一种改进的Apriori算法在试卷评估中的应用研究
2012-10-21陈世保吴国凤
陈世保,吴国凤
一种改进的Apriori算法在试卷评估中的应用研究
*陈世保1,吴国凤2
(1.安徽财贸职业学院,安徽,合肥 230601;2.合肥工业大学,安徽,合肥 230009)
试卷评估是教学工作中非常重要的一部分,针对传统试卷评估方法中仅仅是对试卷进行宏观整体的分析与评价,缺乏对试卷的微观分析。文章将一种高效的改进的Apriori算法应用在试卷分析中,挖掘出知识点之间的关联,得到的结论对于教师改进教学方法、优化教学效果,提高命题水平和试卷质量对有巨大的指导作用,对于学生有针对性的学也具有巨大的指导作用,同时对于教学管理部门的决策提供了理论依据。
Apriori算法;试卷评估;关联规则;数据挖掘
0 引言
试卷评估是考试阅卷完毕后对学生试卷进行的综合分析,是教学过程中的一个必不可少的环节。试卷评估是评估教学质量的一个重要依据,它是科学地修订、筛选和调取使用试题的重要理论基础,同时也是检查学生掌握课程综合知识能力的重要途径,更是检验教师教学质量和教学效果的具体体现。试卷评估所反馈的信息能为教学工作提供更有效的帮助,可以指导老师有针对性地调整教学计划,调整教学策略以及改进教学方法,提高教学质量。教学管理部门也可以依据上述数据做出决策,让学校的决策建立在科学的基础之上。
现有的试卷评估方法通过统计方法得到一些常用的指标,如试卷的期望值、最高得分、最低得分、全距、平均成绩、标准偏差、难度系数、及格率以及分数段人数分布等,这些指标是对试卷进行了宏观整体的分析和评价,虽然基本上能反映学生对课程的掌握程度,但是缺乏对具体考题的评价。
关联规则挖掘是从大量的数据中挖掘出有价值的、描述数据项之间相互关联的有关知识。最经典的关联规则挖掘算法是Apriori算法,它是一种挖掘单维、单层、布尔关联规则的算法[1]。该算法无论在处理的数据量还是处理效率上都有很大的局限性。本文讨论了Apriori算法存在的不足以及改进的基本思想,并将其应用在试卷分析中。
1 试卷分析中的关联规则问题描述
关联规则是描述数据库中数据项之间存在的潜在关系的规则,形式为“A1∧A2∧…∧Am=>B1∧ B2∧…∧Bn”,其中Ai(i=1,2,…,m),Bj(j=1,2,…,n)是数据库中的数据项。数据项之间的关联规则即根据一个事务中某些项的出现,可推导出另一些项在同一事务中也出现。

在给定的数据库D,关联规则挖掘问题就是产生支持度和置信度分别大于用户给定的最小支持度(minsup) 和最小置信度(minconf) 的关联规则。例如,在某门课程试卷得分情况的数据库中,1000个学生中有600个学生答对第10题、第20题,而这600个学生中又有360个学生答对了第1题,则规则对答对第10题、第20题的学生同时又答对第1题的的支持度S=360/1000=0.36(答对第10题、第20题和第1题360人占总人数的比例),置信度C=360/600=0.6(答对第10题、第20题和第1题360人占答对第10题、第20题600人的比例)。
2 Apriori算法分析及其缺点
2.1 算法的基本原理和性质
Apriroi 算法是一个基于两阶段频繁项集的数据挖掘方法[2],将关联规则挖掘算法分为两部分:一是找到所有支持度大于最小支持度的项集,二是使用第一步找到的频繁项集产生期望的规则。
首先产生频繁1-项集L1,然后是频繁2-项集L2,直到有某个r 值使得Lr为空,算法停止。这里在第k 次循环中,过程先产生侯选k-项集的集合Ck,Ck中的每一个项集是对两个只有一个项不同的属于Lk-1的频繁集做一个(k-2)连接来产生的。Ck中的项集是用来产生频繁集的候选集,最后的频繁集Lk必须是Ck的一个子集。如果Ck中某个候选集有一个(k-1)子集不属于Lk-1,则这个项集可以被修剪掉不予考虑。
性质1:一个频繁项目集的任一非空子集必定也是频繁项目集[2];
性质2:一个非频繁项目集的任一超集必定也是非频繁项目集[2];
性质3:若一个事务包含K个元素,则该事务不可能包含k+1-项集[2];
性质4:K维数据项集XK是频繁项集的必要条件是它所有K-1维子项集也为频繁项集,记为XK-1[6]
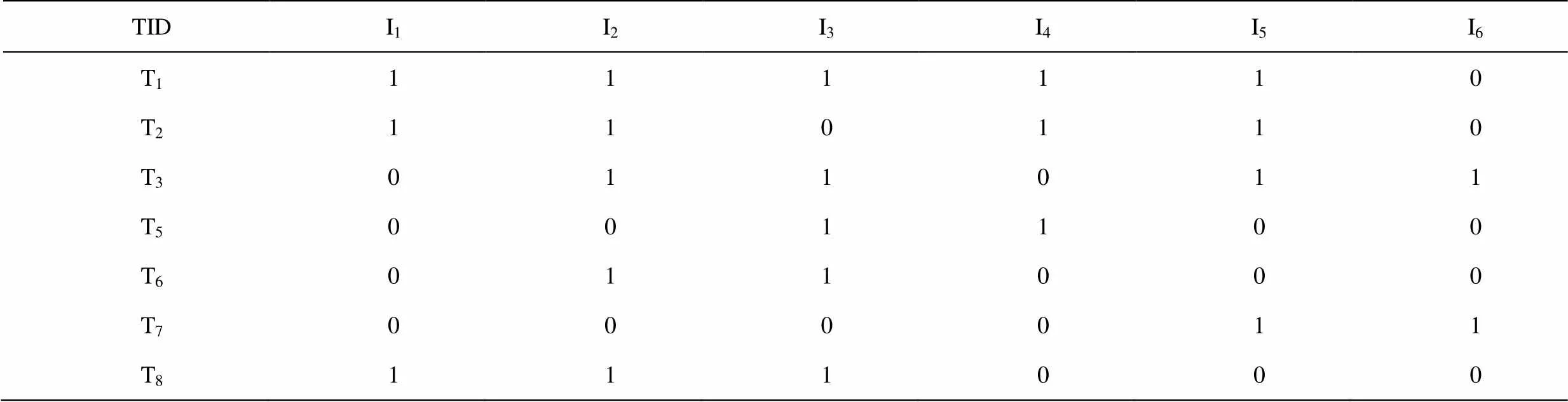
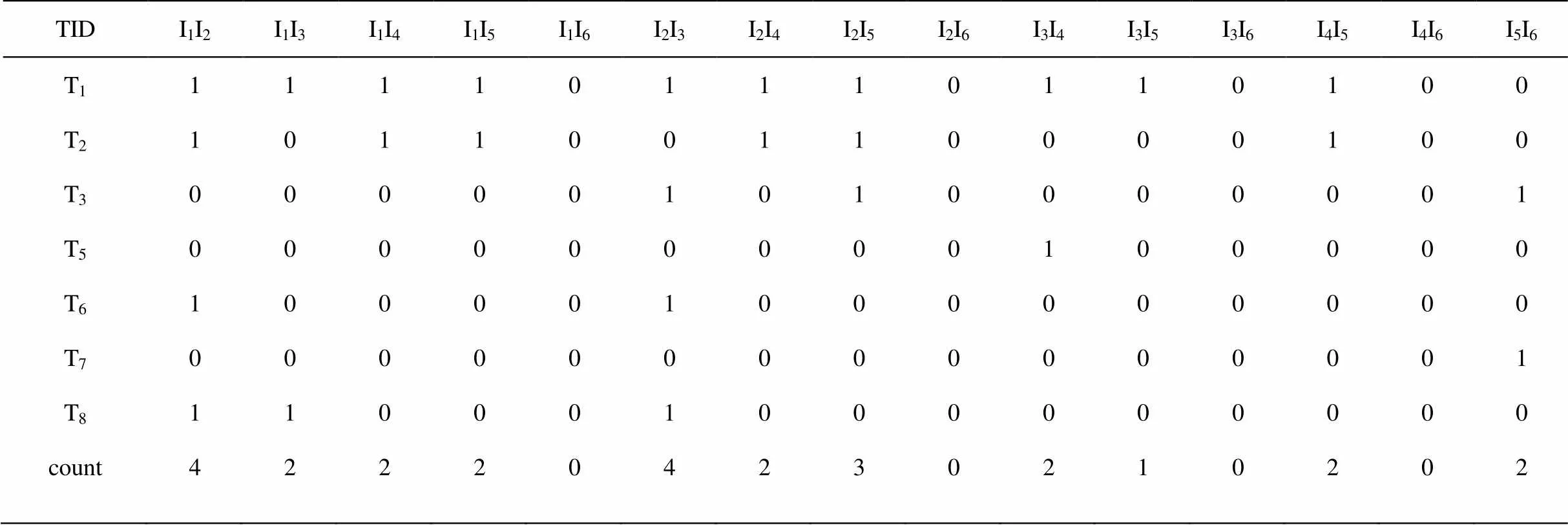
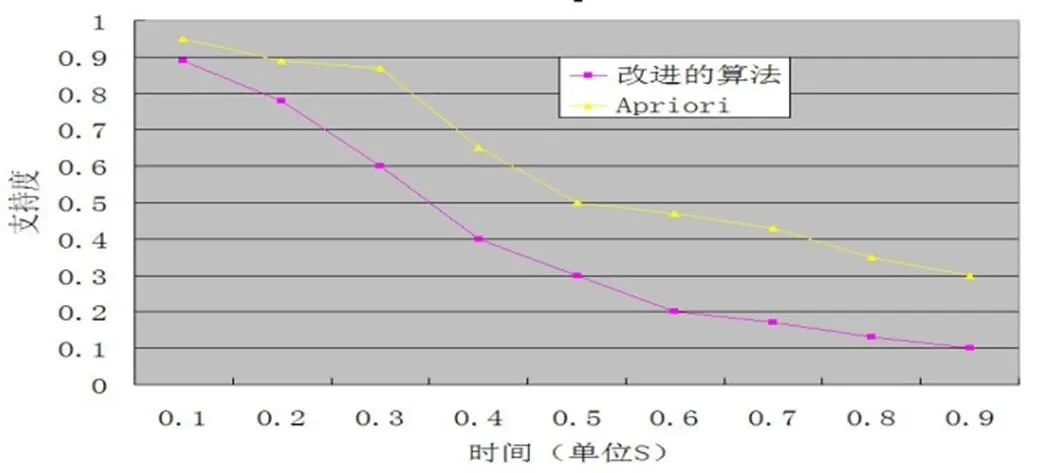
性质5:若在k-维数据项目集X={i1,i2, …,ik}中,存在一个j∈X,使得|Lk-1(j)| (1)连接步骤:连接(k-1)-频繁项集生成k-项候选集。可以连接的条件是2个(k-1)项的前(k-2)项相等并且第1个(k-1)项集的第(k-1)项比第2 个(k-1)项集的第(k-1)项小。记li[j]为li中的第j个项,则条件即为: l1[1]=l2[1]∧l1[2]=l2[2]∧…∧l1[k-2]=l2[k-2]∧l1[k-1] (2)删除步骤:利用Apriori 性质对k-项候选集进行剪枝。剪枝的规则是:若一个k-项候选集的任一子集((k-1)-项集)不属于(k-1)-项频繁集L,那么该候选k-项集就不可能成为一个频繁k-项集,可以将其删除。 (3)计数步骤:扫描数据库,累加k-项候选集在数据库中出现的次数。对于一条记录和一个候选项集,若记录包含该候选项集,则该候选项集出现的次数就加1。最后根据给定的最小支持度阈值(minsup)生成k-项频繁集。 (1) 由k-1阶频繁集生成K阶候选频繁集时,产生的候选项集太多,没有排除不应该参与组合的元素 (2) 由k-1阶频繁集生成K阶候选频繁集时,在K阶候选频繁集中过滤掉非频繁集的策略值得进一步改进。 (3) 连接程序中相同的项目重复比较太多,因而其效率值得进一步改进。 (4) 在回扫数据库时有许多不必比较的项目或事务重复比较。 针对以上提出的四点不足进行整改,在候选项集确定一个子项集是否频繁时,需扫描整个数据库。如果能将数据库中一些不必要的事务事先删除,则可减少扫描数据量。另外如果事先能过滤掉候选项集中的非频繁子集,这样也能减少计算量。同时在由LK-1组合成CK前,对将参与组合的元素进行计数处理,根据计数结果决定排除一些不符合组合条件的元素。本方法是将三者结合起来一起考虑。 选取8名学生某门课程的试卷部分试题得分情况的数据,对改进的算法进行详细的演示。假定支持度为2。数据表如表1: 表1 学生试卷得分情况表 注:Ii(i=1, 2,…,8)表示试题编号,Tj(j=1,2,…,8)表示学生编号,表中第i行第j列所对应得数值1表示第j个学生正确回答了第i题,SUM用来对事务中包含的项进行计数(即学生答对试卷中的题目数量),COUNT用来对表格中某列值为1的项进行计数(即某道试题被答对的学生数)。 从表1中,根据minsup =count≥2,得到1-频繁项集{I1}{I2}{I3}{I4}{I5}{I6}。 约简事务:从表1中可以看出TID为T4的事务只包含单项集{I6},T4不可能包含任何一个链接后的2-项集或者K-项集(K≧2)(性质3),故T4事务在后面的高阶频繁项集中不再用到,删除T4。得到表2: 表2 得到频繁1-项集L1 根据Apriori算法:项之间作逻辑与运算构成2-项集,结果如表3: 表3 由L1得到的候选2-项集C2 约简事务:由表3可以求出频繁2-项集,首先删除count<2的列,另外由于T5、T6、T7三个事务只包含2个元素,故在以后的3-项集或更高阶项集的链接中不再用到这些事务(性质3),将其删除。得到的频繁2-项集:{I1I2}{I1I3}{I1I4}{I1I5}{I2I3}{I2I4} {I2I5}{I3I4}{I4I5}{I5I6}。得到表4: 表4 由C2得到的频繁2-项集L2 根据Apriori算法的:项之间作逻辑与运算构成3-项集,结果如表5: 表5 由L2得到的候选3-项集C3 约简事务:由表5可以求出频繁3-项集,首先删除count<2的列,另外由于T8三个事务只包含3个元素,故在以后的4-项集或更高阶项集的链接中不再用到这些事务(性质3),将其删除。得到频繁3-项集{I1I2I3}{I1I2I4}{I1I215}{I1I4I5}{I2I3I5}{I2I4I5}。得到表6: 表6 由C3得到的频繁3-项集L3 在由L3产生C4前进一步约简:根据性质5,在第k步中,根据k-1步生成的k-1维频繁项目集来产生k维候选项目集,产生k-1维频繁项目集时,对该集中出现元素的个数进行计数处理,因此对某元素而言,若它的计数个数不到k-1的话,可以事先删除。根据频繁3-项集得到的元素计数:{I1:4, I2:5, I3:2, I4:3, I5:3},故可以删除包含I3元素的频繁3-项集。然后进行逻辑与运算得到4-项集,如表7: 表7 由L3得到的修选4-项集C4 由表7可以看出,最终产生频繁4-项集{I1I21415}。 为了证实对Apriori算法的改进效果,对Apriori算法和改进的算法进行了测试。数据来源于我校2010年《计算机基础》课程中的数据,将1000人的答题情况转换为布尔型事务数据库,然后进行测试。 图1 算法效率对比 图1为改进的算法和传统的Apriori算法在不同的支持度下找出所有频繁项集所用的时间对比图。实验结果表明在支持度比较大的时候两个算法性能差异不大,当支持度比较小也就是产生的频繁项集比较多的时候,则性能差异比较大。 以上通过关联规则算法挖掘出了频繁项集后,再对频繁项集进行分析,找出教师或者教学管理部门感兴趣的模式或规则,得到试卷中试题之间有用的强关联规则。假定给定置信度90%,则产生的部分强关联规则如表8: 表8 由频繁项集产生的强关联规则 在对试卷的难度及每道题的知识点全面分析后,再根据挖掘结果进行分析,并以{I4,I5}→ {I1}[25%,100%]强关联规则为例进行分析,不再逐一进行分析。该强关联规则表明:25%的学生答对了I4、I5题,但是答对I4和I5题的学生全部答对了I1题。这表明I1题和I4、I5题具有很强的关联联系,从试卷的质量上来说I1题和I4、I5题在知识点上可能重合,或者该知识点非常重要所以有意的强化该知识点;从教学上面来说,教师可以重点讲授I4题和I5题的知识点,而不是I1的知识点,掌握了I4题和I5题的知识点后,自然就理解或掌握了I1,这样对于教师有针对性的授课和改进教学方法都提供了理论依据。从教学内容的组织上来说,教师应该先讲授I4题和I5题的知识点;对于学生而言,将学习的重点放在I4、I5题,指导学生有侧重点的学习和复习,达到学习效率更高效,学习效果更好。以上的信息对教学具有非常好的指导作用,为相关部门决策提供理论依据,有促于教学大纲的制定以及学生复习计划的执行。 试卷评估是每个学校教学中的重要环节,我们要充分利用试卷中的信息,挖掘出有意义、有价值的信息,就可以为教师有针对性地调整教学计划,调整教学策略以及改进教学方法提供科学依据,进而提高教学质量。文章是对学生答对的题目重点进行关联分析,也还可以对学生失分的题目进行关联分析[5],进而帮助老师有侧重点的教,也帮助学生有侧重点的学。 [1] Tan Pangning, Steinbach M, Kumar V. Introduction to Data Mining[M]. 北京: 人民邮电出版社, 2006. [2] Han Jiawei, Kamber M. Data Mining. Concepts and Techniques[M].北京: 机械工业出版社, 2001. [3] 贾文,臧明相,周鸿.基于数据挖掘的课程相关性研究与分析[J].计算机技术与发展,2006,16(12):178-180. [4] 赵辉.数据挖掘技术在学生成绩分析中的研究及应用[D].大连:大连海事大学,2007. [5] 张瑶, 陈高云, 王鹏.数据挖掘技术在试卷分析中的应用[J].西南民族大学学报:自然科学版,2008,34(4):839-842. [6] 钱光超,贾瑞玉,张然,等.Apriori算法的一种优化方法[J].计算机工程,2008,34(23):196 -198. Design and Implementation of News Gathering System Based on Web Structure *CHEN Shi-bao1,WU Guo-fen2 (1.Anhui Finance and Trade Vocational College, Hefei, Anhui 230601, China;2.Hefei University of Technology, Hefei,Anhui 230009, China ) Examination paper evaluation is a very important part of the traditional assessment methods in the teaching work. According to the macroscopic analysis on the examination paper and the lack of microscopic analysis, we improves the Apriori algorithm of the examination paper analysis which excavates the knowledge correlation, improves their teaching methods, optimizes the effect of teaching and the quality of the proposition. It also has a huge role in guiding students learning and theoretical basis for the decision provided for teaching management. apriori algorithm; examination paper evaluation; association rules; data mining TP274 A 10.3969/j.issn.1674-8085.2012.02.015 1674-8085(2012)02-0058-05 2012-01-08; 2012-02-21 *陈世保(1981-),男,安徽合肥人,工程师,研究生,主要从事数据库技术研究(E-mail:Chenshibao@189.cn); 吴国凤(1964-),女,安徽合肥人,副教授,硕士生导师,主要从事计算机网络技术、网络安全研究(E-mail:guofen@163.com).2.2 Apriori算法三个步骤
2.3 Apriori算法的缺点
3 Apriori算法的改进和在试卷分析中的应用
3.1 改进的思想
3.2 在试卷分析中的应用





3.3 算法评估
4 规则产生

5 关联规则结果分析
6 结论
