融合深度信息的视觉注意模型研究
2013-07-18高秀丽陈华华
高秀丽,陈华华
(杭州电子科技大学通信工程学院,浙江杭州310018)
0 引言
随着信息技术的发展,图像数据的规模变得越来越大。面对如此庞大的图像数据,如何能够快速而准确地完成各种图像分析任务己经成为人们研究的热点。视觉注意模型可以模拟人的注意机制,在图像和视频处理领域可以有选择的获取人们所关注的目标显著信息,在一定程度上降低了信息处理量。通过视觉注意模型计算得到的显著图在计算机视觉领域有着广泛的应用,包括图像中显著对象的分割[1],目标对象识别[2],图像压缩[3]等。近年来,对于视觉注意的研究一直是计算机视觉和多媒体方向研究的热点之一。一种基于全局对比度的显著性区域检测方法,得到了较为理想的显著图[4]。然而,方法并没有考虑深度信息对人类视觉注意机制的影响,在特征选择上与人类视觉注意机制存在较大的差异。为了得到更接近于人类视觉感知的视觉注意计算方法,根据特征整合理论[5],本文在基于全局对比度模型的基础上提出了一种融合深度信息的视觉注意模型。该模型首先通过全局优化的图切割方法提取深度信息得到深度信息图,然后与原图像分别进行基于全局对比度的视觉注意计算得到各自的显著图,最后对两者进行融合得到最终的视觉注意显著图。实验结果表明该模型能够得到相对完整的显著性目标,反映了深度信息对人类视觉注意的影响。
1 深度信息提取
立体匹配方法可大致分为两种:一种是只对象素周围小区域进行约束的局部匹配方法;另一种是对扫描线甚至整幅图进行约束的全局匹配方法。全局匹配方法将计算集中在视差计算阶段,目的是找出一个视差函数,使全局能量达到最小。全局能量函数如:

式中,映射函数f:P→L,P为各个摄像机拍摄成像的象素集,L是对应不同深度值的离散集合,Edata(f)是数据项,Esmooth(f)是平滑项,Evisibility(f)是可视性约束项。
本文采用图切割算法来求解使全局匹配能量最小的最小割曲面[6],并根据最小割曲面为图像中的象素分配视差值,最后通过计算最小代价视差得到最优的视差图,即深度信息图。与误配率较高的局部匹配方法相比,图切割算法有较高的匹配准确率。
2 基于全局对比度的视觉注意计算方法
基于全局对比度的显著性计算方法是用一个区域和整幅图像的对比度来计算显著值[4]。首先用基于图的分割方法将图像分成若干区域[7],然后对于图像中的每个区域rk,计算它与图像中其他区域的颜色对比度,并引进空间信息来增加区域的空间影响,最后计算每个区域rk和其他区域对比度加权和来得到区域rk的显著值。区域rk的显著值计算公式如:

式中,Ds(rk,ri)为区域rk和ri的空间距离,δs控制空间权值强度。两个区域的空间距离定义为两个区域重心的欧氏距离。w(ri)为区域ri的权值,表示区域ri里的象素数,Dr(·,·)表示任意两个区域的颜色距离度量。
3 融合深度信息的模型
在基于全局对比度模型的基础上,本文提出一种融合深度信息的视觉注意模型,如图1所示。在这个模型中,左图像和右图像首先通过全局优化的立体匹配方法计算深度信息,得到深度信息图。然后,利用基于全局对比度的方法,对左图像和深度信息图分别进行计算得到各自的显著图。最后将左图像显著图和深度信息显著图进行融合得到最终的视觉注意显著图。
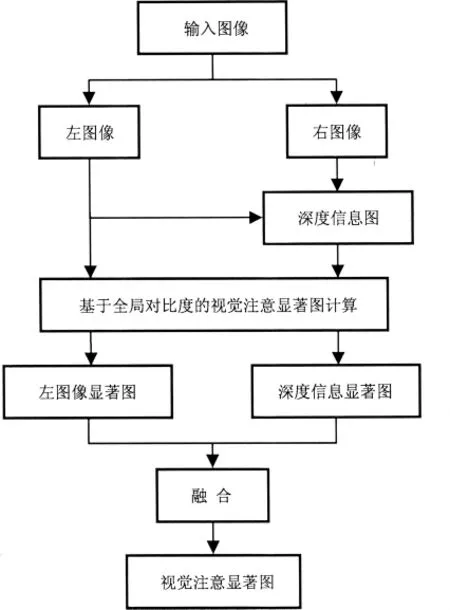
图1 视觉注意模型系统框图
深度信息融合的具体过程如下所述。左图像显著图和深度信息显著图中的象素值均被归一化到0-255之间,显著性高的区域对应的显著值比较大,在显著图中会显示的比较亮;相反,显著性低的区域对应的显著值比较小,在显著图中会显示的比较暗。对图像计算显著图的目的是找到图像中更容易引起观察者感兴趣的区域,是显著值比较大的区域。因此,可以适当的忽略显著值比较小的区域,更多的考虑显著值比较大的区域。基于上面的考虑,对左图像显著图和深度信息显著图进行阈值处理,选取0-255之间某一阈值T,分别将两幅显著图中低于该阈值的象素值赋为0,其他象素的显著值保持不变,这样就得到经过阈值处理的两幅显著图。对于处理后的两幅显著图,分别计算所有非0象素显著值的均值,假设M1、M2分别表示经过处理的左图像显著图和深度显著图中非0象素显著值的均值。对于两幅显著图中的显著区域,首先考虑第一显著区域,即最容易引起观察者兴趣的注意焦点。为了判断哪幅显著图中的显著区域更占优势,对M1和M2进行比较,采用胜者为王(即WTA)机制,如果M1大于M2,则M1对应的阈值处理后的显著图作为最终的视觉注意显著图,相反,则M2对应的阈值处理后的显著图作为最终的视觉注意显著图。
4 实验及结果分析
为验证本文提出的方法的可行性,对该方法进行了实验验证。本文实验用到的数据来自于美国Middlebury大学计算机视觉研究中心提供的立体图像数据库。本文用立体数据库中的Tsukuba和Aloe图像做实验。实验结果如图2、3所示。
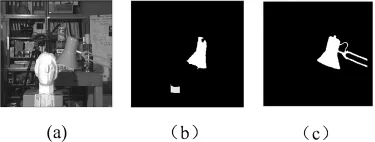
图2 Tsukuba实验结果
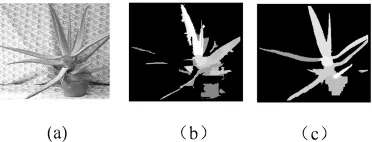
图3 Aloe实验结果
图2、3(a)是 Tsukuba和 Aloe原图,图2、3(b)是由程明明模型得到的显著图[4],图 2、3(c)是由本文提出的融合深度信息的视觉注意模型计算得到的显著图。在Tsukuba实验结果中,图2(b)较好的表示了容易引起观察者注意的台灯区域。与图2(b)相比较,图2(c)更完整的检测到了引起观察者注意的台灯区域。对于Aloe实验结果,图3(b)显示的显著区域中的一些枝叶是不连续的。与图3(b)相比较,图3(c)得到了相对完整的显著性目标。图2、3(b)是基于二维信息模型得到的,由于没有考虑深度信息对人类视觉注意的影响,因此在特征选择上存在一定的不足。图2、3(c)的效果比较理想,显著值高的区域比较集中,显著度区分明显。
为了更形像的描述本文模型得到的显著图,将得到的显著图中的显著区域信息还原到原始图像中,同时将基于二维信息模型得到的显著图信息也还原到原始图像中。得到的实验效果图如图4所示。

图4 Tsukuba和Aloe实验效果图
图4(a)是Tsukuba和Aloe原图,图4(b)是由程明明模型得到的显著图[4],图4(c)是基于图4(b)得到的效果图,图4(d)是本文模型得到的显著图,图4(e)是基于图4(d)得到的效果图。以Tsukuba图为例,由图可知,图4(c)除了检测到台灯,还有雕像脖子处的一小块残余区域,而且台灯区域有缺口。相比较而言,图4(e)检测到的台灯区域比较完整,而且没有周围残余区域的影响,检测效果比较好。Tsukuba图像中台灯位置距离观察者比较近,通过比较效果图(e)和(c),可以看出本文模型得到的效果图(e)更好的反映了空间深度信息对视觉注意的影响。因此,深度信息的引入符合人类视觉感知的要求,体现了深度信息对人类视觉注意的影响,更符合人类生理学机制对目标注意对像的判断。
5 结束语
本文根据人类视觉机制及图像的特点,综合考虑影响人类视觉注意的因素。在基于全局对比度的视觉注意模型的基础上,将深度信息对视觉注意的影响融合进去,建立了融合深度信息的视觉注意计算模型。模型更全面的考虑了图像中所含的二维信息和立体信息对人类视觉注意的影响,对于图像中能够引起人类视觉注意的注意焦点具有较好的检测能力。本文模型对于区域颜色对比度比较明显的图像可取得较好的检测结果,然而对于具有复杂纹理背景的图像有待于进一步的研究。因此,研究更适用的视觉注意计算方法,以及如何更好的将影响视觉注意机制的各因素进行融合,是今后需要进一步努力的方向。
[1] Han J,Ngan K,Li M,etal.Unsupevrised extraction of visual attention objects in color images[J].IEEE Transactions on Circuits and Systems for Video Technology,2006,16(1):141 -145.
[2] Rutishauser U,Walther D,Koch C,etal.Is bottom-up attention useful for object recognition[C].Washington:IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2004:37 -44.
[3] 纪震,蒋峰.基于注意力集中机制的图像压缩算法[J].深圳大学学报(理工版),2001,18(2):51-56.
[4] Cheng Mingming,Zhang Guoxin,Mitra N J,etal.Global Contrast based Salient Region Detection[C].Providence:IEEE Conference on Computer Vision and Pattern Recognition,2011∶409-416.
[5] Treisman A M,Gelade G.A feature - integration theory of attention[J].Cognitive Psycholog,1980,12(1):97 -106.
[6] Boykov Y,Kolmogorov V.An Experimental Comparison of Min-cut/Max-flow Algorithms for Energy Minimization in Vision[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(9):1 124 -1 137.
[7] Felzenszwalb P,Huttenlocher D.Efficient graph-based image segmentation[J].International Journal of Computer Vision,2004,59(2):167 -181.
