基于视频编解码的可重构处理器存储系统设计
2013-05-12王明江王新安
戴 鹏,王明江,王新安
1)哈尔滨工业大学深圳研究生院,深圳 518055;2)北京大学深圳研究生院,深圳 518055
基于视频编解码的可重构处理器存储系统设计
戴 鹏1,王明江1,王新安2
1)哈尔滨工业大学深圳研究生院,深圳 518055;2)北京大学深圳研究生院,深圳 518055
针对可重构视频编解码处理器ReMAP-2在高清视频编解码应用中对大规模数据吞吐率的需求,提出一种由全双工的帧缓存器及直接内存存取 (direct memory access,DMA)组成的高速存储系统.其中帧缓存器由2个4 kbyte存储器构成,每个存储器分为16个存储块,采用二维地址编码,通过数据排列开关对像素数据的重排序,可满足视频编解码算法对子块像素数据快速读取的需求.仿真实验表明,该存储系统可满足可重构处理器ReMAP-2面向高清视频编解码的高性能处理应用需求
集成电路技术;可重构;处理器;数字信号处理;离散余弦变换;存储器;多媒体处理;视频编解码
随着集成电路制造工艺及电路设计水平的不断进步,视频编解码技术已广泛应用于移动终端、互联网及视频监控等领域.视频编解码具有3大特点[1],包括:①媒体像素间的操作独立,块间像素处理存在较大的并行性;②全局数据少;③计算密集.这意味着视频编解码处理的计算量大,复杂度高.
可重构处理器[2-7]通过多个处理单元的并行处理可达到强大的处理性能,同时兼顾应用的灵活性,逐渐成为视频编解码领域的研究热点.Re-MAP[8-12]是一款针对媒体处理的可重构处理器.本研究针对改进的ReMAP-2结构,基于ReMAP原型验证芯片,设计了一种高速存储系统,可同时与片外总线及可重构存储器进行数据交互,优化了视频编码算法中的存储器结构,提高了数据吞吐率,大幅缩短了可重构处理器访问存储的时间,提升了可重构处理器的整体性能.
1 ReMAP-2系统结构
如图1,ReMAP-2系统结构由可重构处理器、存储系统及精简指令集处理器 (reduced instruction set computer,RISC)处理器组成.可重构处理器完成大规模计算密集型数据运算;存储系统用来缓存可重构处理器待处理的图像数据及与系统外总线进行数据交互;RISC负责加载可重构处理器的程序和数据,以及视频编解码算法中控制程序段的运行.上述3部分硬件结构分别执行视频编解码算法中计算、存储与控制3部分不同类型的程序段.
可重构处理器由9个处理单元 (reDSP)级联而成.每个reDSP处理单元由1个可重构控制单元(reconfigurable control unit,RCU)、8个 ALU和1个互连单元reRouter构成.ALU可完成16 bit的算术逻辑运算,第9个处理单元 (reDSP)中每个ALU还包含单独的乘法累加器.reRouter完成ALU单元间的数据通信,RCU为reDSP的控制单元,向reDSP中的ALU和互连单元发送配置信息流,配置处理单元运算操作和数据交互.可重构处理器还包含用来加载配置信息流的配置接口,以及ALU阵列与片外存储收发数据的数据接口.其中,数据接口为2级深度的数据缓冲器 (infifo和outfifo),可在1个周期内向ALU阵列输送16个像素数据,并通过内部数据总线发送至ALU的输入端口.

图1 ReMAP-2系统结构图Fig.1 The system architecture of ReMAP-2
2 ReMAP-2存储系统设计
ReMAP-2的存储系统主要由帧缓存器和直接内存存取 (direct memory access,DMA)组成.帧缓存器主要用于图像像素数据存放,并根据视频编解码算法对图像数据排序再送入到可重构处理器中实现并行计算;DMA用于ReMAP-2与系统片外总线进行数据交互.本研究着重介绍帧缓存器结构设计,DMA采用通用的硬件结构.
ReMAP-2的帧缓存器由存储单元、地址产生器、数据排列开关和输入输出数据缓冲器组成.RISC向地址产生器发送图像数据地址,帧缓存器通过地址产生器管理数据排列开关将从存储单元中取得的数据以一定的顺序送入可重构处理器中,完成运算操作.
由于高清视频中每帧像素都很大,将数据帧全部数据存于帧缓存器中显然不现实,可采用片外动态随机存取存储器 (dynamic random access memory,DRAM)实现.帧缓存器主要用来存放当前宏块参考窗和中间计算结果,其设计考虑以下问题:
1)帧缓存器的大小.帧缓存器存放的数据不宜过多,否则将增加芯片面积;而太小会导致频繁访问外部存储器,占用总线带宽.
2)因ReMAP-2有8路并行计算单元,帧缓存器至少需同时提供16笔数据以满足阵列的处理单元需求,因此需考虑帧缓存器的大存储带宽设计.
3)运动估计等算法在随着搜索窗移动时需能从帧缓存器的任意地址取出连续数据.因此需有专门的排序模块来完成帧缓存器的数据排序.
4)片外总线和ReMAP-2会同时对帧缓存器提出访存请求,将造成一方等待帧缓存器空闲的情况,带来计算性能的损失.
本研究设计了一种全双工的帧缓存器.帧缓存器由2块存储空间组成,可分时向ReMAP-2提供操作数,从而隐藏帧缓存器与片外数据交互的存取时间.帧缓存器采用2个4 kbyte的双端口存储器,共分为16个存储块,每个存储块为256 byte,可在每周期内向ReMAP-2提供16个16 bit数据或32个8 bit数据.帧缓存器为运动估计开辟了专门的32×32参考像素的存储空间,其他存储空间用来满足帧内预测和环内算法等数据存储的需求.帧缓存器采用二维地址编码,每个存储块中的地址含x方向和y方向信息.如图2,宏块中同一个子块内像素处于不同存储块的相同位置,如bank(0,0)存储子块像素左上角的像素,bank(3,0)存储子块像素左下角的像素,依此类推.宏块中每个子块中相同位置的像素处于帧缓存器的同一个存储块中.

图2 宏块像素在存储器中存放位置的映射关系Fig.2 The relationship between macro-block pixels and memory
在视频编解码的运动估计算法中,搜索窗是以当前宏块位置为中心建立的,并随搜索窗的移动在其相邻范围内选择宏块像素.连续搜索窗大部分像素是重叠的.如图3,本研究采用循环存储方法,在搜索完一个运动向量后,由地址产生器产生新的起点位置,并重排数据,从而最大程度复用了上一个搜索窗的数据,避免总线重复读取搜索窗的大部分数据,节省了总线带宽.

图3 采用循环存储法复用搜索窗的像素数据Fig.3 The search window pixel data reuse by recycling memory method
本研究在帧缓存器中针对搜索窗开辟了4个宏块像素的存储空间.设某帧图像中任意点的像素坐标为 (xpxl,ypxl),则其在帧缓存器的位置为{ypxl[4∶2],xpxl[4∶2],ypxl[1∶0],xpxl[1∶0]}.其中,ypxl[1∶0]为帧缓存器中16个存储块的y方向地址,xpxl[1∶0]为帧缓存器中16个存储块的x方向地址,通过这两个参数选择对应的存储块,再由ypxl[4∶2]和 xpxl[4∶2]选择该像素在存储块内的存储空间.通过转换,可将图像帧中任意像素与帧缓存器的存储地址映射起来.当读取任一4×4子块像素时,由RISC处理器给出4×4子块的左上角像素地址,即可通过帧缓存器的地址产生器按式(1)和式(2)将子块像素存放在各存储块的地址算出.设左上角地址为 (y,x,ybank,xbank),其在存储块(i,j)的地址为
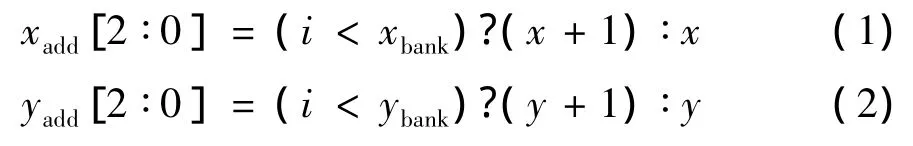
地址转换后即可读取一帧图像中任意一个子块中的像素数据.ReMAP-2中计算单元对于子块数据的处理有排序要求,如计算单元阵列依次处理子块像素(1,1),(1,2),…,(4,3),(4,4),根据算法需求可一次完成最多8个像素的并行计算.多数情况下,采用这种地址转换方法从16个存储块中取出搜索窗中的4×4子块数据对ReMAP-2的计算单元阵列来说有可能是乱序的.如图4,在获取虚线框所示的子块数据时,根据这种对应关系,从帧缓存器的首个存储块中取出的是虚线框内子块右下角的像素数据(4,4),从帧缓存器的第2个存储块中取出的是虚线框内子块左下角的像素数据(4,1),同理接下来分别从剩余14个存储块中依次取出的像素数据依次是(4,2)、 (4,3)、 (1,4)、(1,1)、(1,2)、(1,3)、(2,4)、(2,1)、(2,2)、(2,3)、 (3,4)、 (3,1)、 (3,2)、(3,3).因此,从帧缓存器中16个存储块中取出4×4子块数据后,需进行重排序以满足子块数据来计算单元阵列处理的矩阵顺序 (1,1)(1,2),…,(4,3),(4,4)出现在可重构处理器的输入数据总线上.为此,本研究专门设计了用于子块数据重排序的数据排列开关 (图5),它包含2层桶形移位器,参数xbank和ybank为左上角像素地址的低4 bit作为移位器的移位参数,可使从帧缓存器16个存储块中取出的数据以算法需要的数据重排列后再送入可重构处理器,从而大幅提高存储效率,提升可重构处理器的整体效能.

图4 帧缓存器读取子块数据时出现数据乱序排列的情况Fig.4 The data disorder in sub-block data access in frame buffer
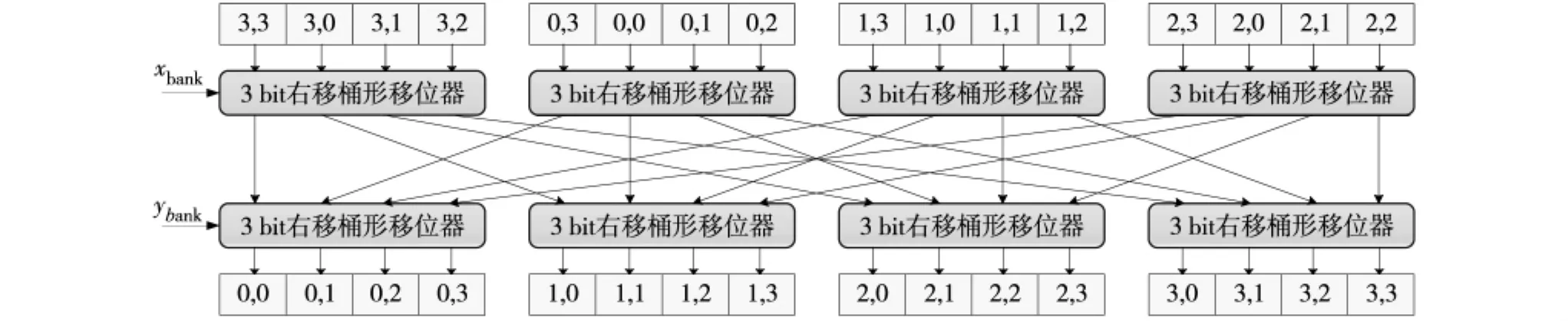
图5 数据排列开关硬件结构Fig.5 The architecture of data re-arrangement switch
3 ReMAP-2存储系统性能验证
本研究构建了ReMAP-2的仿真平台ReSim[13],用于其功能及性能的建模仿真,如图6.
3.1 利用ReSim仿真器的存储系统参数确定
通过对视频编解码中残差、DCT及量化算法运行时的可重构处理器整体执行性能,在几种不同存储块结构和存储带宽的方案下进行性能仿真,可评估整体执行结果 (图7).由图7可见,量化算法对存储块的带宽不敏感,DCT对存储器的带宽的敏感度较高.本研究根据仿真结果最终确定了16个byte带宽的双端口帧缓存器的存储块设计方案.
3.2 利用ReSim仿真器的存储系统性能仿真

图6 ReMAP-2图形调试界面Fig.6 The GUI of ReMAP-2 simulator

图7 ReMAP-2帧缓存器采用不同存储结构和存储带宽的计算性能比较Fig.7 The performance analysis for different memory architecture and bandwidth of frame buffer in ReMAP-2
ReSim既可用于仿真确定帧缓存器的系统参数,又可用于整个ReMAP-2的存储系统性能仿真.本研究完成了 H.264视频解码中1/2亮度插值、1/4亮度插值、1/8色度插值、残差、DCT和量化等H.264编码算法在ReMAP-2上的映射,采用6种算法处理1个宏块像素的计算性能如表1.仿真结果表明,ReMAP-2对这些视频编解码算法有较大幅度的性能加速[10,14].由于ReMAP-2的存储系统拥有1周期提供16个数据的存储带宽,所以可重构处理器获取1个宏块的数据的全部访问时间为16或32个周期.又因可重构处理器的流处理特性,大部分存储访问时间被隐于流处理执行过程,对外显式的访问时间仅为1~2个周期,所以存储访问效率较高.
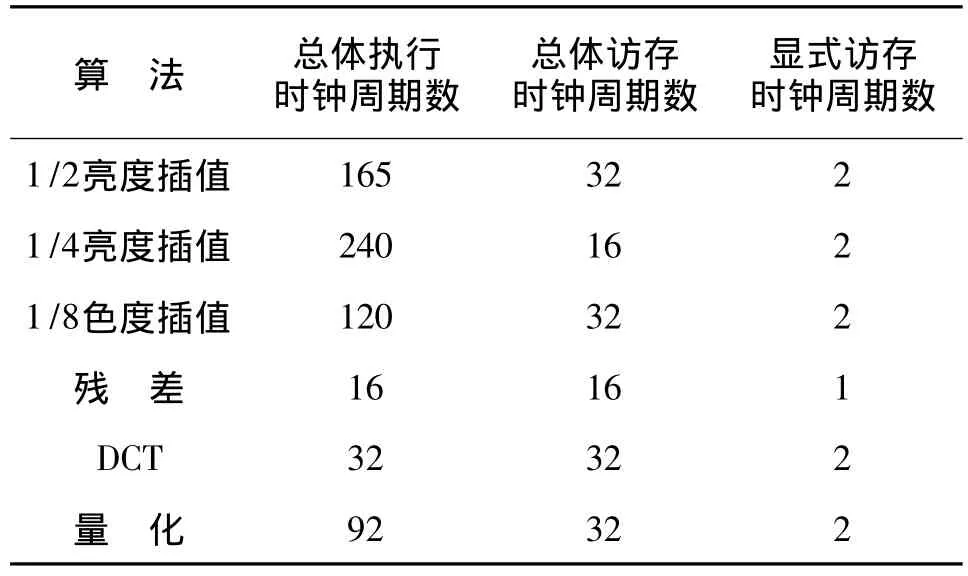
表1 H.264算法在ReSim仿真的性能列表Table 1 Performance analysis for H.264 algorithm in ReSim
表2和表3分别为SAD算法及1/2亮度插值算法在ReMAP-2与其他处理器结构的映射性能比较.

表2 SAD算法处理性能比较Table 2 Performance analysis for SAD algorithm

表3 4×4子块1/2亮度插值算法处理性能比较Table 3 Performance analysis of 1/2 pixel luma interpolation for 4×4 sub-block
H.264广泛使用的匹配准则是绝对误差和(sum of absolute difference,SAD)准则,即

其中,C(i,j)为当前像素;R(x+i,y+j)为参考像素.SAD算法主要包含减法、取绝对值和累加等操作.由于视频数据中1个宏块有16×16个像素,每计算1次SAD值需计算256个像素的绝对误差,且256个像素都采用相同流程,数据并行性强.算法映射如图8.

图8 SAD算法在ReMAP-2上的映射Fig.8 SAD algorithm mapping on ReMAP-2
由于帧缓存器存储带宽为128 bit,可支持16个像素数据同时输入可重构处理器,因此加载完1个宏块像素需16个周期.加载完毕后,每周期从帧缓存器中取出16个参考宏块像素,与ALU单元准备好的对应宏块数据进行相减并取绝对值,用两行ALU单元完成,图8圆圈表示1个ALU单元.完成16个数据的相减及绝对值运算共需要4行ALU并行操作完成.第5行ALU单元完成累加操作.由于整个算法计算完全在ALU阵列中展开,因此每周期可以完成16个像素的计算.
文献[3]和[4]采用了与本研究可重构处理器ReMAP-2同样数目的8×8个处理单元阵列.其中,文献[3]的帧缓存器为双存储块的128×8 byte的存储结构,提供128 bit的存储带宽.文献[4]的存储带宽为256 bit.由于本文帧缓存器实现了专门针对子块像素的数据排列开关硬件模块,在帧缓存器取4×4的子块数据时不需要在处理单元阵列对数据进行重排序,节省了处理单元阵列中的计算时间,提升了整体处理效率.
4×4子块的SAD算法在ReMAP-2上映射性能为23周期,每周期可处理16个像素点的数据,因此完成16×16子块的SAD共需39周期.文献[3]和[4]完成4×4子块运算各需48和32周期.本研究的处理性能较文献[3]和[4]分别提升了128.6%和52%;而TMS320C64x[15]因处理器不支持高度并行计算,处理16×16的宏块需时884周期.
1/2插值需周围水平或垂直方向的6个像素.以水平插值为例,图9中像素b的计算公式为


图9 1/2亮度插值和1/4亮度插值像素分布Fig.9 1/2 luma interpolation and 1/4 interpolation pixel distribution
图10以水平插值为例,1个1/2插值像素的计算通过可重构处理器中8个ALU以流水方式实现.由于帧缓存器每周期可提供16个像素数据,8×8的ALU阵列每周期最多可插值8个像素.插值时,通过帧缓存器的数据排列开关排序后将搜索窗左端4×8像素块读入ALU的本地寄存器,共2周期完成.其中,Ashl为相加左移;Acshr为相加右移.
ReMAP-2映射时采用5级流水结构,每级流水复杂度为1个加法+1个移位,完成4×4子块共需21周期;文献[17]中1个像素点运算采用了6级硬件流水形式,流水级中硬件复杂度为1个乘法,完成4×4子块的运算需12周期;文献[18]采用2级流水形式完成1个像素点计算,硬件复杂度最高为2个加法和1个移位的组合,完成4×4子块的运算需14周期.考虑到文献[17]和[18]每级计算流水结构的硬件复杂度都较本研究高,本研究结构可运行在较高的时钟频率上,处理性能接近ASIC.

图10 1/2亮度插值在ReMAP-2中的映射Fig.10 1/2 interpolation algorithm mapping on ReMAP-2
结 语
本研究设计了一种适用于视频编解码的可重构处理器存储系统,由全双工的帧缓存器和DMA组成.帧缓存器的每个存储空间由16个存储块组成,采用二维地址编码,通过数据排列开关可快速有效地进行视频子块像素存取,通过H.264解码算法在可重构处理器中的映射仿真表明,本研究设计的帧缓存器结构可满足可重构处理器ReMAP-2面向高清视频编解码的高性能处理应用需求,算法映射实现性能较同类可重构处理器有较大提升.
/References:
[1] Khailany B,Dally W J,Kapasi U J,et al.Imagine media processing with streams[J].IEEE Micro,2001,21(2):35-46.
[2]Pham P,Mau P,Kim J,et al.An on-chip network fabric supporting coarse-grained processor array[J].IEEE transaction on Very Large Scale Integration(VLSI)Systems,2012,21(1):178-182.
[3]Baumgarte V,Ehlers G,May F,et al.PACT XPP:a self-reconfigurable data processing architecture[J].The Journal of Supercomputing,2003,26(2):167-184.
[4]Singh H,Lee M H,Lu G,et al.MorphoSys:an integrated reconfigruable system for data-parallel and computation-intensive applications[J].IEEE Transactions on Computers,2000,49(5):465-481.
[5]Lattard D,Beigne E,Bernard C,et al.A telecom baseband circuit based on an asynchronous network-on-chip[C]//IEEE International Solid-State Circuits Conference,Digest of Technical Papers.San Francisco(USA):IEEE Press,2007:258-601.
[6]Vangal S,Howard J,Ruhl G,et al.An 80-tile 1.28 TFLPS network on-chip in 65 nm CMOS[C]//IEEE International Solid-State Circuits Conference,Digest of Technical Papers. SanFrancisco(USA):IEEE Press,2007:98-589.
[7]Wentzlaff D,Griffin P,Hoffmann H,et al.On-chip interconnection architecture of the tile processor[J].IEEE Micro,2007,27(5):15-31.
[8]Dai Peng,Wang Xin'an,Zhang Xing,et al.A high power efficiency reconfigurable processor for multimedia processing[C]//IEEE 8th International Conference on ASIC.Changsha(China):IEEE Press,2009:67-70.
[9]Dai Peng,Wang Xin'an,Zhang Xing.A novel reconfigurable operator based IC design methodology for multimedia processing[C]//2009 IEEE Region 10 Conference(TENCON 2009).Singapore:IEEE Press,2009:1-5.
[10]Dai Peng,Yong Shanshan,Wang Xin'an,et al.Design of reconfigurable processor ReMAP for video codec [J].Acta Scicentiarum Naturalum Universitis Pekinesis,2011,47(3):418-426.(in Chinese)
戴 鹏,雍珊珊,王新安,等.可重构视频编解码处理器ReMAP设计 [J].北京大学学报自然科学版,2011,47(3):418-426.
[11]Dai Peng,Wang Xin'an,Zhang Xing.Implementation of H.264 algorithm on reconfigurable processor[C]//Asia Pacific Conference on Postgraduate Research in Microelectronics& Electronics(PrimeAsia 2009).Shanghai(China):IEEE Press,2009:237-240.
[12]Wang xin'an,Ye Zhaohua,Dai Peng,et al.ReMAP:A reconfigurable array DSP architecture[J].Journal of Shenzhen University Science and Engineering,2010,27(1):16-20.(in Chinese)
王新安,叶兆华,戴 鹏,等.可重构阵列DSP结构ReMAP[J].深圳大学学报理工版,2010,27(1):16-20.
[13] Dai Peng,Wei Lai,Xin Lingxuan,et al.ReSim:a simulator platform for reconfigurable processor[J].Acta Scicentiarum Naturalum Universitis Pekinesis,2011,47(2):231-237.(in Chinese)
戴 鹏,魏 来,辛灵轩,等.ReSim:一个面向可重构处理器的仿真平台[J].北京大学学报自然科学版,2011,47(2):231-237.
[14]Zhang Wenliang,Yong Shanshan,Dai Peng,et al.Implementation of FME on reconfigurable processor ReMAP[J].Microelectronics,2011,41(1):124-127.(in Chinese)
张文良,雍珊珊,戴 鹏,等.小数运动估计在可重构处理器ReMAP的映射实现[J].微电子学,2011,41(1):124-127.
[15]Texas Instruments Incorporated.TMS320DM6446 digital media system-on-chip [EB/OL].[2010-03-27].http://focus.ti.com/docs/prod/folders/print/tms320dm6446.html.
[16]Chatterjee S K,Chakrabarti I.A high performance VLSI architecture for fast two-step search algorithm for sub-pixel motion estimation[C]//International Multimedia,Signal Processing and Communication Technologies(IMPACT'09).Aligarh(India):IEEE Press,2009:205-208.
[17]Lu L,McCanny J V,Sezer S.Subpixel interpolation architecture for multistandard video motion estimation [J].IEEE Transactions on Circuits and Systems for Video Technology,2009,19(12):1897-1901.
[18]Yalcin S,Hamzaoglu I.A high performance hardware architecture for half-pixel accurate H.264 motion estimation[C]//International Conference on Very Large Scale Integration(IFIP).Nice(France):IEEE Press,2006:63-67.
2012-02-19;Revised:2013-01-09;
2013-02-25
Design of reconfigurable processor memory system for video codec
Dai Peng1,Wang Mingjiang1†,and Wang Xin'an2
1)Shenzhen Graduate School,Harbin Institute of Technology,Shenzhen 518055,P.R.China
2)Peking University Shenzhen Graduate School,Shenzhen 518055,P.R.China
A high-speed memory system is proposed for reconfigurable codec processor to access high data throughput rates in video codec applications.The full duplex frame buffer and direct memory access(DMA)are included in this new memory system.The frame buffer contains two memories with the size of 4 kbyte and is divided into 16 banks.Two-dimensional address coding is introduced as well as data arrangement switch for fast sequential data access by codec algorithm.The simulation result shows that the memory system can meet high performance requirement for reconfigurable processor ReMAP-2 in high-definition video codec application.
integrated circuit technology;reconfigurable;processor;digital signal processing;discrete cosine transform;memory;multimedia processing;video codec
TN 47;TN 492
A
10.3724/SP.J.1249.2013.02150
国家博士后基金资助项目 (20110491091);深圳市科技研发资金基础研究项目 (JC201105160591A)
戴 鹏 (1983-),男 (苗族),湖南省双峰县人,哈尔滨工业大学博士后研究人员.E-mail:daiowen@126.com
引 文:戴 鹏,王明江,王新安.基于视频编解码的可重构处理器存储系统设计 [J].深圳大学学报理工版,2013,30(2):150-156.
Foundation:National Science Foundation for Post-doctoral Scientists of China(20110491091);Shenzhen Science and Technology Research Foundation for Basic Project(JC201105160591A)†
Professor Wang Mingjiang.E-mail:mjwang@hit.edu.cn
:Dai Peng,Wang Mingjiang,Wang Xin'an.Design of reconfigurable processor memory system for video codec [J].Journal of Shenzhen University Science and Engineering,2013,30(2):150-156.(in Chinese)
【中文责编:英 子;英文责编:雨 辰】
