基于双栈的缓冲区溢出攻击的防御
2012-10-30陈林博江建慧张丹青
陈林博,江建慧,张丹青
(同济大学 计算机科学与技术系,上海 201804)
缓冲区溢出漏洞是困扰系统安全的最常见漏洞之一,近几年来所占比例不低于当年发布总漏洞数的10%[1].相比堆缓冲区漏洞和格式化字符串攻击的漏洞,栈缓冲区漏洞仍占多数,且攻击者利用栈缓冲区漏洞的手段多样化,攻击更隐蔽.
由于C及C++语言中指针的灵活操作与广泛运用,同时函数中存在没有做边界检查的缓冲区,并且Intel 80X86体系结构中栈的增长方向及栈中数据的增长方向相反,都为缓冲区溢出攻击提供了条件.目前,典型的栈缓冲区攻击方法有直接篡改函数的返回地址EIP和调用函数的栈基址EBP值、通过指针间接篡改函数返回地址等.防御缓冲区溢出最成功的方法有基于编译器优化的StackGuard[2]、基于操作系统优化的ASLR[3]和Non-executable stack[4]的组合方法.
本文首先从攻击者角度对存储在栈中的数据分类,并简要描述了栈缓冲区溢出攻击的两种模式.其次,阐述了现有栈缓冲区溢出防御方法及其存在的问题,在此基础上提出了基于双栈结构的缓冲区溢出防御模型,并分析其有效性.最后开发了一个针对ELF格式的目标文件重构工具用以实现双栈结构,以实验验证了双栈结构的有效性,并评估其性能.
1 缓冲区溢出攻击
缓冲区溢出攻击是指攻击者利用程序中存在的漏洞,向缓冲区中存入超过设计时定义的数据量,从而覆盖缓冲区相邻存储单元中的数据,使得程序在执行时跳转执行攻击者所指定的代码.因此可以将栈缓冲区溢出攻击总结为两种模式[5-11]:一是通过对缓冲区的溢出直接篡改EBP和EIP等关键数据;二是通过对缓冲区的溢出修改指针变量等,间接篡改EBP和EIP等关键数据.
通过对攻击模式的分析,可将栈中数据分为安全(security)相关数据和非安全相关数据,其中,安全相关数据包括各种保存在内存中的寄存器值,如:返回地址、EBP等,指针类型变量,指针数组、字符数组等各种数组变量,包含字符数组的联合体和结构体等.非安全相关数据包括整数类型变量、浮点数类型变量及其他攻击过程中不被利用的变量.
安全相关数据又可以根据攻击者的利用程度分为三种类型:载体数据、目标数据和中间数据.载体数据指栈中存在的能被攻击者直接利用的数据,主要有缓冲区类型的变量,如未经边界检查的字符数组,它承载了攻击者的恶意代码.目标数据指能直接或者间接影响函数控制流的数据,如函数返回地址、EBP等.介于这两者之间的为中间数据.这类数据在多步攻击中既能被攻击者作为目标数据,又能被间接利用作为载体数据来篡改目标数据的值.例如在int*a=b赋值语句中,若指针变量a的低地址侧存在可溢出的缓冲区,那么可以通过改变a的值使其指向函数返回地址,再改变b的值使其指向恶意代码.那么此时b承载了指向恶意代码的指针,因此可以作为载体数据;a被赋予了指向返回地址的指针也可以作为载体数据,但同时要通过a修改返回地址的值,所以a也可以作为目标数据.
因此,攻击模式一可以表述成攻击者将恶意代码注入到载体数据中,利用载体数据的特性直接覆盖并篡改目标数据的内容.攻击模式二可以表述成攻击者将恶意代码注入到载体数据中,通过篡改中间数据的内容,使其指向目标数据的地址后间接篡改目标数据的内容.
2 缓冲区溢出攻击的防御方法
针对缓冲区溢出攻击,在程序生命周期的每个阶段都有相应的防御方法,主要分为两类:一是防止目标数据被篡改,二是防止恶意代码执行.本文所述的基于双栈结构的防御方法是防止目标数据被篡改.
编译器在编译源代码的过程中采用栈来保存控制程序正常执行的数据,即在栈中保存EBP和EIP等目标数据.因此可通过编译器在源程序的编译过程中引入保护机制,如在程序中插入安全相关的代码,以保护程序的栈结构或者控制相关的安全数据.
2.1 基于编译器优化的方法
2.1.1 边界检查
边界检查是防御缓冲区溢出攻击的有效方法之一.如果在程序运行时能得到每个数组的大小信息,并且能实时检查数组中的数据是否发生越界行为,那么就能保证代码不会篡改数组边界外的信息,溢出攻击就不可能发生.
bcc是一种源到源的高级语言转换器[12],用来实现对指针引用和数组访问的边界检查.在源代码中指针引用和数组访问的地方添加实现边界检查、空检查和对齐检查的函数,并且封装经常误用的标准库函数.但是,使用bcc会增加编译时间,产生更多的代码,程序的运行时间也会急剧增加.
类似的方法还有Safe C[13],它为每个指针定义了安全相关的属性,如指针值、指针基地址、指针大小、存储类型(堆、局部变量、全局变量)等,程序在每次引用指针访问数据时都会依据指针的属性,检验指针是否有效、是否越界等安全状态.C的数组边界检查技术[14]对每个指针只定义了“基指针”单个属性,在每次使用指针时对这一属性检查,比较其是否仍在边界内.
从理论角度分析,边界检查的方法能从本质上解决缓冲区溢出漏洞,但需直接修改程序中二进制代码甚至是添加额外的局部变量,性能开销很大.
2.1.2 栈的保护
目前大部分针对栈保护方法的主要目的是为了保护栈中的返回地址值免受篡改,后来又拓展到保护栈中其他的安全关键信息,包括EBP值和局部变量指针值.
StackGuard是在紧邻栈的返回地址低地址处插入一个canary字,保护返回地址值不受篡改[2].该canary字可以是程序启动时随机生成的32位的随机值,也可是终结符,如NULL,LF,-1或者CR:0X000aff0d等.当被调用函数执行完返回时,将会检查canary字是否变化.如果变化将会记录警报并终止程序,如没有则从栈中移除canary字,函数会正常返回.在后续版本中,StackGuard将canary字与返回地址异或运算得到新的canary字插入栈中,防止返回地址被篡改.即使如此,StackGuard不能防御攻击模式二和攻击模式一中针对EBP的攻击.
Stack Shield通过修改编译器插入优化代码来保护栈上返回地址[15],包括两个方法:Global ret stack和Ret range check.前者在程序启动时,在堆上分配全局数组用来存储函数的返回地址.在函数执行开始时,将返回地址复制到堆上的返回地址表中,在函数结束时,比较或者直接从堆上的返回地址表读取返回地址用以替换当前栈帧中的返回地址,与此同时堆上的返回地址表中相应的返回地址将会移除,函数正常返回.但是在堆上分配的返回地址表的大小是固定的,若函数中的返回地址数超过了返回地址表的容量,那么超过容量的部分返回地址将不受保护.后者是在进程的数据段的开始处设置全局变量G,在函数返回时,若返回地址值R<G,表明函数返回地址指向进程的代码段,函数将正常返回.若R>G,那么返回地址指向数据段,程序将终止.但与StackGuard一样,Stack Shield也不能防御攻击模式二及攻击模式一中针对EBP的攻击.
类似的防范还有返回地址保护RAD[16],但与Stack Shield不同之处,RAD采用两种方法保护RAR中存储的返回地址值,分别是Minezone RAD和Read-Only RAD.Minezone RAD是声明一个全局的整型数组作为RAR用来存储返回地址值,并将RAR两端的相邻页置为只读.这样可避免基于堆缓冲区溢出的攻击,篡改RAR中的返回地址值.Read-Only RAD是将整个RAR标志为只读,只有在函数开始时,设置RAR为可写,加入新的函数返回地址值.RAD也采用连续弹出RAR中地址,利用穷举法找出相同的值,以解决系统调用setjmp()和longjmp()造成的RAR和栈中返回地址不一致的问题.
尽管GCC 4.0以上版本通过在栈中插入随机canary字实现了对返回地址和EBP值的保护,但是相应的破解方法依然层出不穷,如通过篡改EBP来破解StackGuard和Stack Shield的方法[8].而若程序中存在能被利用的代码,那么攻击者可以不需要注入代码,直接篡改返回地址使其指向程序中代码位置,这样就能破解 RAD[9-10].
2.1.3 指针的保护
现有的通过注入恶意代码而实现的缓冲区溢出攻击都需要篡改内存中指针的值,攻击者首先要篡改指针使其指向注入的恶意代码,当程序在引用该指针时,原来指向合法代码的指针却指向恶意代码,而程序将执行该恶意代码.
PointGuard[17]在进程启动时随机生成一个密钥,利用异或运算加密存储在内存中的指针值.在程序需要访问指针的数据时,利用相同的密钥解引用该指针,然后才能正确找到数据所在的位置.若攻击者没有密钥,在溢出缓冲区并篡改了指针的值后,程序在正常执行过程中解密指针,得到的数据将不会指向恶意代码处,而会指向不可预知的地址,在多数情况下会导致进程退出或异常行为.若程序中存在能被格式化字符串攻击利用的漏洞,攻击者可以获得部分加密指针的数据,且由于加密算法仅仅是采用异或运算,因此攻击者很容易得到加密的密钥.
2.2 其他方法
针对缓冲区溢出攻击防御的方法还有许多,在硬件上实现的对函数返回地址的保护,如SplitStack[18]、StackGhost[19]等.在操作系统层面上实现的有指令集随机化方法 RISE[20]和 Kc[21];内存空间地址变形方法,包括地址随机化方法ASLR[3]及 TRR[22]、地址迷惑方法[23-24]和地址空间分离[25];不可执行栈PAGEEXEC[26]、Non-executable stack[4].在操作系统层面实现的方法大部分是在攻击者修改了目标数据后,作为最后一道防御措施用以防止恶意代码的执行.
2.3 方法的评价
现有的基于编译器的栈缓冲区溢出防御方法存在下列问题:① 密钥的存储与保护难以防范攻击者的窃取.以StackGuard中的canary、PointGuard中密钥为例,若程序中存在能被格式化字符串攻击利用的漏洞,攻击者可以直接得知canary[6],或者获得部分加密指针的数据,并通过简单的异或运算得出加密的密钥;② 保护的数据类型过少,如StackGuard和Stack Shield仅对返回地址进行保护.因此攻击者可以参照攻击模式一,篡改EBP,利用伪造的栈帧构造指向恶意代码的EIP值,绕过保护字进行攻击[8];③ 性能开销大,编译器优化的方法是要在二进制代码中插入安全代码,而增加操作指令,会增加性能的开销.
3 基于双栈的缓冲区溢出防御方法
针对已有防御方法所存在的问题,本文提出了一种基于双栈结构的缓冲区溢出防御方法,该方法将在栈中常被攻击者利用的载体数据从栈中剥离.一方面将目标数据与载体数据分离,并在两者间加入防护页,达到直接保护目标数据的目的.另一方面将中间数据与载体数据分离,使绕过该双栈结构中保护页的攻击变得困难.最重要的是本方法不需在程序中添加额外指令来保护栈,仅需修改程序中某些特定的指令即可,因此它对性能的影响较小.
3.1 双栈结构
双栈结构是在紧邻原栈的低地址处构造新栈,用以存储程序中的载体数据,因为只有载体数据能被攻击者直接利用,所以在两个栈之间设立防护页(guard page),确保新栈中的数据不能有越过栈边界的行为.图1中给出了采用双栈结构和未采用双栈结构的数据分布情况.

图1 采用双栈结构和未采用双栈结构的数据分布Fig.1 Data distribution on stack with or without dualstack structure
防护页是不能读也不能写的页,任何访问该页的操作都会引起程序异常中断.采用双栈结构可以保证攻击者最常利用的缓冲区类型变量都放在新栈中,而栈的增长方向与缓冲区增长方向相反,缓冲区的溢出只能覆盖其在新栈中相邻的高地址处的变量值,由于防护页的存在而不能篡改目标数据,也不能通过更改中间数据间接篡改目标数据.
栈指针ESP随着局部变量出入栈而不断地改变,但EBP值从函数被调用开始就被确定下来,所以对被调用函数中局部变量的访问都将通过该变量与EBP的偏移量来计算该变量的存储地址.不同于SplitStack[18]中采用额外的栈指针CSP来确定新分配栈的位置,这里只要对程序中的某些指令做修改就能实现双栈结构.首先在函数的初始栈桢代码prologue中修改初始栈的指令,如sub sizeofstack,%esp,将其设置为sub 2×sizeofstack+pagesize,%esp,即将栈大小拓展为当前所分配栈的2倍,并且多分配一页空间作为防护页.栈中局部变量的访问都是通过计算变量与EBP的偏移量offset来实现,因此上述修改不会影响栈中数据的分布.然后修改机器指令中所有对载体数据的访问指令,即修改原栈中载体数据与EBP的偏移量,将(sizeofstack+pagesize)加入到偏移量中,使得载体数据移到新栈当中.
图2给出了一个具体示例.采用双栈结构后,buf在内存中的位置比在原栈中的位置要下移(sizeofstack+pagesize).原栈中的目标数据、中间数据及非安全相关的数据所处的位置不改变.随着指令的执行,被调用函数strcpy()的参数也将会通过push指令存放在紧邻新栈的低地址处,这不影响程序的正常运行,因为在函数调用完成后,将通过ret指令返回,栈指针ESP也将被重新赋值,函数运行过程中使用的原栈和新栈也将会释放.

图2 含漏洞的源码及其采用和未采用双栈结构的栈分布Fig.2 Source code with vulnerability and stack layouts with or without dual-stack structure
为了避免发生绕过防护页的间接指针攻击,在新栈中不能存储类似指针数组等可能被攻击利用的变量类型.可以在指针数组中插入动态的边界检查,检查数组下标是否在界内.这样可以将作为载体数据的指针数组转换成非载体数据类型,并将修改后的指针数组存放到原栈中.
3.2 有效性分析
假设程序中存在栈缓冲区溢出漏洞,并且攻击者能估计出当前栈缓冲区所在的虚拟地址.
对于攻击模式一,在未加入防御机制前,攻击者能有效利用恶意代码注入到缓冲区中,直接覆盖目标数据,篡改EIP值.当程序在从当前栈帧返回时将已篡改的EIP出栈,程序的控制流将跳转到攻击者指定的恶意代码处.采用双栈结构的防御,将程序中的载体数据与目标数据隔离,即使攻击者能猜测到当前载体数据的虚拟地址,也会因为两者之间存在guard page而导致恶意代码不能越过保护页覆盖目标数据,因此双栈结构能有效防御攻击模式一.
对于攻击模式二,假设程序在载体数据的低地址处存在能被利用的指针数据,攻击者能估计出当前栈缓冲区所在的虚拟地址.在未加入防御机制前,攻击者能够通过修改指针使其指向当前栈帧中的返回地址,并再次利用该漏洞将其指向的地址值(即返回地址)修改为恶意代码处的起始位置.在采用双栈结构后,被间接利用的中间数据同样也会与载体数据隔离,并与目标数据保存到原栈中,因此在新栈中的载体数据尽管写入了恶意代码,但是当前栈中不存在中间数据,攻击不能绕过guard page,因此,攻击模式二间接转换为攻击模式一.
3.3 双栈结构的实现
从程序编译后的二进制代码可以看出,编译器在编译过程中设置栈中数据的排列及栈帧大小.开发了一个重构ELF格式的目标文件的工具软件,用以在程序中实现双栈结构,该工具的目标对象是通过GCC编译器-g选项获得的可重构文件.
首先反汇编 .text节区中机器指令,在其汇编代码中通过修改prologue初始栈的指令,如sub sizeofstack,%esp,将其设置为sub2×sizeofstack+pagesize,%esp,将新分配大小为sizeofstack的空间作为新栈.
然后通过GCC编译器中的-g选项获得可重定位文件的DWARF3格式下的调试信息,利用调试信息定位载体数据所在的函数块及其在栈中的位置,即与当前栈帧中EBP的偏移量.在汇编代码中修改该载体数据的偏移量,其实质只需修改该载体数据相关的每条指令,将(sizeofstack+pagesize)加入到载体数据的偏移量中,即可实现在新栈中存储载体数据.最后将修改后的汇编代码转换成机器指令后重新放入 .text节区.
考虑到指令在修改后长度会变化,因此,利用指令长度增加的总量重新定位 .rel.text节区中各表项的值(主要为offset值),使其指向修改后的 .text节中引用外部变量的地址处.最后链接该可重构文件,所得的可执行文件就具有了双栈结构的保护功能.
GCC 4.1以上版本中开始使用Propolice堆栈保护方法[27].该方法是在函数prologue处先设置栈的初始大小,而后插入保护代码,即将canary插入到栈中紧邻EBP的低地址处,并在函数返回时比较判断是否发生溢出.由于插入的保护代码指令和比较指令都需要通过EBP的偏移量确定栈中的数据,因此本文所述目标文件重构工具可借用该保护机制来实现防护页功能,即通过修改该指令,将canary移动到原栈和新栈的连接处,并在函数返回时比较canary的值,实现了防护页的保护功能.
4 有效性验证和性能评估
为验证本方法及依据其原理所开发的工具软件的有效性,并分析其性能,设计了相应的实验.实验环境建立在Dell微机(3GHz core2CPU、2GB内存)上,运行包含Red Hat 7.0企业版的虚拟机,内存设置为256MB,编译器选用GCC 4.2.1.
4.1 有效性验证
目前绝大部分的缓冲区溢出攻击代码都是由Aleph One攻击代码衍生而来[5],因此本实验也采用Aleph One攻击集作为实验对象.它们主要由四组程序构成,分别是overflow1.c,vulnerable.c/exploit2.c,vulnerable.c/exploit3.c 和 vulnerable.c/exploit4.c,其中,overflow1.c中包含攻击程序和被攻击程序,vulnerable.c作为被攻击程序,承受来自exploit2.c,exploit3.c及exploit4.c等攻击程序的攻击,exploit4.c属攻击模式二,其他属攻击模式一.
本文使用所开发的目标代码重构工具重构了overflow1.c和vulnerable.c的二进制代码,测试结果如表1所示.

表1 Aleph One攻击代码的测试结果Tab.1 Results of attack test with Aleph One codes
从表1可知,采用双栈结构后的被攻击程序能有效防御缓冲区溢出攻击,并能正常返回.本工具的实质是修改目标文件中 .text节区的二进制代码,因此在表中列出了重构前后指令序列长度以作比较.这四组程序中只有overflow1.c在重构前后指令序列长度发生变化,这是因为其在重构时,有三处指令需修改,这三处指令使用的立即数或地址均小于0x7f.指令在重构后所使用的立即数或地址超过0x7f,因此遵循指令对齐原则,其长度增加三个字节,这样,重构后指令序列总长度增加到149.而vulnerable.c的程序相对简单,需要重写的指令的立即数或地址均大于0x7f,故重构后的指令序列长度没有变化.重构后overflow1.c的可执行文件所占用存储空间也相应增加了9个字节,而vulnerable.c在重构前后的可执行文件所占用存储空间没有变化.尽管如此,overflow1.c与vulnerable.c在重构前后的可执行文件的指令数没有变化.
4.2 性能评估
为了评估程序采用双栈结构后的性能,采用文献[23-24]中所用的几组验证程序作为基准程度集macrobenchmarks,并编写了几组常用的程序作为基准程度集microbenchmarks,如表2所示.
利用目标代码重构工具重构程序,比较其重构前后的运行时间和所占用存储空间,其中macrobenchmarks分别运行20次,测量结果见表3.
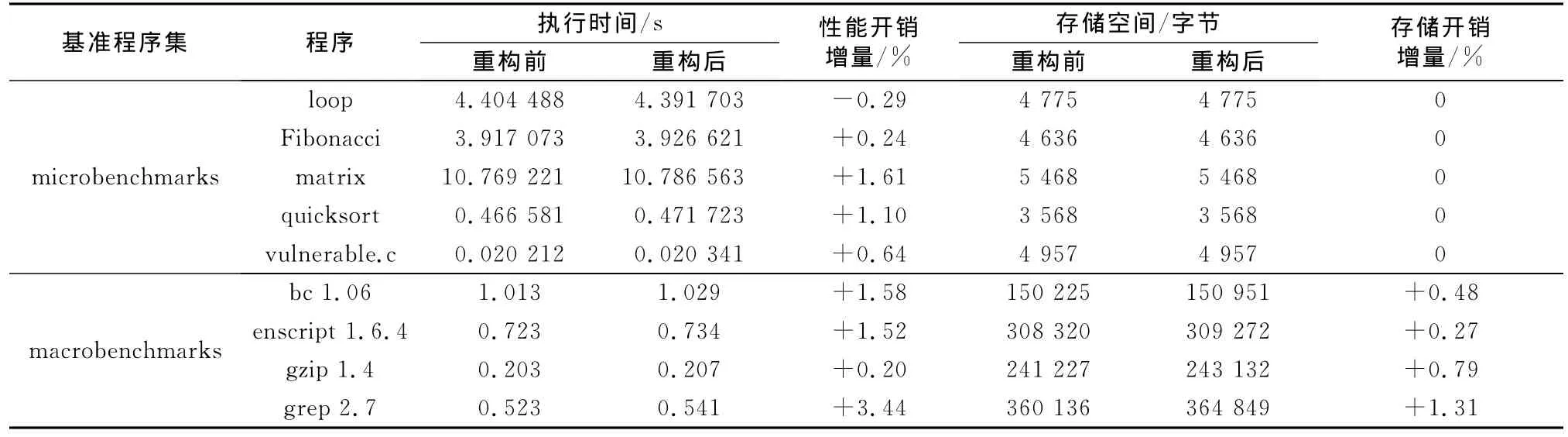
表3 性能测试结果Tab.3 Performance test results
从表3中可以看出,采用双栈结构并未对程序的性能产生不利影响.这是因为重构仅仅是修改了访问局部变量时引用的偏移量,没有添加额外的安全指令,因此使用双栈结构后的程序的性能开销可以忽略不计.重构工具修改了函数prologue中的栈的初始分配指令及函数中对载体数据类型数据变量的访问指令,所以重构后增加的代码长度不仅与程序中函数调用的次数相关,也与其对相关变量的具体操作指令相关.另外从表3中还可以看出,采用双栈结构后,程序也没有占用过多的存储空间.
采用双栈结构程序在运行时所分配栈的大小至少是原来栈的2倍,因而在虚拟地址空间上开销较大.但只要没有数据写入到新分配的栈中相应页上,根据写时复制技术可认为进程只会在页面表中占据一项,不会对实际的物理地址空间造成额外开销.
5 结论
本文阐述分析了栈缓冲区溢出攻击的两种模式,并由此对栈中的数据进行分类.在分析基于编译器的典型缓冲区溢出攻击防御方法的基础上,提出了利用双栈结构实现缓冲区溢出漏洞的防御方法,分析了该结构的有效性.为了评估该结构的有效性和性能,设计并开发了一个重构ELF格式的目标文件的工具软件.实验表明,所提出的方法及开发的工具能有效防御缓冲区溢出攻击,并且性能开销较小.
本文所述的重构工具主要是修改局部变量的访问指令,让局部变量在栈中呈稀疏分布,隐藏甚至消除漏洞.为了更有效地迷惑攻击者,可以利用该工具修改函数中所有的局部变量访问方式,使各变量在栈中呈随机化排列,让攻击者更难猜测各种安全相关数据在栈中的地址,提高攻击代价,有效地提高防御性能.也可以对该工具进行修改,适当加大新栈,使其有足够的空间包容各类攻击带来的大量溢出数据,即使在受到攻击时,函数也能返回正确的值.
[1]National Institute of Standards and Technology.National vulnerability database statistics[EB/OL].[2009-06-15].http://nvd.nist.gov/statistics.cfm.
[2]Cowan C,Pu C,Maier D,et al.StackGuard:automatic adaptive detection and prevention of buffer-overflow attacks[C]∥Proceedings of the 7th Conference on USENIX Security Symposium.San Antonio:USENIX Association,1998:63-78.
[3]The PaX Team.PaX address space layout randomization(ASLR)[EB/OL].[2009-06-15].http://pax.grsecurity.net/docs/aslr.tx.
[4]Solar Designer.Non-executable stack patch[EB/OL].[2009-06-15].http://www.openwall.com.
[5]Aleph One.Smashing stack for fun and profit[EB/OL].(1996-08-11)[2009-06-15].http://www.phrack.com/issues.html?issue:49&id=14#article.
[6]Strackx R,Younan Y,Philippaerts P,et al.Breaking the memory secrecy assumption[C]∥Proceedings of the Second European Workshop on System Security.Nuremburg:ACM New York Press,2009:1-8.
[7]Salamat B,Jackson T,Wagner G,et al.Runtime defense against code injection attacks using replicated execution [J].IEEE Transactions on Dependable and Secure Computing,2011,8(4):588.
[8]Richarte G.Four different tricks to bypass StackShield and StackGuard protection[EB/OL].(2002-04-06)[2009-06-15 ]. http://www. core security. com/files/attachments/StackGuard.pdf.
[9]Krahmer S.x86-64 buffer overflow exploits and the borrowed code chunks exploitation technique[EB/OL].[2009-06-15].http://www.suse.de/~krahmer-/no-nx.pdf.
[10]Roglia G F, Martignoni L,Paleari R,et al.Surgically returning to randomized lib(c)[C]∥Proceedings of Annual Computer Security Applications Conference.Honolulu:ACM New York Press,2009:60-69.
[11]Dalton M,Kannan H,Kozyrakis C.Real-world buffer overflow protection for userspace &kernelspace[C]∥Proceedings of the 17th USENIX Security Symposium.San Jose:USENIX Association,2008:395-410.
[12]Kendall S.Bcc:Runtime checking for C programs [C]∥Proceedings of the USENIX Summer 1983 Conference.Toronto:USENIX Association,1983:5-16.
[13]Austin T M,Breach S E,Sohi G S.Efficient detection of all pointer and array access errors[C]∥Proceedings of the ACM Conference on Programming Language Design and Implementation.Orlando:ACM New York Press,1994:290-301.
[14]Jones R W M,Kelly P H J.Backwards-compatible bounds checking for arrays and pointers in C programs [C]∥Proceedings of the 3rd International Workshop on Automatic Debugging.Linköping:Linköping Univerty Electronic Press,1997:13-26.
[15]Vendicator. Stack Sheild: a stack smashing technique protection tool for Linux [EB/OL].(2000-01-08)[2009-06-15].http://www.angelfire.com/sk/stackshield.
[16]Chiueh T,Hsu F.RAD:A compile-time solution to buffer overflow attacks[C]∥Proceedings of the 21st International Conference on Distributed Computing Systems.Phoenix:IEEE Computer Society,2001:409-420.
[17]Cowan C, Beattie S,Johansen J,et al. Point-guard:Protecting pointers from buffer overflow vulnerabilities[C]∥Proceedings of the 12th USENIX Security Symposium.Washington:USENIX Association,2003:91-104.
[18]Xu J,Kalbarczyk Z,Patel S,et al.Architecture support for defending against buffer overflow attacks[C]∥Proceedings of the Second Workshop on Evaluating and Architecting System Dependability.San Jose:ACM New York Press,2002:51-62.
[19]Frantzen M,Shuey M.StackGhost:hardware facilitated stack protection [C]∥Proceedings of the 10th USENIX Security Symposium.Washington:USENIX Association,2001:271-286.
[20]Barrantes E G,Ackley D H,Forrest S,et al.Randomized instruction set emulation to disrupt binary code injection attacks[C]∥Proceedings of the 10th ACM Conference on Computer and Communications Security.Washington:ACM New York Press,2003:281-289.
[21]Kc G S,Keromytis A D,Prevelakis V.Countering codeinjection attacks with instruction-set randomization [C]∥Proceedings of the 10th ACM Conference on Computer and Communications Security.Washington:ACM New York Press,2003:272-280.
[22]Xu J, Kalbarczyk Z, Iyer R. Transparent runtime randomization for security [C]∥Proceedings of the 22nd International Symposium on Reliable Distributed Systems.Florence:IEEE Computer Society,2003:260-269.
[23]Bhatkar S,DuVarney D C,Sekar R.Address obfuscation:An efficient approach to combat a board range of memory error exploits[C]∥Proceedings of the 12th USENIX Security Symposium.Washington:USENIX Association,2003:105-120.
[24]Bhatkar S,Sekar R,DuVarney D C.Efficient techniques for comprehensive protection from memory error exploits[C]∥Proceedings of the 14th USENIX Security Symposium.Baltimore:USENIX Association,2005:105-120.
[25]Riley R,Jiang X,Xu D.An architectural approach to preventing code injection attacks[J].IEEE Transactions on Dependable and Secure Computing,2010,7(4):351.
[26]The PaX Team.Documentation for the PaX project[EB/OL].[2009-09-15].http://pax.grsecurity.net/docs/pageexec.txt.
[27]Etoh H.ProPolice:GCC extension fro protecting applications from stack-smashing attacks [EB/OL].(2005-08-22)[2009-09-15].http://www.trl.ibm.com/projects/security/ssp/.
