结构特征和内容分析融合的博客文章分类
2013-07-11张译匀
张 永,王 芳,张译匀
兰州理工大学 计算机通信学院,兰州 730050
结构特征和内容分析融合的博客文章分类
张 永,王 芳,张译匀
兰州理工大学 计算机通信学院,兰州 730050
1 引言
随着互联网技术的不断发展,博客以极快的速度融入到社会生活中,随之带来海量的博客文章。如何组织其中的大量文章,从中快速准确获取所需要的信息,成为一项重要而紧迫的研究课题。博客文章的分类是其中的核心任务之一。
普通的文本分类方法通常基于主题突出,有明确类别倾向,且多为第三人称对事物叙述,语气较为客观的新闻文章,而考虑到博客文章通常包含多个主题,类别归属不明显,且多为第一人称对事物的叙述,涉及较多的作者的主观意见,且博客文章有标签等自身的结构特性的现象。所以,普通的文本分类并不适用于博客文章分类。目前,对博客文章分类已经开展了一些研究。文献[1]使用标签对博客进行分类,并且发现标签的数量对分类结果有一定的影响,因此通过对标签扩充来进一步改善分类的效果。它们的不足在于以博客作为分类对象,由于一个博客中会包含多个类别的文章,因此这种方法的分类力度不够细致。文献[2]利用文章中提取的关键词代替标签进行博客文章聚类,取得了较好的效果。文献[3]利用博文间的评论,阅读关系,进行文章聚类。文献[4]通过构建一个词条-页面矩阵来对博客进行聚类。它们的不足在于聚类得到的类别数量太大并且结构混乱,缺乏层次性和条理性。
针对上述情况,本文提出一种结构特征和内容分析融合的博客文章分类方法。该方法通过组合期望交叉熵(CrossEntropy)和互信息(MI)两种不同的特征选择方法提取的特征词集前提下,结合正文,标题,标签作为衡量博客文章分类的三个方面,并将其利用分类器训练融合,从而取得好的分类效果。
2 博客文章分类的相关算法
本文采用朴素贝叶斯分类算法作为分类的基本算法。其基本思想是假设文档中词与词之间对于类别的影响是相互独立的前提下,计算文档属于各个类别的概率,最终选择最大的概率值对应的类别作为文档属于的类别[5]。
步骤如下:
(1)根据贝叶斯定理,转换类别对于文档的后验概率,公式如下:

其中,d:文档,ci:第i个类别。P(ci|d):给定文档条件下,文档属于ci的概率。P(ci):类别ci的先验概率。P(d):文档的先验概率,P(d|ci):给定类别ci的条件下,产生文档d的概率。
(2)文档d用向量空间模型表示为一组特征词向量(t1,t2,…,tn),公式(1)的分子部分为:

假设各特征词之间对于类别的影响是相互独立的,公式(2)变为:
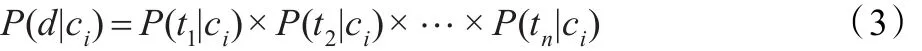
(3)得到的概率值最大的类别为文档d的类别。
3 博客文章的分类过程
给定一个博客文章的集合,本文的目标是取得较好的分类效果。通过期望交叉熵和互信息两种不同的特征选择方法提取的特征词集进行组合,一定程度上改善了博客内容上的多主题,类别归属不明显的现象,结合正文,标题两个方面分类博客文章。利用博客文章自身结构特性上的标签,作为衡量博客文章分类的第三个方面。最终,利用分类器训练融合正文,标题,标签三个方面。
3.1 内容分类
为了改善博客文章内容上,包含多个主题,类别归属不明显,且多为作者自己主观意见的现象,提出结合互信息和期望交叉熵两种不同的特征词选择方法,更好地挖掘出体现博客文章内容的特征词集,从而取得好的分类效果。
3.1.1 融合的特征选择方法
通过实验发现,不同的特征提取方法会产生不同的特征词集合,且各个特征词集合最低重合率还不到10%,每个特征提取方法都倾向于选择自己认为重要的一些特征词,但其他的特征提取方法却不一定这样认为。因此,组合它们选择的特征项结果,来改善博客文章内容上的多主题,类别归属不明显的现象,从而进一步取得较好的博客文章分类效果。
特征项提取的方法[6]有很多,试图组合互信息和期望交叉熵两种不同的特征提取方法提取的特征词集,从而取得更好的分类效果。因为:(1)互信息是在统计语言模型中被广泛采用,且大量的研究表明采用互信息算法的效果要明显优于其他算法。(2)互信息方法是对不同的类别抽取不同的特征项,而期望交叉熵考虑的是各个特征在每个类别中的分布情况,所以本文选取的是互信息与期望交叉熵两种方法进行迭代。下面是这两种方法的标准形式(t表示特征词,ci表示类别)。
互信息函数定义如下:

其中,P(t/ci):训练语料中特征词t出现在类别ci中的概率,P(ci):类别ci出现的概率,P(t):训练语料中特征项出现的频率。对于每一类别来讲,词t的互信息越大,说明该词与该类的共现概率越大。一般取t在所有类中的最大值为其MI值。
期望交叉熵,定义如下:
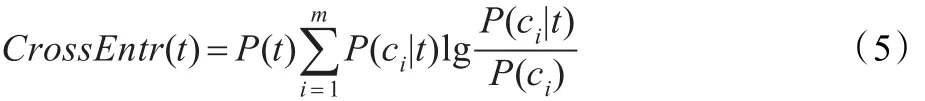
其中,P(ci|t):文章中出现词条t时,文本属于ci的概率,m:类别的总数。如果词条和类别强相关,且相应的类别出现概率又小的话,则说明词条对分类的影响大,相应的函数值就大,就很可能被选中作为特征项。
3.1.2 改进的特征选择过程
(1)分别计算所有特征项的互信息和期望交叉熵。
(2)分别按分值的大小排序。
(3)按互信息和期望交叉熵所占特征集的比例,分别抽取特征项,并将其合并得到特征子集。
(4)计算该条件下对分类性能的影响。
(5)调整比例大小,重复(3)(4)直到获取最优特征子集。
3.1.3 正文,标题分类
利用改进的特征提取方法提取的特征项,结合贝叶斯分类算法,进行博客文章内容的分类。对于一篇博客文章d,利用正文对博客文章分类,得到一组对应各个类别的概率值,其中,P1(d,ci)表示利用正文分类时,博客文章d属于类别ci的概率值,同理利用标题对博客文章分类,得到一组对应各个类别的概率值,其中,P2(d,ci)表示利用标题分类时,博客文章d属于类别ci的概率值。
3.2 标签分类
利用改进的特征提取方法提取的特征项,结合贝叶斯分类算法,进行博客文章结构的分类。标签是一篇博客文章中特有的结构特性,是和文章内容相关的一组关键词。它通常由博客作者自行标注,用来高度概括博客文章的内容,并被证明对博客文章的分类起到了积极作用。对于一篇博客文章d,使用博客文章特有的结构特性:标签,进行分类后,得到一组对应各个类别的概率值,其中,P3(d,ci)表示利用标签分类时,博客文章d属于类别ci的概率值。
3.3 结构特性和内容分析融合的博客文章分类
正文,标题,标签分类都可作为衡量博客文章分类的方面,因此将这三个方面融合。
3.3.1 博客文章的最终分数
对于一篇博客文章d,单独利用正文,标题,标签三方面的一种分类后,得到一组对应各个类别的概率值。将三个方面都分类后,得到各个类别的最终分数:
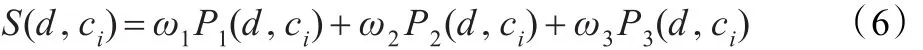
对于任一篇博客文章d,分数最高的类别即为它所属的类别。其中,S(d,ci):类别ci的最终分数,P1(d,ci):使用正文分类时,文章d属于类别ci的概率,P2(d,ci):使用标题分类时,文章d属于类别ci的概率,P3(d,ci):使用标签分类时,文章d属于类别ci的概率。ω1,ω2,ω3三个参数用以权衡不同因素的重要程度。
3.3.2 参数估计
本文采用与文献[7]中多分类器组合类似的方法,估计三个特征权重,区别在于本文只使用一个分类器,训练特征权重。单独使用正文,标题,标签三个方面分类的结果表示为向量P=(Pj1,Pj2,…,Pji),j∈[1,3],其中Pji:使用任一方面 j分类后类别i的概率值。那么,用本文中的三个方面分类后的结果可以用矩阵P=(P1,P2,P3)来表示。根据公式(6),对于文章d,可以得到方程组:
S=P*ω (7)其中,向量ω=(ω1,ω2,ω3)表示要求的特征权重,P为概率矩阵,通过文中的三个方面分类可以获取。S=(S(d,c1),S(d,c2),…,S(d,c5))表示累加后各个类别的分数,通过人工标注可以得到。
在训练权重时,对训练集中文章的类别进行标注。一般而言,标注后训练集中的文章d属于某正确类别的概率设为1,属于其他类别的概率均为0。但为了避免出现过拟合现象,为其他类别加入松弛变量,即假设文章属于正确类别的分数S为θ,剩下的错误类别对应的分数为(1-θ)/ (m-1),m为类别总数。保持所有类别的概率值总和为1。选择θ值时,应考虑使文章属于错误类别的概率值要远小于正确类别的概率θ,从而保证加入的松弛变量对分类结果影响很小,同时有效避免了过拟合现象。因此,对于文章d,可以利用公式(7),用线性回归的方法求得向量ω的值。然后,对总训练文章的解求平均值,从而得到最终的特征权重。
4 实验与结果分析
4.1 数据集
实验中利用Heritrix从http://blog.sina.com.cn/网站抓取5 000篇博文,因为博客网站中文章类别标注错误的现象比较严重,所以需要对抓取的博客文章重新人工标注文章类别。并且考虑到部分博客文章的标签,正文可能为空,所以经过筛选,得到标签和正文两个特征都不为空的4 000篇博客文章。本文只选取健康,财经,军事,娱乐和体育5个类别进行训练和测试。其中,这5个类别的分布情况如表1所示。

表1 各主题类文本分布
本文从各主题类别中分别取出200篇作为训练集,200篇作为测试集,训练集和测试集彼此不重叠,不包括任何重复博客文章。
4.2 评价指标
采用标准的查全率和查准率以及F-调和均值作为评价准则[8]。
查全率(Recall)是与人工分类结果吻合的博文数与分类应有的博文数的比率。

查准率(Precision)是与人工分类结果吻合的博文数与总博文数的比率。

F-调和均值综合考虑了查全率和查准率,其值能够更好地反映分类性能,取值在[0,1]范围内,当查全率和查准率都增大时,F的值也增大,F值越大表示性能越好。其定义如下:
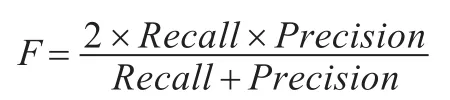
4.3 结果与分析
实验分为两部分,第一部分验证互信息和期望交叉熵在特征集中所占的比例是多少时,能得到最优的特征集,更好地达到分类的效果;第二部分验证利用互信息和期望交叉熵组合的最优比例,且区分博客文章的标签,正文,标题对分类的影响。
4.3.1 特征子集
针对3.1.2节改进的特征抽取过程中,特征集由互信息和期望交叉熵两部分组成,考虑到测试集和训练集的数目相对较少的情况,本文通过大量实验,利用互信息在特征集中10%的比例递增,相反期望交叉熵以10%递减的比例,且未区分博客文章的标签,正文,标题对分类影响,分别对5个类别的分类效果验证,数据结果如表2所示。
从表2可以看出,利用互信息和期望交叉熵结合的方法进行特征抽取,明显优于单独使用互信息或期望交叉熵的特征抽取方法,且最优的特征集组合是,互信息占70%,期望交叉熵占30%。然而,这个实验结果也与所选的类别及比例递进的间隔有关,今后将在更多类别中收集数据,以进行更全面的验证。
由于F-调和均值能更好地反映分类性能,故进行F的比较,结果如图1所示。
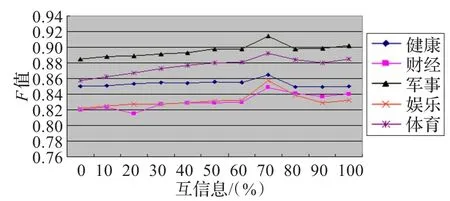
图1 不同特征集组合的分类方法F值比较
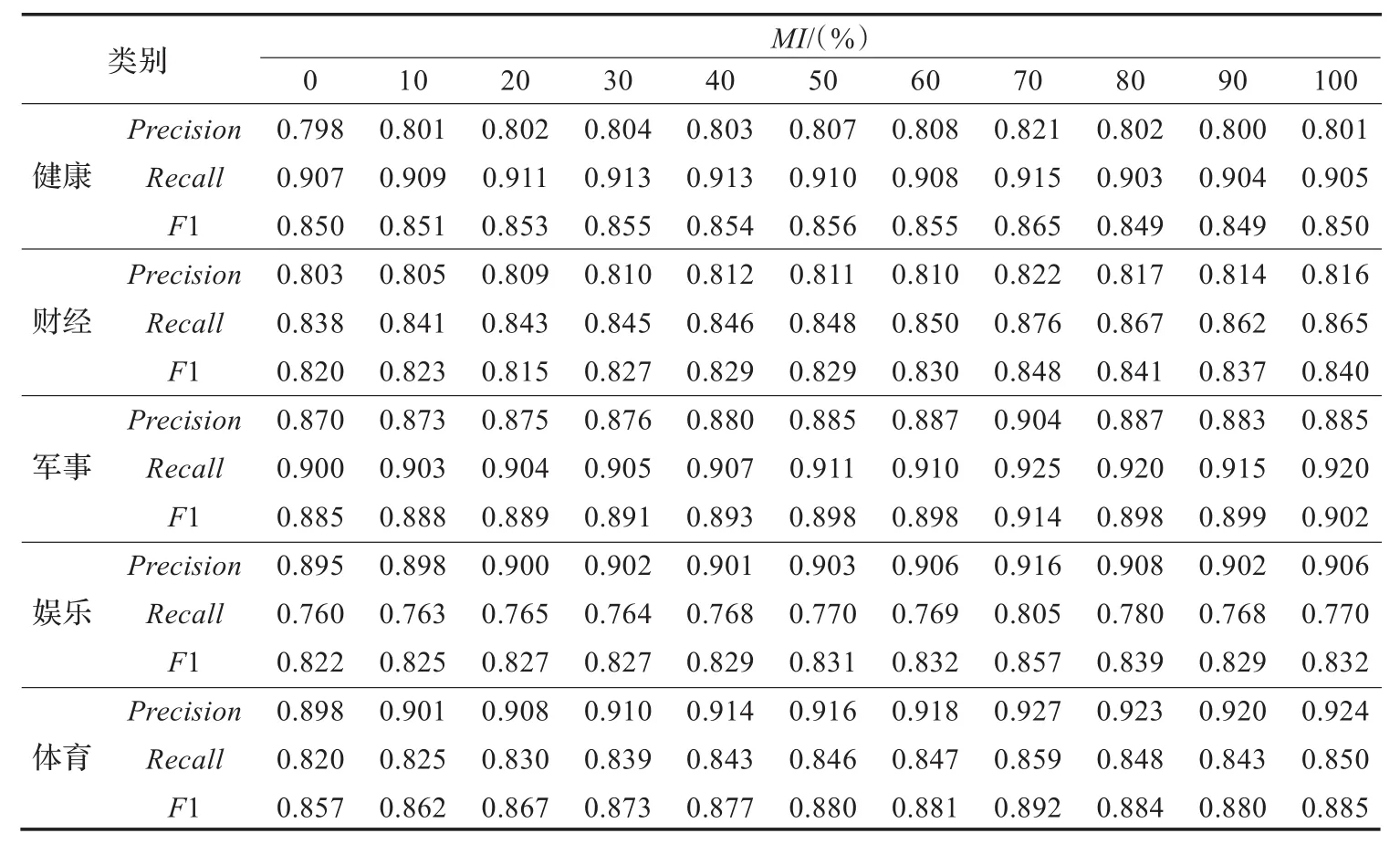
表2 不同特征集组合的博客文章分类结果
4.3.2 分类结果
改进前,采用互信息占70%,期望交叉熵占30%的最优特征子集进行特征选择,但未区分博客文章的标签,正文,标题对分类的影响,利用传统贝叶斯分类。改进后,采用互信息和期望交叉熵的最优组合进行特征选择,且区分博客文章的标签,正文,标题对分类的影响。训练中,考虑到本文的类别总数只有5类,比较小,所以选取θ=0.7,而剩下的错误分类每个只占0.3/4=0.075,这样就远小于0.7。训练后得到的标题,正文,标签三个特征的特征权重分别为0.27,0.25,0.48。利用这三个特征权重,分别对改进前和改进后的分类效果比较,数据结果分别如表3和表4所示。
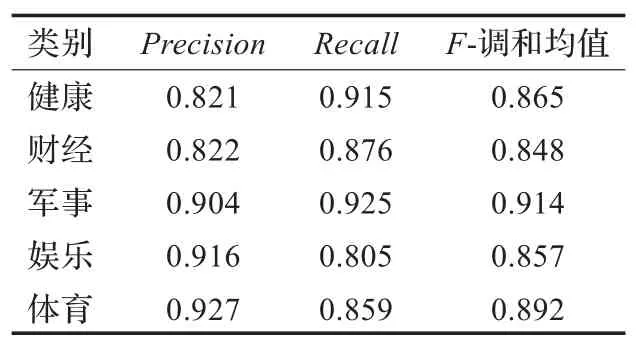
表3 改进前博客文章的分类结果
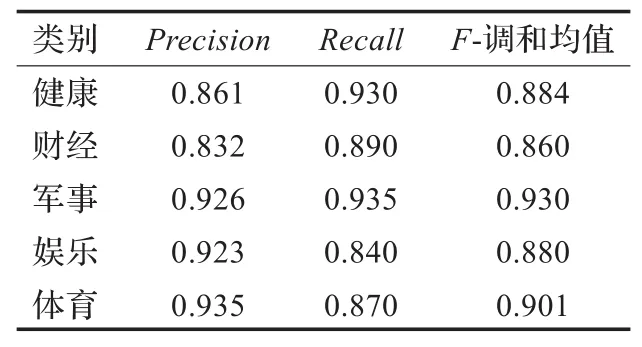
表4 改进后博客文章的分类结果
从表3和表4可以看出,改进后博客文章的分类性能有显著的提高,主要原因是:改进前的分类方法,忽略了博客文章不同与普通文本的,特有的结构特性和内容特性,所以造成查全率和查准率较低的现象。而本文的改进方法,全面考虑博客文章的特性,内容上,通过期望交叉熵和互信息的最优组合,利用正文,标题两个方面分类。结构上,利用博客文章特有的标签分类,并区分三个方面对分类的影响。
由于F-调和均值能更好地反映两种方法的分类性能,故进行F的比较,结果如图2所示。
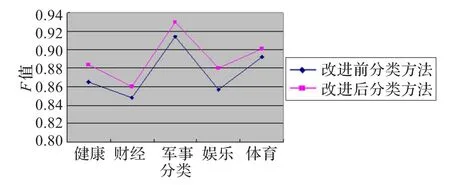
图2 两种博客文章分类方法的F值比较
5 结论
本文针对博客文章的结构特征和内容分析,提出一种改进的贝叶斯博客文章分类算法。通过组合期望交叉熵和互信息两种不同的特征选择方法提取特征词集,结合正文,标题,标签作为衡量博客文章分类的三个方面,并将其利用分类器训练融合。实验证明,该方法有效地提高了博客文章分类的性能。在以后的工作中,将把构建博客作者的兴趣,考虑博客的其他结构特征等,作为文章分类的新重点。
[1]Sun Aixin,Suryanto M A,Liu Ying.Blog classification using tags:an empirical study[C]//LNCS 4882:ICADL 2007.Berlin:Springer-Verlag,2007:307-316.
[2]Brooks C H,Montanez N.Improved annotation of the blogosphere via autotagging and hierarchical clustering[C]//WWW'06. New York:ACM,2006:625-632.
[3]Li Xin,Yan Jun,Fan Weiguo.An online blog reading system by topicclustering and personalized ranking[J].ACM Transactions on Internet Technology,2009,9(3).
[4]Li Beibei,Xu Shuting,Zhang Jun.Enhancing clustering blog documentsby utilizing author/readercomments[C]//ACM-SE 45:Proceedings of the 45th Annual Southeast Regional Conference.New York:ACM,2007:94-99.
[5]Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[6]Yang Yiming,Pedersen J O.A comparative study on feature selection in text categorization[C]//Proceedings of the 14th International Conference on Machine Learning.San Francisco,CA,USA:Morgan Kaufman Publishers,1997:412-420.
[7]Ni Xiaochuan,Wu Xiaoyuan,Yu Yong.Automatic identification of Chinese weblogger's interests based on text classification[C]//Proceedings of IEEE/WIA/ACM International Conferenceon Web Intelligence.Washington,DC,USA:IEEE Computer Society,2006:247-253.
[8]徐威,董渊.针对中文文本自动分类算法的评估体系[J].计算机科学,2007,34(18):177-179.
ZHANG Yong,WANG Fang,ZHANG Yiyun
School of Computer and Communication,Lanzhou University of Technology,Lanzhou 730050,China
Aiming at the problems of blog posts contents including multiple themes,unobvious categories ownership and more author's subjective views,structures including tags which are different from texts,common text classification methods not performing well,a new blog posts classification method is presented based on structural characteristics and content analysis.By taking into account blog posts content features,it iterates two different feature extraction methods to enhance the representative ability of feature collection effectively,makes use of main body and title classification.By taking into account the structural features of blog posts,it makes use of tags classification and finally fuses three aspects.The experimental results show that the performance of the improved method is obviously better than common text classification methods.
text classification;blog post classification;structural characteristics;content analysis
针对博客文章内容上,包含多个主题,类别归属不明显,多为作者自己主观意见且结构上,包括不同于文本的标签,普通文本分类方法直接应用于博客文章效果不理想的问题,提出一种结构特征和内容分析融合的博客文章分类方法。内容上,通过迭代两种不同特征选择方法,提高特征集代表性的前提下,利用正文,标题两个方面分类.结构上,利用博客文章特有的标签分类,并将三个方面融合。实验结果表明,改进的分类方法有效地提高了博客文章分类的性能。
文本分类;博客文章分类;结构特征;内容分析
A
TP391
10.3778/j.issn.1002-8331.1107-0441
ZHANG Yong,WANG Fang,ZHANG Yiyun.Structural characteristics and content analysis fusion for blog post classification.Computer Engineering and Applications,2013,49(5):123-126.
张永(1968—),男,教授,研究领域:智能信息处理;王芳,女,硕士;张译匀,女,硕士。E-mail:3wf851008@163.com
2011-07-21
2011-09-06
1002-8331(2013)05-0123-04
CNKI出版日期:2011-11-14 http://www.cnki.net/kcms/detail/11.2127.TP.20111114.0941.032.html
