基于Heritrix和Lucene的专题搜索引擎研究
2012-11-14贾超卫文学
贾超 卫文学
山东科技大学信息科学与工程学院,山东 青岛 266590
基于Heritrix和Lucene的专题搜索引擎研究
贾超 卫文学
山东科技大学信息科学与工程学院,山东 青岛 266590
专题搜索引擎也称垂直搜索引擎,主要用来满足特定领域的用户需求。Heritrix是开源的网络爬虫,Heritrix的WebUI启动方式并不易用于广大用户。本文改变了往常对Heritrix用法,摒弃了Heritrix的WebUI启动方式,对Heritrix源码进行修改,将Lucene整合到Heritrix中,构建成一个完整的搜索引擎,并通过监听器监听搜索引擎状态,使搜索引擎能够进行自动爬取和数据更新。同时,本文添加了网页过滤模块以及对查询结果排序算法进行了改进,提高了搜索引擎的易用性和查询的准确率。
专题搜索引擎;Heritrix;Lucene;排序算法
thematic search engine; Heritrix; Lucene; sorting algorithm
引 言
万维网上信息浩瀚万千,而且毫无秩序,所有的信息像汪洋上的一个个小岛,而搜索引擎正如一副地图可以让用户一目了然[1]。但在使用通用的搜索引擎时,返回的结果往往成千上万,用户需要花费大量的时间甄选自己真正感兴趣的信息,很难准确返回用户需求[2]。垂直搜索引擎正好为解决该问题,提出了很好的解决方案,它是一个针对某个行业的专业搜索引擎,是对网页库中某类专门信息的一次重新整合,为某一特定领域、某一特定人群或某一特定需求提供有一定价值的信息和服务[3]。
常见Heritrix的使用方法往往是通过WebUI方式启动并进行相应的爬取配置后,才能进行爬取。该方法并不容易被用户接受和使用,同时会爬取大量的冗余和无用的网页。本文通过将Lucene整合的Heritrix中,在网页下载前,进行网页过滤,并对查询结果排序的算法进行改进,提高了查询的准确率,搜索引擎会根据专题的相关配置信息进行自动的爬取和更新。
1 Heritrix与Lucene介绍
专题搜索引擎的实现过程,主要分为三个步骤:(1)抓取网页。(2)对网页进行处理,建立索引文件库。(3)进行查询。本文中使用Heritrix实现从万维网上抓取网页,Lucene负责对网页进行处理和查询。
1.1 网络爬虫Heritrix
Heritrix是一个由Java开发的、开源的Web网络爬虫,用户使用它从网络上抓取特定的网页或文档等资源[4]。Heritrix可以通过Web UI的方式来启动、设置爬行参数并监控爬行,其出色之处在于它的扩展性,开发者可以扩展它的各个组件,来实现自己的抓取逻辑。虽然Heritrix功能强大,但其配置复杂,而且官方只在Linux系统上测试通过,用户难以上手,这也是本文将要解决的技术难点之一。
Heritrix采用了模块化的设计,用户可以根据需要选择使用的模块。它主要由核心类(core classes)和插件模块(pluggable modules)构成。核心类可以配置,但不能被覆盖,插件模块可以由第三方模块取代。所以就可以用实现了特定抓取逻辑的第三方模块来取代默认插件模块,从而满足自己特定的抓取需求。Heritrix的整体结构如图1所示。

图1 Heritrix整体结构
其中CrawlController(下载控制器)是整个下载过程的总控制者,整个抓取工作的启动者,决定整个抓取任务的开始和结束。每个URI都有一个独立的线程,它从边界Frontier(控制器)获取新的URI,然后传递给Processor chains(处理链)交由系统Processor(处理器)处理[5]。
1.2 检索工具包Lucene
Lucene是一套用于全文检索和搜寻的开放源代码,由Apache软件基金会支持和提供[6]。Lucene提供了一个简单却强大的应用程式接口,能够实现全文索引和检索,是目前最受欢迎的免费java信息检索程序。Lucene最初是由Doug Cutting开发的,在SourceForge的网站上提供下载[7]。在2001年9月作为高质量的开源Java产品加入到Apache软件基金会的 Jakarta家族中。随着每个版本的发布,这个项目得到明显的增强,也吸引了更多的用户和开发人员。Lucene的各组件及工作如图2所示。
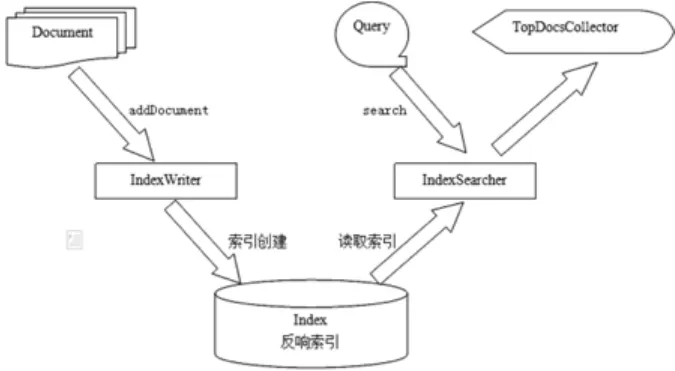
图2 Lucene的各组件及工作
Document对象代表被索引文档,IndexWriter通过方法addDocument()将文档添加到索引中,实现创建索引的过程。Lucene的索引时应用反向索引。当用户有请求时,Query代表用户的查询语句。IndexSearcher通过方法search()搜索Lucene Index。IndexSearcher计算term weight和score并且将结果返回给用户。返回给用户的文档集合用TopDocsCollector表示。
2 整合Heritrix与Lucene的专题搜索引擎
本文设计开发的专题搜索引擎具有以下四个技术创新点:专题搜索引擎自动运行、摒弃Heritrix传统的WebUI启动方式、网页过滤、查询结果排序算法改进。
2.1 专题搜索引擎设计和自动运行
本文设计的专题搜索引擎包括爬取器(网络爬虫)、索引器、查询器和控制中心四个模块。四个模块的运行协作关系如图3所示。

图3 专题搜索引擎模块运行协作关系图
爬取器主要负责网页爬取,为索引器提供索引文档;索引器负责对爬取的网页建立倒排索引,供查询器进行搜索;查询器负责用户查询;控制中心负责监听爬取器、索引器和查询器的运行状态以及根据专题配置信息启动爬取器或索引器,以实现专题搜索引擎的自动爬取和数据更新。
为了保证搜索引擎的自动运行和各模块间的协调工作,本文分别为爬取器、索引器和查询器设定了两种运行状态,0表示空闲状态,1表示运行状态。
爬取器与索引器的运行存在一定的顺序,二者不能同时运行,只有当爬取器运行完之后,才能运行索引器,若网页数据没有下载更新,索引器是不能继续运行的。因此,需要为爬取器和索引器设定运行状态,并在控制中心中设置监听器,定时监听二者的运行状态,协调二者工作。另一个问题是如何控制爬取器的自动运行,我们的解决方法是在数据库中保存搜索引擎爬取时间间隔取值,这里爬取时间间隔取值是指从爬取器上一次爬取完到下一次开始爬取之间的时间间隔。当监听器检测到爬取器处于空闲(等待)状态时,且爬取器等待时间超过数据库中设置的爬取时间间隔时,控制中心会启动爬取器进行网页爬取。
2.2 摒弃Heritrix WebUI启动方式
Heritrix的WebUI启动方式虽然广泛被开发人员使用,但其配置繁琐,不具备易用性。无法动态设置爬取网站和爬取深度,不能自动的持久运行,对于普通用户很难掌握并使用。本文摒弃Heritrix的WebUI启动方式,通过配置CrawlController类来启动抓取任务过。Heritrix启动核心代码如下:

SystemInfoDao负责读取专题的配置信息,比如爬取深度、种子链接等。HeritrixCrawlInfo负责保存每一次爬取任务的专题配置信息。当然,相关的配置信息是提前保存在数据库中的,为不同的专题提供不同的配置信息,避免了每次都要设置配置信息。
通过控制中心的协调以及摒弃Web UI启动方式,用户只需要配置相关专题领域的信息就可以高效的检索相关专题领域的信息,用户不在需要关心搜索引擎的启动和运行,方便了用户的使用。
2.3 网页过滤
当使用Heritrix爬取网页时,磁盘上会存放大量的网页文件,而且其中会有很多无用和冗余的网页信息,占用大量的磁盘空间。通过网页过滤,系统仅爬取与专题领域相关的网页,可以提高网页爬取的准确性和节省磁盘空间,即在网页下载到本地磁盘之前,对网页数据进行挖掘分析。Heritrix在下载某一网页或某一文档之前,我们先对该网页或文档对应的文本数据进行信息分析,判断是否包含相关专题领域的关键词,当然相关专题领域的关键词事先存储在数据库,由专业领域人员来设定。若该网页或文档包含相关专题领域信息,则下载该网页或文档,否则抛弃该网页或文档,继续处理其它链接。
2.4 查询结果排序算法设计
查询结果排序算法实际是指文档得分算法,为了提高查询的准确率,本文对文档的得分算法进行了改进。通层次分析法(AHP),为相关专题领域关键词设定权重(用weight表示),通过设定关键词权重,更能体现专题领域信息的专业性。当同一信息在多个网页或网站被转载或发表时,从侧面反映出其存在较高的价值和实用性。因此,本文在排序算法中引入了一项评估指标—网页信息重复率(用pac表示),网页信息重复率的权重通过德尔菲法(Delphi)来获取,同样我们引入传播范围这一评估指标,传播范围(用ptc表示)在本文中代表同一信息出现在多少不同的网站上,当然其权重同样是通过德尔菲法(Delphi)来获取。
本文将文档的最后的得分划分为两部分:Lucene原始文档得分和引进评估指标算法得分,两部分得分之和为文档的最后得分。Lucene的文档得分算法,具体公式如下:2.0[M].人民邮电出版社,2007.

tf的全称为Term Frequency,也就是词条频率的一次。idf的全称为Inversed Document Frequency,它表示反转文档频率。Boost指在建立索引时,对每个Field设置的一种激励因子[8]。
引进评估指标算法得分算法,具体得分计算如下:

两部分得分之后即为文档得分,查询结果按照文档得分的高低显示,当然文档内容重复率达到规定取值时,取文档得分较高者显示。最终通过引入新的得分算法,在一定程度上既能提高了查询的准确率又能降低了查询结果的重复率。
2.5 搜索引擎应用
本文设计开发的搜索引擎已被成功的应用到一涉腐舆情预警系统中。搜索引擎查询结果界面如图4所示。
图4 搜索引擎查询结果界面
3 结语
本文通过将Heritrix和Lucene进行有效的结合,构建成一个完整的搜索引擎。并通过对源码的修改和封装实现了专题搜索引擎的自动运行,用户只需配置相应的专题信息即可使用其检索功能,无需进行繁琐的配置和关心搜索引擎的运行。本文的主要创新点有专题搜索引擎的自动运行,易于普通用户的使用,提高了易用性;摒弃Heritrix的传统用法,避免了繁琐的配置过程;进行网页过滤,避免爬取大量无用的和冗余的网页信息,节省了磁盘空间;改进文档得分算法,提高查询的准确率和在一定程度上实现了检索去重。
[1]http://zh.wikipedia.org/wiki/%E6%90%9C%E7 %B4%A2%E5%BC%95%E6%93%8E
[2]李世明,赵恒永.专题搜索引擎研究与实现[J].电子科学技术评论,2005.
[3]高伟峰.基于Heritrix的主题网络爬虫设计与实现[J].南宁职业技术学院,2011.
[4]孟祥成.基于Lucene和Heritrix技术搜索引擎的设计与实现[J].中国现代教育装备,2010.
[5]http://www.chineselinuxuniversity.net/ articles/40890.shtml
[6]白坤,耿国华.基于Lucene/Heritrix的垂直搜索引擎的研究与应用[J].计算机应用与软件,2009.
[7]Erik Hatcher,Otis Gospodetic,Lucene In Action [M]. Manning Publications Co.2005.
[8]邱哲,符滔滔.开发自己的搜搜引擎Lucene
Research on the topical search engine based on Heritrix and Lucene
JIA Chao WEI Wen-xue
College of Information Science & Engineering , Shandong University of Science & Technology , Qingdao Shandong 266590 , China
thematic search engine, also known as vertical search engines, mainly used to meet specific user needs. Heritrix is an open source Web crawler Heritrix the WebUI start way is not easy for the majority of users. Changed the usual Heritrix usage abandon the way of the Heritrix of WebUI start Heritrix source code be modified to integrate Lucene into Heritrix build into a complete search engine, and through the listener to monitor the status of the search engine, search engines can automatic crawling and data updates. Meanwhile, the paper added Web filtering module, and query results sorting algorithm has been improved, easyto-use search engine and query accuracy.
TP393
A
10.3969/j.issn.1001-8972.2012.10.050
贾超(1989-),男,山东泰安人, 硕士研究生,主要研究方向为软件工程
