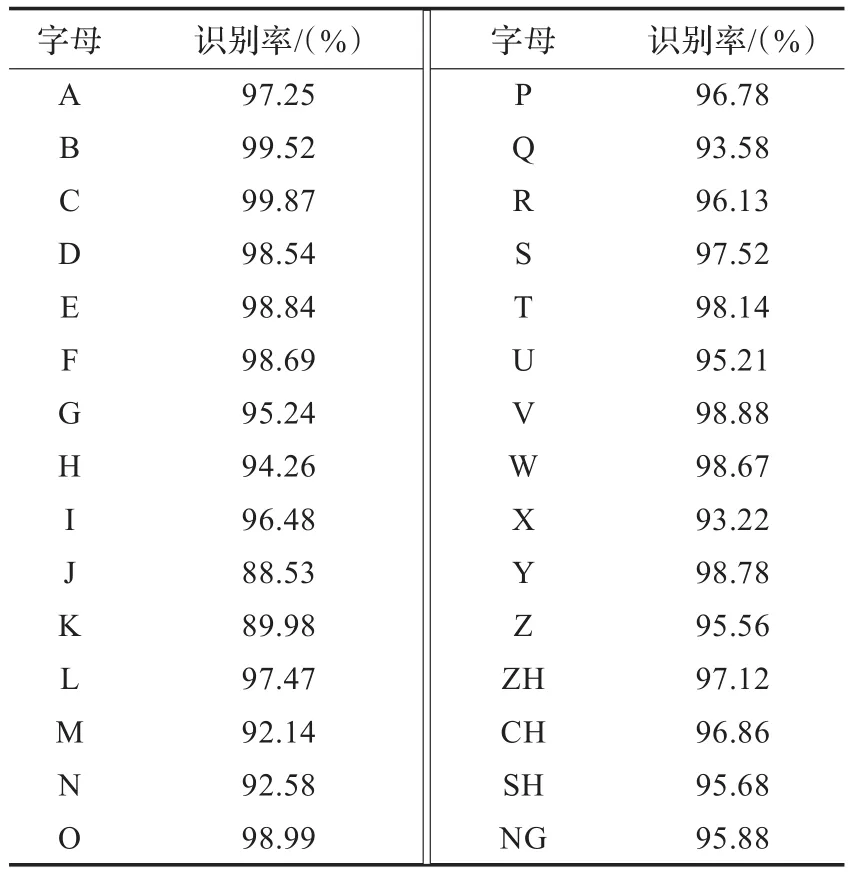
表2 手语字母识别结果
5 结束语
本文提出了一种基于SLVW的手语字母识别方法,使用改进后的DI_CamShift算法,通过计算深度图像中手语手势的主轴方向和质心位置调整Search Window的尺寸,实现了对手语手势的持续稳定跟踪;将深度积分图像应用于Ostu算法对手语手势进行分割提取;通过提取手语SIFT特征,将手语图像小区域量化生成其SLVW特征,然后使用K-means聚类算法得到视觉单词频率统计直方图,最终生成SLVW词包。由于引入了手语的深度图像信息特征,使得识别过程不受颜色、光照和阴影的干扰。实验采用基于RBF的SVM分类器对Kinect采集的中国手语30个字母手势进行识别,获得了较高的识别率。
[1]Wachs J P,Kolsch M,Stern H,et al.Vision-based hand-gesture applications[J].Communications of the ACM,2011,54(2):60-72.
[2]Ren Zhou,Yuan Junsong,Zhang Zhengyou.Robust hand gesture recognition based on finger-earth mover’s distance with a commodity depth camera[C]//Proceedings of the 19th ACM International Conference on Multimedia(MM’11),Scottsdale,Arizona,USA,November 28-December 1,2011:1093-1096.
[3]Doliotis P,Stefan A,McMurrough C,et al.Comparing gesture recognition accuracy using color and depth information[C]// Proceedings of the Conference on Pervasive Technologies Related to Assistive Environments(PETRA),Crete,Greece,May 2011:1-7.
[4]杨筱林,姚鸿勋.基于多尺度形状描述子的手势识别[J].计算机工程与应用,2004,40(32):76-78.
[5]张良国,高文,陈熙霖,等.面向中等词汇量的中国手语视觉识别系统[J].计算机研究与发展,2006,43(3):476-482.
[6]姜峰,高文,姚鸿勋,等.非特定人手语识别问题中的合成数据驱动方法[J].计算机研究与发展,2007,44(5):873-881.
[7]Deng J W,Tsui H T.A two-step approach based on HMM for the recognition of ASL[C]//Proceedings of the 5th Asian Conference on Computer Vision,Melbourne,Australia,Jan 23-25,2002:1-6.
[8]Chen Qing,Georganas N D,Petriu E M.Real-time vision-based handgesturerecognitionusingHaar-likefeatures[C]//ProceedingsofInstrumentationandMeasurementTechnology Conference,1-3 May,2007:1-6.
[9]Silanon K,Suvonvorn N.Hand motion analysis for Thai alphabet recognition using HMM[J].International Journal of Information and Electronics Engineering,2011(1):65-71.
[10]Ong E J,Cooper H,Pugeault N,et al.Sign language recognition using sequential pattern trees[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Providence,Rhode Island,16-21 June,2012:2200-2207.
[11]王宇石,高文.用基于视觉单词上下文的核函数对图像分类[J].中国图象图形学报,2010,15(4):607-616.
[12]刘扬闻,霍宏,方涛.词包模型中视觉单词奇异性分析[J].计算机工程,2011,34(19):204-209.
[13]张秋余,王道东,张墨逸,等.基于特征包支持向量机的手势识别[J].计算机应用,2012,32(12):3392-3396.
[14]朱志亮,刘富国,陶向阳,等.基于积分图和粒子群优化的肤色分割[J/OL].(2013-01)[2013-03].http://www.cnki.net/kcms/ detail/11.2127.TP.20130129.1543.016.html.
[15]郎咸朋,朱枫,都颖明,等.基于积分图像的快速二维Otsu算法[J].仪器仪表学报,2009,30(1):39-43.
[16]Lin C J.LibSVM:a library for Support Vector Machines[EB/OL].(2012)[2013-03].http://www.csie.ntu.edu.tw/~cjlin/libsvm.
YANG Quan,PENG Jinye
School of Information Science and Technology,Northwest University,Xi’an 710127,China
In order to realize the accurate recognition of manual alphabets in the sign language video,this paper presents an improved algorithm based on DI_CamShift(Depth Image CamShift)and SLVW(Sign Language Visual Word).It uses Kinect as the sign language video capture device to obtain both of the color video and depth image information of sign language gestures. The paper calculates spindle direction angle and mass center position of the depth images to adjust the search window and for gesture tracking.An Ostu algorithm based on depth integral image is used to gesture segmentation,and the SIFT features are extracted.It builds the SLVW bag of words as the feature of sign language and uses SVM for recognition.The best recognition rate of single manual alphabet can reach 99.87%,and the average recognition rate is 96.21%.
manual alphabets recognition;Depth Image CamShift(DI_CamShift);Sign Language Visual Word(SLVW);Kinect; depth image
为了实现手语视频中手语字母的准确识别,提出了一种基于DI_CamShift和SLVW的算法。该方法将Kinect作为手语视频采集设备,在获取彩色视频的同时得到其深度信息;计算深度图像中手语手势的主轴方向角和质心位置,通过调整搜索窗口对手势进行准确跟踪;使用基于深度积分图像的Ostu算法分割手势,并提取其SIFT特征;构建了SLVW词包作为手语特征,并用SVM进行识别。通过实验验证该算法,其单个手语字母最好识别率为99.87%,平均识别率96.21%。
手语字母识别;深度图像CamShift;手语视觉单词(SLVW);Kinect;深度图像
A
TP311.52
10.3778/j.issn.1002-8331.1304-0279
YANG Quan,PENG Jinye.Improved sign language recognition research using depth image information and SLVW. Computer Engineering and Applications,2013,49(19):5-10.
国家自然科学基金(No.61075014);高等学校博士学科点专项科研基金资助课题(No.20116102110027)。
杨全(1980—),女,博士研究生,讲师,研究领域为模式识别,数字图像处理;彭进业(1964—),男,博士生导师,教授,研究领域为数字图像处理。E-mail:yangquan1110@yeah.net
2013-04-19
2013-06-14
1002-8331(2013)19-0005-06
CNKI出版日期:2013-06-18http://www.cnki.net/kcms/detail/11.2127.TP.20130618.1559.007.html
