可重构处理器的AVS高清解码探究
2012-10-26赵静周莉喻庆东陈杰
赵静,周莉,喻庆东,陈杰
(中国科学院微电子研究所,北京100029)
可重构是处理器领域的一种前沿技术,已开始应用于多媒体高清视频解码[2],一些研究成果也已经证明[5-7]:粗粒度的可重构处理器,能有效提高多媒体系统的性能.AVS标准由中国数字音视频编解码标准工作组提出,是中国第一个自主知识产权的视频编解码协议[1].目前市场上存在的AVS解码方案,主要有2种:1)通用处理器(GPP),但即使是多核,也很难满足高清应用的性能要求;2)通过专用集成电路(ASIC)对关键算法进行硬件加速,再与通用处理器协同工作的 SoC解决方案[3-4],这种方案在AVS高清市场得到广泛应用,但ASIC灵活性差,研发周期长,成本高等缺点也不容忽视.应用可重构技术来实现AVS解码,具有很大的灵活性,并且达到了很好的性能,是一种值得探索的新思路.
1 AVS标准概述和Remus平台介绍
1.1 AVS 标准概述
图1所示为AVS视频解码的流程.AVS标准采用了与H.264相似的框架,比MPEG-2达到了更好的压缩性能.AVS采用了经典的多媒体处理算法,包括2D-VLD熵解码、DCT变换、运动补偿、帧内预测、环路滤波,并对每种算法分别进行了优化,在压缩效率略逊于H.264的条件下,大大降低了复杂度.
1.2 Remus平台架构介绍
Remus是由863项目可重构工作组研发的基于粗粒度可重构技术的处理平台.图2是Remus目前的体系架构,其主要功能模块包括,可重构处理器核RPU0(reconfigurable processing unit)和RPU1、主控ARM7、微处理器阵列uPA、熵解码模块EnD(entropy decoder)以及其他辅助模块和总线.可重构处理器的最大优势体现在大量规则运算,尤其是循环运算.因此,在运算复杂度极高的多媒体处理领域,可重构处理器有巨大的潜在应用市场.

图1 AVS视频解码流程Fig.1 Decoding flow of AVS standard(video)

图2 Remus架构Fig.2 The architecture of Remus
1.2.1 可重构阵列结构
可重构处理器核RPU高并行度的运算能力,主要是由其内部的运算阵列实现的,每个RPU包含4个8×8规模的处理阵列PEA(processing element array),PEA是RPU完成一个算法所需的最小功能模块.每个PEA的结构如图3所示.
除了用来实现运算功能的8行8列的运算阵列,每个PEA8×8中还包括一个与64个PE处理单元相对应的临时寄存器阵列Temp_reg8×8,用来暂存一些中间结果,辅助提高运算阵列的并行性.可重构阵列以行为基本单位,每行的PE单元在同一周期得到结果,在下一周期将得到的结果送至下一行PE.

图3 PEA8×8的结构Fig.3 The architecture of PEA8 ×8
1.2.2 阵列中的处理单元PE
运算阵列中的每个PE单元以通用处理器中的ALU结构为基础,添加一些逻辑运算,关系运算等使其功能更完备.如图4所示.输出寄存器用于存放运算结果,临时寄存器用于存放中间数据.运算单元的输入、输出和算子都是可配的,临时寄存器的输入和输出也是可配的.运算单元和临时寄存器单元的输入可来自输入FIFO,常数寄存器,上一行PE的结果,输出可传到下一行PE继续运算,也可送至输出FIFO进行输出,表示运算结束.

图4 PE单元的结构Fig.4 The architecture of PE
1.2.3 处理器RPU的工作模式
用来配置PE阵列完成一个特定算法的文件称为配置文件(context),在一个任务执行之前,执行该任务所需的配置文件会预先存储在内部存储器GCCM(global core context memory)中,所需的常数会从常数存储器CM(constant memory)中载入2个常数寄存器,这些常数可被配置为运算单元的输入.在任务的执行过程中,RPU会根据为控制阵列uPA的配置字,通过配置接口CI(context interface)动态调度存储器中的配置信息,来完成一个个子算法,从而完成整个任务.
2 处理器核RPU上的算法映射
可重构技术在大量规整运算中特别是循环运算中,显示了的强大优势.在AVS解码过程中,逆离散余弦变换(IDCT)、运动补偿(MC)、帧内预测、环路滤波这几种算法的运算量,占到整个解码过程的80%以上.把这几种算法映射到RPU上,将会显著提高解码性能.
2.1 IDCT
IDCT是能充分发挥可重构阵列优势的一种最典型的算法.AVS采用8×8大小的IDCT变换,通过行变换和列变换,将编码产生的残差从频域重新变为空域信息[1].图5是根据IDCT行变换算法抽象出来的数据流图(DFG).DFG图是算法到运算阵列映射的一种清晰明了的表示方法,根据算法的DFG图很容易得到相应的配置信息.

图5 IDCT的DFG图Fig.5 DFG of IDCT
图5中的数组a表示8×8块频域数据的一行,数组b表示行变换的结果.在阵列运算的第1个周期,a[1]、a[7]、a[3]和 a[5]从输入FIFO 进入阵列参与运算;第2个周期,第1行PE单元的运算结果到达第2行PE,参与第2行PE单元的运算,同时,a[2]、a[6]进入PE阵列第2行其余空闲 PE 单元;第3个周期,第3行PE接受第2行的结果继续运算,a[0]和 a[4]进入阵列;从第 4 个周期开始,PE单元的输入都来自上一行PE单元或常数寄存器,直到第8个时钟周期,8×8块中一行数据的行变换结束,到达输出FIFO.列变换可采用与行变换相同的DFG图,只需载入不同的常数.
事实上,在第1个周期即可把输入数据a[2]、a[6]、a[0]和 a[4]存入临时寄存器阵列,于是从第2周期开始,参加运算的数据都可来自上一行PE的结果.这样做的好处是,在8×8块的第1行数据运算到第2周期的时候,即可把块中第2行数据导入阵列开始运算,而不造成行与行之间相互干扰.这样,算法中8次循环运算,就转化成了阵列中的八级流水处理,流水线之间间隔一个周期.完成一个块的行变换所需的运算时间为16个周期(8+8).这样的高并行度运算甚至比ASIC性能更高[5].
2.2 运动补偿(MC)
运动补偿是把参考块的数据进行插值滤波,得到当前块的预测值,运算量占到AVS视频解码的50%以上.图6中大写字母表示整像素点,整像素之间是分像素点,AVS亮度预测采用1/4预测精度,因而共有16种位置.样点位置不同,插值的规则也不同:整数像素无需插值;1/2像素采用四抽头滤波器F1(-1,5,5,-1)对距其最近的4个整数像素点进行插值,1/4像素点采用四抽头滤波器 F2(1,7,7,1)对距其最近的1/2像素点插值.色度像素预测精度是1/8,采用双线性插值.
一个8×8块的MC,通常由一个大于8×8的参考块插值得到.以图6中亮度分量的1/2像素点b为例,其插值过程由以下2个公式完成:

完成此位置的一个8×8块需要一个8×11的参考块.图7为以像素点b为代表的8×8块一行像素插值的DFG图.同样,第1周期所需的数据全部进入阵列,第2周期开始下一行,形成高效流水.完成这样一个8×8块的插值运算,只需要14个周期.

图6 样点的不同位置Fig.6 Different positions of pixels
单从以上的例子来看,基于可重构的MC比现有的提出的方法性能提高数倍之多[3-4,8-10].然而,这只是一种最简单的情况,根据像素点的位置不同,插值的复杂度上升,给阵列运算也带来一定的挑战.例如图6中像素点i所在的8×8块的插值运算,需要一个11×12的参考块.这样的一个块在阵列中完成插值需要以下过程:
1)把参考块转置,以便步骤2)的流水顺利进行;
2)对整数样点 A、D、H、K用F1插值滤波,得到1/2样点h及相应位置的像素;
3)将步骤(2)得到的结果转置,以使步骤(4)顺利进行;
4)将步骤对bb、h、m、cc用 F1插值滤波,得到 j及与其位置相应的像素;
5)对 gg、h、j、m 用 F2滤波插值得到 i.
步骤2)、4)、5)均采取与图7相似的DFG图.而转置用阵列的直通和输入输出地址配置实现.在这种情况下,完成一个块的插值将需要5套配置信息顺次执行,加上数据在输出和输入FIFO之间传输需要的时间,对于这个位置的样点,从第1次进入阵列运算,到完成一个8×8块的插值,需要至少113个周期,而在双向预测并且前后向都是这个位置的像素点时,完成一个8×8块的运动补偿则需要至少236个周期.
可见,同ASIC实现相类似,在视频解码中运算量最大的MC仍然是影响性能的关键.不同的是,ASIC实现中,各个位置的像素点插值所需的时钟周期相差不大,而在可重构处理器中,不同位置的像素点,根据其运算复杂度,实现性能也有着显著的差别.但是即使在最坏的情况下,可重构实现的MC性能仍与ASIC实现相当.而对于部分码流,平均性能甚至超过ASIC实现.
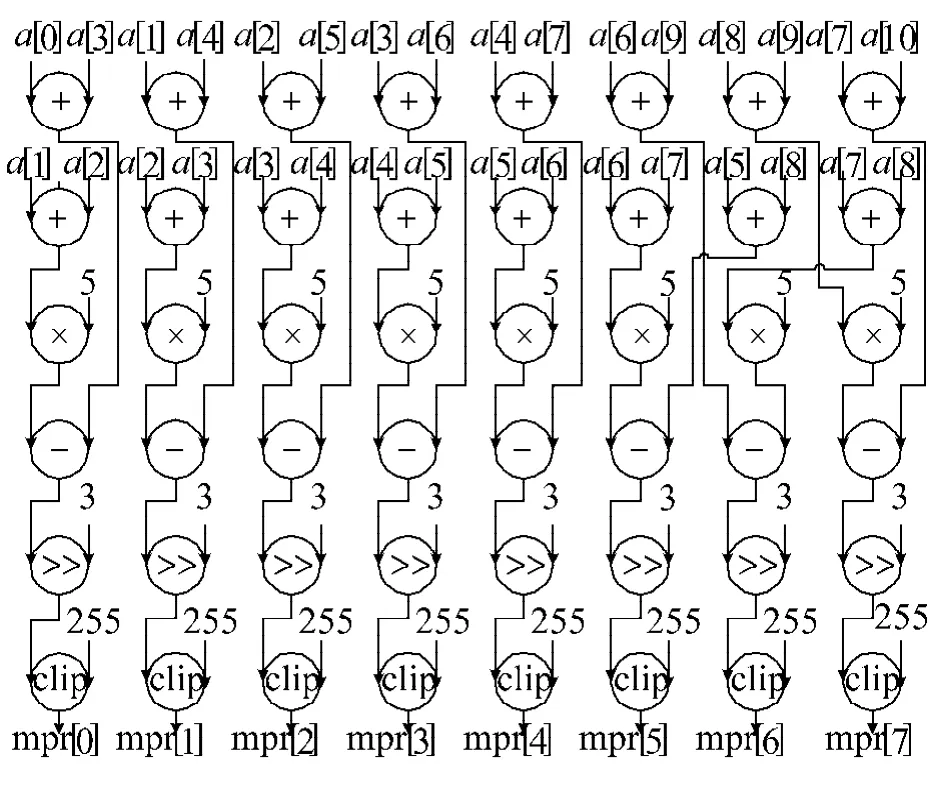
图7 像素点b插值的DFG图Fig.7 The interpolation DFG of sampleb
2.3 帧内预测
AVS帧内预测以8×8块为单位进行[1].由于帧内预测模式较多,并且根据宏块和块的位置不同,预测所采用的像素也不同,从而导致分支较多[11].但是具体到每个分支,运算量并不大.图8是DC预测模式下的一个DFG图,它表示只有8×8块左边像素可用而上边像素不可用时,根据左边像素c[1]~ c[8]和左下角像素的可用性(left_down_valid)得到8×8块预测值的过程.
图中前4个周期是对块左边的像素进行滤波,后4个周期里利用运算单元的直通运算和寄存器阵列将前面的滤波结果复制成8行8列的块.整个8×8块预测的运算时间是7个周期,是一种非常高效的预测方式.
因此,在帧内预测时,可以将每个分支抽象出来作为一个子算法进行映射,而由微控制阵列uPA来承担控制任务,根据不同的分支指定RPU分别执行不同情况下的子算法.子算法划分越细,RPU执行效率越高.

图8 DC预测其中一种情况的DFG图Fig.8 DFG of DC-prediction on a given situation
2.4 环路滤波
环路滤波是为了去除编码时产生的块效应,运算复杂度和控制复杂度都相对较高[12],并不是一个典型的适合可重构阵列的算法,然而可重构阵列支持的一些逻辑运算,可以通过算法优化,将控制分支设法用逻辑运算的方式来实现.图9是边界强度为2时的亮度块边界滤波的DFG图,以此为例来说明这种映射过程.
图9中的算子comp?A:B表示:如果正上方的PE输出结果不为0则当前PE结果为A,否则结果为B.这个算子与关系运算相结合,很好的解决了阵列不擅长的选择分支运算,使得阵列灵活性更好.6个周期完成边界两边6个像素的滤波,在高效流水情况下完成一条8×8块的垂直边的滤波需要14个周期.水平边则要加上使流水线顺利进行的转置运算,复杂度相对较高,即使这样,仍取得了相当高的性能.
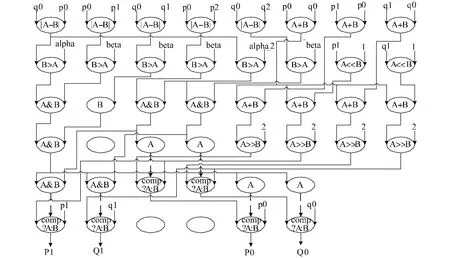
图9 环路滤波(bs=2)DFG图Fig.9 DFG of deblocking(bs=2)
3 解码过程的并行化设计
在AVS解码流程中,除了可在RPU上执行的运算密集型的算法,还有部分控制密集型的算法,主要集中在熵解码,在Remus系统中熵解码的任务由EnD模块来承担.微控制器阵列uPA则承担着配置RPU,指定其执行的具体配置信息的任务.
3.1 解码流程
系统在主控ARM7的控制下开始解码,熵解码模块EnD根据ARM7指定的码流地址,通过EMI从外部的存储器中读取码流进行序列参数集和图像参数集的解析,并由ARM7读取解析值.
在图像参数解析完毕之后,由EnD、uPA和RPU进行宏块级的解码.EnD进行熵解码并将结果以宏块为单位进行组织,每个宏块的信息分成两部分,一部分是残差信息,放入存储器,另一部分是宏块预测信息,送到微控制器阵列uPA,再由uPA解析得到的宏块预测信息,对RPU进行相应的配置,而RPU0和RPU1则在uPA的配置下,完成以下工作:
1)从存储器中读取残差数据,进行IDCT;
2)从存储器中读取参考像素,进行帧内预测,或者帧间预测;
3)将预测结果和残差相加进行重建;
4)对重建结果进行环路滤波,并将结果送出.
图10是EnD、uPA、RPU0和RPU1进行宏块级流水处理的示意图,其中RPU0用来处理亮度数据而RPU1处理色度数据.

图10 宏块级流水示意Fig.10 Stream line of MB
3.2 阵列运算的并行化设计
在宏块解码的过程中,由于算法之间和宏块之间的数据依赖性,因此在RPU中各个阵列的运算需要有一定的同步控制.
图11是RPU0和RPU1分别在解码帧内和帧间预测的宏块时,PE阵列并行示意图.MB0和MB1分别为帧内和帧间预测的宏块.对于亮度块来说,帧内预测时后面的块要用到前面块的重建结果,只能顺序执行4个块的帧内预测和重建,由RPU0中第1个阵列PEA0来执行这个过程,其余3个阵列空闲,4个块全部重建之后,再由4个阵列分别完成4个块的边界滤波.而帧间预测时,4个亮度块可以独立读取各自的参考数据并且独立进行插值运算,这时RPU0中的4个PEA可并行完成4个亮度块的IDCT,插值,重建和边界滤波.可见帧间预测时亮度块解码的并行度更高.虽然帧内预测并行度比较低,但是每个块进行帧内预测时的运算量都不大,因而不会成为性能的瓶颈.
假设码流色度模式4:2:0,对于2个色度块,不存在数据依赖性,可由RPU1中的2个阵列完成IDCT,另外2个阵列同时进行预测,结束之后再相加重建,最后由2个阵列分别完成2个块的边界滤波.色度运算量要比亮度小,因而亮度块的解码是影响性能的关键.
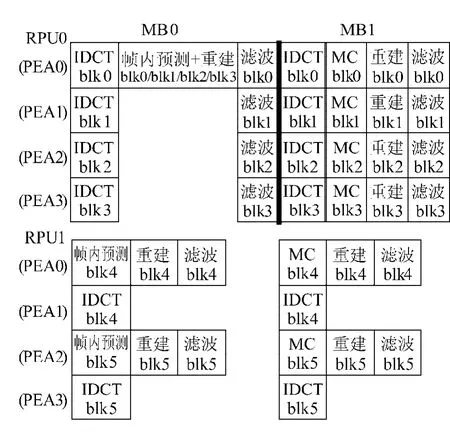
图11 RPU并行化运算Fig.11 Parallel execution of RPU
4 仿真结果和性能统计
本文分析了理想状态下数据在进入阵列后的运算周期数,但是综合考虑外部数据存取时间和内部数据传输时间以及配置信息载入时间,实际情况会比理想情况有所下降.另外,对于不同的宏块,解码所需的周期数会有比较大的差异,特别是对于帧间预测的宏块,因而,可重构系统解码的性能应以码流中各种宏块解码的平均性能为主要依据.
目前已有的基于可重构系统的AVS解码方案还很少,因而选取一些ASIC实现方案作为比较.表1为可重构方案在各个算法中的性能统计,以及文献[4]方案的性能.文献中的高清解码系统是将几种算法作流水处理,因而降低了对每种算法实现的性能要求,而可重构系统的并行处理,对每种算法有更高的加速比.
通过对foreman等20个经典码流的仿真测试,在200 MHz的工作频率下,可重构系统解码1080 p的高清码流可达30 f/s的实时效果,图像清晰稳定.图12(a)和(b)分别为VCS仿真结果中I帧和B帧具有典型代表性的一段,时钟周期为20 ns,基本每个宏块均可以在766个周期以内解码完毕.

表1 RPU中各种算法性能及与文献[4]的比较Table 1 Performance of the algorithm s in RPU and the com parison with referenne literature[4]

图12 仿真结果截图Fig.12 Simulation results
5 结束语
可重构系统保持了很好的通用性,若要实现其他视频标准,不需更换硬件,只需改变配置信息和控制软件即可.根据算法映射分析可以看出,可重构技术在大量规整的运算中确实有显著的优势,而仿真结果也表明可重构系统在保持通用性的情况下,可以达到与ASIC相匹敌的性能.
同时,可重构作为一种前沿技术,还有很大研发空间.进一步加强其灵活性,可使其在ASIC和通用处理器之间取得更好的平衡,在多媒体处理领域,发挥更大的潜力.
[1]高文,黄铁军,吴枫,等.GB/T 20090.2-2006,AVS workgroup.information technology-advanced audio video coding standard,part2:video[S].中国标准出版社,2006.
[2]GAMESAN M K A,SINGH S,MAY F,et al.H.264 decoder at HD resolution on a coarse grain dynamically reconfigurable architecture[C]//International Conference in Field Programmable Logic and Applications.2007,[s.l.],2007:467-471.
[3]LIU Wei.A Soc design for AVS video decoding[C] //IEEE Pacific-Asia Workshop on Computational Intelligence and Industrial Application.[s.l.],2008:700-703.
[4]JIA H,ZHANG P,WEN Gao.An AVS HDTV video decoder architecture employing efficient HW/SW partitioning[J].IEEE Transactions on Consumer Electronics,2006,52(4):1447-1453.
[5]SINGH H.Morphosys:an integrated reconfigurable system for data-parallel and computation-intensive applications[J].IEEE Trans Computers,2000,49(5):465-481.
[6]BEREKVICM.Mapping of video compression algorithms on the ADRES coarse-grain reconfigurable array[C] //MSP7 Workshop on Multimedia and Stream Processors.Barcelona,2005:47-52.
[7]XPP-IIIprocessor overview white paper[EB/OL].[2007-09-03].http:∥www.pactxpp.com.
[8]ZHENG JH,DENG L,ZHANG P,et al.An efficient VLSIarchitecture for motion compensation of AVS HDTV decoder[J].Journal of Computer Science and Technology,2006,21:370-377.
[9]WAN Yi,LU Yu.Highly parallel implementation of subpixel interpolation for AVSHD decoder[J].Journal of Zhejiang University:Science A,2008,9(12):1638-1643.
[10]黄玄,陈杰,李霞,等.AVS高清视频帧间补偿结构与电路实现[J].电子科技大学学报,2009,38(2):202-206.HUANG Xuan,CHEN Jie,LI Xia,et al.Architecture and VLSI implementation of inter compensator for AVS HDTV application[J].Journal of University of Electronic Science and Technology,2009,38(2):202-206.
[11]WANG Zheng,LIU Peilin.Analysis of AVS intra-prediction technology and its implementation by hardware[J].Computer Engineering and Applications,2006,42(19):80-83.
[12]CHIEN Chengan,CHANG Hsiucheng,GUO Jiunin.A high throughput deblocking filter design supporting multiple video coding standards[C]//IEEE International Symposium on Digital Object Identifier 2009.[s.l.],2009:2377-2380.
