基于非线性关系的税务自发任务分发应用的算法分析与Oracle 实现
2013-03-20朱爱民
◆孙 利 ◆朱爱民
一、引 言
税务任务分发应用是工作流的一种,工作流的概念源自企业的生产经营管理与办公自动化领域。税务任务分发应用通过记录对税务机关在税收征管活动中具有上下层级顺序的若干涵盖多部门、多人员的工作流及工作流变化过程,监督与控制税务机关的整个任务落实过程诸如上传下达完成等环节流程的执行时间、效率与结果。通过对任务分发过程与结果的信息分析利用,进行税收征管业务流程再造,实现高水平的税务信息化建设。
二、非线性的税务任务分发应用与一般税务任务应用的区别
一般税务任务应用是按照始于纳税人需求的纳服体系建设要求设计的业务流程,通常是从纳税人的申请与纳服部门的受理开始,中间经过调查、核实、报批、审批等节点,最终回到纳服部门反馈纳税人结果为结点的过程。如图1 所示:
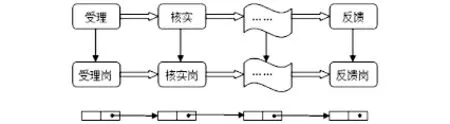
图1 一般税务任务应用
图1 显示了一般税务任务应用中节点与岗位的关系。在实际运用中,通过设计不同事项途经不同的节点以及不同的操作人员对应的岗位,实现从对纳税人申请的受理开始任务的传递流程。这种业务流程实现的是一种线性关系,其结构是链表式的基本数据结构,流程按顺序访问一组数据项的集合,这些数据项形成一个链表,每个元素都含有访问下一个元素所需的信息。要访问链表的信息,只需要引用链表的指针和结构体的成员名即可。
从税务机关内部发起的自发任务分发应用则不同。一项从内部发起的征管任务,从发起者开始,到最终履行者,任务逐级推送,涉及人员逐级增长,内容逐步明晰,其业务流程实现的是非线性关系,所呈现的树图如图2 所示。
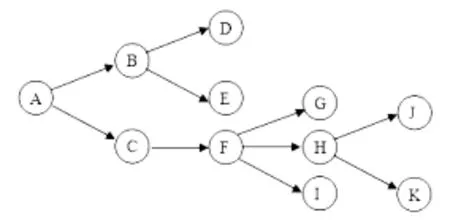
图2 税务机关自发任务分发应用的树图
其基本特征有:
特征1.1 税务自发任务分发应用是树的应用。
税务自发任务分发应用是由n 棵互不相交的树组成的集合,即森林;每一棵树是一棵有向树,每棵树的每个节点有零或多个子节点,每个子节点有且仅有一个父节点,在树的根与其他节点之间、父节点与子节点之间有且仅有一条路径。
特征1.2 税务自发任务分发应用是有序树。
有一个结点的入度为0,其余所有结点的入度都为l,是一个有根树,虽不是自由树,但作为一个为每个子结节规定从左到右次序的有序树,则在实际中未必有必要性。
特征1.3 税务自发任务分发应用是M 叉树。
作为一个M 叉树,每一个节点的出度小于或等于m,子节点的数目并不确定。 从行业应用来看,税务自发任务分发应用有以下特征:
特征2.1 树的根、层数、不同层数的节点均存在不确定性。
不同层级的税务机关下发任务时,其根、层数与不同层数的节点均不确定。不同的任务,也产生同样的不确定性。以节点落实到具体数据的不确定性为例:有的任务是指定数据的,例如对全国重点税源纳税人的管理任务,表现为数据量固定不变;有的任务是从一批指定数据到另一批指定数据,如从风险识别->风险推送->风险应对,呈数据量衰减趋势;有的任务是从文字描述发起到具体数据的落实过程,呈数据量增长趋势。
特征2.2 目标是实现以任务自身为核心的柔性的任务分发功能。
基于特征2.1,税务自发任务分发应用的目标是实现以任务自身为核心而非任务内容为核心的、柔性的而非刚性的任务分发功能。在核心功能实现的基础上,兼顾任务内容所落实的具体数据信息,实现系统的完整性。
三、基于实际税务应用的表设计
如果从存取类似税务任务分发这样的应用来说,无疑一些NoSQL 数据库,例如文档型数据库是更好的解决方案。NoSQL 数据库与关系型数据库相比,更偏重于数据存取和问题的解决,而非像关系型数据库那样基于关系模型、侧重于分析数据与数据之间的关系和结构。关系型数据库虽然不是唯一的高级数据库模型,也不是性能最优的模型,但是因为功能兼顾,易于理解和使用,已成为目前使用最广泛的主流数据库,包括在税务系统的应用。本文也以关系数据库为例说明。
税务自发任务分发应用需要的基本信息有:
1.任务信息
任务有发起时间、发起部门、类型、完成任务的数量要求、质量要求、时限要求等信息,因此,需要一个任务表(tasks),如表1:

表1 任务表
2.任务状态信息
在业务流程设计上,任务分发的正常流程包括:生成->下发->未读->已读->(转发)->申请完成->完成,其业务逻辑为从任务制订为起点,把任务下发给指定对象,指定对象是否阅读的状态用于监控接收任务对象的工作流。指定对象收到任务后,决定是否要转发任务,对转发的任务,原任务处于转发状态,再重新生成新的任务。接收任务方完成任务后,向任务发起方提交任务完成申请,由任务发起方设定任务完成状态。
非正常的业务逻辑有申请退回、删除、冻结等。
任务状态表(states)用于保存任务的状态,如表2:

表2 任务状态表
3.任务分发人员信息
由于税务任务分发时,常常需要分发同一任务给多个接收人员,因此需要任务分发人员信息表(operators)记录任务分发人员的信息,对下发人员、接收人员进行记录,如表3:

表3 任务分发信息表
4.任务内容/附件信息
在解决了核心问题后,通过任务内容或附件表(attachments)的形式,记录任务相关的内容与附件,为精细化处理任务保存信息,如表4:

表4 任务附件表
税务自发任务分发应用的E-R 图如图3 所示。

图3 表设计的E-R 图
为便于描述,以上数据表设计均以单树为例,未加入总任务号字段来标识区分多树。
四、任务分发应用的算法
对以上通过保存任务号+父任务号信息的形式实现的最基本的税务任务分发应用的数据表结构,我们运用的最基本的算法即是任务的遍历。通过任一任务的节点,系统地处理任务里的每一节点。有三种基本的顺序来遍历节点:
先序:先访问根节点或父节点,再访问子节点。
中序:通过父节点得到所有同层子节点,然后访问子节点。
后序:先访问子节点,再访问父节点直至根节点。
通过递归可以实现以上遍历方法,如图4 所示(图左为先序遍历,右为后序遍历):
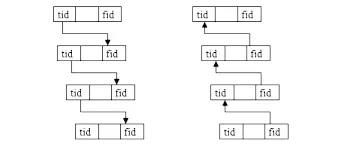
图4 递归遍历图示(tid/fid 分别为子节点与父节点)
在最简数据表结构的基础上实现的遍历,虽然可以采取三个遍历方法,但实际使用以后序法为主。因数据表结构中保存的信息仅有父信息与子信息,要从任一节点出发,只能跟踪链接逐一从一个节点移到上一节点。从数据库运行来说,即每次节点的移动就是对数据库的一次检索,如果一个任务有N 个节点,对该任务的一次遍历访问数据库也不会少于N 次。
因此,我们还可以看到在基本数据表结构的基础上,为解决遍历效率问题而衍生的另外几种扩充数据表结构,用于实现任务分发应用的参考:
1.加路径信息
例如在前面的tasks 表中增加路径信息字段paths,定义为AA(-BB-CC……)的结构,如00-00-00 为根节点(或00),第一层的左节点为00-01-00(或00-01),右节点为00-02-00(或00-02),依次类推,也可不补零。在检索时,通过SQL 语句SELECT * FROM tasks WHERE paths LIKE SUBSTR(@path,1,2) ORDER BY paths 在任一节点可以仅访问数据库一次即可检索整棵树。但其缺点也很明显,即路径字段宽度受到层数和子节点个数的限制,仅适用固定层数的树遍历。
2.加层数信息
通过增加层数和根节点信息,有利于提高中序检索的效率。如在前面的tasks 表中增加层数信息字段layer 和根节点信息字段root,通过SQL 语句SELECT * FROM tasks WHERE root=@root AND layer=@layer AND father_id=@father_id 在任一节点访问数据库可以得到中序遍历的结果。其缺点是数据冗余严重。
3.设置左右代码信息。
在tasks 表中增加表示左右信息的字段left 和right,left 数据以根节点为1 开始,从根节点沿子节点路径向下,每个节点加1,到树叶后,再沿子节点向上,right 数据在每个节点加1,通过SQL 语句SELECT * FROM tasks WHERE left>@left AND right<@right 可以得到中序遍历的检索结果。从算法上是一种新颖的设计,但目前仅适用二叉树,且不适应节点的删改变更。
综上几种数据表结构设计,从算法来看可以获得不同的遍历效率,但从实际运用来看,则是耦合度越高,容错度就越低。
五、Oracle 实现举例
Oracle 数据库是关系型数据库,不能像层次型数据库那样存放层次关系。但Oracle 数据库提供了强有力的层次查询(Hierarical Retrival)功能,可以高效地获得层次关系信息。以Oracle10g 为例,可以实现用先序、中序、后序各种方法遍历树,其实现方法为:通过查询子句START WITH 确定起始节点位置;通过查询子句CONNECT BY 确定遍历方向,先序或后序。
SQL 语句语法为:

Oracle 提供了一个用于层次检索的虚拟列level,与CONNECT BY 子句共用,通过level 列可以获得树的层数值。
检索的遍历方向根据CONNECT BY 后的PRIOR 在哪个节点前确定。如在子节点前,则为先序;如在父节点前,则为后序。如子句为CONNECT BY PRIOR son_id=father_id 或CONNECT BY father_id=PRIOR son_id 时,则其方向为先序遍历,按START WITH 子句指点的节点按路径逐一向下遍历;如子句为CONNECT BY son_id= PRIOR father_id 或CONNECT BY PRIOR father_id=son_id 时,则其方向为先序遍历,按START WITH 子句指点的节点按路径逐一向上遍历,但遍历的范围仅限于同一父节点为止。
例如在表tasks 中,从father_id 为空处(表示根节点)开始进行先序检索:

检索结果如表5:

表5 检索结果
使用DELETE 语句结合START WITH 和CONNECT BY 子句,实现对指定节点的子节点删除。
Oracle10g 在层次查询上的一个新增功能是引入了CONNECT_BY_ISLEAF 函数,通过函数值判断指定节点是否为树的叶子。函数值为0 时,非叶子;函数值为1 时,为叶子。
如按先序检索tasks 表中father_id=1 开始的子节点信息,并显示其是否为叶子:

Oracle10g 对层次查询中可能发生的递归死循环,即互为父子节点的情况,使用NOCYCLE 关键字进行干预,而且可以通过CONNECT_BY_ISCYCLE 关键字的值查询在哪个节点发生了死循环。
六、结语
本文分析基于非线性关系的税务机关自发任务分发应用的算法,并在实际税务应用的基础上,给出了基本的数据表设计,通过Orcale 实例,说明了应用的实现效果。文章表明了非线性关系的税务机关自发任务分发系统的实现可能性、可靠性与可维护性,为最终实现该应用提供了坚实的基础。
[1][美]塞奇威克.算法Ⅰ-Ⅳ 基础、数据结构、排序和搜索[M].张铭泽等译.北京:中国电力出版社,2004.
[2][美]科曼.算法导论[M].潘金贵等译.北京:机械工业出版社,2006.
[3]Iggy Fernandez.Beginning Oracle Database 11g Administration[M].USA CA:APRESS,2009.
