微博情感倾向算法的改进与实现
2013-04-29张伟舒吕云翔
张伟舒 吕云翔

【摘要】为了提升对微博数据分析的准确度,首先对微博的发展现状及文本特点进行分析;其次提出全新的情感倾向词典构建方案,在改进现有词典的同时加入三个全新类型的词典,并以此作为词法分析的基础;随后建立可解析词与词、子句与子句之间的逻辑关系的语法库,从而实现对微博文本的语法分析;最后,应用本文提出的改进算法,设计、实现算法验证程序并进行测试。结果表明,改进算法在处理微博文本数据时正确率为80.74%,较原算法提高了22.72%。
【关键词】情感倾向分析 微博 情感词典 算法
微博情感倾向算法的改进与实现
自2006年Twitter在国外兴起开始,微博以其方便、快捷的特点迅速风靡全球。据统计,Twitter在2012年平均每天都有1亿7 500万Tweet被发布;在国内,新浪在率先推出微博服务后,已经聚集了4.24亿微博用户,平均每天活跃用户多达4 230万[1]。同时,腾讯微博也借助于其在即时通讯领域的优势,用户数量很快就突破了2亿,处于强势追赶阶段。各种形式的微博服务已经成为网民发布信息、交换对于事件的看法、观点与态度的重要途径。
微博用户数量的快速增长,使得网络上出现了海量的、以文本形式存在的数据信息。这些信息包含了用户对于特定事物的心情、看法、评价等。由于微博特有的文本长度限制,单条微博所能提供的信息相对有限,因此需要通过增加数据量来弥补这一缺陷。面对大量的文本数据信息,采用人工手段进行倾向分析往往会力不从心,因此,需要一种可以快速准确地对大规模文本进行倾向标注的方法,微博情感倾向分析研究就是在这种背景下发展起来的。
背景及相关研究
微博情感倾向性分析就是对说话人的态度(或称观点、情感)进行分析,也就是对文本中的主观性信息进行分析[2]。早期的微博情感倾向分析主要是进行词语语义的倾向计算[3]和文本情感分类[4-6]等工作。随着研究的不断深入,分析的重点逐渐转移到了更加精细的粒度上,如产品属性挖掘[7]、情感摘要[8]、情感分类器等[9]。
现有的情感倾向分析大致可以分成4个级别: 词语级别、短语级别、语句级别和篇章级别[10]。词语级别的分析主要是基于词典的语义相似度或层次结构来计算单词的情感倾向[11]。短语级别的情感倾向分析是在词语级别之上引入了程度词、否定词等分析内容,从而增加了判断情感倾向正负强弱的准确性。短语级别的情感倾向分析可以采用语料库[12-13]和词典[14-15]两种方法。句子级别的情感倾向分析主要包括主客观语句的区分、主观语句的倾向性计算以及语句中细粒度内容的提取[16-18]。篇章级别的情感倾向分析就是从一个整体的角度对文本进行情感倾向性分析[19-20]。在这4个级别上已有了一定数量的研究成果。
2009年,Yang Shen[14]提出了MBEWC微博情感倾向计算器。 该方法在算法设计时考虑了目标数据的特殊性,并进行了一些针对微博文本分析的改进。但在进行数据分析时,仍然存在以下缺陷:①沿用了由情感词词典、程度词词典和否定词词典三个词典组成的短语情感倾向分析体系,没有添加其他针对微博数据特征的词典系统;②计算子句倾向时,采用的是直接统计的方式,没有将词汇之间的修饰关系考虑在内;③分析子句之间关系时,虽然考虑到了子句先后顺序对子句情感倾向权重的影响,但是却没有进一步将逻辑关系考虑在内,导致该算法在分析转折句、感叹句等特殊句式时正确率下降。
本文在Yang Shen等所提出的MBEWC微博情感倾向计算器的基础上,在清华大学人机交互与媒体集成研究所的支持下,提出了针对微博文本信息的特殊性的改进算法。本算法以微博文本中的情感倾向元素以及相关的语法特征作为情感倾向证据,在原有的以情感词、程度词、否定词为核心的分析系统基础上,针对微博的语言特征及用户使用习惯,添加了表情、语气词以及用于进行主客观判断的部分特殊词,以有效地提升情感倾向分析的准确度。除此之外,本算法还引入了修饰语法和逻辑语法的概念,以确定文本信息中词与词之间、子句与子句之间的逻辑关系。新算法通过子句分割、子句倾向计算、逻辑关系计算、整句倾向汇总等步骤实现。算法验证程序可根据获取的词典、语法库等数据信息,对微博情感倾向进行自动标定。最后进行了网络真实微博信息的相关测试。
情感倾向词典构建与分析
文本情感倾向分析的基础是判断词语的语义倾向[21]。现有的情感倾向词典构建中,比较常见的是情感词词典、否定词词典以及程度词词典。分析时通常以单个词作为目标,而忽略了词与词之间的顺序、修饰关系,导致分析准确率有限。本文在对现有的上述三个词典进行改进的基础上,添加了特殊标识符词典、表情词典以及语气词词典三个新的词典。以这六个不同功能的词典构成一个新的词典系统,对文本数据进行综合分析,以期得到一个更加准确的结果。
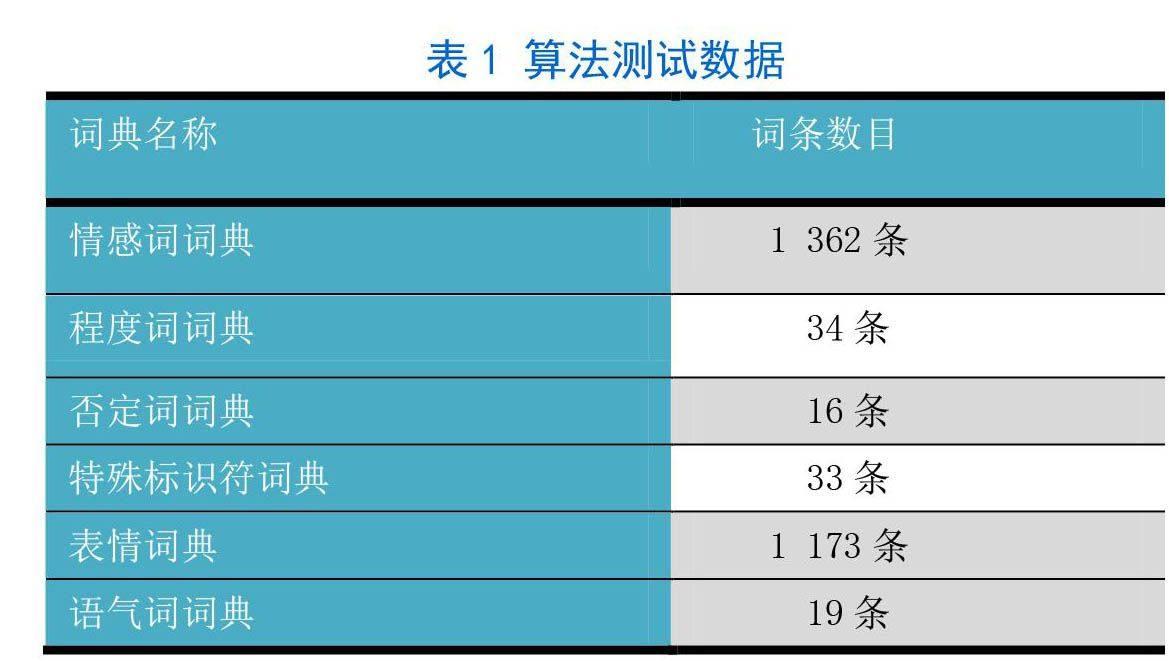
首先,本文对现有的情感倾向词典系统进行了改造与重构。新的情感倾向词典系统不仅对MBEWC中提到的情感词词典、程度词词典和否定词词典进行了内容和结构上的改进,而且新添加了表情词典、语气词词典以及特殊标记符词典,从而提升文本分析的准确度。其中,情感词词典包含可以反映用户情感倾向的名词、形容词和副词,如“高兴”、“失望”等;程度词词典包含可以反映用户情绪激烈程度的形容词和副词,如“非常”、“特别”等;否定词词典包含表示否定关系的词汇,如“不”、“非”等;表情词典包含微博中可能出现的表情符号,如“ ”(大笑)、“OTZ”(膜拜)等;语气词词典包含各种语气助词和感叹词,如“哈哈”、“唉”等;特殊标识符用于识别微博中的特定标记,包含各种新闻、广告的对应标记。在以上六个词典中,前三个词典适用于大多数文本倾向分析工作,后三个则是针对微博的文本特征特别设计的,可以有效地提升分析的准确率。
随后,对网络上1万条新浪微博数据进行分词、统计,为词典中的各个词条计算对应的权值:情感词、表情词与语气词的权值表示用户的基础倾向,权值范围是[-20,20];否定词表示否定关系,权值为-1;程度词表示情感激烈程度,权值范围是[0.7,1.3];特殊标记符用于判断情感倾向的可信度,权值为1或0。每个词条均由多人分别进行标记,取其平均值作为结果,从而保证这一过程的客观性。
新建立的词典系统共包括词条2 637条(见表1)。
通过这种方法建立的词典系统的优点是:①针对性强。由于词典组中的词条均来自真实的微博数据,因此与其他方式建立的词典组相比,该词典组包含了较多的网络用语和专有词汇(这些内容在其他文本数据中十分少见),从而更加适合处理微博数据。②分析全面。这个词典组由六个词典构成,可以对微博文本数据进行表情符号、语气特征以及可信度进行评判,使得整个分析过程更加全面合理。
微博情感倾向算法主要流程
在进行数据分析之前,先要对数据进行筛选,剔除微博系统自动发布的广告和新闻信息,仅保留能够反映用户真实情感倾向的微博数据。这部分工作主要依靠特殊标识符词典的识别和判断。
微博情感倾向分析改进算法的主要流程如下:
● 子句分割。根据标点符号将读入的微博数据分割为多个子句c1,c2,…,cn。由于部分标点符号会对子句的倾向值产生影响(例如小括号中的内容多为解释说明,属于次要信息),因此需要对部分子句进行额外的权值运算,权值取值范围为[0.5,1.5]。
● 表情符号分析。利用表情词典,对于ci中的表情符号a1,a2,…,an进行匹配(见图1),并累计表情符号的权值为Ai。如果Ai大于特定阈值,则以Ai作为子句ci的情感倾向值Eci,并直接执行“重复计算”流程;如果Ai小于特定阈值,则将表情符号从ci中删去,生成ci,并进行后续分析。
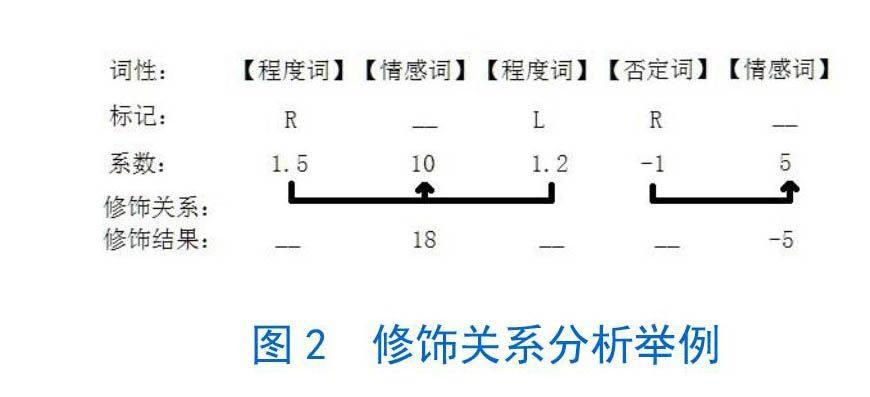
● 修饰关系分析。利用情感词词典、程度词词典以及否定词词典识别ci中的情感词(e1,e2,…,en)、程度词(d1,d2,…,dn)和否定词(n1,n2,…,nn)。修饰关系的分析主要是根据特定方向的最近原则来确定,即根据每个程度词和否定词在词典中的修饰标记位,确定其修饰方向,并将该方向最近的一个情感词作为其修饰目标。程度词和否定词的权值会与被修饰的情感词相乘,作为修饰后的情感词权重ei。随后,已经完成修饰的程度词和否定词会被从ci中删去,生成ci(见图2)。
● 语气分析。利用感叹词词典,识别ci中的语气词(m1,m2,…,mi),从而进行子句的语气分析。
● 子句倾向汇总。将子句中的表情(ai)、情感词(ei)以及语气词(mi)的系数进行加和,得到子句的倾向值Eci。
● 重复计算。当子句ci的倾向值计算完成后,转至下一子句,并重复上述的过程,直至所有子句的倾向值计算完成。
● 子句逻辑分析。根据子句中所包含的逻辑连词,对特定子句进行额外的权值运算,从而增强和削弱部分子句的重要程度。此外,还需要根据子句的先后顺序,进行权值运算,突出位置靠后子句的重要程度,得到逻辑分析后的子句倾向值Eci。
● 子句倾向汇总。对每一个子句倾向值Eci进行累加,得到该微博的情感倾向系数E。
至此,微博数据的情感倾向分析已经完成,E即为所求的倾向系数。
算法测试评估
在完成上述工作后,利用C++编写算法验证程序。该程序可以读入词典系统以及微博数据,并按照算法流程进行计算,最后得出相应的情感倾向。笔者使用这个程序对算法进行测试。测试中将以下结果视为判断成功:积极倾向微博的计算结果>0;中立倾向微博的计算结果=0;消极倾向微博的计算结果<0。
4.1 数据准备
利用网络爬虫重新获取了一定量的微博数据,并从中随机抽取了10 000条用于测试。这样做可以有效降低爬虫软件带来的数据来源局限性,使得测试结果更加客观。
测试数据的情感倾向由多人分别进行标定,并在最后进行统一汇总。汇总时,将情感倾向标定意见相同的微博作为样例,对意见不同的微博进行讨论,直至所有测试数据的情感倾向被确定。测试数据的分布如表2所示:
4.2 算法测试
使用对比试验的方式,借用现在比较成熟的ROST_EA[14]微博情感倾向分析系统与本文所提出的改进算法进行比较,从而明确新算法的特点、优势与不足。本文主要比较了两种算法的召回率与准确率。
召回率代表原有的某种倾向微博(积极、中立或消极)被算法成功识别的概率。即召回率越高,算法在处理该类微博时遗漏越少。
测试结果如表3所示:
准确率代表在算法做出某种倾向判断(积极、中立或消极)时,判断为正确的概率,即准确率越高,算法在做出该类判断时错误越少。
测试结果见表4。
从表4可以看出,与ROST_EA相比,新算法在处理情感倾向比较明显的微博时略逊于ROST_EA,分别低0.84%和3.48%;但是在处理情感倾向比较模糊或偏向中性的微博时,准确率提高了46.53%。 整体而言,在分析微博数据的过程中,新算法的正确率高达80.74%,远高于ROST_EA的58.02%。
尽管ROST_EA在处理情感倾向明显的微博时召回率略微高于本算法,但是这并不代表该算法的分析模式占优。在分析这些微博时,ROST_EA总共将4 901条微博标记为积极倾向、将3 053条微博标记为消极倾向,但它们之中判断正确的仅有2 678条和1 314条。这说明该算法在判断出较多的具有倾向性微博的同时,也包含了大量的错误判断,导致整体效果有限。反观新算法,其不但在判断倾向性明显的微博时表现优秀,在面对中立倾向的微博时也一样具有很高的召回率,达到了召回率和正确率的平衡。改进的算法与
4.3 测试结果分析
新算法针对现有算法的缺陷进行了改进和完善,具体改进效果如表5所示:
从表5可以看出,新算法在词典系统、词法分析和语法分析等方面的改进提升了数据分析的正确率。其中,仅词典系统改进就使得分析正确率提升了16.05%,从而证明了词典系统改进方案的有效性。此外,词法分析与语法分析分别使分析正确率提升了4.15%和3.52%,这一方面显示出本文所提出的词法语法分析体系的合理性,另一方面也反映了现有的修饰规则和语法库还不够完善,有进一步改善的空间。最后,改进算法中的格式统一、文字翻译等其他改进项也使得正确率得到了0.33%的提升。
整体而言,本文提出的改进算法对现有算法的缺陷进行了弥补,并提出了一系列改进措施,使得微博文本数据分析的正确率有了较大的提升。
结 语
本文提出了一种针对微博系统的情感倾向分析算法,用于对网络微博文本进行倾向性分析。与现有的微博情感倾向分析算法相比,这套算法考虑了更多的语法因素,从而使分析计算过程更加科学合理。最后,本文还对所提出的算法进行了测试并与现有的微博情感倾向算法进行对比,证明新算法具备明显的优势和特点。
[参考文献]
[1] 新浪网. 新浪2012年第三季度财务报告[EB/OL].[2013-04-17].http://tech.sina.com.cn.
[2] 冯希莹,王来华. 舆情概念辨析[J]. 社会工作(学术版), 2011(5):83-87.
[3] Hatzivassiloglous V, MCKeown K. Predicting the semantic orientation of adjectives[C]// Proceedings of ACL-97, 35th Annual Meeting of the Association for Computational Linguistics. Madrid: ACL, 1997:174-181.
[4] Zagibalov T, Carroll J. Automatic seed word selection for unsupervised sentiment classification of Chinese text[C]//Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008).Manchester: Coling 2008 Organizing Committee, 2008:1073-1080.
[5] Pang B, Lee L, Vaithyanathan S. Thumbs up? Sentiment classification using machine learning techniques[C]//Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing(EMNLP 2002). Philadelphia:ACL,2002:79-86.
[6] Turney P D, Littman M L. Measuring praise and criticism: Inference of semantic orientation form association[J]. ACM Transactions on Information Systems, 2003, 21(4):315-346.
[7] 王素格. 基于Web的评论文本情感分类问题研究[D].上海:上海大学, 2008.
[8] Tan S, Wu G, Tang H. A Novel scheme for domain-transfer problem in the context of sentiment analysis[C]//Proceedings of the 16th ACM Conference on Information and Knowledge Management. Lisbon: ACM, 2007:979-982.
[9] Hu M, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle: ACM, 2004:168-177.
[10] 魏韡,向阳. 中文文本情感分析综述[J].计算机应用,2011(12):3321-3323.
[11] 杜伟夫,谭松波,云晓春,等. 一种新的情感词汇语义倾向计算方法[J].计算机研究与发展,2009,46(10):1713-1720.
[12] Yuen R W M, Chan T Y W, Lai T B Y. Morpheme-based derivation of bipolar semantic orientation of Chinese words[C]//Proccedings of the 20th International Conference of Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2004: 1008 - 1014.
[13] 张靖,金浩. 汉语词语情感倾向自动判断研究[J]. 计算机工程, 2010, 36(23): 194-196.
[14] Yang Shen. Emotion mining research on Micro-blog[C]//2009 1st IEEE Symposium on Web Society(SWS 2009). Lanzhou: Lanzhou University,2009.
[15] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006, 20(1): 14-20.
[16] 熊德兰,程菊明,田胜利. 基于HowNet的句子褒贬倾向性研究[J]. 计算机工程与应用, 2008, 44(22): 143- 144.
[17] 李实,叶强,李一军. 中文网络客户评论的产品特征挖掘方法研究[J]. 管理科学学报, 2009, 12(2): 142-152.
[18] 刘鸿宇,赵妍妍,秦兵,等. 评价对象抽取及其倾向性分析[J]. 中文信息学报, 2010, 24(1): 84-88.
[19] 唐慧丰,谭松波,程学旗. 基于监督学习的中文情感分类技术比较研究[J].中文信息学报, 2007, 21(6):88 - 94.
[20] 李寿山,黄居仁. 基于Stacking组合分类方法的中文情感分类研究[J]. 中文信息学报, 2010, 24(5): 56 - 61.
[21] 吴迪. 汉语微博文本特征研究[D]. 长春:吉林大学, 2012.
