Web挖掘的关联规则优化算法
2013-05-24曾姣艳
曾姣艳
(福州软件职业技术学院计算机系,福建福州350003)
Web挖掘的关联规则优化算法
曾姣艳
(福州软件职业技术学院计算机系,福建福州350003)
对Apriori算法进行优化,提出了一种Z_Apriori算法。该算法在首次产生频繁项集时,扫描数据库并通过二进制编码串记录每个项目在事务里是否出现过,在每次进行计算迭代过程中无需再对数据库进行扫描,避免了对数据库的重复扫描,在系统性能和效率上较经典的Apriori算法有一定的改善。
关联规则;个性化推荐服务;频繁项集
Internet技术近年来正以难以想象的速度爆炸式发展,面对“信息超载”的问题,如何从海量的信息中分析和研究客户的喜好和浏览习惯,有针对性地为不同客户群提供他们所需要或感兴趣的信息资源,已成为一项迫切而重要的课题。
Web日志挖掘属于Web挖掘的一个研究方向,它基于站点服务器的日志文件进行数据挖掘,找出其中的特点和规律,分析客户在对系统进行浏览和访问过程中的行为特性,推测出用户的兴趣偏好,根据这些特点改进系统的组织和结构,制定商品销售方案,从而提升公司的服务标准[1]。因此,在电子商务系统中使用日志挖掘和个性化服务等技术是非常迫切需要也是必然趋势。
1 关联规则经典Apriori算法
1.1 算法的设计思想
关联规则挖掘实现从庞大的数据集中发现它们之间的关联。Apriori算法作为关联规则的经典算法,其主要思想是在大量的数据集中发现频繁项集,再由频繁项集产生强关联规则。该算法中涉及到支持度和置信度两个重要指标[2]。
Aprior算法的实现分成两步:第一步是进行迭代,发现数据集中所有频繁项目集,要求计算得到的支持度不小于最小支持度;第二步是根据频繁项目集生成强关联规则并计算置信度,要求计算得到的置信度不小于最小置信度[3]。
1.2 算法示例
表1是一个简单的事务数据库D,该数据库D里共有4个事务,包含项目{A}、{B}、{C}、{D}和{E},设定的最小支持度阀值s=40%,用户设定的最小置信度阀值c=80%。
频繁项目集挖掘过程:
(1)第一次迭代,产生1-频繁项目集。分三个阶段计算
生成阶段:产生1-候选项目集C1。
计算阶段:求每个候选集在事务中出现的次数并计算支持度。
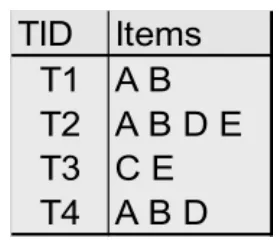
表1 事务数据库D

选择阶段:选择支持度s≥40%的项目,生成1-频繁项目集L1。

(2)第二次迭代,2-产生频繁项目集。
产生阶段:利用L1*L1生成候选项目集。“*”运算定义为:Lk*Lk={X∪Y,其中X,Y∈Lk,|X∩Y|=k+1}。设C2为在第二次迭代中产生的2-候选项目集。|C2|=|L1|· (|L1|-1)/2。在此例中为:4·3/2=6。因此,产生6项2-候选项目集C2。
计算阶段:求每个候选项目集在事务中出现的次数并计算支持度。
选择阶段:选择支持度s≥40%的2-频繁项目集L2。



(3)第三次次迭代,产生3-频繁项目集。
产生阶段:使用L2*L2生成候选项目集。计算产生1项3-候选项目集C3。
计算阶段:求每个候选集在事务中出现的次数并计算支持度。
选择阶段:选择支持度s≥40%的3-频繁项目集L3,并根据Apriori算法的性质进行剪枝:所有频繁项目集的子集都是频繁项目集,项集{A,B,D}的所有子集都是L2的元素,故保留。



由于本例的L3不能产生4-候选项目集,因此迭代停止。
由频繁项目集产生关联规则:
第二阶段的工作是根据第一阶段计算的结果,生成关联规则。如果规则为{x1,x2,x3}→x4,那么项集{x1,x2,x3,x4}和{x1,x2,x3}都必须是频繁的。然后,规则置信度c=P({x4}|{x1,x2,x3})=s(x1,x2,x3,x4)/s(x1,x2,x3)。置信度c不小于最小置信度阀值的规则就是强关联规则[4]。
由上面的例子,得到一个频繁集{A,B,D},非空真子集有{A},{B},{D},{A,B},{A,D},{B,D}。结果关联规则如下。

根据设定的最小置信度阀值c=80%,只有第三、第三和第六规则符合可以输出,因为这些都是强规则。
1.3 算法的缺点
对Apriori算法进行研究发现,在计算支持度的过程中,进行每一次迭代发现频繁项集都要重新扫描整个事务数据库,因此若要进行n次迭代,则需要重复扫描数据库n次[5]。若碰到事务数据库非常庞大或迭代次数非常多时,则该算法运行要花费大量的时间,导致可能不能满足实际要求甚至难以进行。
2 优化的Z_Apriori算法
2.1 算法的基本思想
针对Apriori算法存在的缺陷,提出了一种优化算法Z_Apriori算法。对于Apriori算法在每次计算频繁项目集时都需要对数据库重复进行扫描的问题进行了优化,Z_Apriori算法通过二进制编码统计每个项目在事务中是否出现,因此只需要扫描一次数据库,大大提高了算法的执行效率。
2.2 算法示例
表2为一个简单的事务数据库D,共有8个事务,数据库D中包含的项目{A}、{B}、{C}、{D}、{E}和{F},设定最小支持度s= 50%。
Z_Apriori算法频繁集挖掘过程:
(1)第1次迭代,生成1-候选项目集,选择支持度s≥50%的项目,生成1-频繁项目集L1。对事务数据库进行扫描,用一串二进制编码依次记录每个项目在事务中是否有出现,出现用1表示,没出现用0表示。

表2 事务数据库D

(2)第2次迭代,产生2-候选项目集,选择支持度s≥50%的项目集,生成2-频繁项目集L2。将使用L*L1产生候选项集,根据第1次迭代计算得到的二进制编码计算每个新项目在事务中是否出现。

(3)第3次迭代,产生3-候选项目集,选择支持度s≥50%的项目,生成3-频繁项目集L3。

由于本例的L3无法生成4-候选项目集,因此算法迭代结束。
3 两种算法性能比较
使用Microsoft Visual Studio 2005中的C#分别实现了经典Apriori算法和改进的Z_Apriori算法,利用Microsoft SQL Server 2005中的Transaction数据集进行测试,证实了Z_Apriori算法节省了系统运行时间[6]。
实验1:项目数items=25,事务数目TID=5000,计算在不同支持度情况下Apriori算法和改进的Z_Apriori算法的运行时间,实验结果如图1所示。由图1可知,在相同的项目数和事务数目情况下,随着最小支持度阀值的增加,两种算法的运行时间都随着变少。但在同一最小支持度下,Z_Apriori算法的运行时间一直小于Apriori算法的运行时间。
实验2:交易事务表项目数items=25,最小支持度s=40%,考察不同事务数量下两种算法的运行时间。实验结果如图2所示:由图2可知,在相同的项目数和最小支持度情况下,随着事务数目的增加,两种算法的运行时间都随着增加。但在同一事务数目下,Z_Apriori算法的运行时间一直小于Apriori算法的运行时间。

图1 不同支持度下两种算法的运行时间比较

图2 不同事务数量下两种算法的运行时间比较
4 结语
分析和研究了关联规则的经典算法Apriori算法,并基于该算法提出了一种改进算法Z_Apriori算法。跟Apriori算法相比较,Z_Apriori算法中在整个计算求解的过程中只需要对事务数据库扫描一次。只有在第一次迭代生成1-频繁项集时要对数据库进行扫描,通过一串二进制编码来统计每个项目是否在事务里出现过。每次迭代产生频繁项集的过程中,只需根据二进制编码计算项目集的支持度,不用像APriori算法要对事务数据库进行重复扫描,因此减少了系统运行花费的时间,很好地对Apriori算法不足的地方进行了优化。
[1]李晓艳.Web使用挖掘在电子商务个性化服务中的应用[J].科技创业月刊,2008,21(5):122-124.
[2]杨风召,白慧.电子商务推荐系统的算法与模型分析[J].情报杂志,2007,26(12):40-42.
[3]陈美荣,杨莉.基于电子商务网站的WEB内容挖掘[J].商场现代化,2008(5):149-150.
[4]曹丽君,刘蹦印.基于电子商务的数据挖掘探究[J].商场现代化,2008(5):157-157.
[5]许国忠.基于可变阶模型的Web访问模式挖掘算法[J].三明学院学报,2008,25(2):204-207.
[6]姜美玉,卢利平,宜建军.基于WEB日志挖掘的网站个性化服务研究[J].图书馆学刊,2006,28(5):137-138.
An Optimization Association Rules Algorithm of Web Mining
ZENG Jiao-yan
(Department of Computer,Fuzhou Software Vocational Technology College,Fuzhou 350003,China)
Z_Apriori algorithm,which based on optimization of Apriori algorithm,is put forward in this paper.When generating frequent item sets for the first time,the algorithm can scan the database and record which project appears in the transaction by the binary code string and it no longer need to scan the database in each calculation and iteration process, which avoids scanning the database repeatedly.Compared with Apriori algorithm,it has a certain improvement about the performance and efficiency of the system.
association rules;personalized recommendation service;frequent item set
TP301.6
A
1673-4343(2013)02-0027-05
2012-11-26
曾姣艳,女,湖南郴州人,助教。研究方向:计算机应用。
