面向《道德经》英译的基于短语的机器翻译探析
2013-06-01姚振军郑旭红徐鹏涛王继升
姚振军, 郑旭红, 徐鹏涛, 王继升
(1.河南大学外国语言文学博士后流动站,河南开封 475001/东北财经大学国际商务外语学院,辽宁大连 116025; 2.大连外国语学院计算机教研部,辽宁大连 116002;3.东北财经大学管理科学与工程学院,辽宁大连 116025)
面向《道德经》英译的基于短语的机器翻译探析
姚振军1, 郑旭红2, 徐鹏涛3, 王继升3
(1.河南大学外国语言文学博士后流动站,河南开封 475001/东北财经大学国际商务外语学院,辽宁大连 116025; 2.大连外国语学院计算机教研部,辽宁大连 116002;3.东北财经大学管理科学与工程学院,辽宁大连 116025)
本文以《道德经》现有英译本为训练集,进行基于短语的面向古汉语到英语的统计机器翻译研究。实验分别以字为基本分词单位和以短语为基本分词单位对同一源文本进行处理,并对比两次实验所得机器翻译的译文评测的BLEU值,研究发现:在《道德经》英译中,基于短语的统计机器翻译的具有一定优势。
机器翻译;中文分词;道德经;古汉语;英译
1.0 引言
翻译已经成为现代社会中的一项重要的语言服务活动(徐彬、郭红梅,2012:103),而机器翻译是当代科学技术的十大难题之一(冯志伟,2004)。现代的机器翻译研究已有半个多世纪的历史,其间产生过令人振奋的成果,也有过令人沮丧的时候,但无论多么艰深,人类对于机器翻译的探索和渴求始终也没有停止过。(王海峰,2011:72)
在国际上,机器翻译已经取得巨大的成就,设在美国俄亥俄州代顿的美国联邦翻译部和欧洲联盟委员会设在卢森堡的翻译中心每天都在用自动的机器翻译进行着大规模的翻译;成千上万的商业机器翻译系统在日本投入使用;每天世界各地的网民在使用着浏览器上提供“翻译此页面”的功能。(Wilks,2008)机器翻译应用领域从天气预报翻译到专利文献的机器翻译,涉及语种从俄、英到“谷歌翻译”提供的多种语言之间的即时机器翻译,使用人数超过1000万的语言约有100种,而谷歌翻译已经实现了对其中58种语言的支持。(许磊,2011)
中文信息处理作为自然语言处理中的一个分支,近几年来备受关注。(刘群,2011)机器翻译研究是中文自然语言处理研究中的热点和焦点之一,研究角度和方法不断丰富。国内机器翻译研究从汉语与主要外语相互机译扩展到汉语与国内民族语言的多/双语语料库的建设和机译。目前己经开发并投入使用的翻译系统和软件通常侧重于中英、中日、中俄等不同语种之间的互译。
专门针对古代汉语与现代汉语之间机器互译的研究还比较少,国内学者在分析现有机器翻译研究方法的基础上,提出了一种基于实例的古今汉语机器翻译系统并进行了设计与实现(王爽等,2009),目前国内外专门的面向古代汉语与外语互译的机器翻译的研究仍处于探索阶段。
本研究以王弼本的《道德经》为训练集,探索面向古汉语英译的机器翻译的研究。古汉语仍以现代人书面和口头引用方式出现在自然语言处理的实践中,成为影响汉英机器翻译译文质量的一个侧面;同时,在对外文化交流和中国传统文化外传过程中,大量的古汉语典籍和相关研究文献需要外译,开展面向古汉语的机器外译研究可在一定程度上解决专门翻译人才不足的问题。
2.0 基于短语的《道德经》统计机器翻译
2.1 运行环境及相关开源工具
运行环境为 Centos 6.3版的 Linux平台,在Linux平台下利用开源工具Niutrans构建《道德经》统计机器翻译系统,该系统需要gcc、g++和GNU Make软件的支持。采用Stanford汉语分词工具得到汉语分词,使用GIZA++进行词语对齐训练,采用Niutrans工具包进行短语语法规则抽取、语言模型训练、重排序模型和生成模型的训练及解码。
2.2 系统的整体框架
该系统包括数据预处理、词对齐、短语规则抽取、短语规则打分、语言模型训练器、权重调优和短语解码器几个模块(银花等,2011:92),所有这些模块分为训练和解码两个阶段。系统的整体框架如图1所示:
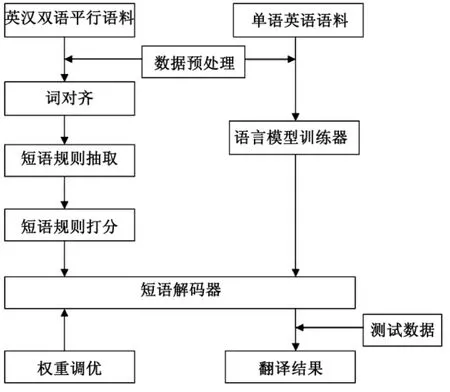
图1 《道德经》英译机器翻译系统的整体框架
在训练阶段,系统可以从训练数据中学习得到模型和模型参数,每个模块功能如下:
数据预处理模块:该模块主要是完成对训练数据的加工处理,包括分词、词性标注等。
词对齐模块:该模块可以为双语平行数据中的每一句对得到词对齐之后的结果,使得源语言词汇和目标语言词汇对应起来。
短语规则抽取模块:该模块用于从包含词对齐信息的双语平行语料中抽取出短语翻译规则。
短语规则打分模块:该模块用于对所抽取得到的规则进行概率估计和打分。
语言模型训练器模块:该模块用于从目标语言的单语语料中学习从而得到语言模型。
权重调优模块:该模块用于在数据集上对翻译模型特征权重向量进行调优。
解码阶段所包含的模块功能如下:
解码器模块:该模块主要功能是找出所有存在于搜索空间中的最佳目标语言译文,即完成测试数据的翻译,得到目标语言译文。
2.3 系统翻译过程流程
利用系统翻译得到目标语的过程主要包括:数据准备、训练翻译模型、训练N元语言模型、配置文件、权重调优、解码翻译和评价几个阶段。具体流程如图2所示:
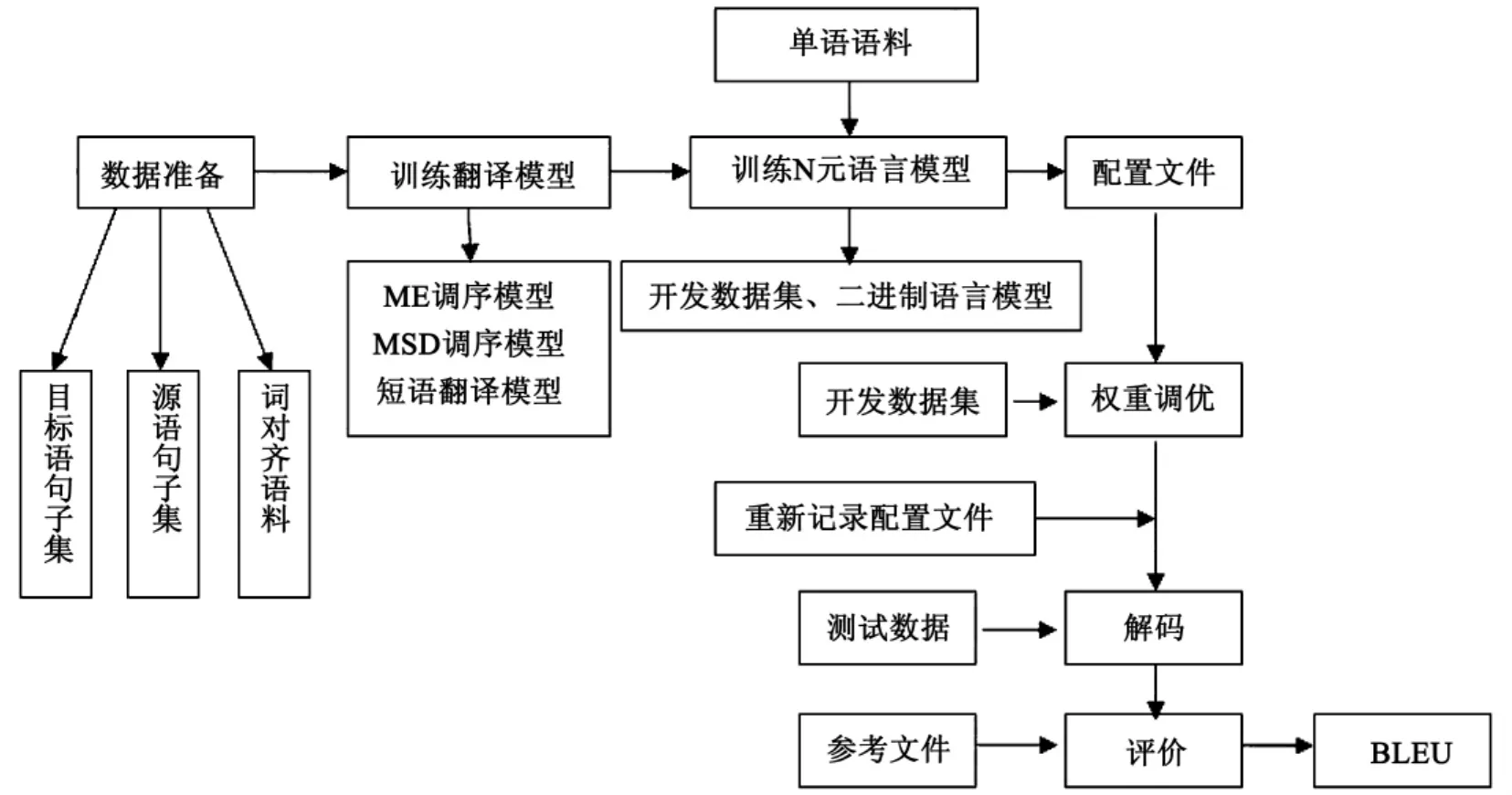
图2 《道德经》英译机器翻译系统过程流程
3.0 实验环节
在翻译过程中,主要工作是为系统提供训练和测试所需数据,包括目标语(英语)句子集、源语(汉语)句子集以及双语对齐的文件,此外还有测试数据和参考译文,然后调用系统的工具包进行训练翻译模型、权重调优、解码和评价等过程。
3.1 训练和测试数据
源语句子集:在对平行语料进行对齐之前,首先需要进行中文分词,系统中使用Stanford NLP自然语言处理小组开发的中文分词开源工具对文档进行处理,分词后的文件保持原文件名,同时产生原文件的备份文件。
目标语句子集:对于平行语料中的目标语句子集进行英文分词。
词对齐文件:为了获得该文件,主要是利用GIZA++进行汉语到英语、英语到汉语两个方向的训练,再对两个方向的对齐结果进行优化,GIZA++实现了IBM统计翻译模型。
测试数据:在该系统中,所使用的测试数据为《道德经》古汉语的分词结果。
参考译文:在该系统中,所使用的参考文件为林语堂的《道德经》英文译本。
3.2 训练《道德经》的翻译模型和N元语言模型
训练翻译模型:将分词后的双语语料进行短语抽取和调序,得到短语翻译模型以及ME和MSD调序模型。
N元语言模型:本次实验采用了3元文法语言建模。
3.3 权重调优
利用开发集和之前得到的配置文件进行权重调优,并将结果重新记录入配置文件。至此,基于短语的《道德经》机器翻译系统构建完毕。
3.4 评测
解码:利用配置文件对测试数据进行解码操作,即完成对《道德经》测试数据的翻译。
评价:得到双语评测的指标BLEU值,比较翻译结果的准确性。
4.0 实验结果及分析
4.1 实验数据
翻译模型的训练实验分两次进行。鉴于先秦时期的古汉语基本上是以单字词为基本词汇单位,实验1是将测试语料按字切分来进行《道德经》的翻译。实验2是将测试语料按分词切分(基于短语)进行《道德经》的翻译。训练数据采用《道德经》的道经部分的古文和林语堂翻译的《道德经》英文构建的英汉平行语料。考虑到《道德经》有道经和德经之分,本次实验主要采用道经的双语平行语料。考虑到古文的特点,翻译系统的输入输出文本文件采用UTF-8标准编码方式。为了评测《道德经》统计机器翻译系统,采用IBM公司提出的BLEU评测方法对系统进行评价。评价结果的BLEU值越高,翻译效果越好。
4.2 实验结果
1)实验1,以分字结果为测试语料进行的《道德经》的翻译(见图3):

图3 将测试语料分字进行《道德经》翻译测得BLEU值
2)实验2,以短语分词结果为测试语料进行的《道德经》的翻译(见图4):

图4 将测试语料短语分词进行《道德经》翻译测得BLEU值
4.3 实验结果分析
从BLEU值来看,以短语分词结果为测试语料的《道德经》的翻译结果明显比以分字结果为测试语料的《道德经》的翻译结果要好。由此可见,在相同规模的平行语料的前提下,分词结果对基于短语的机器翻译系统有一定的影响。而在构建机器翻译模型中,双语语料的构建、权重调优的开发集数据和作为参考标准的参考译文也都与切词密切相关,因此,更准确的古文切词将会大幅提高《道德经》机器翻译结果的准确率。
5.0 结语
本文是面向汉语(古籍)英译的机器翻译研究的初步探索,对于古汉语的词汇和语法的分析还有待于进一步深入研究,在语料训练和机器翻译技术等方面尚有较大的提升空间。
[1]Wilks,Y.Machine Translation:Its Scope and Limits[M].Berlin:Springer,2008.
[2]冯志伟.机器翻译研究[M].中国对外出版公司,2004.
[3]刘群.基于句法的统计机器翻译模型与方法[J].中文信息学报,2011,(6):63-71.
[4]王海峰.互联网机器翻译[J].中文信息学报,2011,(12):72-80.
[5]王爽,熊德兰,王晓霞.基于实例的古文机器翻译设计与实现[J].许昌学院学报,2009,(5):88-91.
[6]徐彬,郭红梅.计算机辅助翻译环境下的质量控制[J].山东外语教学,2012,(5):103-108.
[7]许磊.谷歌翻译凭啥跨越语言障碍[N].计算机世界,2011-03-28:016.
[8]银花,王斯日古楞,艳红.基于短语的蒙汉统计机器翻译系统的设计与实现[J].内蒙古师范大学学报(自然科学汉文版),2011,(1):91 -94.
An Exploration of Phrase-based SMT for English Translation of Tao Te Ching
YAO Zhen-jun1,ZHENG Xu-hong2,XU Peng-tao3,WANG Ji-sheng3
(1.Mobile Station for Post-doctoral Research of Foreign Language&Literature of Henan University,Kaifen 475001,China/ SIBC of Dongbei University of Finance,Dalian 116025,China;2.Computer Department of DUFL,Dalian 116002,China; 3.SMSE of Dongbei University of Finance,Dalian 116025,China)
With the existing English versions of Tao Te Ching as training sets,this research aims at exploring phrase-based SMT.By comparing the BLEU results of two experiments of word-for-word segmentation and phrasebased segmentation in the same source text,we find phrase-based SMT works better in English translation of Tao Te Ching.
machine translation;Chinese word segmentation;Tao Te Ching;old Chinese,English translation
TP391.2
A
1002-2643(2013)03-0109-04
2013-01-19
姚振军(1972-),男,黑龙江肇东人,博士后在站,副教授。研究方向:翻译学与计算机应用技术。
郑旭红(1965-),女,四川眉山人,副教授。研究方向:计算机应用技术。
徐鹏涛(1986-),男,山东烟台人,研究生。研究方向:计算机应用技术与电子商务。
王继升(1988-),男,辽宁朝阳人,研究生。研究方向:计算机应用技术与电子商务。
