基于AdaBoost的组合网络流量分类方法❋
2013-06-27赵小欢夏靖波连向磊李巧丽
赵小欢,夏靖波,连向磊,李巧丽
(1.空军工程大学信息与导航学院,西安710071;2.解放军71155部队,山东威海264200;3.解放军94326部队,济南250023)
基于AdaBoost的组合网络流量分类方法❋
赵小欢1,❋❋,夏靖波1,连向磊2,李巧丽3
(1.空军工程大学信息与导航学院,西安710071;2.解放军71155部队,山东威海264200;3.解放军94326部队,济南250023)
针对单一分类方法在训练样本不足的情况下对于小样本网络流分类效果差的特点,通过自适应增强(Adaptive Boosting,AdaBoost)算法进行流量分类。算法首先使用CFS(Correlation-based Feature Selection)特征选择方法从大量网络流特征中提取出少量高效的分类特征,在此基础上,通过AdaBoost算法组合决策树、关联规则和贝叶斯等5种单一分类方法实现流量分类。实际网络流量数据测试表明,基于AdaBoost的组合分类方法的准确率在所选的几种算法中是最高的,其能够达到98.92%,且相对于单一的分类算法,组合流量分类方法对于小样本网络流的分类效果具有明显提升。
网络流;流量分类;相关特征选择;自适应增强算法;组合分类器
1 引言
随着近年来互联网的不断发展,社交网络、在线视频、电子商务、即时通信、微博、P2P应用等多种新兴业务不断涌现并迅速占据互联网中主流应用位置,互联网流量在组成和性质上发生了较大的变化,网络的可控可管性变得越来越差。由于不同的网络应用对于带宽、时延等指标的需求不同,不同等级用户占用的网络资源不同,仅通过网络层和传输层流量实现网络流量管理是不够充分的,而需要将网络流量映射到特定的业务,根据网络业务实现网络流量的精细划分、分级管理和差异化服务。同时,精确的流量分类对网络安全、网络计费、网络规划等也具有重要的意义。
为了应对互联网流量数据庞大、结构复杂、属性动态变化的特点,利用机器学习方法挖掘流量数据从而实现流量分类成为网络流量分类的研究热点,目前已有较多文献将多种机器学习算法引入到网络流量分类中。Thuy在文献[1]中将网络流量分类方法分为无监督算法(聚类算法)、有监督算法和半监督算法3类,并详细综述了2004~2007年间网络流量分类领域的18项重要工作,最后从时间复杂度与持续分类能力、方向无关性、存储与计算复杂度、健壮性与鲁棒性等方面探讨了多种流量分类方法在实际应用时面临的挑战。文献[2]选取日本、韩国和美国的7组流量数据并通过实验全面对比了基于端口、基于主机行为和基于流特征的流量分类方法,文中指出各种流量分类方法均存在优势及不足,并且在所对比的几种机器学习分类方法中,SVM算法具有最高的准确性和鲁棒性。文献[3]通过对比C4.5、Naive Bayes、L7方法在相同时间段不同观测点及不同时间段同一观测点两种情况下的流量分类效果,指出C4.5方法具有良好的时间空间适应性。文献[4]指出现有的机器学习流量分类方法只是在特定的条件和假设下具有良好的分类效果,在多种网络环境及不同粒度的情况下,没有哪一种机器学习算法能够始终比其他算法分类效果好,文中通过最大似然组合、D-S证据理论、增强型D-S证据理论等理论融合流量分类中常见的几种分类算法,改善了网络流量分类的效果和鲁棒性。文献[5]也指出多种分类方法的有效组合是网络流量分类发展的一个重要方向。
本文通过实际网络流量数据对比了流量分类中常见的NBTree、PART、C4.5、B-Net(Bayes Net)、BKernel(Bayes Kernel)和SVM 6种分类方法,发现各种单一分类算法在训练样本不足的情况下对于小样本网络流的分类效果较差,基于此,本文采用基于AdaBoost(Adaptive Boosting)的组合分类方法组合决策树、关联规则和贝叶斯等5种方法进行流量分类。实验结果表明,相对于单一分类算法,基于AdaBoost的组合分类方法具有较高的准确性,算法在一定程度上能够有效降低单一分类算法过于依赖特定假设分布的要求,算法具有更好的鲁棒性和适用性。
2 AdaBoost组合网络流量分类方法
采用机器学习方法实现网络流量分类主要包括两方面的工作:首先,需要按照不同粒度(常见的粒度包括TCP Connection、Flows、Biflows、Services、Hosts等)将网络流量归并成网络流,从网络流中选择合适的流属性构建分类特征向量;其次,需要选择合适的机器学习分类算法实现网络流量分类。本文采用的基于AdaBoost的组合网络流量分类方法的框架如图1所示。

图1 AdaBoost组合分类框架Fig.1 Framework of ensemble classification based on AdaBoost
2.1 网络流量特征选择
网络流量分类特征的选择对于机器学习分类方法至关重要,过度相关或冗余的特征会对机器学习算法的性能造成负面影响,同时流量特征的增加使得机器学习算法需要的空间和时间复杂度急剧增加,因此选择足够少、但能够提供高效分类信息的特征子集十分必要[1]。
特征选择方法主要分为两种模式:过滤器方式和封装器方式。过滤器方式利用数据本身的特征作为特征子集的度量指标,而封装器方式利用机器学习算法的准确率作为特征子集的度量指标。考虑到机器学习算法的性能要求,按照Moore等在文献[6]中定义的网络流特征,本文首先采用NetMate[7]软件从网络流量中提取出TCP流特征,然后采用基于CFS(Correlation-based Feature Selection)的过滤器方式从大量冗余流特征中选择合适的特征子集。
CFS方法是一种经典的可以消除无关重复变量的基于过滤器方式的特征选择方法,使用如下变量子集评估方法给变量子集排序:
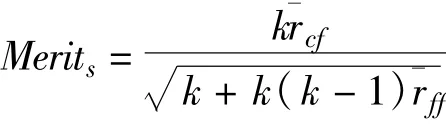
其中,Merits表示一个包含k个特征的特征子集S的评价,¯rcf表示平均特征类别相关系数(f∈S),¯rff表示平均特征特征相关系数。通过该评价指标能够有效地给出特征对于分类的贡献度,从而清除贡献度低的特征。表1描述了基于CFS方式选择的TCP流分类时使用的流特征。
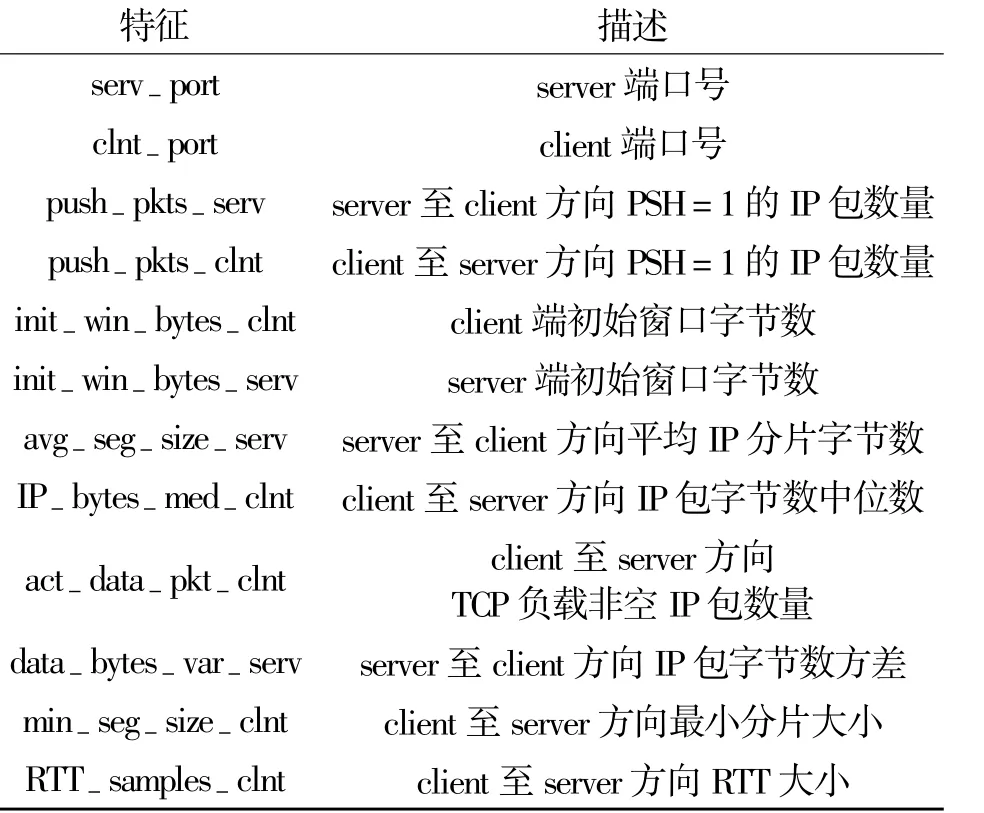
表1 TCP流特征描述Table 1 Characteristics of TCP flows
2.2 AdaBoost组合流量分类方法
根据“没有免费的午餐”法则可知,没有一种学习算法可以在任何领域总是产生最准确的学习器[8]。每一种机器学习算法都需要构建一个基于一组假设的某种模型,当假设在数据上不成立时,这种归纳偏倚将导致误差。学习是一个不适定问题,并且在有限的数据上,每种学习算法都收敛到不同的解,并在不同的情况下失效,可以通过性能调节使一个学习算法在确认集上达到尽可能最高的准确率,但即使对最好的学习算法也存在实例使其不能足够准确。同时由于不同地域、不同链路、不同应用产生的网络流量千差万别,文献[3]通过实验也指出即使是在特定时间、特定流量数据上性能最优的分类算法,当其适用于更长时间及不同地域的流量时,算法的分类准确性迅速降低,因此期望得到一种普遍适用的性能最优的网络流量分类算法是很难实现的。
通过多个单分类器组合能够克服单一分类器中对于某些实例分类效果差的问题,从而提升系统的分类精度。多分类器组合有两种常见类型:并联组合和串联组合。装袋法(bagging)和提升法(boosting)是并联与串联两种组合的典型代表。在Boosting算法中,首先需要根据已有的训练样本集选择一个准确率比平均性能要好的基分类器,分类器对样本正确分类后要降低该样本的权重,而错误分类时,则要增加错误分类样本的权重,而后加入的基分类器着重处理比较难的训练样本,最终得到一个分类准确率较高的组合分类器。
AdaBoost算法是Freund和Schapire根据在线分配算法提出的一种利用大量分类能力一般的基分类器通过一定方法组合成分类能力强的组合分类器的方法,组合分类器为基分类器加权投票的线性组合。AdaBoost算法的弱分类器组合方法和训练方法的有效性已经得到了证明并有大量应用验证,其中基于AdaBoost算法的人脸检测方法已经成为目前人脸检测最成功的方法之一[9]。本文选用AdBoost M1算法处理网络流量分类问题,它可以处理两种类别以上的分类问题。基于AdaBoost的组合流量分类算法的描述如下。
给定训练集
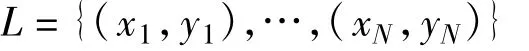
其中,xi表示网络流对应的特征向量,yi表示网络流对应的应用类型,i=1,2,…,N,yi∈{1,2,…,J},令T表示基分类器的数目,令ht(x)表示第t个基分类器,其中t=1,…,T,令mt表示训练第t个基分类器ht(x)时使用的分类方法,其中分类方法包括C4.5、B-Kernel、PART、NBTree、B-Net 5种类型。
(1)对于t=1,初始化样本权值Dt(i)=1/N,i=1,2,…,N,以概率分布Dt(i)从训练样本集L中可放回重复抽样得到样本数为N的新的训练集L1,
使用分类方法m1对训练集L1进行训练得到基分类器h1(x),应用基分类器h1(x)对原始样本集L上所有样本进行分类,计算错误率


以概率分布Dt(i)从原始样本集L中可放回重复抽样得到样本数为N的新的训练集Lt,使用分类方法mt对训练集Lt进行训练得到基分类器ht(x),应用基分类器ht(x)对原始样本集L上所有样本进行分类,计算错误率若εt≥0.5,T=t-1,结束;否则
(3)组合J个基分类器ht(x)得到组合分类器H(x),对于xi,使得
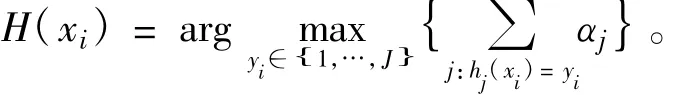
3 实验与评价
3.1 实验数据基本信息
早期的网络流量分类方法中大部分采用的均是2003年的Moore数据集[6],主要原因是出于隐私的考虑,我们能够得到的网络流量基本上都去除了有效载荷,并且IP包头信息也采用了匿名化技术,导致研究者无法有效地获得各网络流对应的应用类型来评估自己的分类方法。一种可能的解决方案是网络流量发布者在匿名处理流量之前先采用特定的流量标记工具(如L7-Filter、GVTS(Ground Truth Verification System))标记好网络流对应的应用类型,然后将匿名化的流量及对应的应用类型共同发布,如UNIBS[10]数据库就提供了部分标记好的网络流量数据。由于Moore数据集采集的时间较早,许多新出现的网络应用在Moore数据集中并没有体现,基于此,本文选用文献[3]提供的一条吉比特链路2007年的流量数据集,该数据集为剑桥大学计算机实验室所提供,且该数据集提供了详细的应用类型标记信息以供研究者评估自己的算法。从数据集中提取30 min的TCP流评估流量分类方法,其中TCP流对应的分类结果、流数量和具体的网络应用情况如表2所示。
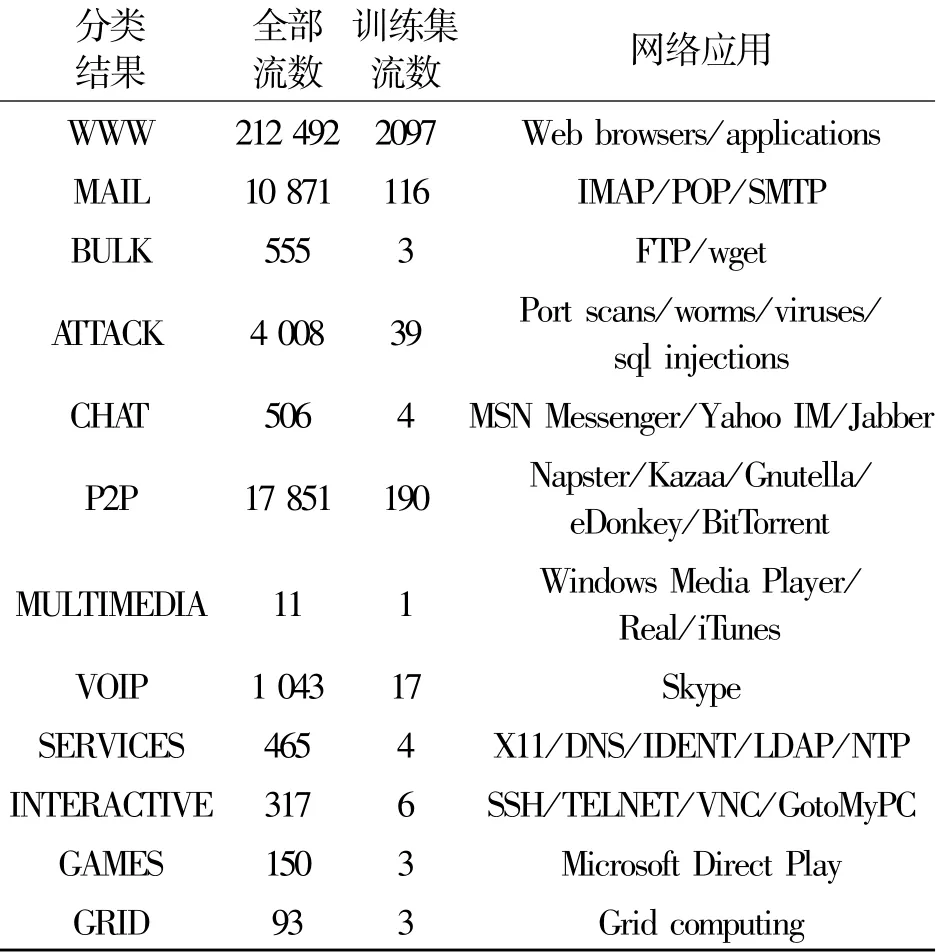
表2 TCP流组成Table 2 Composition of TCP flows
3.2 分类结果及对比
本文选用C4.5、NBTree、PART、B-Net、B-Kernel、SVM和AdaBoost组合分类方法共7种算法测试分类效果。其中C4.5与NBTree分类方法为基于决策树的算法,PART分类方法为基于关联规则的算法,B-Net与B-Kernel分类方法为基于贝叶斯原理的算法,SVM支持向量机方法通过非线性映射和结构风险最小化原则实现分类,且SVM类型选为CSVM,核函数选为径向基RBF函数,AdaBoost方法通过AdBoost M1算法组合除SVM外其余5种分类算法实现分类(通过选择不同原理、互有差异的分类方法构造基分类器,有利于实现各种方法的优势互补,提高组合分类模型的分类效果)。本文采用数据挖掘软件Weka[11]实现6种单一的分类算法,而AdaBoost组合分类方法通过Matlab和Weka软件共同实现。
由于在实际的网络环境中获取网络流对应的应用类型是比较困难的,为了能够更加贴近实际网络环境,本文选用小训练样本集测试流量分类效果。首先从整个数据集共248 362条TCP流中无放回等概率抽取1%共2 483条TCP流构成训练集,以整个TCP数据集作为测试集,训练集中各种应用类型对应的流数如表2所示。同时采用AdaBoost算法计算出的组合分类方法中各基分类器的权值,如表3所示。
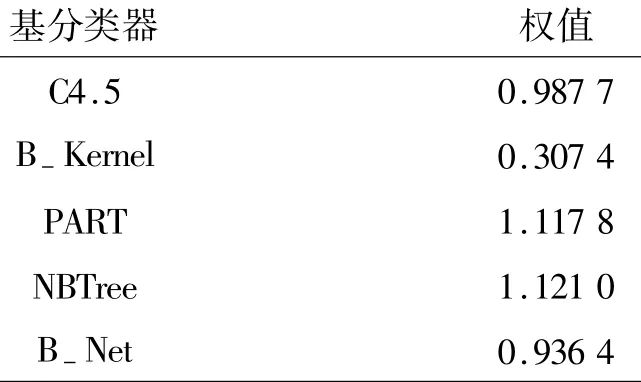
表3 AdaBoost方法基分类器权值Table 3 Weights of base classifiers for AdaBoost
表4显示了7种分类算法在测试集上的分类效果,其中各种应用类型对应的单元格格式为:准确率(Precision)/召回率(Recall),例如采用NBTree算法分类WWW类型得到的结果为0.996/0.998,该分类结果表示:分类结果为WWW的流中有99.6%的流是正确的WWW流,同时测试集全部WWW流中有99.8%的流被正确分类为WWW流。

表4 TCP流分类效果对比Table 4 Comparison of classification accuracy of TCP flows
从表4中可以看出,即使是在1%的抽样率的情况下,7种算法的总体流分类准确率仍然较高,效果最差的SVM算法其总体流准确率也达到了85.723%,同时表中几种单一的分类算法对于不同的应用类型分类效果高低不一,很难准确地评判出哪种算法优于其他算法。各种单一分类算法对于训练集中小样本网络流的分类效果较差,对于训练集中流数为1的MULTIMEDIA流,NBTree、PART、C4.5 3种算法完全无法识别出TCP流测试集中对应的应用类型。
值得注意的是,与文献[2]得出SVM算法具有最高准确性和鲁棒性的结论不同,本文实验中SVM算法的流准确率是几种单一分类算法中最低的。对于BULK、CHAT、MULTIMEDIA、SERVICES、INTERACTIVE、GRID 6种小样本网络流,SVM算法在测试集中检测到的流数与训练集中检测到的流数完全相等,这意味着SVM算法完全没有识别出测试集中新出现的BULK、CHAT等6种应用流。可以推断出SVM算法在训练样本分布不均衡的情况下为了寻求最优分类平面导致出现了过拟合(overfitting)的现象。同时,由于SVM算法的时间复杂度明显高于其他5种单一分类算法,因此组合分类方法中并未采用SVM算法构造基分类器。
通过对比各种单一分类算法以及组合分类方法可以看出,相比于单一的分类算法,基于AdaBoost的组合分类方法的分类准确率在各种算法中是最高的,算法的总体流准确率达到98.92%,算法的分类效果要优于文献[2-3]采用的SVM和C4.5分类方法;同时对于各种小样本网络流,如训练流数为1的MULTIMEDIA流及训练流数为4的SERVICES流等,AdaBoost组合分类方法的分类效果相对于单一分类方法具有明显的提升。
由于数据分布不均衡是网络流量的一个重要特征,在各种情况下获取的流量数据中必然存在部分网络流的规模远大于其他网络流的现象,而各种单一分类方法对于小样本网络流的分类效果波动较大,基于AdaBoost的组合流量分类方法通过赋予前一次分类错误的样本更高的权重实现多个基分类器的加权组合,算法能够取得更加稳定的分类效果。因此AdaBoost组合流量分类方法能够在一定程度上克服单一分类算法过于依赖特定数据分布的缺点,算法具有更好的实用性和鲁棒性。
4 结论
随着互联网规模的不断扩大和新兴业务的持续涌现,互联网的可控可管性越来越差,精确的网络流量分类是实现网络可控可管的关键,同时流量分类对于网络性能、网络安全、网络计费、网络规划等也具有重要的作用。基于机器学习的流量分类方法是近年来网络流量分类领域的研究热点之一,由于传统的单一机器学习算法都需要构建基于特定假设的某种模型,不能满足复杂多变的网络流量的分类要求,本文采用基于AdaBoost的组合流量分类方法组合决策树、关联规则和贝叶斯共5种方法进行流量分类,算法在1%训练样本的情况下能够正确分类出测试集中98.92%的网络流,算法的分类效果优于常用的单一流量分类算法,同时AdaBoost组合流量分类方法能够在一定程度上克服单一分类算法对于小样本网络流分类效果差的问题,算法对于待分类数据的分布要求低,具有更广泛的实用性和更好的鲁棒性。
然而AdaBoost组合流量分类方法同样存在小样本网络流分类效果低于大样本网络流的问题,这是由于网络流分布的不均衡以及多分类AdaBoost算法仅考虑错分代价总和最小而不区分不同类型代价的差异所致。为进一步提高小样本网络流的分类效果,下一步可考虑引入重抽样技术使得训练样本集的不平衡度降低,或者对于某些关键的少数类引入较大的加权系数使得这些类被错分时产生较大的代价来改进AdaBoost组合分类方法。
[1]Nguyen T T,Armitage G.A Survey of Techniques for Internet Traffic Classification using Machine Learning[J].IEEE Communications Surveys&Tutorials,2008,10(4):56-76.
[2]Kim H,Claffy K C,Fomenkov M,et al.Internet traffic classification demystified:Myths,caveats,and the best practices[C]//Proceedings of 2008 ACM CoNEXT Conference.New York:ACM,2008:1-12.
[3]Li Wei,Canini M,Moore A W,et al.Efficient application identification and the temporal and spatial stability of classification schema[J].Computer Networks,2009,53(6):790-809.
[4]Callado A,Kelener J,Sadok D,et al.Better network traffic identification through the independent combination of techniques[J].Journal of Network and Computer Applications,2010,33(4):433-446.
[5]Dainotti A,Pescape A,Claffy K C.Issues and Future Directions in Traffic Classification[J].IEEE Network,2012,26(1):35-40.
[6]MooreA W,Zuev D.Internet traffic classification using Bayesian analysis techniques[C]//Proceedings of 2005 International Conference on Measurement and Modeling of Computer Systems.Banff,AB,Canada:ACM,2005:50-60.
[7]Schmoll C,Zander S.Network Measurement and Accounting Meter[EB/OL].[2013-04-08].http://sourceforge. net/projects/netmate-meter/.
[8]范明,昝红英,牛常勇.机器学习导论[M].北京:机械工业出版社,2009:230-231. FAN Ming,ZAN Hong-ying,NIU Chang-yong.Introduction to Machine Learning[M].Beijing:China Machine Press,2009:230-231.(in Chinese)
[9]Viola P,Jones M.Robust real-time face detection[J].International Journal of Computer Vision,2004,57(2):137-154.
[10]Gringoli F,Salgarelli L,Dusi M,et al.GT:picking up the truth from the ground for Internet traffic[J].ACM SIGCOMM Computer Communication Review,2009,39(5):13-18.
[11]Witten I H,Frank E,Hall M A.Data Mining:Practical Machine Learning Tools and Techniques[M].3rd ed.San Francisco:Morgan Kaufmann Publishers,2011:424-438.
ZHAO Xiao-huan was born in Zaoyang,Hubei Province,in 1984.He received the M.S. degree from Air Force Engineering University in 2009.He is currently working toward the Ph.D.degree.His research concerns network traffic measurement.
Email:zxhzxh-2012@163.com
夏靖波(1963—),男,河北秦皇岛人,教授、博士生导师,主要研究方向为军事信息网络管理与安全;
XIA Jing-bo was born in Qinhuangdao,Hebei Province,in 1963. He is now a professor and also the Ph.D.supervisor.His research concerns military information network management and security.
连向磊(1981—),男,山东荣城人,硕士,工程师,主要研究方向为军事信息网络管理;
LIAN Xiang-lei was born in Rongcheng,Shandong Province,in 1981.He is now an engineer with the M.S.degree.His research concerns military information network management.
李巧丽(1983—),女,山东聊城人,硕士,工程师,主要研究方向为网络测量与管理。
LI Qiao-li was born in Liaocheng,Shandong Province,in 1983.She is now an engineer with the M.S.degree.Her research concerns network measurement and network management.
Ensemble Classification Overnetwork Traffic Based on AdaBoost
ZHAO Xiao-huan1,XIA Jing-bo1,LIAN Xiang-lei2,LI Qiao-li3
(1.Institute of Information and Navigation,Air Force Engineering University,Xi′an 710077,China;2.Unit 71155 of PLA,Weihai 264200,China;3.Unit 94326 of PLA,Jinan 250023,China)
To cope with the poor performance of single classification algorithms on minority flows when the train dataset is deficient,the AdaBoost(Adaptive Boosting)algorithm is introduced to classify network traffic.On the basis of selecting few but effective classification features with CFS(Correlation-based Feature Selection)method from a variety of flow′s features,the AdaBoost algorithm is used to combine five single classification algorithms which belong to Decision Tree,Rules and Bayes respectively for the sake of traffic classification.The experiment over real network traffic shows that the AdaBoost algorithm has the highest precision up to 98.92%among the selected classification algorithms.Moreover,the AdaBoost algorithm achieves great improvement on the performance of minority flows′classification compared with single classification algorithms.
network traffic;traffic classification;correlation-based feature selection;adaptive boosting algorithm;ensemble classifier
The Natural Science Basic Research Project of Shaanxi Province(2012JZ8005)
date:2013-04-09;Revised date:2013-06-18
陕西省自然科学基础研究计划重点项目(2012JZ8005)
❋❋通讯作者:zxhzxh-2012@163.comCorresponding author:zxhzxh-2012@163.com
TP393
A
1001-893X(2013)09-1207-06

赵小欢(1984—),男,湖北枣阳人,2009年于空军工程大学获通信与信息系统专业硕士学位,现为博士研究生,主要研究方向为网络流量测量;
10.3969/j.issn.1001-893x.2013.09.017
2013-04-09;
2013-06-18
