上下文决策树学习算法及其在机械波图像中的应用
2013-07-18李凡长
许 晴, 李凡长
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
上下文决策树学习算法及其在机械波图像中的应用
许 晴, 李凡长
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
机器学习技术在现代各种数据分析中是备受关注的有效方法之一,目前已在众多领域得到广泛应用。文章以目前较为流行的决策树学习为重点,介绍了决策树学习的几个较为成熟的算法,并将相应算法应用到机械波图像分析中,提出了5点、7点与11点上下文决策树学习算法。通过实验验证该处理方法是有效的。
决策树;信息熵;信息增益;机械波图像
决策树学习是机器学习中重要的学习方法之一,也是应用最广的归纳推理算法之一。它是一种逼近离散函数值的方法,分类精度高,操作简单,并且对噪音数据有很好的健壮性,在数据分析中有着广泛的应用[1-2]。本文在学习决策树算法的基础上,引入上下文模型来改进决策树学习算法,从而实现对机械波图像的分析[3]。具体处理方法是首先通过决策树学习算法从一组数据中学习机械波图像的一般规律,从而发现该物理现象的波特征,然后在学习到的图像特征基础上,形成相应的方法,在该方法的基础上,对新的数据进行评估预测[4]。通过实验验证该方法是有效的。
1 决策树学习
1.1 决策树学习简述
决策树学习是以实例为基础的学习算法,是目前较为流行的归纳学习算法之一。决策树学习有多种形式,其中心思想是输入已知数据(即训练集),通过决策树算法对其进行训练,产生一棵决策树,然后对其进行分析,从而得到研究者想要的预测结果[5]。
1.2 决策树学习算法
基本决策树学习算法是一个贪婪算法,采用自顶向下、分而治之的递归方式构造一棵决策树来进行学习。学习构造决策树的一个基本归纳算法[6]如下:
算法:根据给定数据集产生一个决策树。
输入:训练样本,各属性均取离散数值,可供归纳的候选属性集为:attribute-list。
输出:决策树。
处理流程:
(1)创建一个结点N。
(2)若该结点中的所有样本均为同一类别C,则返回N作为叶结点并标志为类别C。
(3)若attribute-list为空,则返回N为叶结点,并标记为该结点所含样本中类别个数最多的类别。
(4)从attribute-list选择一个分类训练样例能力最好的属性test-attribute,并将结点N标记为test-attribute。
(5)对于test-attribute中每个已知取值ai,准备划分结点N所包含的样本集。
(6)根据test-attrtibute=ai条件,从结点N产生相应的一个分支,以表示该预测条件。
(7)设si为test-attrtibute=ai条件所获得的样本集合。
(8)若si为空,则将相应叶结点标记为该结点所含样本中类别个数最多的类别。
(9)否则将相应叶结点标志generate-decision-tree(si,attribute-list-test-attribute)返回值。
1.3 ID3算法
在各种决策树学习算法中,最具有影响的是ID3算法。其核心思想是在决策树各级结点上选择属性时,利用信息熵原理,选用信息增益作为属性的选择标准。其具体方法为:检测所有的属性,选择信息增益最大的属性产生决策树结点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法,建立决策树结点的分支,直到所有子集仅包含同一类别的数据为止;最后得到一棵决策树,它可以用来对新的样本进行分类[7]。
(1)用熵度量样例的均一性。熵是信息论中广泛使用的度量标准,刻画了任意样例集的纯度,具体定义为:给定包含关于某个目标概念的正反样例的样例集S,则S相对布尔型分类的熵为:
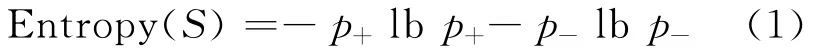
其中,p+为在S中正例的比例;p-为在S中反例的比例。
以上是目标分类为布尔型情况下的熵,更一般的,如果目标属性具有c个不同的值,那么S相对于c个状态的分类的熵定义为:
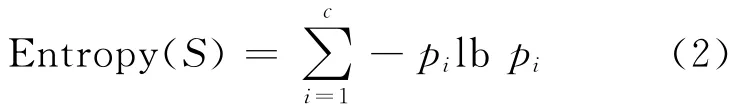
其中,pi为S中属于类别i的比例[8]。
(2)用信息增益度量期望的熵降低。熵是衡量训练样例集合纯度的标准,而信息增益则是属性分类训练数据能力的度量标准。一个属性A相对样例集合S的信息增益Gain(S,A)为:

简单记作:Gain(S,A)≡Entropy(S)-E(A)。
(3)式中,Values(A)为属性A所有可能值的集合;Sv为S中属性A的值为v的子集,即Sv={s∈S|A(s)=v};(3)式中第1项为原集合S的熵,第2项为用A分类S后熵的期望值。
信息增益是ID3算法增长树的每一步中选取最佳属性的度量标准,且应当选取各属性中Gain(A)最大的,因为在Entropy固定的情况下,E(A)值最小,即以A为被选属性所得分类的信息熵最小,此时对向量空间分类的稳定性最好。以A为根结点,对以后的各结点不断调用上述过程,从而构成一棵决策树[9]。ID3算法理论清晰、方法简单、学习能力较强,但只对比较小的数据集有效,对噪声比较敏感,当训练数据集加大时,决策树可能会随之改变[10]。
2 基于上下文模型的决策树
2.1 先验模型
先验模型中的每个对象类别都关联着一个二进制变量,表示是否在图像中出现,以及一个高斯变量,表示它的位置[11]。
2.1.1 共现先验
对象对的共现是一个简单但有效的背景信息,本文使用二叉树模型编码共现统计数[12]。树中的每个结点bi表示相应的对象i是否在图像中出现。当pa(i)为结点i的父,所有二进制变量联合概率根据树结构可分解[13]为:
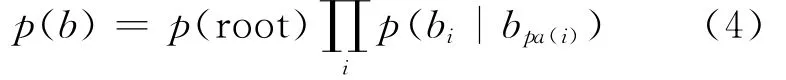
其中,下标i表示与对象i对应的变量,用一个没有下标的符号表示所有对应变量的集合,b≡{bi}。一个父-子对可能有正相关关系(地板和墙常常共现),也可能有负相关关系(地板很少和天空同时出现)[14]。
2.1.2 空间先验
(1)空间位置表示。对象出现在另一个对象特定的相对位置上。例如,电脑屏幕通常出现在键盘和鼠标之上。通过添加位置变量到树模型来捕捉这些空间关系,用包围框取代对象分割,它是所有分割点的最小封闭框,表示对象实例的位置。设lx、ly分别为包围框中心的水平和垂直坐标,lw、lh分别为框的宽和高。假设图像高度为1,且lx=0,ly=0是图像的中心。对象中心间的预期距离取决于对象的大小。运用以下坐标变换来表示在三维世界坐标中的对象位置,即
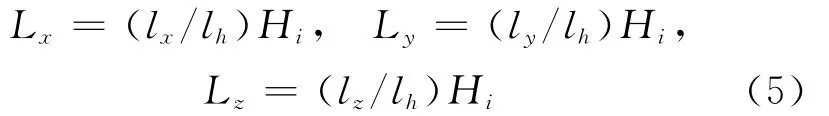
其中,Lz为观察者与对象之间的距离;Hi为对象i的物理高度。每个对象类的高度可以从算法获得的注解数据推断,但真实对象的大小采用手动编码获取(人的高度为1.7m,车的高度为1.5m)。
(2)空间位置先验。从不同的角度来看,对象的水平相对位置会有很大的不同,并且已经显示水平位置一般有微弱的背景信息。因此忽略lx,只考虑ly、lz来捕捉竖直信息和规模关系。假设Lys、Lzs是独立的,即对象的竖直位置与到图像平面的距离是独立的。本文建模Lys为联合高斯,使用对数正态分布建模Lzs,因为它们始终是正的,并更多地围绕小值分布。本文为对象类i定义一个位置变量Li=(Ly,lgLz),并且假设Lis为联合高斯。为了简单起见,对对象类的空间关系进行建模,如果在一张图像上有多个对象类实例i,Li代表所有实例中的中心位置。
假设以存在变量b为条件时,Lis的依赖结构与二叉树具有相同的树结构,即
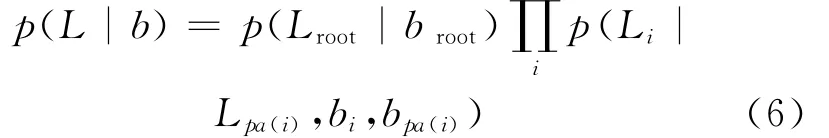
其中,以父位置和父与子都出现与否为条件,每边势p(Li|Lpa(i),bi,bpa(i))编码一个子位置的分布。
结合(4)式和(6)式,所有二进制和高斯变量的联合分布可以表示为:
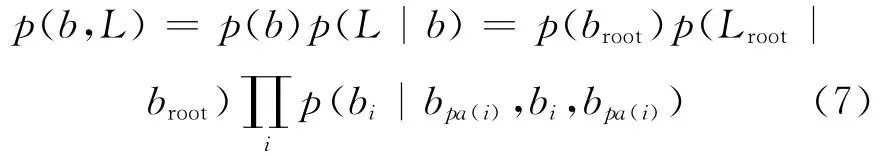
2.2 测量模型
2.2.1 混合全局图像特征
要旨描述符是图像的低维表示,用来捕捉场景的粗结构和空间布局。引入要旨作为每个存在变量bi的测量,将全局图像特征并入本文测量的模型,使上下文模型能够完全地推断出场景类别,尤其有助于推测室内对象还是室外对象应该出现在图像上。
2.2.2 集成定位检测器的输出
为了检测并定位图像中的对象实例,首先运用现有的单目标检测器,为每个对象类获得1组候选窗口。用i表示对象类,k索引由基线检测器产生的候选窗口。每个检测器输出提供了1个评分sik和1个包围框,对(5)式进行坐标变换以获得位置变量Wik=(Ly,lgLz),分配一个二进制变量cik给每个窗口,代表它是正确的检测(cik=1)或假阳性(cik=0)。如果一个候选窗口是对象i的正确检测(cik=1),则Wik为一个高斯向量,均值为Li,位置为对象i的位置,如果窗口为假阳性(cik=0),Wik与Li独立,且均匀分布。
2.3 学习
2.3.1 学习对象依赖结构
本文从一组完全标记的图像中学习对象间的依赖结构。周刘算法是学习树模型的一个简单而有效的方法[15],能最大限度地提高数据的似然性,该算法使用示例值计算所有变量共同信息,再发现最大权重生成树,它的边权重为由边连接的变量间的共同信息。本文用一组标记的图片的bis示例学习树结构,即使有100个对象,成千上万的训练图片,Matlab可在几秒钟内学习到树模型。
尽管周刘算法的输出是一个无向树,本文可以选取某个对象作为树的根,以获得有向树结构。在学习过程中,本文并没有使用任何有关对象类之间固有层次结构的信息,周刘算法只选择强依赖性的对象类。然而,学习到的树结构用一种自然的层次组织对象,例如,以建筑为根的子树,会有许多出现在街道场景的对象,而以水槽为根的子树则包含常常出现在厨房的对象。因此,许多非叶结点用来表示粗规模的元对象或者场景类,即学习到的树结构捕捉对象和场景间的固有层次结构能促使更好地进行对象识别及场景理解表现[16]。
2.3.2 学习模型参数
用训练图片的地面实况标签学习先验模型的参数,p(bi|bpa(i))可以简单地通过数父 -子对象共现的对数获得。对于每个父-子对象对,本文为p(bi|bpa(i),bi,bpa(i))使用3个不同的高斯分布:当2个对象均出现,即bi=1,bpa(i)=1,子对象的位置Li取决于其父位置Lpa(i)。当对象出现而它的父对象没有出现,即bi=1,bpa(i)=0,则Li独立于Lpa(i)。当一个对象本身没有出现,假设Li与其他所有对象位置均独立,并且它的均值与所有图片的平均位置对象i相等。
在测量模型的训练中,p(g|bi)可以使用从每张训练图片中计算得到的要旨描述符,因为该要旨是向量,为了避免过度适合,使用逻辑衰退为每个对象类匹配p(bi|g),由此可用p(g|bi)=p(bi|g)p(g)/p(bi)来间接地估计p(g|bi)[17]。
为了学习剩余参数,本文为训练图片的每个对象类运行局部检测器。将局部检测器的评分排序,则sik为第k高的评分的类,p(cik|sik)被训练使用逻辑衰退,从中可以计算似然性p(sik|cik)=p(cik|sik)p(sik)/p(cik)。 正 确 检 测 的 可 能 性p(cik|bi)使用训练集中的地面实况标签和正确检测来进行训练。
3 实验分析
本文主要探索决策树学习算法在机械波图像分析中的应用,以决策树学习算法为基础,结合上下文模型加以改进,在weka中加以实现,然后通过学习大量的实验数据,找出机械波图像的一般规律并加以分析[18]。
3.1 实验准备
3.1.1 数据准备
机器学习的3个主要特征为:任务的种类、衡量任务提高的标准及经验的来源。其中,经验来源为实验数据,由此可见,数据采集是机器学习中必不可少的组成部分。本实验由于客观条件的限制,无法搜集现成的数据,本文自行设计实验数据,并根据物理学知识,了解到机械波图像基本符合正余弦特征分布,因此设计实验数据以正余弦公式为基础。以5点上下文模型决策树学习为例,其具体构造过程如下:
(1)选定一个最简单的机械波图像,其满足y=sinx。
(2)关注该机械波图像上的5个位置的点,分别为0、π/2、π、3π/2、2π,其对应的y值分别为0、1、0、-1、0。
(3)设定误差为±0.1。
(4)设定一个类别属性,当5点的值均在误差内,则认为正确,记为1;否则,如果有1个或多个点的值溢出误差,则认为错误,记为0。
(5)设计数据若干组,其中包含所需的训练集以及测试集,且包含故意错误数据若干。
按照上述步骤,实验数据即可构造完毕,其基本情况见文献 [19]。
3.1.2 实验算法
本文通过对决策树算法的学习,结合上下文模型构造决策树实现了分类预测。以5点上下文模型决策树学习为例,在机械波图像中,根据y=sinx取5个点,分别为0、π/2、π、3π/2、2π,由经验可知,该图像中,如果已知了0点,可根据0点决定π/2的位置,从而确定π的位置,依此类推,5点的位置均可以确定,该过程用到了上下文信息,根据一阶 Markov随机场论(Markov random field,简称MRF),在树结构中,结点的父亲可建模为其上下文,上下文信息有助于分类过程达到更高的分类精度[20]。具体实现算法为:
(1)确定0、π/2、π、3π/2、2π5个点,其中“0”点定为根结点。
(2)根据“0”点的不同属性值计算信息熵及信息增益,从而确定正确的一类。
(3)不考虑“0”点错误分支,在其正确分支下按照同样方法确定π/2点的正确分支。
(4)按照以上方法,依次确定π、3π/2、2π点,构造一棵基于上下文模型的决策树。
(5)按照该决策树对新的数据集进行分类。
以上实现了5点上下文模型决策树学习算法,同样的方法还可以实现7点以及11点上下文模型决策树学习算法等。
3.2 实验结果
3.2.1 基于上下文模型的决策树算法的结果
5点、7点与11点上下文模型决策树算法实验结果如图1所示,由图1可以看出,基于上下文模 型 的 决 策 树 算 法 (Context-Based Decision Tree,简称CBDT)的测试分类精度较高,且随着数据集逐渐变大,其精确度也不断增大,最终趋于稳定,且当点数逐渐增多,即上下文信息更加明显时,精确度也有所上升。
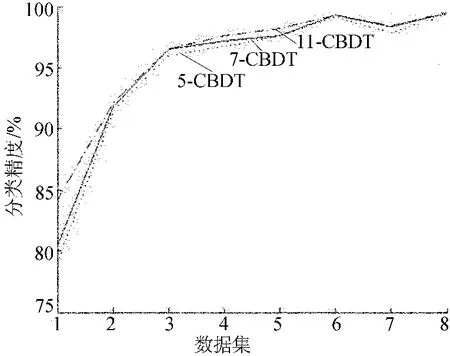
图1 上下文模型决策树算法结果比较
3.2.2 几种算法结果的比较
为了说明基于上下文模型的决策树可以很好地学习并进行分类预测,本文将其与SimpleCart算法以及KNN算法的测试分类精度加以比较。
本文设计了8个数据集,从dataset 1的100组数据到dataset 8的800个数据,以100的增长量递增,分别用这3个算法对8个数据集进行学习,测试其分类精度,结果如图2所示。
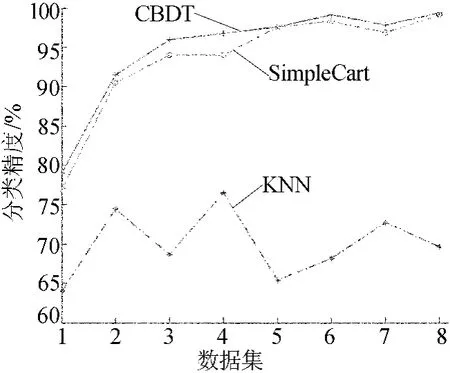
图2 不同算法分类精度的比较
由图2可以看出,KNN的精度最低,Simple-Cart的精度较高,CBDT的精度最高。
4 结束语
本文主要介绍了决策树学习的基本知识与概念和几种较为成熟的算法,并提出了一种基于上下文模型的决策树,这种决策树学习结合了上下文信息来构造决策树,从而消除了构造过程中一些明显的错误组合,提高了分类精度。本文利用基于上下文模型的决策树分析物理学中的机械波图像,用决策树算法从设计的实验数据中学习图像的一般规律,并用于分类预测。实验证明,基于上下文模型的决策树的精度相对较好,且随着数据量的增大,趋向于稳定。
本文在以下方面可进一步改进:
(1)本文只运用基于上下文模型的决策树在简单的机械波图像上进行研究,可增加实验图像的复杂性及实验数据的大量性,以进一步验证基于上下文模型的决策树的分类预测精度。
(2)基于上下文模型的决策树不仅可以进行分类预测,还可以检测脱离上下文的对象等。本文运用了该决策树的一部分知识,可以考虑继续对基于上下文模型的决策树的深入研究。
(3)当研究的对象更加复杂时,可采用隐Markov树模型(HMT)[20],不仅能以结点的双亲为其上下文,结点间为因果关系,还可以使建模双亲结点和孩子结点同时作为结点的上下文,结点间为非因果关系,这样可以使算法分类精度更高。
[1]王 源,王甜甜.改进决策树算法的应用研究[J].电子科技,2010,23(9):89-91.
[2]胡学钢,方玉成,张玉红.基于Logistic回归分析的直推式迁移学习[J].合肥工业大学学报:自然科学版,2010,33(12):1797-1801,1810.
[3]倪海鸥.决策树算法研究综述[J].宁波广播电视大学学报,2008,6(3):113-115.
[4]郭亚宁,冯莎莎.基于决策树方法的数据挖掘分析[J].软件导刊,2010,9(9):103-104.
[5]Mitchell T M.Machine Learning[M].曾华军,张银奎,译.北京:机械工业出版社,2011:38-44.
[6]邢晓宇,余建坤,陈 磊.决策树算法在学生考试成绩中的应用[J].云南民族大学学报:自然科学版,2009,18(1):77-80.
[7]胡兰兰.决策树算法在淘宝店铺中的应用研究 [J].贵州师范学院学报,2010,26(6):40-43.
[8]牛晓博,赵 虎,张玉册.基于决策树的海战场舰艇意图识别[J].兵工自动化,2010,29(6):44-45.
[9]林忠会.基于归纳学习的数据挖掘技术在高校教学研究中的应用[D].哈尔滨:哈尔滨工程大学,2008.
[10]余 艺.基于遗传算法的分类器的研究及其应用[D].武汉:武汉工程大学,2008.
[11]李秋颖.决策树优化与关联规则挖掘算法研究[D].辽宁大连:大连海事大学,2010.
[12]牛文颖.改进的ID3决策树分类算法在成绩分析中的应用研究[D].辽宁大连:大连交通大学,2008.
[13]谭俊璐.基于决策树规则分类算法的研究与应用[D].昆明:云南大学,2010.
[14]Choi M J,Torralba A,Willsky A S.A tree-based context model for object recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34:240-252.
[15]Chow C K,Liu C N.Approximating discrete probability distributions with dependence trees[J].IEEE Trans Inform Theory,1968,14(3):462-467.
[16]田永洪,黄铁军,高 文.基于多粒度树模型的 Web站点描述及挖掘算法[J].软件学报,2004,15(9):1393-1403.
[17]王 一,杨俊安,刘 辉.一种基于遗传算法的SVM决策树多分类方法[J].信号处理,2010,26(10):1495-1499.
[18]张先武,郭 雷.一种新的支持向量机决策树设计算法[J].火力与指挥控制,2010,35(10):31-35.
[19]陈 伟.改进的ID3算法构造决策树[J].淮南师范学院学报,2010,12(3):33-35.
[20]朱颢东.ID3算法的改进和简化[J].上海交通大学学报,2010,44(7):883-886.
Context-based decision tree learning algorithm and its application in images of mechanical wave
XU Qing, LI Fan-zhang
(School of Computer Science and Technology,Soochow University,Suzhou 215006,China)
Machine learning technique is an effective way of modern data analysis.It has been widely used in many fields and got a lot of attention.Focusing on the most popular decision tree learning,a few of the most sophisticated algorithms are introduced.Then the corresponding algorithm is applied to the image analysis of the mechanical wave,and the five-point,seven-point and eleven-point contextbased decision tree learning algorithms are proposed.The approach is proved to be meaningful by experimental validation.
decision tree;information entropy;information gain;mechanical wave image
TP181
A
1003-5060(2013)02-0160-05
10.3969/j.issn.1003-5060.2013.02.008
2012-07-11;
2012-09-28
国家自然科学基金资助项目(61033013;60775045)
许 晴(1990-),女,江苏东台人,苏州大学硕士生;
李凡长(1964-),男,云南宣威人,苏州大学教授,博士生导师.
(责任编辑 闫杏丽)
