聚类分析中的相似度研究
2013-03-12邓冠男
邓冠男
(东北电力大学理学院,吉林吉林132012)
聚类,也称作无监督分类,是数据挖掘的重要组成部分,目前已经在很多领域取得了成功的应用。聚类分析的目的是通过将有限的数据集分成多个具有同质的“簇”(即不同的类),来发现隐藏的、潜在于数据中的有用信息。其目标是要求同一类内的数据尽可能相近,而不同的类之间的数据尽可能相异。为了达到这一目标,必须考虑如何度量数据之间、数据与类之间或者类与类之间相似性这一基本而重要的问题。为了度量数据的相似性,人们提出相似度的概念,并提出许多相似度的计算公式[1-3]。
尽管很多时候没有明确说明,但是事实上,无论何种聚类算法,都是建立在事先假定某种相似性度量方式基础上的,比如K-均值算法假定数据之间、数据与类之间都使用欧式距离构造的相似度;基于图的聚类算法假定数据之间使用欧式距离构造的相似度,但是数据与类之间的相似度定义为数据该类所有元素相似度的最小值;EM算法利用某种概率密度函数来度量数据与类之间的相似度等等。
在实际的聚类问题中,存在很多与相似度有关的问题。比如,当数据的属性具有不同权重时,如何计算相似度。如果没有任何关于属性重要性的先验信息,毫无疑问我们会认为所有属性都应当平等对待,但是如果必须区别对待的话,我们必须考虑如何对属性进行加权。然而,从众多相似度的计算公式中,我们并不能看出或者明确给出权重如何分配给各个属性的。再如,如果数据混合有不同类型的数据(如布尔型、文本型、数值型等等),如何计算其相似度,目前能够解决这一问题的相似度还是非常少的[4,5]。
本文针对聚类分析中的相似度进行研究。首先,通过分析相似度的构成的过程,将相似度的构造分解为比较、综合及转换的过程,进而提出一般相似度的概念。之后,利用一般相似度分析常见相似度对权重的分配方式,同时提出几种多类型混合数据相似度计算的策略。
1 相似度
在一些文献中可以找到不同的相似度的公理化定义方式[6,7],这里我们给出其中一种简单的定义方式。
定义1设X=X1×X2×…×Xn为n维有限论域,对于∀x,y∈X,如果映射s:X×X→[0,1]满足下列条件时:
(1)非负性0≤s(x,y)≤1;
(2)对称性s(x,y)=s(y,x);
(3)s(x,x)=1。
则称s(x,y)称为x与y之间的相似度。
但是,需要注意的是,目前某些文献中给出的相似度的计算公式并不完全满足上述定义。针对不同的数据类型,目前有许多相似度的计算公式,下面列出常见的一些:
(1)数值型数据的相似度
数值型数据的相似度通常利用数据间的距离来构造,可以利用公式

将距离转化为相似度,其中max_d表示数据集中数据之间的最大的距离。
常用的距离公式有:
其中,∨表示取大运算,对应的∧表示取小运算。
(2)二元数据的相似度
二元数据是由二元变量构成。二元变量只能有两种取值状态:0或1,其中0表示该特征为空,1表示该特征存在。设x=(x1,x2,…,xn)、y=(y1,y2m…,yn)为二元数据,常用0-0匹配表示xi=0且yi=0,同理可用0-1、1-0及1-1匹配表示xi及yi相应的取值。常见的计算其相似度的方法列举如下,其中fij表示集合{(xk,yk)xk=i且yk=j,k=1,2,…,n}的基数,i,j∈{0,1}。

(3)其他相似度
2 一般相似度
上文列出了一些相似度的计算公式,显然,由这些公式,我们是无法看出这些相似度之间有什么差别,也看不出这些相似度对于权重是如何分配的,那么,在实际运用中究竟选择哪种相似度进行计算呢。
如果给定两个数据x=(x1,x2,…,xn)及y=(y1,y2,…,yn),显然数据由各个分量所共同描述而成,因此其相似度也是由各分量来决定的。自然而然,可以得到这样的想法,如果比较xk与yk(k=1,2,…,n)之间的接近或者分离程度,然后将所得结果综合起来就可以形成对x与y之间整体相似度的描述。这就是本文一般相似度的基本出发点,并且下文分析也可以看出,常见的一些相似度实际上也是这样计算得来,而且由此我们可以看出权重的分配方式及相关问题的解决方案。
定义2设X=X1×X2×…×Xn是n维有限论域,x=(x1,x2,…,xn),y=(y1,y2,…,yn)是两个n维数据对象,那么x与y之间的一般相似度可由下式计算得到:
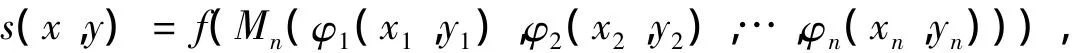
其中,
(1)φi:Xi×Xi→Y称作单属性相似或相离度,是度量第i个属性元素之间接近或分离程度的函数;
(2)Mn:Yn→Y称作综合函数[8],满足如下条件:

(3)f:Y→[0,1]称作转换函数。
定义2中,Y表示计算单属性元素之间接近或者分离程度函数的值域,通常如果计算的是接近程度Y=[0,1],如果计算的是分离程度Y=R。从定义2可以看出,一般相似度将相似度的计算过程分解成三个步骤:比较、综合及转换。比较,度量单个属性之间的相似或相离程度;综合,将每一属性之间的度量结果综合,形成对整体的度量结果;转换,将上一步的计算结果映射到[0,1]。这样构成的相似度给出了大多数相似度的一般表示形式,具体的转化形式在下一节给出。为了方便起见,称φi、Mn及f为一般相似度的构成函数,其中综合函数在文献[8]中已经详细讨论过,这里不再赘述,常用的综合函数有:

特别的,如果φi为单属性相似度,且Mn为可加标准综合函数[8],则可以将一般相似度形式简化为:
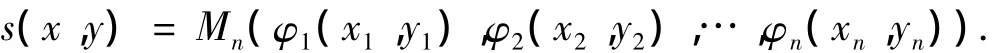
为了方便起见,称其为一般正规相似度。
设μn={MnMn是n阶可加标准综合函数},si为单属性相似度,按照综合函数的性质,很容易得到如下这些结论:
定理1设M2∈μ2,令Mn(x)=M2(M2(…(M2(x1,x2),x3)…),xn),那么s(x,y)=Mn(s1(x1,y1),s2(x2,y2),…,sn(xn,yn))为一般正规相似度。
定理2设Mm∈μm,Mnk∈μnk且,令
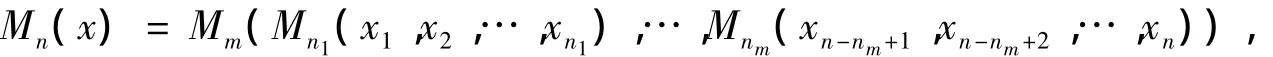
则s(x,y)=Mn(s1(x1,y1),s2(x2,y2),…,sn(xn,yn))为一般正规相似度。
定理3设Mm∈μm,M(k)n∈μn且1≤k≤m,令
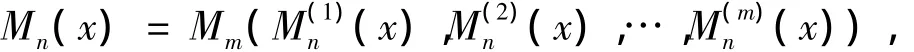
则s(x,y)=Mn(s1(x1,y1),s2(x2,y2),…,sn(xn,yn))为一般正规相似度。
定理1-定理3可以很容易由可加标准综合函数的性质直接得到,需要注意的是,这三个定理给出了三种不同的方式来获取同样的两个数据相似度的方法,虽然,这里看起来比较复杂,但是对于多类型混合数据却是非常有用的。
3 相似度相关问题分析
3.1 常见相似度的权重分配
设x=(x1,x2,…,xn)和y=(y1,y2,…,yn)为两个数据对象,这一节我们分析常见相似度是如何分配权重的。如果没有特别说明,本节中我们取综合函数
我们以欧式距离构成的相似度为例进行分析,设Ri为第i个属性差异量数,Li为第i个属性的集中量数,则有
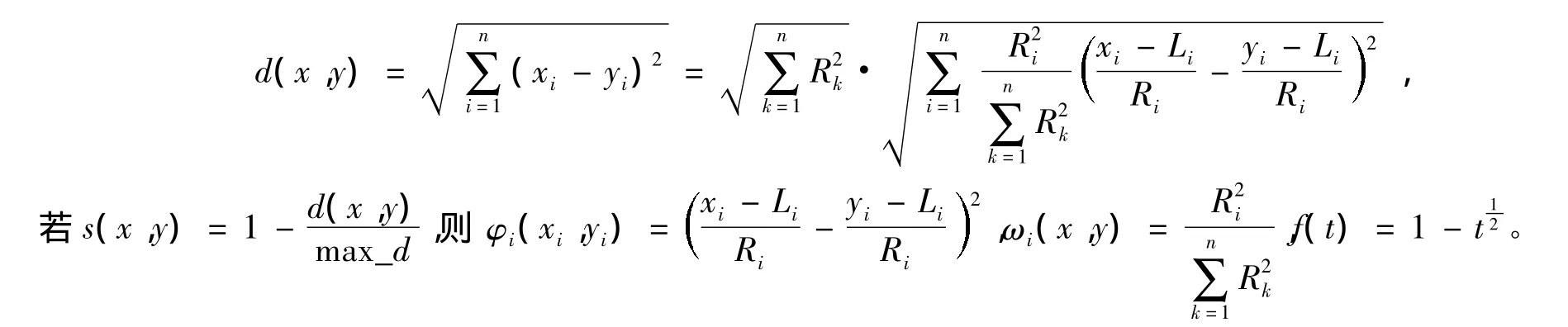
对于其他一些相似度我们进行了类似分析,具体如表1、表2及表3所示。

表1 基于距离的相似度的构成函数
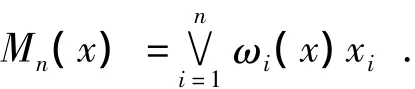
观察基于距离的相似度的构成函数,从中可以发现这样一个事实:如果数据没有经过标准化处理,基于距离的相似度并不是平均分配权重的,对于差异量数较大的属性赋予了较大的权重,这也反映了数据标准化处理的必要及重要性。
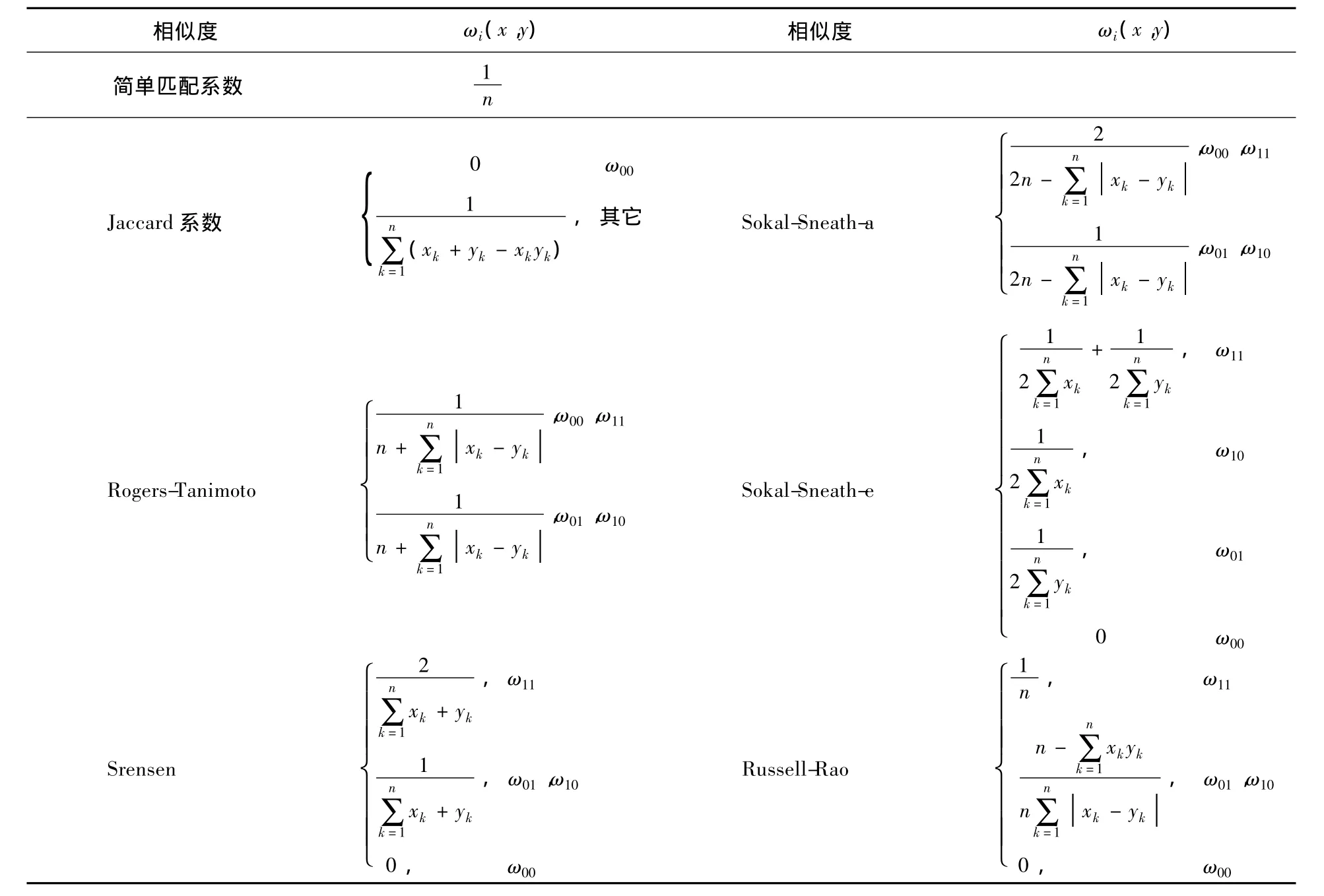
表2 二元数据相似度的函数构成
表2中,ω00表示xi=0且yi=0对应属性的权重,同理可理解ω01,ω10及ω11。表中所列二元数据相似度,其转化函数均为f(t)=t,单属性相似度均为的函数形式可知,0-1及1-0这两种匹配形式,对相似度计算没有任何影响。从表2中可以看出,一些相似度公式,如简单匹配系数、Rogers-Tanimoto以及Sokal-Sneath-a对0-0匹配及1-1均给予考虑;而Jaccard系数、Russell-Rao以及Srensen仅考虑1-1匹配。另外,通过比较不同相似度的权重分配数值,很容易得到下面的结论。
定理4简单匹配系数、Rogers-Tanimoto以及Sokal-Sneath-a的权重ω11(或ω00)之间有如下关系:

定理5Jaccard系数、Russell-Rao、Srensen以及Sokal-Sneath-e的权重之间有如下关系:
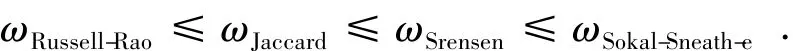
由于φi(xi,yi)=1-xi-yi,因此有
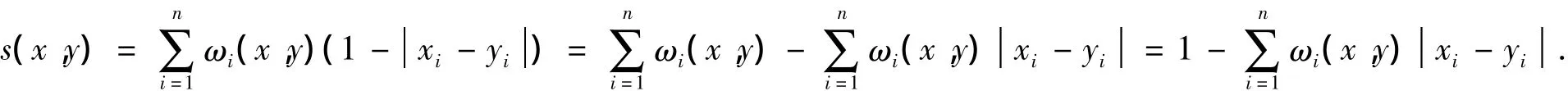
这说明本文所列的二元数据相似度可以看成由Manhattan距离(令p=1的Minkowski距离)构成的相似度,可以看作是一种特殊的由距离构成的相似度。

表3 其他相似度的函数构成
由表3可知,余弦相似度及相关系数构成的相似度对各个属性的权重也不是平均分配,而是数据的函数。可以看出,数据取值越大,余弦相似度分配的权重越大,同样数据距离均值越远,相关系数构成的相似度分配的权重越大。
3.2 多类型混合数据的相似度
在很多应用问题中,数据不仅是由一种类型的属性构造,这时各种相似度的计算公式就不能直接应用。然而,除了Gower[4]及Ichino[5]给的计算混合数据相似度的方法外,很少有人对此进行考虑。由本文的研究可知,问题的关键在于如何将不同类型属性的相似度综合起来,本文提出的一般相似度正好提供了这一问题的解决方案。具体在实施的时候可以有三种策略:
(1)直接按照一般正规相似度的定义方式进行计算。也就是,先度量单个属性之间的相似度,然后利用综合函数得出整体相似度。但是,很多常见的相似度在计算单属性相似度时会归约到同一形式上,如由Minkowsi距离、平均距构成的相似度以及很多二元数据的相似度都可以写成s(x,y)=1-x-y。
(2)将数据按照类型划分,利用相应的相似度公式计算不同类型数据的相似度,之后利用综合函数得出整体相似度,这种方法将同种类型的数据看成整体进行考虑。
(3)将上两种策略混合使用。
在实际应用中,还会涉及到其他一些问题,比如权重分配问题、综合函数选取问题、相似度选取问题等等,这还需要针对实际问题进行考虑。
4 结论
针对聚类分析中的相似度问题,本文提出了一般相似度的概念,在此基础上分析常见相似度的权重分配及多类型混合数据的相似度计算策略。需要注意的是,由一般相似度的概念可以很容易构造多种相似度的计算公式,这也是本文提出的一般相似度非常具有前景意义之处,但是鉴于本文并未考虑实际问题的需求,因此没有具体去做。
[1]S.Santini,R.Jain.Similarity Measures[J].IEEE Trans.Pattern Analysis and Machine Intelligence,1999,21(9):871-883.
[2]Y.S.Son,J.Baek.A modified correlation coefficient based similarity measure for clustering time-course gene expression data[J].Pattern Recognition Letters,2008,29(3):232-242.
[3]L.Bodis,A.Ross,E.Pretsch.A novel spectra similarity measure[J].Chemometrics and Intelligent Laboratory Systems,2007,85(1):1-8.
[4]J.Gower.A general coefficient of similarity and some of its properties[J].Biometrics,1971,27(4):857-874.
[5]M.Ichino,H.Yaguchi.Generalized Minkowski metrics for mixed feature-type data analysis[J].IEEE Transactions on System,Man and Cybernetics,1994,24(4):698-708.
[6]L.Kaufman,P.Rousseeuw.Finding Groups in Data-An Introduction to Cluster Analysis[M].New York:John Wiley&Sons,Inc,1990.
[7]Anderberg M.Cluster analysis for application[M].New York:Academic Press,1973.
[8]H.X.Li.Multifactorial functions in fuzzy sets theory[J].Fuzzy Sets and Systems,1990,35(1):69-84.
