普通话双音节词表在听力正常青年中的复测信度分析*
2012-12-04吴丹张华王硕武文芳
吴丹 张华 王硕 武文芳
1 首都医科大学附属北京同仁医院,北京市耳鼻咽喉科研究所(北京 100005);2 首都医科大学生物医学工程学院
言语测听可为听力损失患者的咨询及需求评估提供参考,并便于了解其助听后的康复效果[1]。一套好的言语测试词表必须具有良好的信度(reliability)和效度(validity),才能用于言语评估。评估听力干预对言语理解能力改善的效果涉及到词表的复测信度,即听力干预前后该词表测试结果的差异是否有统计学意义,是否能证明听力干预有效。双音节词言语测试在临床上有很广泛的应用价值,它可以检查纯音测听结果的准确性,考查患者对言语的敏感性并得到言语识别阈(speech recognition threshold,SRT),以决定阈上给声强度;也可以测试言语识别率,用于评估人工听觉装置的效果。言语识别率较言语识别阈测试方法统一且简单,应用更广泛;复测信度评估常用言语识别率的变异范围评估,其有理论的数学模型,为此,本研究采用具有等价性的双音节词表言语识别率测试进行复测信度评估[2],旨在得出复测信度的参考指标,在同表等价的基础上保证其测试结果的可靠性,对词表进行标准化。
1 对象与方法
1.1 测试材料 采用张华等[2]编制的普通话言语测听材料(mandarin speech test materials,MSTMs)中具有等价性的9张普通话双音节词表(每表50个双音节字)作为言语测听材料。另有练习表一张,测试项11个,练习表中的测试项与9张双音节词表中的测试项没有重复。
1.2 测试对象 测试对象为18~27岁青年人32例(32耳),平均年龄23.41±1.88岁,其中男15例,女17例,左耳17例,右耳15例;均为大学本科及以上学历,日常交流方式为普通话,无耳科疾病史且近期无上呼吸道感染,纯音听阈均在正常范围(双耳250、500、1 000、2 000、4 000和8 000Hz纯音气导听阈≤15dB HL),鼓室导抗图均为A型,均能引出声反射。受试者均首次接触此词表。
1.3 测试地点及设备 测试地点为北京同仁医院耳鼻咽喉科临床听力学中心标准双间隔声室,本底噪声<20dB(A),测试人员与受试者同室测试。言语测听材料的言语信号通过Lenovo计算机声卡输出,送入MADSEN OB922听力计输出至MADSEN Telephonics 296D000-1压耳式耳机,经单侧耳机传递给受试者。将1.0kHz纯音作为校准音,使用B&K 2209型精密声级计、B&K 4145电容传声器和B&K 4152型仿真耳(设备经北京市计量科学研究院校准)校准设备与声场,参考国标GB/T 7341.2-1998将0dB SHL言语听力级校准为言语声强级(20dB SPL)。
1.4 测试方法 运用首都医科大学生物医学工程学院与北京同仁医院联合开发的汉语言语测听智能化系统[3,4],在智能化软件中选择手动选表、手动操控给词的测试方式。每张表中各个词的测试顺序由智能化软件控制随机给出。言语信号通过软件经电脑输入听力计Channel 1,然后经单侧耳机传递给受试者。以受试者500、1 000、2 000和4 000Hz气导平均纯音听阈(pure tone average,PTA)较好耳为测试耳。
预测试:选择5名受试者进行预测试,找出得分正确率为40%~60%的给声强度。采用下降法,对9张表分别以2dB为步距,根据每名受试的纯音平均听阈(PTA),从PTA+14dB HL到PTA-2dB HL范围分别给声。5名受试者分别从第1、3、5、7、9张表开始,依次测试完九张表,最后得出每名受试者的固定给声强度为各自的阈上4dB,即PTA+4 dB HL。
正式测试:本测试所用的9张普通话双音节词表顺序采用拉丁方设计(表1),27位受试者随机进入实验,反应方式为受试者听到测试词后复述出来,当受试者没有听清楚测试词时,鼓励猜测。
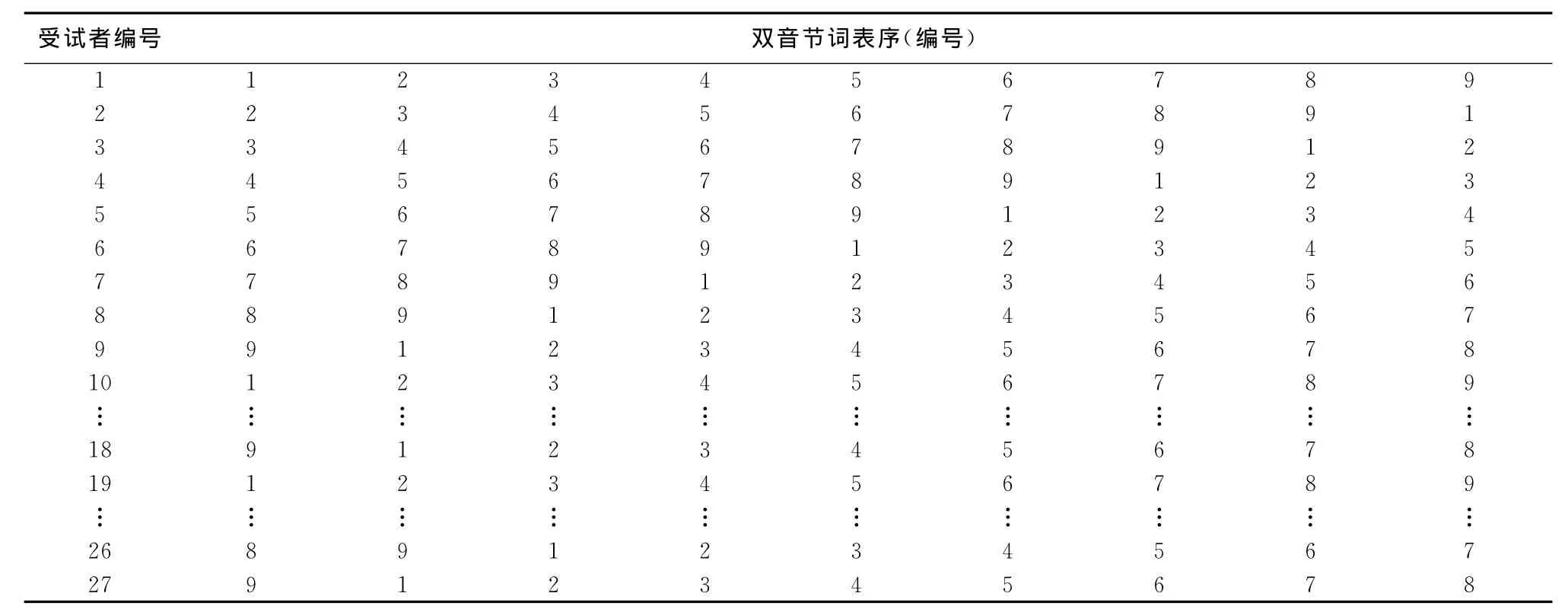
表1 27例受试者MSTMs双音节词表播放顺序
27名受试者复测时间间隔7~28天,平均14天,以完全相同的实验条件(相同地点、相同强度、相同测试顺序等)对每名受试者进行第二轮测试。
1.5 计分方式 采用“全或无”的方式,所用智能化软件会自动计算该表识别率。双音节词中两个字声母、韵母及声调均复述正确得一分,无反应、声母错、韵母错或声调错均计为0分。每张词表的言语识别率得分=(复述正确词数/总词数)×100%。
1.6 统计学方法 本实验得分率范围0%~100%。识别-强度(performance-intensity,PI)函数曲线上50%左右得分率变异最大,而在两端得分率变异度最小,各个得分率的随机误差是不一致的[5]。因此,Studerbaker提出了一种对识别率分数进行“合理化”反正弦变换(“rationalized”arcsine transform)的方法[6],采用SPSS17.0软件计算每张表两次得分差值及其变异程度,进行复测信度评估。
2 结果
经正态性检验,各表复测和初测得分都符合正态分布。9张表总体的复测和初测的言语识别率分别为52.40%±13.82%和50.74%±13.51%,复测和初测得分平均差值仅为1.66%。对每张表得分进行复测和初测的配对t检验显示,各表复测和初测结果差异无统计学意义(P>0.05)(表2)。
表2 27例受试者9张MSTMs双音节词表复测、初测言语识别率比较(%,±s)
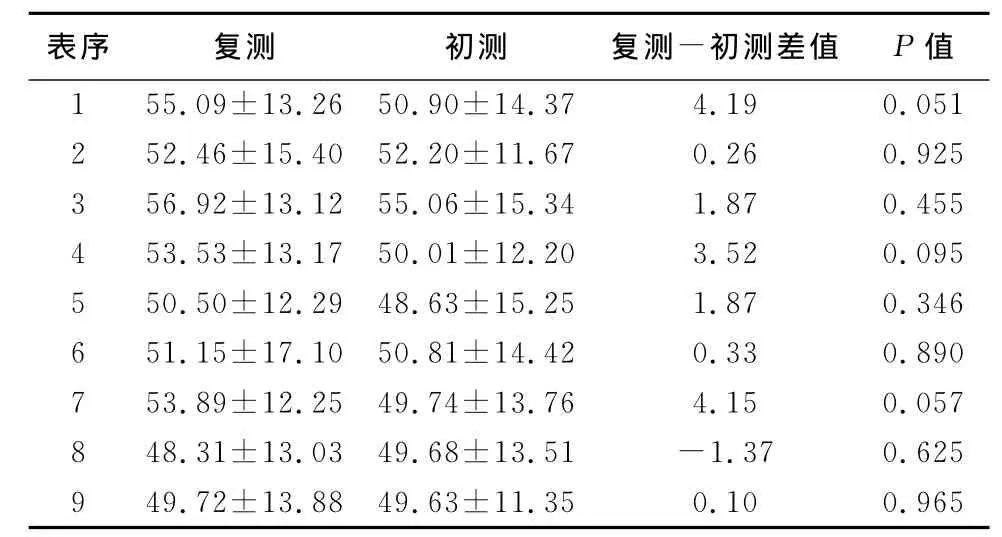
表2 27例受试者9张MSTMs双音节词表复测、初测言语识别率比较(%,±s)
表序 复测 初测 复测-初测差值 P值1 55.09±13.26 50.90±14.37 4.19 0.051 2 52.46±15.40 52.20±11.67 0.26 0.925 3 56.92±13.12 55.06±15.34 1.87 0.455 4 53.53±13.17 50.01±12.20 3.52 0.095 5 50.50±12.29 48.63±15.25 1.87 0.346 6 51.15±17.10 50.81±14.42 0.33 0.890 7 53.89±12.25 49.74±13.76 4.15 0.057 8 48.31±13.03 49.68±13.51 -1.37 0.625 9 49.72±13.88 49.63±11.35 0.10 0.965

表3 9张双音节词表初、复测结果差值的标准差及临界差值(%)
根据各表在两轮测试中各自识别率得分的差值,逐表统计该差值在27名受试者中的标准差(standard difference,SD),并换算成95%置信度下的临界差值(critical difference,CD)=SD×1.96(表3)。可见,该套词表总体标准差为12.0%,总体临界差值为23.6%。
3 讨论
3.1 实验设计 本研究中所采用的9张测试词表的顺序采用拉丁方设计,对于不同受试者将测试词表顺序循环排列,避免某张表总是在最前或最后,测试期间间断休息,这样可避免疲劳测试使言语识别率降低[7]。本研究通过预实验找出得分正确率为40%~60%的给声强度为测试强度,既可以比较灵敏地判断出得分的差异,又避免了得分最差的地板效应(floor effect)和得分最高的天花板效应(ceiling effect)。
本实验采用的是受试者口头复述、测试者即时记录的方式,所以实际听力测试不仅受到受试者反应的影响,也受测试者的听力感知的影响[8]。因此,在更严格的试验中,可以在测试者记录受试者复述内容的基础上对受试者进行录音或录像,以提高测试结果记录的准确性[8]。
Bamford等[9]提出应该对同一受试者在相同的条件下进行测试,这样有助于去除仪器和人为因素的误差。本研究复测时测试者、测试地点、给声强度及词表顺序都与初测时保持不变,要最大程度的减少系统误差。然而,相对于纯音测听,重复言语测试面临一个不可避免问题,就是受试者可能会对测试材料有学习和记忆,即可能存在学习效应这种系统误差。理论上双音节词相对于单音节词有更多的冗余度,更易于学习记忆,但是本研究结果显示,各表的复测和初测得分差值均无统计学意义,表明该套词表并没有受到明显的学习效应的影响,证实了使用该套词表进行复测评估的可行性,复测和初测得分平均差值仅为1.66%,远小于临界差值23.6%,说明本研究较好地排除了系统误差的影响。
3.2 复测信度评估 信度指标关注的是测试结果的可靠性程度,它对于临床上选择什么样的测试材料、如何理解测试结果的误差范围都至关重要[10]。信度包括多张测听表之间的等价性(复本信度)和得分在多次测试中的稳定性(复测信度)。本研究通过对9张等价的双音节词表复测信度评估,得出复测和初测的言语识别率差异无统计学意义,证实了该套词表复测的可靠性,准确的评估测试结果。
言语测听材料复测信度评估的常用指标是临界差值(critical difference,CD)。重复测量获得的实际测量值往往并不能稳定在同一值,而是围绕某一个数值左右波动,这种误差称为随机误差。本研究设计时最大化的排除了系统误差,但是由于变异的存在,随机误差不可避免。复测信度体现的是这种随机测量误差,它通过计算受试者自身复测得分差值的标准差(standard deviation,SD)进行评估,这个SD值可用来确定得分变化的临界差值(CD=SD×1.96,95%置信度),只有大于该临界差值,才能确切地得出"两次言语识别率有差异"的结论。应用二项式分布理论,由50个彼此独立的、听敏度(audibility)上完全同质的测试项组成的测听表,其言语识别率在50%时所对应的临界差值为18.1%[11],即两次测试条件完全一致,测量的差值也将在此理论值范围内波动,此范围内的言语识别率变化不能表明结果存在统计学差异。
该套词表的临界差值为23.6%,略大于理论值18.1%。分析原因:①测试的给声强度为50%左右得分率,在PI曲线上变异最大,且双音节词较单音节词PI曲线斜率更大,故得到较大值;②参考值是将得分率作为二项分布来研究,但它的前提条件是测试项特征应具有完全同质性;50词的双音节词表在音位平衡、可懂度和言语听力级上基本达到一致;此外,对表内各测试项而言,受试者的状态、测试条件等也应彼此独立,而现实中这些前提条件不可能严格成立,所以实验结果与理论值存在一定的差异。
总之,本次研究初步验证了9张普通话双音节表具有较好的复测信度,在实验和临床应用中其评估言语识别的结果是可靠的。应用该套双音节表在正常人群中进行相关言语评估测试时,确认两次测试言语识别率有差异,其前后两次得分的差值应超过该临界差值(23.6%)。
1 Zhang H,Wang L,Wang S,et al.Speech and language evaluation for cochlear implant[J].Chinese Journal of Clinical Rehabilitation,2005,9:188.
2 Wang S,Mannel R,Philip N,et al.Development and evalua-tion of Mandarin disyllabic materials for speech audiometry in China[J].International Journal of Audiology,2007,46:721.
3 张华,王硕,陈静,等.普通话言语测听材料的智能化研究[J].中华耳鼻咽喉头颈外科杂志,2008,43:407.
4 Wu WF,Zhang H,Chen J,et al.Development and evaluation of computerized mandarin speech test system in China[J].Computers in Biology and Medicine,2011,41:133.
5 Thornton AR,Raffin MJ.Speech-discrimination scores modeled as a binomial variable[J].J Speech Hear Res,1978,21:507.
6 Studerbaker GA.A"rationalized"arcsine transform[J].Speech Hear Res,1985,28:455.
7 Mendel LL,Danhauer JL.Test administration and interpretation[M].In:Mendel LL,Danhauer JL.ed.Audiologic evaluation and management and speech perception assessment.Singular Publishing Group,Inc,1997.21~25.
8 邵广宇,张华,陈静,等.口头复述与书写反应方式对普通话言语识别率的影响[J].听力学及言语疾病杂志,2009,17:207.
9 Bamford J,Wilson I.Methodological considerations and practical aspects of the BKB sentence lists[M].In:Bench J,Bamford J,eds.Speech-hearing tests and the spoken language of hearing-impaired children.London,UK:Academic Press,1979.146~187.
10 郗昕,赵乌兰,冀飞,等.汉语单音节测听表在北京听力正常人群中的复测信度评估[J].听力学及言语疾病杂志,2009,17:98.
11 Raffin MJ,Thornton AR.Confidence levels for differences between speech-discrimination scores:a research note[J].Speech and Hearing Research,1980,23:11.
