ABC-KHM混合聚类算法
2013-06-01陆克中
陆克中
(池州学院 数学与计算机科学系,安徽 池州 247000)
聚类是指将物理或抽象对象的集合分组成为由类似的对象组成的多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。聚类是一种无监督的模式识别问题,目前已在商业、生物、地理、电子商务和因特网等领域得到了广泛的应用[1]。
在诸多的聚类方法中,基于中心的划分聚类方法得到了广泛应用,典型的代表是K-均值算法(K-means,KM)、模糊C-均值算法 (Fuzzy C-Means,FCM)和K-调和均值算法 (K-Harmonic means,KHM)[2]。KM聚类算法的优点是简单、快速,但是它对初始状态的选择比较敏感,且容易限于局部最优。FCM聚类算法是对硬划分的KM聚类算法的一种改进,扩展了隶属度的取值范围,具有较好的数据表达能力和聚类效果。但它也继承了KM算法固有的缺点。KHM聚类算法利用样本点与所有聚类中心距离的调和平均代替了KM算法中的样本点与聚类中心距离,从而引入了聚类中心对样本点的条件概率和每次迭代过程中样本点的动态加权,实际上起到了将“硬”聚类“软化”的作用[3]。与KM和FCM不同,KHM的聚类结果对初始状态的选择不太敏感,Zhang等的实验表明,KHM算法的性能优于KM和FCM算法[2]。但是KHM和KM,FCM聚类算法一样,使用基于梯度下降的寻优算法,致使对于样本点较多时,算法往往易于限于局部最优[4]。
为了克服基于中心的聚类算法易于限于局部最优的问题,当前人们已引入了很多种方法,特别是群智能优化算法近几年得到了广泛应用,并取得了较好的应用效果,如遗传算法、蚁群算法、粒子群优化算法等[4]。人工蜂群(artificial bee colony ABC)算法是学者Karaboga于2005年受蜜蜂采蜜智能行为的启发而提出的一种群智能优化算法[5]。该算法具有控制参数少,容易实现等特点,其性能可与其它群智能算法相媲美,适应于多变量、多峰值函数优化。鉴于ABC算法的良好优化性能,为此本文研究了基于ABC算法的KHM聚类算法,同时对算法进行了仿真实验分析。仿真结果表明,基于ABC算法的KHM混合聚类算法,优于单一的KHM聚类算法。
1 KHM聚类算法
KHM聚类算法是由Zhang等在1999年提出,同KM聚类算法类似,也是基于中心的迭代过程,区别是它采用所有样本点到每个聚类中心的调和均值的和作为目标函数。这里设定k为聚类个数,n为样本点个数,X={x1,x2,… ,xn}为样本数据集,C={c1,c2,…,ck}为聚类中心向量,U为隶属度矩阵,W为权重矩阵。KHM算法的目标函数定义为:样本数据xi与聚类中心向量cj的隶属度u(cj/xi)计算公式为
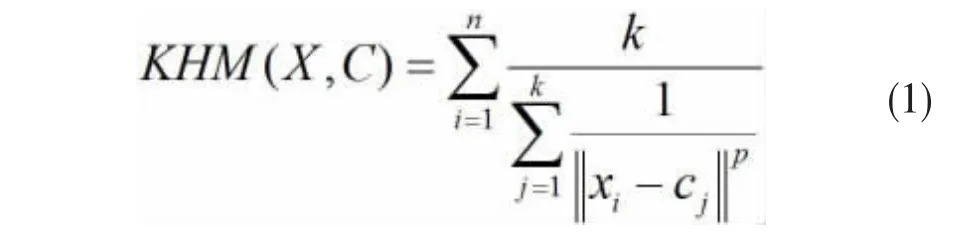

样本数据xi的权值函数w(xi)为

根据样本数据xi的隶属度u(cj/xi)和权值函数w(xi),聚类中心向量C的更新公式如下:
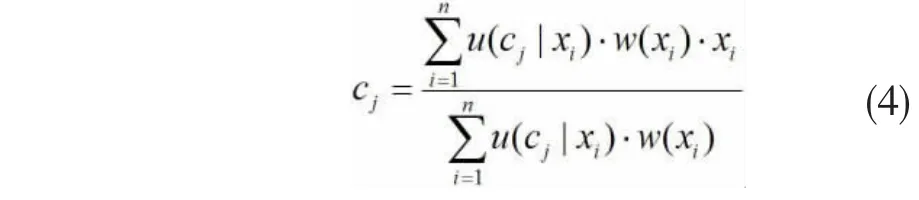
KHM算法根据初始值按照公式(4)不断迭代,使得式(1)的目标函数值不断减小直至稳定。
2 基于ABC的KHM聚类算法
2.1 ABC算法
受蜜蜂采蜜智能行为的启发,Karaboga于2005年提出了人工蜂群(artificial bee colony,ABC)算法模型[5]。ABC算法是一种较新的群体智能算法,具有控制参数比较少、易于实现等优点,并且不需要了解问题的特殊信息,只需要对问题进行优劣的比较,最终在群体中使全局最优值突现出来,具有很好的优化性能,适合用于变量函数优化问题[6]。
在ABC算法模型中,将人工蜂群分为三个部分:雇用蜂、观察蜂和侦察蜂,其中观察蜂和侦察蜂又统称为非雇用蜂[6]。雇用蜂和观察蜂用于蜜源的开采,侦察蜂则完全随机地而非经验地寻找新的蜜源,避免蜜源种类过少。首先由侦察蜂找到蜜源,之后雇用蜂和观察蜂对蜜源中的花蜜进行开采;经过不断开采之后,由于蜜源中的花蜜逐渐枯竭,一些雇佣蜂将转变成侦察蜂,再一次寻找新的蜜源。用ABC算法解决优化问题中,蜜源代表问题的一种可能解,而花蜜量则为对应解的质量,即适应度值。
ABC算法各个阶段表述如下:
(1)初始化阶段
在此阶段需确定蜂群规模SN、解空间的维数D、最大循环次数MCN、放弃准则limit等参数,并按照式(5)产生初始蜜源(即解)X。

其中li和ui分别表示参数xmi的上下限。
(2)雇用蜂阶段
雇用蜂m按照式(6)在其蜜源xm的邻域内产生一个新的蜜源vm,并检查新位置的花蜜量(即适应度值),若新位置的花蜜量比原来的好,则替换为新的位置。

其中vmi为新的蜜源,k和i都是随机选取的,且k≠m;φij为[-1,1]间的随机数。
(3)观察蜂阶段
雇用蜂在搜索完之后,将蜜源信息分享给观察蜂。观察蜂根据雇用蜂所找的蜜源的花蜜量,按概率Pm选择一只雇用蜂,并在雇用蜂所在蜜源附近进行邻域搜索,仍按照择优原则进行蜜源更新。Pm计算公式如下:

其中fitm(xm)为蜜源xm的适应度值,其计算公式如下:

式中fm(xm)是蜜源xm的目标函数值。
(4)侦察蜂阶段
如果雇用蜂在进行预先设定的limit次搜索之后仍不能找到更好的蜜源时,则该蜜源被放弃,并且此蜜源处的雇用蜂将转变成为侦查蜂,侦查蜂的蜜源信息由式(5)随机产生。
在上述的ABC算法中,雇用蜂在全局范围内相对独立的寻找蜜源,并与观察蜂共享自己蜜源信息;观察蜂根据分享到的蜜源信息,在局部范围内概率性地对蜜源作进一步开采;侦察蜂则随机搜索新的蜜源位置,此举有助于算法跳出局部最优。正是通过三者的共同作用,才使得ABC算法具有较强的全局搜索性能,而且收敛速度较快。
2.2 ABC-HKM混合聚类算法
KHM算法聚类过程就是根据初始值按照式(4)不断迭代,直到使得式(1)的目标函数值达到最小的过程。这一过程就是局部优化过程,致使KHM算法易于限于局部最优。ABC算法是一种随机优化算法,具有良好的全局搜索性能。为此,这里我们提出一种ABC-KHM混合聚类算法:在每次迭代过程中,利用人工蜂群算法寻找多个聚类中心点,再将每一个聚类中心点进行一次KHM聚类,两种算法交替进行,直到聚类结束。一方面KHM算法增强混合算法的局部搜索能力,并且加快了混合聚类算法的收敛速度;另一方面ABC算法则增强混合算法的全局搜索能力,二者相互补充,从而提升混合算法相对于单个算法的聚类效果。
给定数据样本 X={x1,x2,… ,xn},其中 xi(i=1,2,3,…,n)为 D 维向量,n 为样本数量;在 ABC算法中,每一个蜜蜂代表一个数据集的聚类中心向量集 C={c1,c2,…,ck},其中 ci(i=1,2,3,…,k)表示一个D维的聚类中心向量,k为聚类个数。ABC算法的目标函数为式(1)的KHM目标函数,将目标函数代入式(8),作为ABC算法的适应度函数。
ABC-KHM混合聚类算法步骤如下:
a)设置雇佣蜂、观察蜂数量,一般设雇佣蜂=观察蜂=蜂群规模(SN)/2,设置最大循环次数 MCN及放弃准则limit,设置类别数k。
b)蜂群初始化,随机产生SN/2个向量{c1,c2,…,ck}作为初始蜂群,并根据式(1)和(8)计算每只蜜蜂的适应度值。
c)雇用蜂m按照式(6)在其蜜源xm的邻域内搜索得到新的蜜源vm,当蜜源vm的适应度值优于记忆最优值时,则用vm替换xm;反之,保持xm不变。
d)观察蜂按照式 (7)的轮盘赌原则选择观察蜂,并对观察蜂进行邻域探索,仍采用贪婪准则,保存较优的解。
e)当雇用蜂在进行limit次搜索之后也没有找到更好的蜜源时,雇用蜂将放弃其记忆的蜜源信息,并转变成侦察蜂,其蜜源信息由式(5)随机产生。
f)将ABC算法得到的蜜源作为初始聚类中心,对数据进行一次KHM迭代,求得每一类新的聚类中心,仍依据保存较优解的原则,更新蜂群。
g)返回到c),直到满足最大循环次数。
h)输出最后的聚类中心,并计算其对应的目标函数值。
3 实验仿真与结果分析
3.1 数据集
为了比较ABC-KHM混合聚类算法的聚类效果,这里使用了5类测试数据集:2类人工数据集和3类经典化学数据集。3类化学数据集分别是Iris、Wine和Breast-cancer;2类人工数据集使用高斯分布随机产生,具体如下:
人工数据集1:数据集的聚类数k=3,每类样本数为50,各类的均值与方差分别是μ1=[3,0]、μ2=[0,3]、μ3=[1.5,2.5]和 λ1=[0.3,1]、λ2=[1,0.5]、λ3=[2,1]。
人工数据集2:数据集的聚类数k=6,每类样本数为25,各类的均值与方差分别是μ1=[3,0]、μ2=[0,3]、μ3=[1.5,2.5]、μ4=[0.2,0.1]、μ5=[1.2,0.8]、μ6=[0.1,1.1]和 λ1=[0.3,1]、λ2=[1,0.5]、λ3=[2,1]、λ4=[0.03,1]、λ5=[2,0.5]、λ6=[0.2,0.4]。
3.2 参数设置
仿真实验中,KHM和ABC-KHM聚类算法的运行次数均为200次,目标函数中参数p=2,ABCKHM算法中的蜂群规模SN=20,放弃准则limit=20,各个数据集的类别数k参见3.1数据集中的给定值。
3.3 结果与讨论
式(1)不仅用作所有算法的目标函数,而且也是聚类质量的评价标准。其值越小,聚类效果越好。表1列举了KHM和ABC-KHM算法的各自聚类结果。每种算法均被执行30次,其中Favg、Fbest、Fworst和Fstd分别表示聚类结果的平均值、最佳值、最差值和标准差。
从表1可以看出,两种算法目标函数的标准差Fstd相对而言都比较小,说明改进的ABC-KHM聚类算法继承了KHM算法对初始值不太敏感的优点。通过与KHM算法在Favg、Fbest和Fworst三个方面进行比较,整体而言,ABC-KHM聚类算法的值在三个方面均明显比KHM聚类算法的结果来得小,说明ABC-KHM聚类算法具有较好的聚类效果,一定程度上克服了KHM算法的局部收敛的缺点。

表1 KHM和ABC-KHM聚类效果比较
图1演示了两种算法对人工数据1的聚类过程。在图1中,KHM算法聚类很快,但是易于早熟收敛,在10次迭代后就使目标函数从509降到381.02,然后定在381.02上,不能进一步收敛;ABC-KHM混合聚类算法收敛速度相对较慢,但是也能在40次迭代之后达到收敛,且最终目标函数值比KHM聚类算法明显要好。
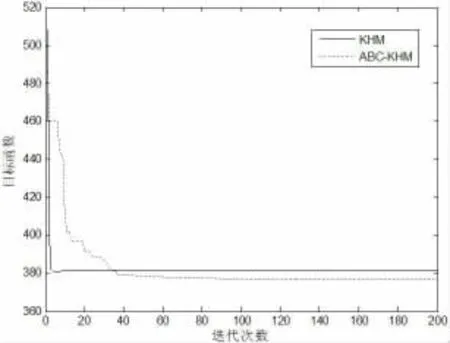
图1 人工数据集1的算法收敛图
4 结论
KHM聚类算法具有对初始值不敏感的特点,但它终究是基于中心的迭代算法,难以摆脱早熟收敛的问题,为此,本文提出结合KHM和ABC的混合聚类算法。在混合算法中,聚类行为可以分为两个阶段:全局搜索的ABC聚类阶段和局部求精的KHM聚类阶段。通过仿真实验,并与KHM聚类算法进行了比较,结果表明:ABC-KHM混合聚类算法,不仅对聚类初始值不敏感,而且具有良好的全局聚类效果,是一个不错的聚类算法。
[1]聚类分析[EB/OL].[2013-03-10].http://baike.baidu.com/view/903740.htm.
[2]B Zhang,M Hsu,U Dayal, “K-Harmonic Means” [R].International Workshop on Temporal,Spatial and Spatio Temporal Data Mining,TSDM2000,Lyon,France,2000.
[3]G Hammerly,C Elkan,“Alternatives to the k-means algorithm that find better clusterings”[C]//The 11th International Conference on Information and Knowledge and Management,2002:600-607.
[4]K.Z.Lu,K.N.Fang,G.Q.Xie.A Hybrid Quantum-behaved Particle Swarm Optimization Algorithm for Clustering Analysis[C]//Fifth International Conference on Fuzzy Systems and Knowledge Discovery,Jinan,2010:21-25.
[5]D.Karaboga.An idea based on honey bee swarm for numerical optimization [R].Technical Report TR06,Computer Engineering Department,Engineering Faculty,Erciyes University,2005.
[6]D.Karaboga.Artificial Bee Colony Algorithm[J/OL].(2012-10-15).Scholarpedia,http://www.scholarpedia.org/article/Artificial_bee_colony_algorithm.
