《中国大学生心理健康量表》的因子结构探究
2012-10-17陈志方沐守宽
陈志方,沐守宽
(漳州师范学院 教育科学与技术系,福建 漳州 363000)
《中国大学生心理健康量表》的因子结构探究
陈志方,沐守宽
(漳州师范学院 教育科学与技术系,福建 漳州 363000)
目的:探究《中国大学生心理健康量表》的因子结构.方法:采用《中国大学生心理健康量表》对漳州师范学院2011级新生施测,筛选出说谎量表得分为零且未出现缺失作答的被试2141人,将样本随机分成校准(calibration)样本(n=1140)和验证(validation)样本(n=1001),分别进行探索性和验证性因素分析.结果:探索性因素分析得到《中国大学生心理健康量表》的单因子和二因子结构,验证性因素分析表明,与单因子结构相比,二因子结构模型拟合较好(RMSEA=0.099,SRMR=0.041,NNFI=0.925,CFI=0.940),本研究二因子结构得到了支持.结论:《中国大学生心理健康量表》存在二因子结构:“神经质”和“精神病性”.
中国大学生心理健康量表;因子结构;因素分析
1 问题提出
随着社会的发展和进步,人们也越来越体会到心理健康的重要性.而大学生处于心理和思想尚未成熟的半社会化的特殊阶段,则更容易产生一系列的思想问题和心理困惑.因此,编制一套科学合理、客观的评估大学生心理健康的量化工具对于大学生心理问题的预测诊断有着十分重要的现实意义.当前特定针对大学生心理健康而编制的量表主要有郑日昌等人[1]编制的《中国大学生心理健康量表》(简称CCSMHS)、王欣等人[2]编制的《大学生心理健康量表》以及李东方[3]编制的《大学生心理健康量表》.本研究基于CCSMHS.
CCSMHS最终设定了测量大学生心理健康的12个维度[1],此维度最先来自于访谈法、经验的建构,并借鉴了SCL-90的6个维度.CCSMHS并未对量表的因子结构做进一步的探索与验证研究,至今仍缺乏对于此结构的探讨,其结构的科学性与合理性有待进一步地检验.
基于以上认识,本研究采用多种手段,对大学生心理健康量表的12个维度进行探索性和验证性分析因素分析,并同时对其他相关问题进行了探讨.
2 研究方法
2.1 被试
采取整群抽样方法,被试为漳州师范学院2011级本科生及研究生,有效样本5333人.本研究从中选取说谎量表得分为0的被试2356人,并剔除掉出现缺失作答的被试215人,余下样本共2141人,其中男生731人,女生1410人,本科生年龄介于18-20岁之间,研究生年龄介于21-30岁之间.
2.2 施测
问卷施测在新生入学的一个月内完成,由校大学生心理咨询中心组织实施,心理学专业研究生及专业教师作为主试,所有被试以系为单位在大教室进行测试.所有被试均被告知测验的目的:(1)建立新生入学心理档案;(2)鉴别筛选出存在心理障碍的学生并加以干预.测试时间大约20分钟.测试完成后的一个月内,每个被试都会收到一份心理健康评估报告.
2.3 研究工具
《中国大学生心理健康量表》,由郑日昌等人于2005年编制,是教育部社政司组织研发的“中国大学生心理健康测评系统”的一个分量表,专门用于评估中国大学生心理健康状况[1],近年来在全国高校的新生入学中得到了广泛的使用.该量表由104个项目组成,13个分量表,包括躯体化、焦虑、抑郁、自卑、偏执、强迫、社交退缩、社交攻击、性心理、依赖、冲动、精神病,说谎量表,包含的项目数分别为 9、6、7、11、12、7、10、10、8、7、8、6、3 个.所有项目均采用 Likert 5 点计分(1没有~5总是).CCSMHS编制过程严格谨慎,量表具有较高的内部一致性信度和重测信度,内容效度、结构效度、效标效度、实证效度被证实均较为理想[1].在本研究中,分量表的内部一致性系数介于0.646至0.846之间.
2.4 数据分析
采用SPSS13.0、LISREL8.70进行描述性统计与探索性因素分析;使用EQS6.1进行验证性因素分析.
在探索性因素分析中,本研究采用了四种判断结构维度的标准:(1)“特征根>1”法,特征值大于1准则是几乎所有统计软件的默认选项,因此也相应成为实践中应用最普遍的确定因子个数的方法,即保留特征值大于等于1的因子,舍弃特征根小于1的因子[4].(2)碎石图法,按照因子被提取的顺序画出因子特征值随因子个数变化的散点图,根据图的形状来判断保留因子的个数,曲线由陡峭变的平缓的前一个点被认为是提取的最大因子数[5].(3)平行分析法,它首先生成一组随机数据矩阵,接着求出这组随机数据矩阵的平均特征值,最后通过比较真实数据特征值的碎石图与随机矩阵特征值的曲线来确定保留的因子数目.(4)Goldberg的方法[6],涉及到不同水平抽取的因子的相关,绘制出因子分裂的维度图表,根据图表来决定可以舍弃的不重要的因子.当提取出了新的一个因子时,可以解释的总的方差减少或者没有有意义的因子出现时,因子提取过程也就结束了(Goldberg,2006).
其中最常用来确定因子个数的准则是“特征根>1”法和碎石图法,但这两种方法又各有其不足之处,特征值大于1准则只适用于主成分法所求解的因子,运用其它方法进行因素抽取时,我们不能根据特征值的大小来判断应保留因子的个数.利用碎石图确定因子个数不可避免具有一定的主观性,并且有时碎石图上并没有明显的折点,或者有多个折点,难以判断保留因子的个数[5].平行分析(Parallel Analysis)为探索性因素分析中所保留因子个数的确定提供了另一种新思路.本研究通过四种方法的结合运用,以求更加精确地确定大学生心理健康量表的结构维度.
3 结果与分析
3.1 项目分析
描述统计选取平均数、标准差、正态分布检验以及频数分布图,正态分布检验采用Shapiro-Wilk 正态分布检验(Shapiro-Wilk test of normality).如表1结果显示,平均数分布有略微的倾斜,自卑、偏执、社交退缩平均分最高;其次是社交攻击、强迫、躯体化、抑郁、依赖、冲动;性心理和焦虑得分较低;得分最低的是精神病维度.正态分布检验表明,各分量表的因子得分均呈现正偏态分布.根据各维度得分的人数分别作频数分布图,所有图均呈正偏态分布,这与正态分布检验的结果是一致的.因为量表所有项目均采用反向计分,分数越高,越有可能存在心理障碍,反之,分数越低,心理越健康,所以符合理论构想.
关于量表的信度,该量表用4道测谎题来鉴别被试是否认真答题或是否按照自己真实情况作答,并以被试在这4道题上的得分之和等于4分做为剔除废卷的标准,在一定程度上提高了此量表的信效度.本研究仅选取了测谎维度得分为0的样本,又进一步提升了信度和效度.将该量表的内部一致性系数作为信度的指标,结果如表1,另外总量表的α系数为0.967.数据表明,该量表的信度较高,具有一定的稳定性.

表1 描述性统计
3.2 因素分析
3.2.1 探索性因素分析
将样本随机分成校准(calibration)样本(n=1140)和验证(validation)样本(n=1001);用校准样本进行探索性因素分析.关于探索性因素分析方法的几点说明:(1)采用了四种判断结构维度的准则;(2)本研究中因子抽取使用公因子法(principal axis factors),原因在于,主成分法(principal components)的主要功能是简化数据,即以最少的因子数最大程度地解释原始数据中的方差.当目的是确定数据结构时,则公因子法更为合适;(3)因子旋转的方法为正交方差最大化旋转(varimax).
(1)“k 大于 1”准则
12 个因子的特征值依次为 6.678、0.991、0.840、0.657、0.573、0.515、0.386、0.365、0.287、0.260、0.245、0.203. 可知,仅有一个因素的特征值大于1,为6.678,第二和第三个特征值分别为0.991、0.840.根据特征值大于1准则,应保留1个因子.
(2)碎石图与平行分析
如前文所叙,特征值大于1准则有时候是不够精确的,可运用平行分析方法对真实特征根与95%分位随机特征根做比对(如图1).观察碎石图可以发现,从第2个点开始曲线由非常陡峭变得趋于平缓,这表明与第1个因子相比,第1个因子后的所有因子均解释了很少的变异;观察平行分析曲线,第2点位于碎石图的第2点之上.以上均表明,应舍弃第2点之后的因子,仅保留1个因子.碎石图与平行分析的结果与特征值大于1准则所得结果是相一致的.

(3)Goldberg的方法
Goldberg技术揭示出当提取成分时,数据如何分裂成不同的维度,见图2.

图2 基于Goldberg技术的、3种抽取水平下的因子相关图
根据旋转后的成分载荷及其所包含的内容,试验性地得出图2中的成分命名.从图2可获知,2—3层均包括神经质(Neuroticism)和精神病性(Psychoticism)这两种成分.第3层提取出了仅包含两个维度的成分:性心理、强迫成分,此成分不满足鉴别度(identification)要求.仅仅包含一两个方面的成分是不能作为因子的,因为一个因子应该包含较广泛的内容.而神经质和精神病性这两个成分在各个层次上均达到了饱和.
考虑到旋转策略时,鉴于斜交旋转方法有时候是优于正交旋转的,所以此处采用了这两种方法,加以对比,以使结果更加精确.采用斜交旋转得到了相差甚微的数据,各个层次提取出的成分也与正交旋转相一致.
基于以上考虑,利用Goldberg技术,抽取出了两个因子,分别命名为“神经质”、“精神病性”.
如果严格按照(1)和(2)的标准,本研究仅抽取一个因子.但是第二个因子的特征值为0.991,非常接近于1;并且(2)中平行分析曲线的第2点与碎石图的第2点几乎重合,所以抽取两个因子也是可取的.综合(1)(2)(3)所述,本研究探索性地抽取一个或两个因子.根据因子包含成分及其负荷大小(见表2),当抽取单因子时,将其命名为神经质(Neuroticism),所包含的项目依次为偏执、焦虑、自卑、抑郁、社交退缩、社交攻击、精神病、躯体化、冲动、强迫、依赖、性心理;当抽取两个因子时,将因子1命名为神经质,所包含项目依次为自卑、社交退缩、焦虑、抑郁、依赖、强迫、性心理,将因子2命名为精神病性,所包含项目依次为冲动、社交攻击、躯体化、偏执、精神病.
3.2.2 验证性因素分析
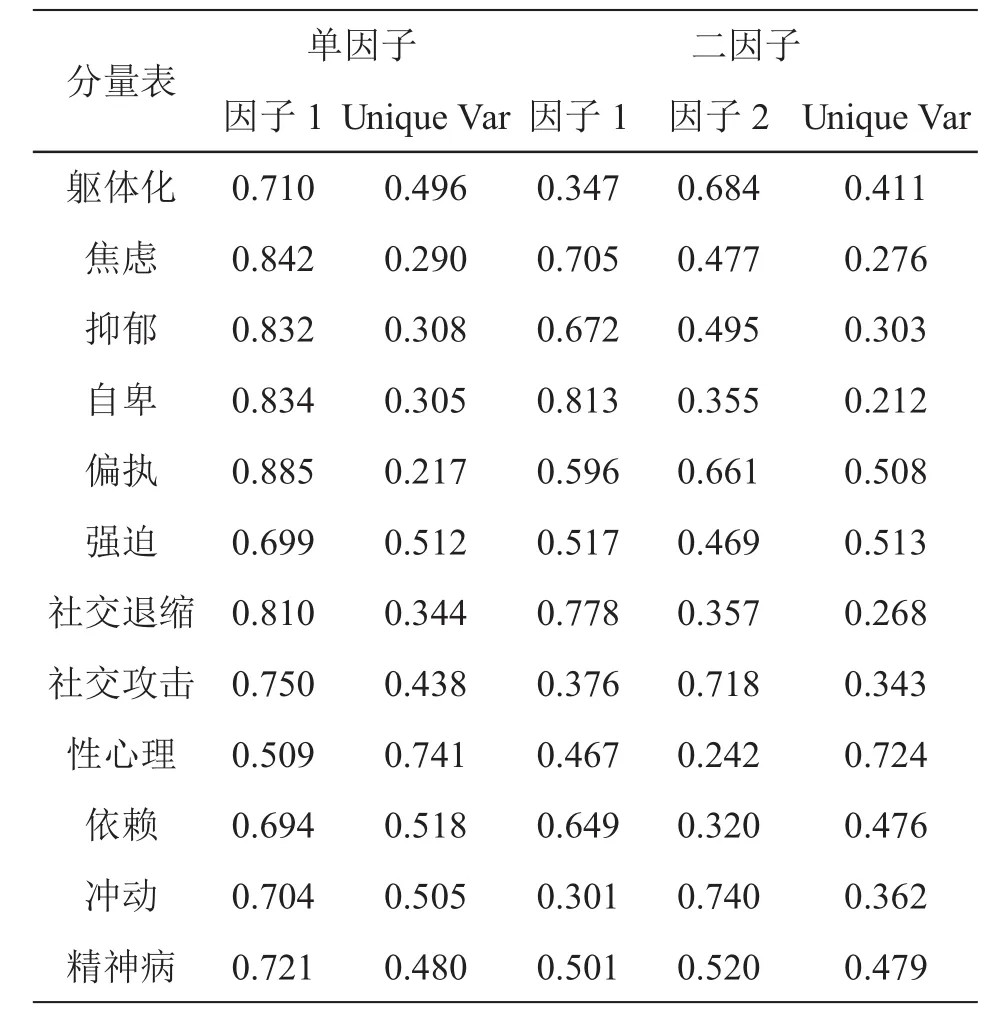
表2 单因子和二因子结构的因子载荷
在探索性因素分析基础上,用EQS6.1对验证(validation)样本(n=1001)进行验证性因素分析,检验CCSMHS 12个分量表的因子结构效度.模型拟合指数选取S-B(Satorra-Bentler scaled chi-square)、RMSEA (the root-mean-square error of approximation)及其90%置信区间、SRMR(the standardized root mean square residual)、NNFI(the non-normed?t index)、CFI(comparative fit index)等.各项拟合指标见表3.

表3 单因子、二因子结构的验证性因素分析
表3显示,单因子结构中,SRMR小于0.08、CFI大于0.90,但 NNFI小于 0.90、RMSEA 大于 0.10,NNFI、RMSEA显示模型拟合较差.与单因子结构相比,二因子结构的模型拟合较好.本研究的二因子结构得到了支持.
4 结论
本研究基于多种确定因子结构的方法,最终得到了中国大学生心理健康量表的二因子结构:“神经质”、“精神病性”,验证性因素分析较好拟合了二因子结构.这为量表的进一步研究与应用提供了参照.
〔1〕郑日昌,邓丽芳,张忠良,郭召良.中国大学生心理健康量表的编制[J].心理与行为研究,2005,3(2):102-108.
〔2〕王欣,张月娟,翟红娟,左晓东.“大学生心理健康量表”的编制和信效度研究[J].中国临床心理学杂志,2005,13(1):29-30.
〔3〕李东方.大学生心理健康量表的编制[D].华中科技大学,2008.
〔4〕Thompson,B.,&Daniel,L.G.Factor analytic evidence for the construct validity of scores:A historical overview and some guide2lines[J].Educational and Psychological Measurement,1996,56(2):197–208.
〔5〕孔明,卞冉,张厚粲.平行分析在探索性因素分析中的应用[J].心理科学,2007,30(4):924–925.
〔6〕Goldberg,L.R. (2006).Doing it all bass-ackwards:The development of hierarchical structures from the top down.Journal of Research in Personality,40,347–358.
〔7〕师晓宁,刘晓红,徐燕等.心理测验在我国大学生心理健康评价中的应用现状及存在问题 [J].健康心理学杂志,2003,11(4):281~283.
〔8〕卢国华,梁宝勇.坚韧人格量表的编制[J].心理与行为研究,2008,6(2):103~106.
〔9〕Shryack J.etc.The structure of virtue:An empirical investigation of the dimensionality of the virtues in action inventory of strengths[J].Personality and Individual Differences ,2010(48).
〔10〕刘华山.心理健康概念与标准的再认识[J].心理科学,2001,24(4):481~482.
G441
A
1673-260X(2012)03-0200-03
