论言思情貌整一原则与鲜活话语研究
——多模态语料库语言学方法
2013-01-24顾曰国
顾曰国
(中国社会科学院语言研究所,北京100732)
提 要 本文探讨言、思、情、貌在鲜活话语中的互动关系,提出“言思情貌整一原则”(亦称“内外整人原则”),并用这个原则对日常生活里一系列修辞现象作统一的阐释。本文追溯言思情貌整一原则跟古代“知言”、“知人”之间的渊源关系,同时指出跟西方语用学中格赖斯会话合作原则的异同。本文采用多模态语料库语言学中贴真建模的研究方法,对“整人”从言己、思己、情己、貌己四个角度分别作概念建模、数据建模和操作分析。本文语料主要来自鲜活话语的录音和录像,用ELAN对语料进行切分与标注。
一、引 言
针对鲜活话语讲修辞,常识要求人们讲话“言真意切”、“声情并茂”、“言行如一”、“表里如一”,而对“言不由衷”、“阳奉阴违”、“假情假意”之举则深恶痛绝。这些四字成语描写的往往是主观判断,缺乏客观的验证和系统的阐述。本文拟做一些研究,弥补其不足。如副标题所示,本文采用多模态语料库语言学的研究方法,对录自现实生活的音视频语料进行建模与分析,对上面提到的修辞现象进行实证型研究。本文力图证明,言思情貌整一原则可以对上面的修辞现象作出统一的阐释。
我们首先以实例说明言思情貌整一原则(第二节),接着介绍多模态语料库语言学及其方法(第三节),然后进入本文的核心,包括言思情貌整一的概念建模(第四节),分析言思情貌整一的八个基本架构和实例(第五节),言思情貌数据建模、操作与评估(第六节)。第七节主要讨论相关的理论问题,如言思情貌整一原则跟我国古代先贤关注的“知言”、“知人”之间的联系,跟西方语用学中格莱斯的合作原则之间的异同,言思情貌整一原则与知言的推理机制等。最后指出本文的不足和遗留问题。
二、言思情貌整一概说
1.童言无忌
当一个幼儿说出“我要姥姥!”这句“言”时,跟这个“言”相伴随的有个“思”,即“我想姥姥”。与“思”相伴随的还有个“情”,即“我跟姥姥在一起幸福”。“貌”指体态特征的总和,其中典型的貌特征是脸部表情、眼神、见到姥姥时搂住姥姥的神态。幼儿说话时言、思、情、貌是相一致的。我们把所有说话时言、思、情、貌相一致的情况称之为“言思情貌整一”。人们在说话时如果努力做到这一点,我们说说话人遵循了“言思情貌整一原则”(以下简称“整一原则”)。
整一原则在幼儿话语里是自然而然地得到遵守的。在成人话语里却并非如此,因种种原因往往是言思情貌相分离的,有些情况下甚至是对立的。在言思情貌整一的情况下,诠释说话人的用意是直接的。然而当言思情貌整一原则被违背时,会引发很多言外之意,诠释说话人的用意就要相对复杂得多。
2.真与假、形外与实内
言、思、情、貌都有真假之分。“真言”通俗地说是口心相应,“假言”是有口无心。“真思”就是心应言,“假思”就是心不应言。“真情”是既应言又应思,“假情”则反之。“真貌”就是应真言、真思、真情的体貌,“假貌”反之。非常有趣的是,现实生活比上面真假二值与言思情貌相搭配的情况要复杂得多。这待下文细说(见下文第五(1)节)。
真假问题从诠释的角度看是形外与实内的问题。换句话说,听话人根据什么来判断真假?言和貌是有外形的,是可以直接听到和看到的。而思和情是内在的,必须借助于其他东西而外泄于形上。对于说话者来说,说出来的音串是形外,驱动说出来的一切都是实内。思就是驱动说出来的因子,属于实内。情(指当下的情感),是伴随思的东西,主要受思的诱发而成,也是属于实内。伴随说话行为的貌是受思和情驱使下身体做出的反应,这类反应不少是观察不到的,有些则外泄于形,外人可以解析。
从说话人的驱动链上说,言思情貌的研究模型应为思→情→言→貌,即从实内到形外。对于听话人来说,研究模型则为言→貌→情→思,即从形外追溯到实内。注意这个研究模型是依研究语言这个宗旨而定的,不等于说话人和听话人产出以及处理话语时的实际过程,实际过程是个什么样子得由心理语言学来回答。
当说话行为的实内与形外完全吻合,即遵循了整一原则。形外与实内不吻合,即出现了违背整一原则。
三、多模态语料库语言学及其方法
1.多模态:定义
模态在本文里指人类通过感官(如视觉、听觉、触觉等)跟外部环境(如人、机器、物件、动物等)之间的互动方式。用单个感官进行互动的叫单模态,用两个的叫双模态,三个或以上的叫多模态。之所以用“多模态”而不用“多感官”是考虑到医学上的发现。感官对应的英文词是sense organ,模态是modality。谈起感官,人们马上联想到五官,这没有错,但这个联想不利于我们开展研究。理由有二:一是人类跟外界互动,包括跟自身的互动,所调用的感官远远超过五个;二是人类利用感官跟外界互动时是受脑控制的,跟各感官相配套的有专门的神经系统。假如离开这些配套的神经系统,感官是起不了作用的。所以现代脑科学研究更喜好用modality这个词来统指感官及其相应的神经系统(详细参见Kolb and Whishaw 2005:135),本文用的多模态,其含义正是源自这个英文词的医学用法。
人类在正常情况下跟外部世界(包括人际之间)的互动都是多模态的。
2.围绕“多模态”开展的相关研究
近几十年来,此类研究如雨后春笋,文献剧增。考虑到文章的宗旨和篇幅限制,本文只能厘清研究思路。跟多模态相关的研究总体上可以分为四种。
一是人机互动中的多模态研究。人与计算机互动,起先是人通过键盘进行文字输入,计算机通过屏幕显示文字做出反应。这是基于文字的触摸-视觉式互动。多媒体计算机发明后出现了基于声音-视屏的互动。当前手机上普遍采用的触摸式手写汉字输入、文语转换等,极大提高了人机互动的多模态性。有兴趣的读者可参阅 Maybury(1993)、Delgado and Araki(2005)。
二是多模态话语分析(multimodal discourse analysis)。在这类研究中,“多模态”这个概念跟人机互动研究中的多模态的含义有所不同。它是指表征意义的多种方式或符号系统,比如书面文字是一种符号系统,声音是另外一种符号系统,静态和动态图像又是另外一种符号系统等。颜色也是一种符号系统,因为不同的颜色有不同的表意功能。比如在我国,黄色历史上曾经是皇帝专用的颜色,红色是革命的象征等。在西方学术史上,对上面这些符号系统进行研究的称之为符号学。符号学研究它们时一般都是分开的,比如文字符号学、音乐符号学等,把它们混合起来统一研究的很少。如今情况不同了。现代数字化技术使得这些符号系统可以混合使用,静态的符号系统可以混排在同一纸质页面上,而且静、动态符号系统还可以出现在同一个网页上。研究人员根据脑医学上的研究,认为人在看或听多符号系统混合的页面时,会调用脑的不同功能部位来对应处理不同的符号系统。鉴于此,人脑在处理单符号系统表征的页面时,其调用的脑功能是单模态的,而在处理多符号系统混排的页面时,其调用的是脑的多模态功能。正是从这一点上考虑,研究人员才把他们的研究称之为多模态话语分析。在操作层面上,他们实际做的是探讨在多符号系统混排的情况下意义是如何得到诠释的。有兴趣的读者可参阅 Kress and Leeuwen(1996)、Leeuwen(1999)、Kress(2001)。
三是多模态语料库的研究。所谓多模态语料库是指把文字语料、音频语料和静、动态图像语料进行集成处理,用户可以通过多模态方式进行检索、统计等操作的语料库。多模态的含义包括(a)用户要调用多种感官(如视觉、听觉)来处理语料,(b)检索语料时其方式是多模态的,如键盘输入文字检索(触觉),音频输入检索(发声、听觉),图像输入检索(触觉、视觉)。这后一种意义上的多模态跟上面人机互动研究中的多模态是相通的。有兴趣的读者可参阅Taylor,N é e l and Bouwhuis(2000)、Gu(2006,2009)。
四是多媒体环境下的多模态学习研究。当今,单纯的基于纸质的学习资源面临被淘汰的可能,基于多媒体的学习资源成为主流。学生在利用多媒体资源学习时需要调用多种模态来互动。研究这类学习的规律成为当今学习研究的重要课题。有兴趣的读者可参阅Mayer(2001)、Gu(2007,2012)。
3.多模态语料库语言学梗概
语料库语言学经过近半个世纪的发展,由当初少数人钻牛角尖的课题变为语言学的显学之一。文献已经很多,本文不必赘言了。相比之下多模态语料库语言学是语料库语言学这个大架构下刚起步的一个支流。其要旨是利用上面说的多模态语料库开展语言学研究。本文涉及的多模态语料库——现代汉语现场即席话语多模态语料库(以下简称多模态语料库①),是一个比较特殊的库,其语料来自现场、事先无准备的话语活动的录音和录像。录音和录像中的语音内容通过人工转写成汉字文本。由此得到的文字、音频和视频三种文本通过时间轴进行同步集成。用户可以通过其中的任一文本同时检索到对应的其他文本。
利用上段定义的多模态语料库能做什么样的语言研究呢?能够研究的课题当然非常多,我们把多模态语料库语言学的终极目标定为:利用各类最前沿技术,尽量采录一切所能收集到的人类与外界互动的多模态数据,力求贴真模拟人类鲜活的多模态活动状况。人类鲜活的多模态互动,其数据状态是充盈的,我们称之为“充盈体验下的充盈意义”(详细参见Gu 2009a)。我国传统中医在诊治患者时所做的“望闻问切”操作,用本文的话说,就是分四个模态进行数据采样。多模态语料库里采用的文字转写、录音、录像,就是分三个模态进行数据采样。用fMRI(功能性核磁共振成像)、ERP(事件相关电位)等手段采集大脑的活动,代表了更多的多模态数据采录手段。
4.研究方法:贴真建模
用各类技术采录多模态数据是研究手段,贴真建模(simulative modeling)是多模态语料库语言学的研究方法。贴真建模不同于产品建模。后者的建模对象是建模者自己设计定义的,而前者的建模对象不是建模者设计的,在建模前就已经存在。人类鲜活的多模态话语活动跟人类的历史一样悠久,而多模态语料库语言学才刚刚起步。所谓贴真建模就是通过建模来贴近人类多模态话语活动的充盈意义状态。
简要地说,贴真建模是面向对象的建模方法,在操作上分三个阶段:概念建模、数据建模和实际操作与评估。在概念建模阶段,建模者根据对建模对象的认识制定概念模型。概念模型核心就是在理论上(即不考虑技术上能否实现)勾画出建模者对建模对象的认识与把握。以视觉和味觉模态为例。人类和其他动物一样都有视觉和味觉模态。假定我们的建模对象是一头绵羊、神农与一株草在这两种模态上的互动。当绵羊见到草时,绵羊眼睛把感光信息转化为脑电信息,经过脑处理后得出一个“解析果”,即视觉解析果。同样,绵羊的舌头把草的味觉信息发送给羊脑,经过处理也得出一个“解析果”,即味觉解析果。神农见到同样的一株草,神农的眼睛跟羊的眼睛一样,也把感光信息转化为脑电信息,经过脑处理后得出一个“解析果”,即视觉解析果。同样,神农的舌头把草的味觉信息发送给大脑,经过处理也得出一个“解析果”,即味觉解析果。
人脑和羊脑都有一个奇特的功能,就是能把来自多模态渠道的各种信息捆绑打包,变为一个完整的体验。这在脑科学中称之为“捆绑难题”(the binding problem)。概念建模至此,绵羊和神农的概念模型是一样的。然而,当概念建模考虑到两者的不同方面时,情况就复杂多了。我们不知道绵羊是如何对视觉解析果和味觉解析果进行编码的,我们也不知道绵羊脑子里是否有羊的语言,通过它进行编码,以便告诉同类伙伴,这样的草可以吃。神农的情况就不同了。神农对他的视觉解析果做出多种编码,比如用语音描述草的形状、颜色等,还用文字记录同样的信息。不仅如此,他还可以用绘画技巧把视觉解析果画出来。神农对他的味觉解析果可以通过上面的编码方式做同样处理。在符号学上,从感官与实物互动到产生解析果、再把解析果反加到事物上的过程称为“符行”(sign action)。需要注意的是,不是所有的视觉解析果、味觉解析果都能够清晰地编码出来。有些体验是无法言说的。
上面的概念建模可以形象地展示出来,如图1:
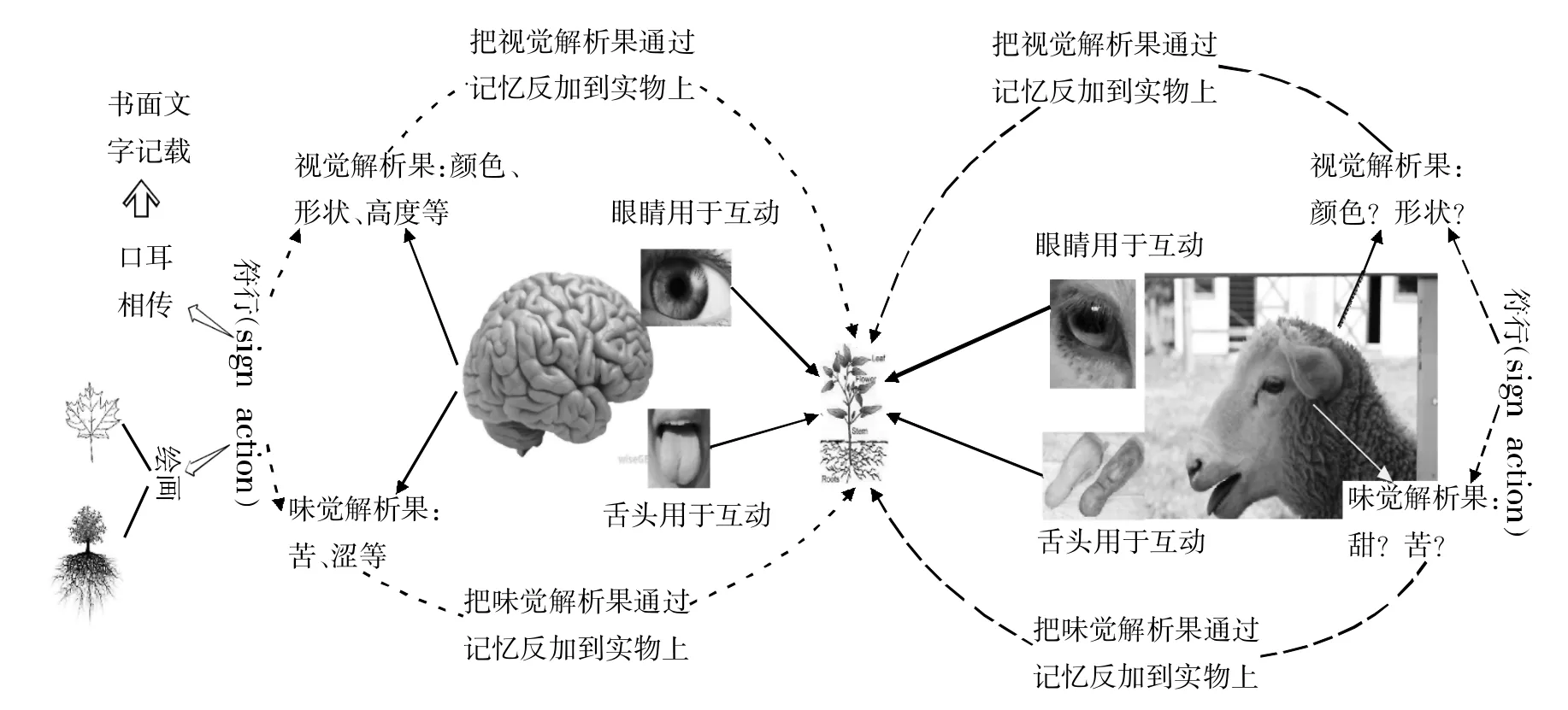
图1:羊、神农与草互动概念模型
贴真建模的第二阶段是数据建模,其核心任务是针对概念模型建相应的数据类型。比如眼睛跟草的互动过程,需要光——物理性数据类型——的支撑,眼睛把载有草信息的光转化为脑电信息,这类操作涉及生物化学数据类型,脑对解析果的编码,其数据类型是符号类。其余如此类推。数据建模还包括数据的元语言、数据整合和集成、数据交换等一系列技术问题。此处只能提及,无法细说。
最后,实际操作与评估阶段是利用先进的数字化技术根据数据模型对建模对象进行模拟操作。这个阶段能否实施,能否达到预想的效果,取决于现有的技术、人员使用技术的水平与经费支持等。
概要地说,对于实际操作与评估阶段来说,概念建模和数据建模反映了建模者“想到”的水平程度。科技发展史告诉我们,不怕做不到,就怕想不到。这就是说,一个概念模型如果在建模的当下还无法实施,还进不了实际操作阶段,并不等于概念模型没有价值。
5.本小节余言
需要特别提醒一下,我们不能把多模态语料库跟多模态语料库语言学混淆起来。在概念上两者是不同的。研究者可以建多模态语料库而不做多模态语料库语言学,这是因为多模态语料库可以为许多研究目的服务。多模态语料库语言学是一种语言学理论,即在多模态语料库的基础上提出来的语言学理论。
四、言思情貌整一:概念建模(上)
1.概说
一个在话语活动上言真意切、声情并茂的人是我们贴真建模的对象。在概念建模上我们把这样的人称之为“鲜活整人”。在建模时为了便于研究,整人被“化整为零”,在建模上“零”等于视角,就是从不同的角度来看这个整人。单个角度看到的整人就是他的某个方面,这就是化整为零。我们在单个角度看好以后再把各个角度集成起来,又得到一个整人了,建模上叫数据集成(详细参见Gu 2009)。
言思情貌就是本文看鲜活整人的四个视角。我们用“己”来代表视角所看到的整人的某个方面。由此我们得到“言己{…}”、“思己{…}”、“情己{…}”、“貌己{…}”四个方面。换言之,在我们的概念建模里,鲜活整人由四个“己”组成。当某个鲜活人的言语行为做到言思情貌整一,那么这四个“己”之间是协调与和谐的。当某个鲜活人的言语行为违背了言思情貌整一原则,那么这四个“己”之间是不协调的,不和谐的。
表达式“…+己{…}”除了用来表示构拟鲜活人的视角外,{…}表示这个“…+己”是动态的,是变化的。在数据建模和操作评估阶段,{…}要填满相应的数据。
下面为了便于阅读,除特殊情况外,我们把言思情貌后面的“己{…}”略去了,请读者注意。读者也许会说,现实生活中的整人远不止上面的四个方面。当然如此。在理论上,建模的视角是可以无限多的,在技术实现上也是没有难度的。到底需要多少视角取决于研究目的和可利用的资源。
2.言:语力与声韵
说出来的“言”是很复杂的。本文讨论的言主要指“鲜活的言”,即跟具体的说话人绑定在一起的、“有血有肉的人”的心声(即来自心里的声音)。传到听话人耳朵里的心声是音串,经过切分和处理,听话人得到由心声承载的关于说话人的各类信息,如语义、情感、说话人的性别、年龄、健康状况等。注意听话人解析到这些信息,无需见到说话人就可以得到。这当然可能与真人不符。当听话人同时看到说话人时,视觉给出说话人的全貌信息,借助于“貌”所传达的信息,他就可以解析到更加接近真实的信息。
本文关注心声的重点在语力和声韵两个方面。语力指说话人在说出某句话时,其说话行为所承载的一种社会行为意义。换句话说,虽然说出某句话是个体行为,但在面对面的互动中,通过谈话双方的共同语言而获得了一种社会意义。举例说明:说出“我要姥姥”这个音串是男孩的个体行为,在男孩跟他妈妈互动中通过双方都会说的普通话而获取了一种社会意义,即“要”他妈妈把姥姥叫到跟前来。“要”是一种社会意义,被“我要姥姥”这一个体说话行为所承载。“要”就是本文所涉及的“语力”②。
声韵指除字调以外的节律特征的总和(可参阅吴洁敏、朱宏达2001)。跟本文有关的包括两个方面。一是声韵跟语力之间的互动作用。以“这十块钱也值得记呀”为例。用什么样的声韵说出这句话,直接影响到语力的承载和辨识。
(1)a这十块钱也值得记呀!(叮嘱调,要记)
b这十块钱也值得记呀?(疑问调,不知道该不该记)
c这十块钱也值得记呀!(鄙夷调,不该记。语料库③中的实例是这个调)二是声韵跟情感的互动作用。声韵是传递讲话人当下情感的重要手段。这一点在我国先秦文献里就有论述(见下文第4小节)。声韵跟情感的互动已经成为当今语音工程的前沿课题(参见李爱军 2005;Li2013)。
3.鲜活话语中的“思”
本文所涉及的“思”指跟语力关联在一起的思想,不涉及跟语力不关联的思。所谓关联,先举例说明。说话人踩了听话人一脚,说:“对不起,对不起。”这句话有个语力,即道歉。跟道歉语力相关联的思想是“踩人不对,说话人错了”。说话人说出话语时抑或真有这个思想,抑或没有这个思想。上文说过,语力(如道歉)是一种社会意义,不管说话人实际上有没有跟语力配合的思,听话人根据这个社会意义都“有权力”去对说话人的行为做出价值判断。
在上文提到的说话人的研究模型里,思驱动言。这里把思跟语力关联在一起,好像是语力带动思。这是从听话人的视角分析的。从说话人的角度,思的确在驱动言。说话人踩了别人一脚,说话人的思对这个行为做出反应,说出“对不起”这个言来。假如他说出“踩死你”这个言来,驱动这个言的思就不同于驱动“对不起”的思了。
4.鲜活话语中的“情”
我国传统文化中有“七情六欲”之说。如《礼记·礼运第九》(中华书局,1989年版。下同):“何谓人情?喜怒哀惧爱恶欲七者,弗学而能。”现代的情感研究首先把情感分为两大类,一是较长期的、比较稳定的性格情绪,通常所说的“脾气秉性”;二是“当下情”,即跟当前的互动状况紧密联系的情感变化(可参见Ekman and Davidson 1994、Lewis and Haviland-Jones2000、蒙培元2002)。本文根据神经学家(也是病理学家)Damasio(1996,1999)以及Damasio&Meyer(2009)的研究,把当下情分为三层:第一,体况情感层(Damasio称之为“背景情感层”),正面的如精神饱满、底气足、康健、兴致高等,负面的如焦虑、疲惫、无精打采、萎靡不振、病态等;第二,基本情感层,如上面礼记所列的七情④;第三,社会情感层,包括对己和对人。社会情感层研究文献不多,Gu(2013)初步作了如图2(上页)所示的分类。
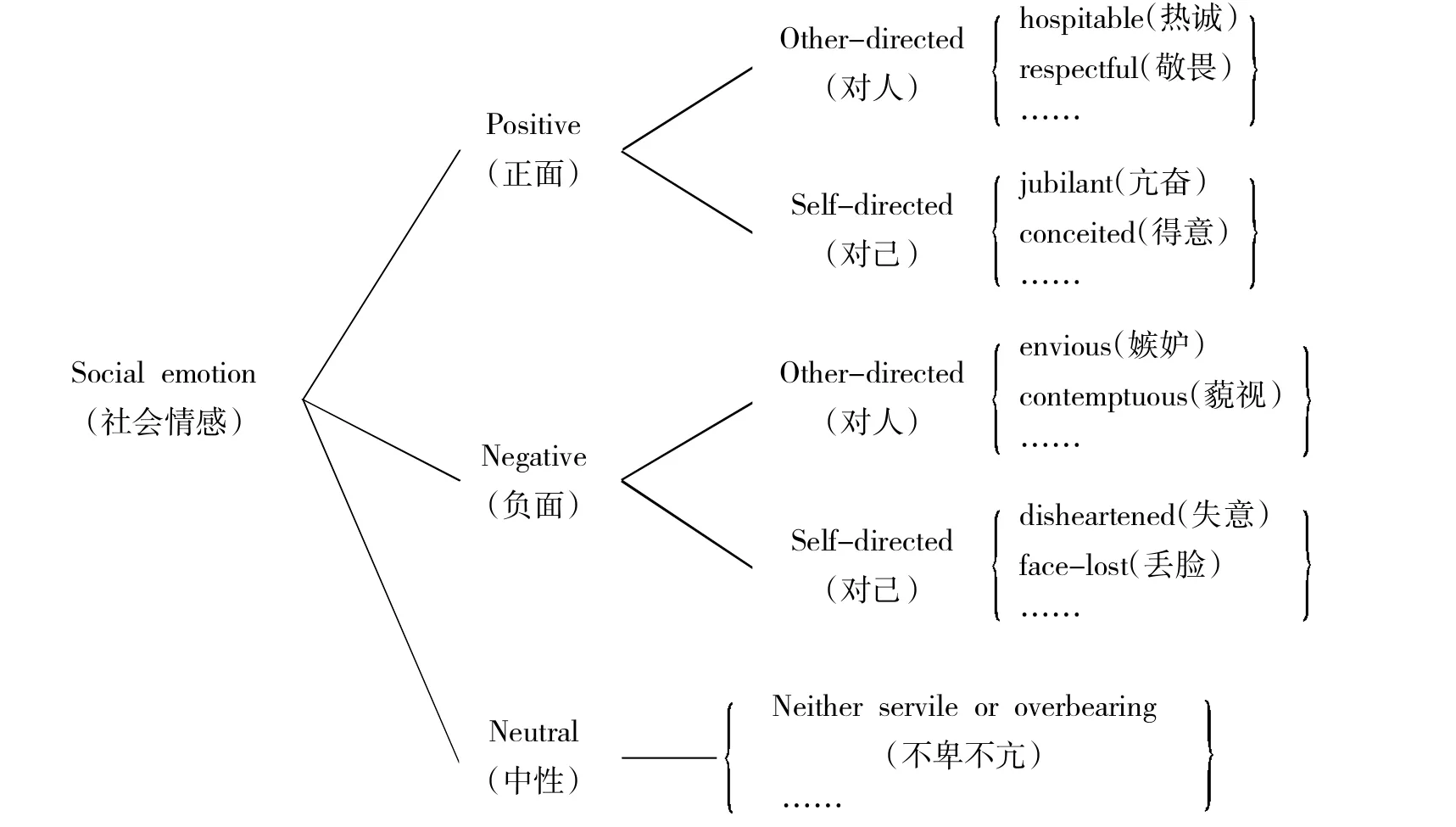
图2:社会情感分类(引自Gu 2013:324)
如Damasio强调指出的那样,这三种情感是层次上的分类,在现实生活中,它们是同时并行运作的。体况情感是基本情感和社会情感的基础(这就是Damasio称之为“背景情感”的依据。但我们称之为“体况情感”是从观察者的角度命名的,跟我们的研究方法协调一致起来)。当下情感要受到性格情绪的影响的,这不必说了。
5.鲜活话语中的“貌”
鲜活话语中的貌极其丰富。本文只限于跟上面定义的与言、思、情相关联的体貌。貌包括姿势(坐姿、站姿)、脸部表情、眼神、触目、手势、头部动作、腿部动作等。貌可以跟言思情貌分别关联,比如,紧盯别人看这个貌就泄露盯人者的思的信息,手部抖动这个貌一般跟激动或气急相关联,跟体况情感也有关联,如因年岁高或体弱也会引起手部抖动。
至此,概念建模对言思情貌整一作了初步的界定。下面概念建模需要更加深入细致,用术语说,即提高概念建模的颗粒度。
五、言思情貌整一:概念建模(下)
1.八个基本格局
言思情貌整一是默认状态,是四个“己”协调和谐的状态。在现实生活中,鲜活整人出于各种考虑,会让四个“己”不协调,不和谐,以至于冲突。下面我们先从默认状态出发,再分别探讨七个变体,累计统称为八个基本格局。
格局一:言思情貌整一(默认态,如图3所示)。说话人说出来的话,其内容跟脑中所想的、心中所感受的、体貌神色所流露的完全一致。在人们日常生活里,说某人是“表里如一”,或跟某人是“推心置腹”,用本文的话说,这个人是执行言思情貌整一原则的模范。
格局二:言思不合(如图4所示)。分早期幼儿和成年两种情况。早期幼儿因语音和声调还不成熟,发出的言只能表达部分内容,非语言的声音、体貌、神色、动作和场景信息等协助传达脑中所想和心中所感。
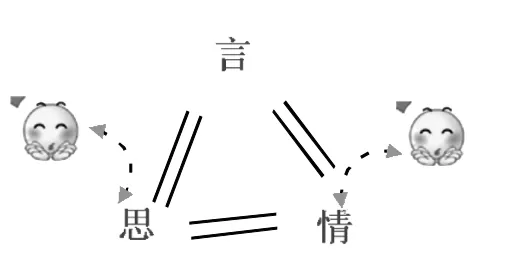
图3:言思情貌整一
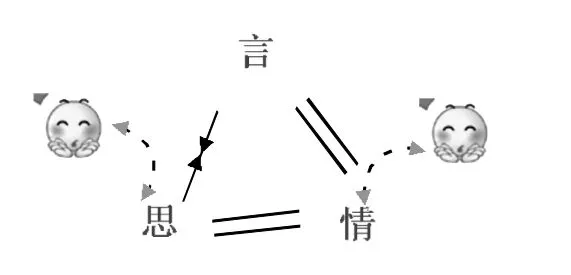
图4:言思不合
当幼儿可以通过言表达自己时,也有言思不合的例子,比如撒谎。儿童与电动小火车玩具的实验证明这一点(见图5a,图5b,图5c):实验员问被试刚才有没有扭头看小火车,被试儿童为了得到小火车奖励品都说“没有”。“没有”这个言跟真实的思是矛盾的,被试知道自己在撒谎。仔细观察被试在说“没有”时,其不定的眼神(即貌)已经外泄了矛盾的思。

图5a:背对行驶的小火车

图5b:扭头看背后是什么东西
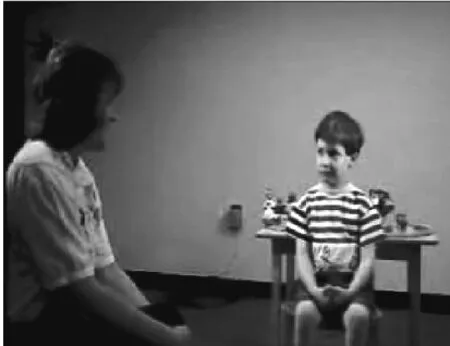
图5c:问有没有扭头看,说“没有”
成年人脑中的思跟言的内容不匹配,即口不应心,就是通常所描述的“有口无心”。比如说话人说“祝贺你得了第一名!”时,与“祝贺”语力相配对的有个思,他心中认为听话人(即获第一名者)所得其所。如果他不这么想,那么,就出现言思不合的情况。大选失败者祝贺获胜者,如果他心里真的认为对方赢得值得,那么他的言与思契合。如果他在祝贺对方时,心里还是气不忿,那么他是言思不合。
情和貌一般是受制于思的,有什么样的思,就会引发相应的情与貌。鉴于此,当成年人有口无心时,他是很有可能被识破的。成熟的政治家大选失败后祝贺获胜者,即便是有口无心,也能控制情貌,不失风度。
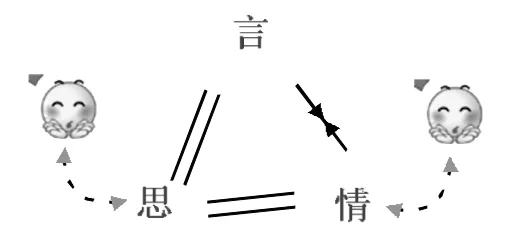
图6:言情不合
格局三:言情不合(如图6所示)。也分早期幼儿和成年两种情况。当幼儿语音虽全但声调还不发达时,韵律还不能完全表达情感,需借助体貌神色传达心中所感。
在成年人话语中,当相随情感为负面情感时,成年男性比女性较易出现言情不合的情况,比如说到伤心处女性容易边泣边说(言情切合),而“大”男子则很少有这样的情况。
在叙述往事时,言情不合男性和女性一样都是容易做到的。下面是语料库中的实例。一位电台主持人上个世纪80年代末下海,晚上到某夜总会当主持,后来讲述这段经历时说:
(2)……那个楼梯两侧从上到下\小姐一二百个齐刷刷站在那个地方\你从中
言情不合是相声里常见的修辞方法。下面是郭德纲与他的捧哏的对话:
(3)郭德纲:将心比心,人家这次保外就医……
捧哏:……什么保外就医呀,合着你说半天搁在里押着呢我。
捧哏对郭德纲的言很“生气”,反唇相讥“质问”郭德纲,说话时抬高嗓门,一脸生气的样子。由于捧哏的生气是假气,即与质问语力并不切合,因此质问也就成了有口无情的质问了(参见下文第七(4)节的进一步分析)。
格局四:言思情双脱节(如图7所示)。分两种情况:一是客观原因脱节,二是有意脱节。说话人由于种种原因(如紧张、结巴等)不能完全表达自己,需借助体貌神色传达脑中所思,心中所感。这种情况在有智障或发育不健全的儿童中才会出现。另外低水平的朗读、转述他人的话、新闻广播等,往往是言思情脱节。
有意脱节即以言遮盖真思、真情,昧着良心说话。赵匡胤说(据史官):“不是我要当,是他们硬把龙袍披在我身上!”说这句话时,赵匡胤的真实的思是:我想当;真实的情是:欣喜。而不是言所传达的“不想当”这个思以及无奈的消极情绪。
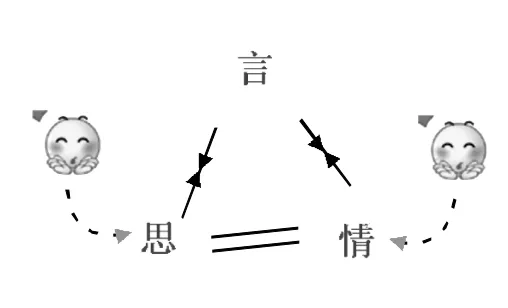
图7:言思情双脱节
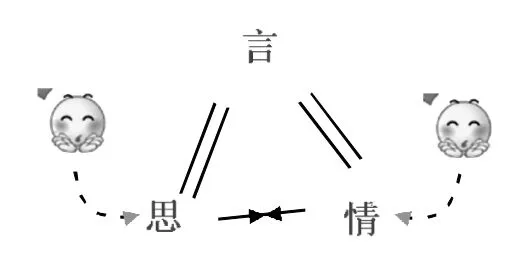
图8:思情不应
格局五:思情不应(如图8所示)。说话人说出来的话传达一种思、一种情,这个思和情说话人也有。但说话人还有一种思,跟情不配。本人对此有切身体验。本人在下放劳动时,时而去看姑妈,她总要留我吃饭。留客的话语还算是言真意切。但她的家境并不宽裕,招待人是要花钱的。她想到这个思,跟她要留客的情冲突。我从她不执意挽留以及双手拉我的力度上知道她矛盾的心理,她的貌还是透露了她的实情。
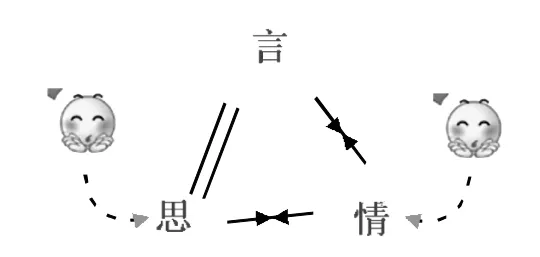
图9:言情、思情不应
格局六:言情、思情不应(如图9所示)。说话人说出来的话,其内容跟脑里所想的是一致的,但言的内容所要配的情,以及思所要配的情不一致。这种冲突在体貌神色上会流露出来。
演员表演喜或悲的内容,心中也真想着喜或悲的事,但情感上做不到,韵律运用上也不能传递真情和真思,结果是演技拙劣。反之,小丑、相声演员则利用言情、思情不应产生滑稽的效果。
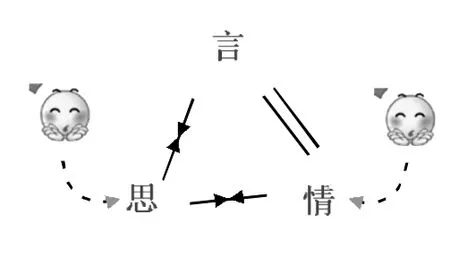
图10:言思、思情不应
格局七:言思、思情不应。与话语的语力所匹配的思,跟脑中实际的思不一致;言的声韵似乎传达跟语力所匹配的情。实际的思跟声韵所传达的情之间不协调。比如职业讨饭的话语,其语力是“乞讨”,与此语力相匹配的思如“我贫困”、“我饥饿”,相匹配的情是负面的,如基本情感哀、悲等。职业讨饭者在乞讨时真实的思和情都不是上面跟语力相匹配的。为掩盖言思、思情之间的冲突,貌上装出一脸苦相,以饰真思、实情。
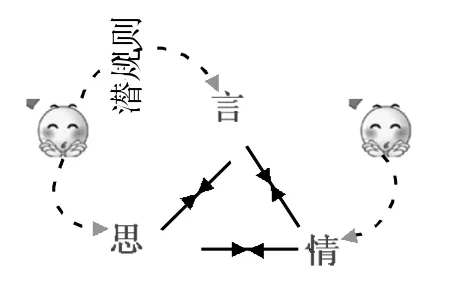
图11:言、思、情甚至貌不应
格局八:言、思、情甚至貌不应。跟语力所匹配的思和情,与真思、真情不切合;而且真情与真思也不协调。在现实生活里,“阳奉阴违”,“两面三刀”描述的就是这个格局,说话人具有官私双重人格。除话语活动的当下场景知识外,还需要调用潜规则知识,才能看到事物的真相。
2.局限与不足
为了叙述的方便,我们把“言”简化为较短的一句话所承载的语力。语力是个很复杂的现象,有些语力需要几句话来承载。本文无法展开论述(参见Gu 2013)。
我们以言为轴心来讨论思、情、貌。在实际话语活动中,有言未发而情先起的情况,甚至“气得连话都说不出来!”同样,貌也有先于言的情况。刘邵《人物志》写道:“言未发而怒色先见者,意愤溢也”;“言将发而怒气送之者,强所不然也”。这些复杂情况本文也无法展开讨论。
六、言思情貌数据建模、操作与评估
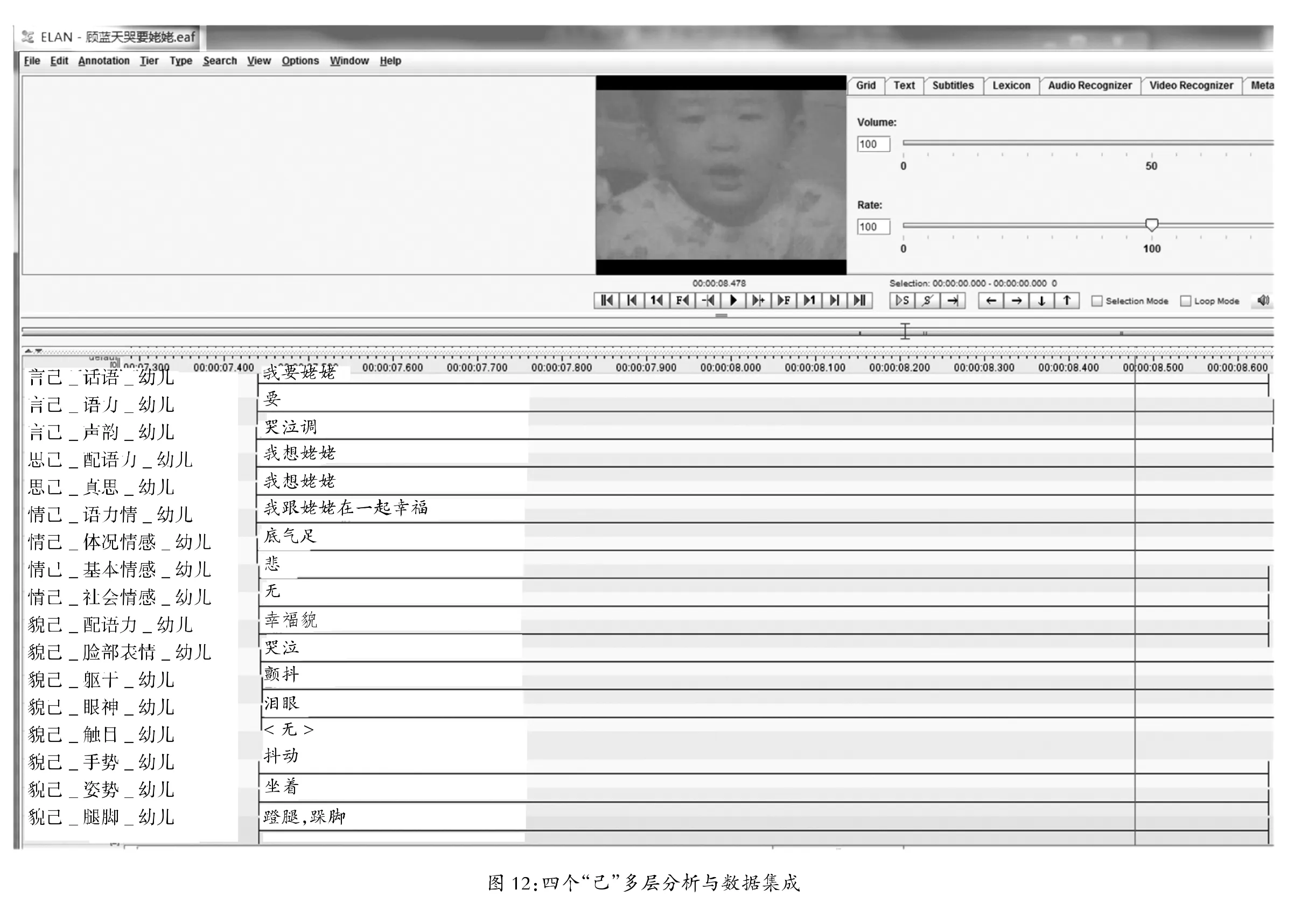
上面分析的八个基本格局是对整人从四个角度——言己、思己、情己、貌己——在概念建模上做的细化工作。如上所指出的,“己”实际上是动态的,后面有{…},需要填加数据,对其做实证研究。这是本节的任务。因篇幅有限,本节只能以“我要姥姥”一个实例来演示数据建模与操作。
三岁半的男孩当被告知带他三年多的姥姥去了美国后一边大哭一边说:“我要姥姥。”根据概念模型,我们要对“我要姥姥”分言己{…}、思己{…}、情己{…}和貌己{…}四个角度作数据模型。四个视角的“己”又分别细化如下:
言己:言己-话语,言己-语力,言己-声韵;
思己:思己-配语力,思己-真思;
情己:情己-配语力,情己-体况情感,情己-基础情感,情己-社会情感;
貌己:貌己-配语力,貌己-脸部表情,貌己-眼神,貌己-躯体,貌己-姿势,貌己-
接目,貌己-手势,貌己-腿脚上面这四个“己”在现实生活的整人中是同时存在和运作的,在数据建模上我们通过时间轴作数据同步集成来构拟。图12(见下页)显示的是用ELAN这个工具实现的多层次数据分析和同步集成。有四点需要说明:
(a)“要”这个语力在实例中是没有被满足的。跟语力相匹配的“幸福”这个正面情感因语力没有得到满足而化为负面情感。另外,跟语力相匹配的“我想姥姥”这个思使得负面情感变得更加强烈。对于一个三岁半的幼儿来说,因语力挫败引发的言思情之间的冲突在心理上是无法承受的,貌上的“大哭”和“全身颤抖”所传达的负面情感是化解冲突的唯一渠道。这个实例从反面验证了幼儿话语是言思情貌整一的。
(b)社会情感是在社会化过程中逐步形成的,早期幼儿还没有此类情感。
(c)本例中“言己-声韵”没有细化分析,因为幼儿是边哭边说的,特征提取很难。
(d)貌己-配语力本应该是高兴貌。因语力没有产生其效果,导致实际上的悲伤貌。
七、言思情貌整一原则与格莱斯的会话合作原则
本节讨论与言思情貌整一原则相关的理论问题。言思情貌整一原则在表达方式上仿照格莱斯的会话合作原则。这不是说言思情貌整一原则只能如此表述,完全可以用其他的表述方式。本文之所以仿照格莱斯的表述方式,出于几个考虑。本节主要阐述两者之间的关系及异同。
1.言思情貌整一原则
根据上面贴真建模分析,我们有条件把言思情貌整一作为修辞学的一个原则提出来。现陈述如下:
在人际互动中,力图做一位言、思、情、貌协调和谐之人。若如此,则需做到:
1)言由衷——言次则
2)思透明——思次则
3)情真切——情次则
4)貌自然——貌次则
在鲜活的交往中,当听话人发现说话人言不由衷,或思不透明,或情不真切,或貌不自然(如出现上面分析的七个基本格局),那么说话人就违背了上面的言思情貌整一原则,听话人就会作出超出常规的诠释,生成言外之意,弦外之音,并对说话者其人作出新的评价。
2.言思情貌整一原则与“知言”、“知人”
对言思情貌整一现象的研究,在我国古代虽然没有这么明确提出来,然而先贤对“知人”、“知言”很关心,如《论语·尧问》:不知言,无以知人。对于本文来说,“知言”、“知人”就是从听话者的角度探讨言思情貌整一问题。《周易·系辞下》(中华书局,2009年。下同)有这样一段识人的话:
将叛者其辞惭,中心疑者其辞枝,吉人之辞寡,躁人之辞多,诬善之人其辞游,失其守者其辞屈。
这段话的内容,按本文的分析思路,讲述了言(即“辞”)、思(即心理状态如“将叛”)和言应思后产生的、经过听话人“知言”处理后的效果(如“惭”、“枝”)。知言是作为知人的一个渠道。图13显示本文对上面引文的重新分析:
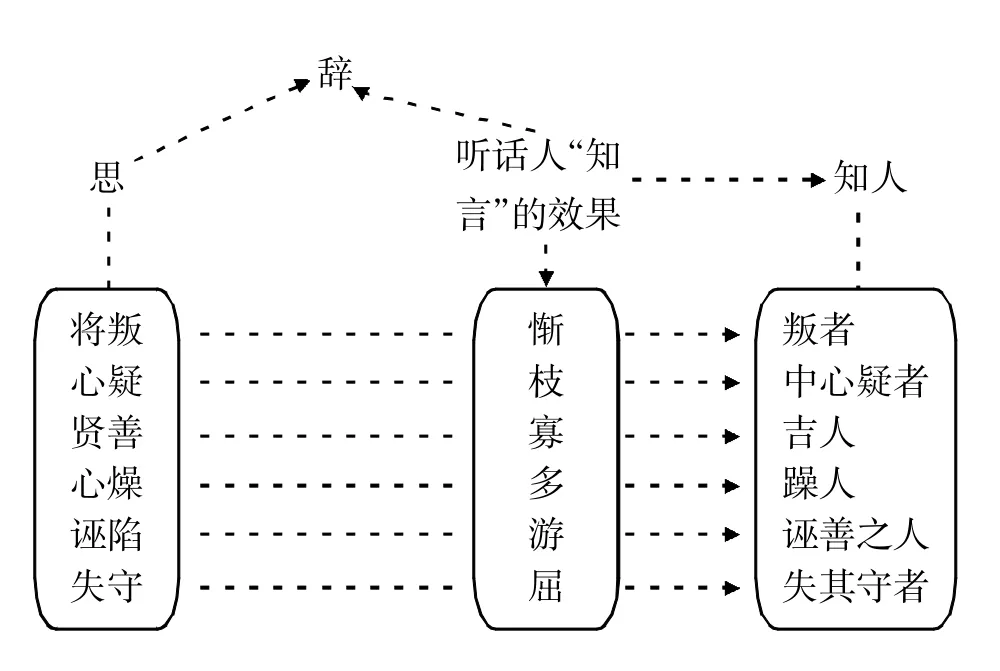
图13:《周易·系辞下》知人的重新分析
《礼记·乐记》涉及情、物、声三者之间的互动关系:
乐者,音之所由生也;其本在人心之感于物也。是故其哀心感者,其声噍以杀。其乐心感者,其声啴以缓。其喜心感者,其声发以散。其怒心感者,其声粗以厉。其敬心感者,其声直以廉。其爱心感者,其声和以柔。六者,非性也,感于物而后动。
用本文的话说,这段论述涉及情与言中的声韵之间的关系。“哀心”即本文说的哀情,跟哀情相匹配的是“声噍以杀”这个声韵特征。其余类推。图14演示本文对上述引文的重新分析:
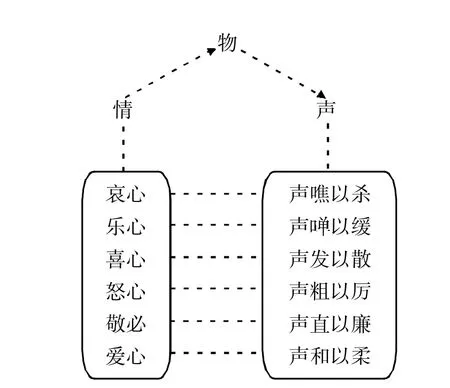
图14:《礼记·乐记》涉及情、物、声的重新分析
《吕氏春秋》有君子“论人”,非常精当。君子论人要“反诸己”(如先审视自己是否是以公心论人),“求诸人”(即审视他人)。求诸人包括“外”和“内”两个方面。其中“外”可归纳为“八观”、“六验”,如图15所示:
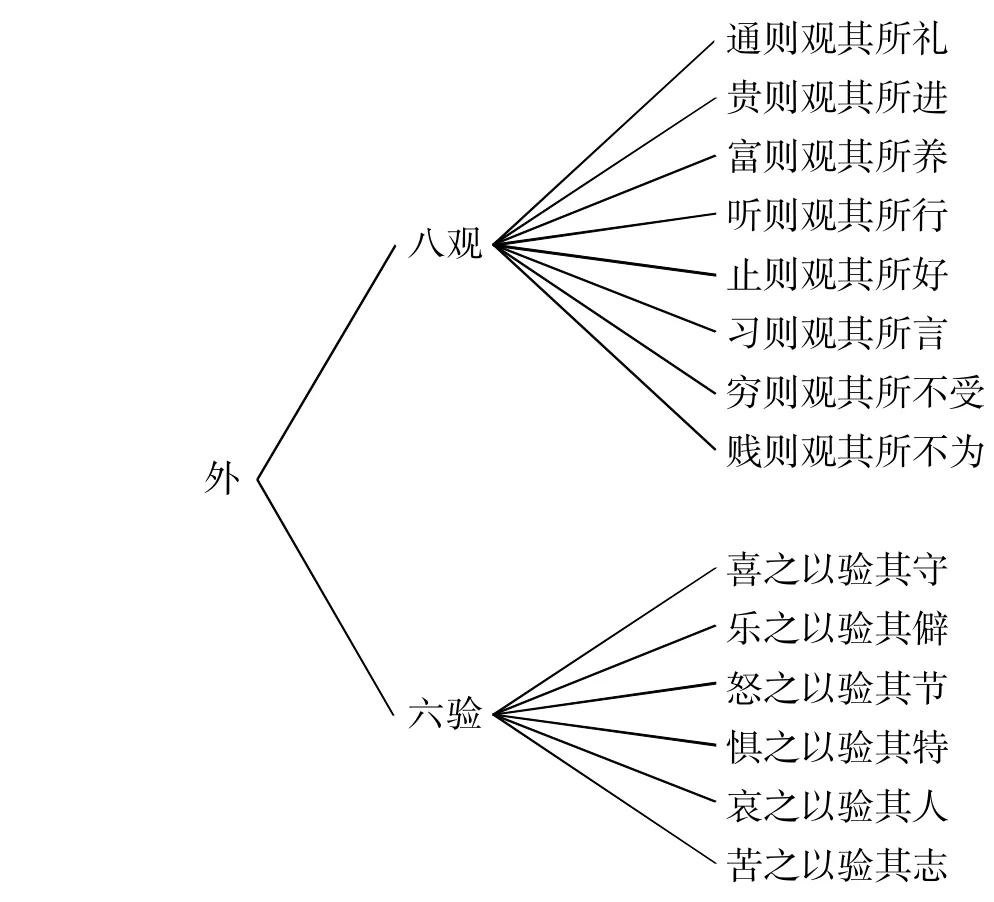
图15:《吕氏春秋》论人的八观和六验
八观里包括言、思、行等,六验专门讲情与人的关系。《吕氏春秋》论人的特点是把言、思、情、行跟人品、人格联系在一起。本文的言思情貌整一原则的研究相比之下只限于在当下话语中鲜活的人,没有拓展到较长期的人品、人格。这正是今后研究的方向。
刘邵《人物志》谈识人,也有八观,内容跟《吕氏春秋》不同,在此略过。值得一提的是,跟《吕氏春秋》一样,刘邵所讲的“识人”,也是识人品、人格。全书涵盖了吕氏的八观、六验的内容。另外,《人物志》对言、情、貌之间的关系,有相当精当的论述,如“征神见貌,情发于目,故仁,目之精、然以端”(《人物志·九征篇》),“其言有违,而精色可信者,辞不敏也”(刘邵《人物志·八观第九》)。
3.格莱斯的会话合作原则
该原则国内介绍很多,为了保持行文流畅,本文通过样例分析来简要回顾他的理论。格莱斯自己的一个例子是这样的:某教授被邀请给他的哲学学生写封推荐信,教授这样写道:“……该先生英语出色,经常参加导师讨论会。”邀请方如何诠释此信的内容?格莱斯建议的邀请方推理过程是这样的:
教授跟我们是合作的。他在写此信时本于合作精神一定会把他所知道的关于该生的信息毫无保留地告诉我们。然而这寥寥两句推荐语显然不是他所知道的全部信息,有悖于合作精神。但是我们没有理由怀疑他的合作精神,他一定有些难言之隐不便直说。那么他的言外之意恐怕是,这个学生英语虽好,但哲学功底不够。
合作原则大意如下:人们在日常交谈中为了达到交流信息这一共同目的,双方努力合作。要达到合作,人们需要满足四个方面的条件,即量、质、相关性和方式,由此产生量准则(提供确如其分的信息)、质准则(提供真信息)、关联准则(提供跟话题相关的信息)和方式准则(把话说得清楚明了)。
这四个准则在内容上有点像我国学者谈论的消极修辞。英国修辞学家利奇就把合作原则及其四个准则视为修辞学原则(见Leech1983)。
4.知言、与言外之意的推理机制
我们知道,诗学、词话、修辞学等都十分关注言外之意,言尽而意远是作家追求的创作效果之一。在本文中,言思情貌整一原则从说话者的角度首先是个做人的原则,从听话者的角度,它用于知言以便知人。言外之意是从知言到知人这个过程中的一部分。
知言和言外之意都涉及推理。其推理机制是什么?这是一个非常复杂的问题,需要做大量的研究才有发言权。西方的诠释学、实用推理等有许多可资借鉴之处。本文在此无法细说。跟言思情貌整一原则有直接关联的是魏晋时期王弼的“得意忘象”和“执一统众”的思想。得意忘象是人们较熟悉的,本文在此略过。根据王晓毅的诠释,执一统众是王弼玄学本体论世界观在方法论上的体现。根据这个方法论,一切事物含“本”、“一”与“末”、“众”两个对立统一的层次。“本”、“一”为根干,“末”、“众”为枝叶。执“一”即抓住了根干,就能统领所有的枝叶(详细论述见王晓毅 1996:227-228)。
王弼把执一统众的方法论用于注释周易,取得空前的成功。
夫众不能治众,治众者,至寡者也。夫动不能制动,制天下之动者,贞夫一者也。故众之所以得咸存者,主必致一也;动之所以得咸运者,原必(无)二也。(王弼《周易略例·明彖》
每卦卦象和卦辞为统帅全卦的“主”、“一”;每卦的六爻及爻辞是“众”。虽各个爻辞的意义各不相同,但被卦辞的“主”义所统领,得到“统众”后的“一”个大义。
现在我们回到言思情貌整一原则上来。言思情貌整一原则是默认的“主”、“根干”、“一”,在现实生活中各种背离整一原则的情况(如上文谈到的七个背离的格局)是“众”。面对鲜活的各种“众”,我们只要抓住言思情貌整一原则这个“一”,就能执一统众,得到个整一的言外之意的诠释。
我们上面这样做是不是在削足适履,穿凿附会?不是。理由如下:
(a)王弼的本体论本文不敢苟同,但执一统众作为方法论用来对复杂的意义现象进行诠释,王弼自己的实践证明是成功的。
(b)上文演示的格莱斯会话含义推理机制,用王弼的话说,就是执“会话合作原则”这个“一”来统领违背原则后所产生的各种会话含义。
我们以上文提到的郭德纲与捧哏的对话为例,根据言思情貌整一原则,郭德纲对捧哏的话“……什么保外就医呀,合着你说半天搁在里押着呢我”假生气的推理机制,可构拟如下:
根据言思情貌整一原则,人们在日常生活场景中力图做一位言、思、情、貌协调和谐之人,为此他力图做到言由衷、思透明、情真切、貌自然。
相声演员在相声场景中,也要遵从言思情貌整一原则,以求反映现实生活。但相声场景相对于日常生活场景而言,前者为假,后者为真。就是说遵从言思情貌整一原则在假场景中是真遵从,但跟真场景相比则为假遵从,反之则弄假成真了!说白了,相声演员在相声场景中需要假戏真做,但不能过度,否则就回到日常生活中来了。
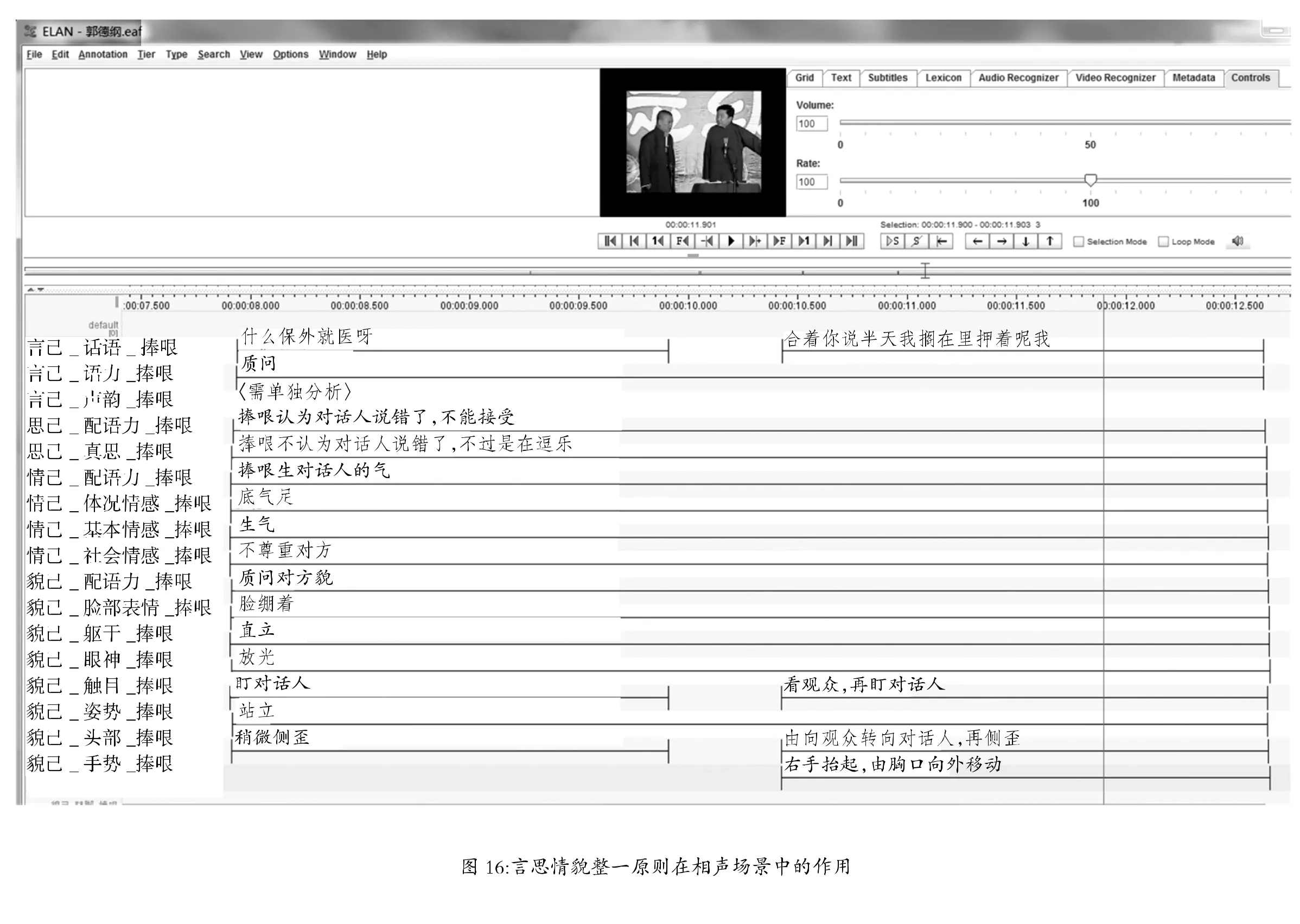
捧哏在相声场景里质问郭德纲时是真遵从了言思情貌整一原则。详细见基于视频流的分析(见图16),特别对捧哏的貌己的一系列分析,比如说话时“脸绷着”、“盯对话方”、“头侧歪”、“右手抬起,由胸向外划动”等。这些貌的特征都跟生气这个基本情感配对,生气这个情又跟“认为对方说错了,不能接受”这个思配对。另外,言除了在韵律上跟思和情匹配外,在句法上也跟思情匹配:“合着你说半天搁在里押着呢我”是个倒装句式,“我”放到了句末,很贴切人在生气时说话的样子。
捧哏在相声场景里遵从言思情貌整一原则,如果恰到好处,则反应了他高超的演技。反之,则是拙劣的业余水平。郭德纲知道捧哏的“质问”不是真的,除了场景知识外,捧哏的适度的声韵、体貌特征都提示这一点(我们用Praat对下页图16中的“言己_声韵_捧哏”这一层单独作分析,因这项颗粒度更高的分析很占篇幅,本文略去,对本文的立论没有影响)。
言思情貌整一原则用于日常生活场景时是默认“一”,执之以统领日常生活中各种违背后产生的特殊“众”多的意义。当言思情貌整一原则在各个“众”多的场景中时(如上面的相声场景),它仍然起着“一”的作用,但跟默认状态相比,它还是默认“一”下面的“众”。儿童对这类换位推理机制不容易掌握,易犯真假难辨的错误。
5.整一原则与合作原则的不同之处
至此,本文提出的整一原则不同于格莱斯合作原则的地方就很容易看清楚了。格莱斯的合作原则是建立在一个“理性人”(rational man)之上的。他的理性人是这样的:假如谈话双方有一个共同的目的,如最大程度上与对方交流信息(maximum exchange of information),那么,为了达到这个共同的目的,谈话双方自然要跟对方合作。为什么说“自然”要合作?因为人是有理性的,他总是做有利于达到自己目的的事,不可能做跟达到自己的目的相反的事。假如不是这样,这个人肯定是失去理性,正像一个人的目的地是去北京而向北京的反方向走去那样。这就是理性的行为逻辑(格莱斯提出会话原则的文章,其名字就叫“logic and conversation”,见Grice1987)。
整一原则是建立在一个懂世故人情的、鲜活的人的基础上的。情在整一原则里是很重要的,在格莱斯的合作原则里只字未提。合作原则里的质准则(即说真话)跟整一原则里的“思”也是不同的。整一原则里的“真思”随说话人的语力来确定,说话人同时可以有“真思”和“假思”两种情况,这在格莱斯合作原则中是不可思议的。鲜活的人的确有这样的情况。
八、结 语
我国修辞学研究的主流一直是放在跟书面文字相关的修辞上。少量文献在研究口语中的修辞现象时,往往把口语看作一种不同于书面语的语体来研究。此类文献研究者都熟悉,无需赘言。本文不用“口语”这个提法,而用“鲜活话语”(situated discourse)这个提法。其理论意义在哪里?有兴趣的读者可参阅拙作Gu(2009b,2010)。研究鲜活话语中的修辞,研究什么?本文试图回答这个问题。如果用一言概之,就是。如何做人,这是伦理学的问题。做人与修辞的关系则是修辞学问题。言思情貌整一原则是关于修辞与做人的关系的一个理论建构。通过上面的粗略分析,本文想传递这样一个信息,修辞与做人的关系是我国的经典命题,修辞学立论的基点是“人”,是鲜活的、通人情世故的整人,包含但不等于抽象的、像格莱斯那样的“理性人”。
如果上面的观点是可以接受的话,那么本文只是画了块地而已,遗留有待解决的问题很多,其中突出的如言、行、果与做人的关系问题。这也是我国经典的修辞学问题,本文没有涉及,只能待另文讨论。
注 释
①该库建设为中国社会科学院重大课题,已经结项,还没有正式对外发布。有关信息可参阅顾曰国(2002),Gu(2002)。亦可访问 www.multimodalgu.com.
②语力是西方语言哲学和语用学研究的经典课题,已经有半个世纪以上的历史。本文在这里不可能对该项研究进行文献梳理和综述,可参阅顾曰国(1989,1994a,1994b)。上面的表述是本人近期的研究体会,详细见拙文Gu(2013)。
③本文的真实语料全部来自“现代汉语现场即席话语多模态语料库”,参见www.multimodalgu.com。
④《礼记》的七情跟中医的七情和佛教里的七情有所不同。请读者注意。
