基于语言学知识的查询个性化潜力预测
2012-10-15赵铁军杨沐昀齐浩亮
陈 晨,赵铁军,李 生,杨沐昀,齐浩亮
(1.哈尔滨工业大学 计算机学院,黑龙江 哈尔滨150001;2.黑龙江工程学院 计算机系,黑龙江 哈尔滨150050)
1 引言
在信息检索时,相关性(Relevance)是需要考虑的主要问题。通常,文档相关意味着用户提交查询后,返回的文档中包括用户需要的信息。文档相关性又包括主题相关性(Topical relevance)和用户相关性(User relevance)[1]。主题相关性指的是文档包含了查询的主题。用户相关性则考虑了用户的信息需求。
与仅考虑主题相关性的传统搜索引擎相比,个性化搜索引擎则进一步考虑用户的信息需求。之所以要考虑用户的信息需求,是因为用户提交的查询通常较短,而且常常会出现歧义。个性化信息检索的难点之一就是要理解不同用户提交查询的歧义性,并确定查询将多大程度上受益于个性化信息检索。例如,输入“苹果”查询的用户,既可能寻找水果苹果,也可能是寻找苹果牌电脑。本文中,查询歧义是指查询在语言学上的歧义,所以查询个性化潜力不同于查询歧义性。查询歧义性是查询本身的语言学特征,而查询个性化潜力则与用户搜索行为有关。歧义查询并不一定需要个性化,但是高个性化潜力的查询一定需要个性化才能满足用户的信息需求。例如,“alloy”是一个歧义查询,既可以指金属混合体,也可以指一个流行游戏的名字(合金弹头)。虽然“alloy”是歧义查询,但是根据查询日志计算得到它的个性化潜力很低,主要原因是用户输入这个查询,大多数用户搜索的都是游戏(合金弹头)。根据查询日志,查询“evolution”的个性化潜力很高,如果不知道输入该查询用户的信息需求,很难返回令用户满意的检索结果。
已知查询的个性化潜力之后,需要用户信息个性化排序检索结果。用户的兴趣爱好决定了用户信息需求。个性化信息检索的一个重要假设就是用户的查询历史可以区分不同用户的信息需求。许多研究机构根据用户兴趣建立个性化的信息检索模型[2-3]。这些模型对所有查询都使用相同的个性化算法和参数。然而,Dou等人[4]发现,个性化信息检索只能改善某些查询的检索结果,而对其他查询反而会带来负面影响。这表明对于一些查询,个别用户的理解和大多数用户的理解存在巨大差异。
为了衡量这种差异,Teevan等人[5]通过大规模的用户日志,分析用户查询意图的差异。他们发现基于点击的间接衡量指标可以真实地反映直接衡量指标。间接衡量查询歧义的指标有两个,都可以通过查询日志计算出来。第一个是点击熵[4],该指标反映了不用用户点击的混乱程度。第二个是根据NDCG定义的Potential@N[6],该指标描述了个人的最佳排序和群体的最佳排序的差异。然而,基于点击的查询个性化潜力的衡量指标只适用于拥有大量查询历史的查询,而对于只有少量查询历史的查询则不适用。因此,查询日志的数据稀疏问题严重影响查询个性化潜力预测的准确率。
此外,Teevan等人[5]提出了使用查询特征、用户交互历史特征和返回结果特征,预测查询的个性化潜力。该方法容易受到查询日志数据稀疏问题的影响。为了解决查询日志的数据稀疏问题,本文提出了使用大规模知识库Wikipedia的解决方案。首先,从Wikipedia中挖掘出大量的语言学知识,然后使用这些知识帮助预测查询的个性化潜力,这样就可以减少搜索日志数据稀疏问题的影响。
有许多语言学资源可以用于分析查询歧义,如WordNet[7]。根据查询个性化潜力的实际情况,选择Wikipedia作为语言学资源,用于预测查询的个性化潜力。大规模知识库Wikipedia包括大量的概念词、同义词和歧义词知识,可以帮助预测查询的个性化潜力。尝试利用语言学知识定义特征,然后训练机器学习模型,预测查询个性化潜力。
本文的创新点主要有两个:第一,之前关于查询个性化潜力的研究工作主要使用查询、检索结果和用户交互历史。很少有工作研究使用语言学知识,预测查询的个性化潜力。可能的原因是根据用户交互历史很容易定量地分析查询歧义,而使用语言学知识却很难定量地分析查询歧义。第二,实验结果显示,预测查询个性化潜力的时候,从Wikipedia中挖掘的语言学知识是有效的,Wikipedia特征可以减少查询日志数据稀疏问题的影响。
本文第2节是相关研究工作概述;第3节介绍如何从大规模知识库中挖掘语言学知识和定义Wikipedia特征;第4节对预测模型和预测目标进行描述;第5节说明如何给出实验结果并进行分析;第6节是本文的总结和工作展望。
2 相关研究工作概述
许多研究者提出个性化信息检索的方法,这些方法通过挖掘用户浏览行为和搜索历史,建模用户兴趣和偏 好[3,8]。 其他的工作[2,9]则把个性化直接加入到排序算法中。然而,这些方法都忽略识别哪些查询将受益于个性化检索,而对所有的查询都使用相同的个性化排序算法和设置。
对于识别不同类型查询的研究,两类研究与本文的研究相关:查询难度(或者歧义)预测和查询意图分类。已知一个检索系统和文档集合,查询难度(或者歧义)预测是判断在文档集合上,一个检索系统搜索一个查询,是否可能返回满意的检索结果。如果能够提前预测查询的难度,检索系统就可以采取适当的步骤改进检索效果。而查询意图分类是根据用户的查询意图把查询分到预先定义好的类别中。
许多研究者尝试各种方法预测查询难度(或者歧义),方法包括查询清晰度[10]、一致度[11]等。这些研究都是针对大多数用户的。本文的研究关注用户之间相关性判断的差异,而不是大多数人对查询难度的判断。Song等人[12]研究了查询歧义,把查询分成三类:歧义查询(Ambiguous query)、广义查询(Broad query)和明义查询(Clear query)。然后,他们使用各种特征预测是否是歧义查询,并人工标注了250个查询用于评价。然而,他们的工作没有涉及查询歧义与个性化信息检索的关系。
查询意图分类的主要目的是识别用户搜索时的意图。Border等人[13]把查询意图分成导航类(Navigational)、信息类 (Informational)和交易类(Transactional)。Kang等人[14]使用查询词出现模板,实现查询意图自动分类。Lee等人[15]建议两类特征,识别查询是否是信息类或者是导航类。这些工作没有说明查询意图分类和个性化信息检索的关系。和本文研究最相近的是Teevan等人[5]的工作。他们使用大规模查询日志和用户直接相关性判断,研究对于相同查询,不同用户意图的差异。他们通过查询字符串、检索结果和用户交互历史,提取各种各样的特征。受到以上研究的启发,本文工作使用语言学知识改进查询个性化潜力的预测效果。
一些研究者已经把语言学知识用于文本分类、语义元数据生成和汉语统计句法分析等任务。王锦等人[16]提出基于维基百科类别体系的文本特征表示方法,方法是将文本中的词映射到维基百科的类别体系中,使用类别作为特征来对文本进行表示。韩先培等人[17]提出基于Wikipedia的语义元数据生成,通过分析一个类别中条目的目录表来抽取目标语义元数据,通过对分析文档结构和赋予目标结构正确的语义元数据来构建训练语料库。熊德意等人[18]提出融合丰富语言知识的汉语统计句法分析。他们认为树库中潜在隐含的语言知识是非常丰富的,但它们并不是可以直接得到,往往需要特定的策略才能将它们融合到模型中。俞士汶等人[19]认为语言知识库的规模和质量决定了自然语言处理系统的成败,并建立一系列颇具规模、质量上乘的语言数据资源,让综合型语言知识库为语言信息处理研究、语言学本体研究和语言教学提供全方位的、多层次的支持。
3 语言学知识挖掘
本节先介绍 Wikipedia的组织结构,然后描述如何从 Wikipedia中挖掘语言学知识,最后说明如何使用语言学知识定义特征。
3.1 Wikipedia的组织结构
在讨论如何从 Wikipedia中抽取知识之前,先了解一下Wikipedia的组织结构。
(1)概念网页(Concept Pages)
Wikipedia包括两百万实体(entries),它们称为Wikipedia概念。一个概念有一篇介绍网页和其所属的目录。Wikipedia里的每篇文档描述了一个概念。每篇文档的标题都是简明的短语或者单词。例如,“Albert Einstein”是一篇介绍理论物理科学家的概念网页。概念网页包括的语言学知识主要是概念词。
(2)重定向网页(Redirect Pages)
Wikipedia为了保证每个概念只对应一篇文档,通过重定向网页把所有相同含义的概念链接到同一个概念网页。例如,“Einstein”就是一个重定向网页,因为它会被链接到概念网页“Albert Einstein”。所有重定向网页的标题可以看成被链接概念网页的同义词。重定向网页确保相同概念没有重复的网页描述,所以从 Wikipedia挖掘的统计信息可以真实地反映语言学知识。重定向网页包括了大量同义词的语言学知识。
(3)消歧网页(Disambiguation Pages)
消歧网页收集了大量具有歧义的概念。消歧网页的标题就是具有歧义的概念名称。例如,“Mercury”同时有一位罗马的神、一个星球的名称和一种化学元素等解释。消歧网页包括了很多歧义词的知识。
3.2 语言学知识
从Wikipedia的三类网页中,可以挖掘出各种各样的知识,本文把这些知识分成五类。
第一类是概念知识,从Wikipedia概念网页的标题中删除下划线和括号,可以获得很多有明确含义的表达,本文称之为概念词。
第二类是歧义知识,从消歧网页的标题中删除标签和标点,只保留唯一的标题。这里做一个假设,即经常出现在消歧网页标题中的词本身歧义倾向很大,那么包括这些词的查询具有歧义的可能性就很大。消歧网页的标题称为歧义词。
第三类是同义知识,具有相同重定向网页的标题被认为是同义词。
第四类是广义知识,来源是Wikipedia中的目录信息,因为目录中的词经常含义丰富,并且涵盖很多主题。
第五类是统计知识,来自所有 Wikipedia网页的索引,由于重定向网页,相同概念没有重复网页,所以Wikipedia包括丰富的语言学的知识更可以通过统计信息表示出来。
从Wikipedia中挖掘出来的知识也可能引入一些噪音,造成对查询的误解。然而,Wikipedia中挖掘的知识也有如下优势:第一,Wikipedia包括丰富的文本信息,统计语言学知识的质量则依赖于文本的丰富性和多样性;第二,Wikipedia网页具有一致的格式,这使得从它的标题和内容中抽取信息变得简单方便;第三,Wikipedia网页的内容能保证语义的一致性和主题相关性。
3.3 语言学特征
Wikipedia特征来源于从Wikipedia挖掘的语言学知识。如表1所示,本文根据特征的来源,把特征分成基于标题的特征和基于文档的特征,因为Wikipedia中的同义词和歧义词等知识都是通过标题体现的,而统计知识是通过文档体现的。基于标题的特征使用概念知识、同义知识、歧义知识和广义知识,而基于文档的特征使用统计知识。在表1中,括号里是特征的简称。

表1 用于预测查询个性化潜力的Wikipedia特征
(1)基于标题的特征
利用从Wikipedia标题中挖掘出的知识,定义了五个基于标题的特征。例如,查询是否匹配一篇歧义网页的标题,查询中歧义词的数量等。
(2)基于文档的特征
基于文档的特征可以根据使用的统计知识分成五类:IDF、SC、Dev、CS、Coh。
查询词IDF值中的最大值、查询词IDF值的平均值、查询词IDF值的标准方差、查询词kwok逆文档词频值的平均值和查询范围都是根据IDF特征。IDF的定义如下:

其中N是 Wikipedia中文档的总数,dft是文档中包含查询词t的文档的数量。
SC是所有查询词TFIDF值的总和。其他SC的特征也是根据TFIDF定义的。

其中N 是 Wikipedia中文档的总数,ft,d是文档d中查询词t的词频,dft是包括查询词t的文档数量。
CS衡量的是查询返回的高排序文档和整个文档集合的相似度。

其中p(t|q)是查询返回文档中查询词t出现的概率,p(t)是查询词t在索引中出现的概率。查询模型是根据高排序的20篇文档估计出来的。简单清晰度只根据查询字符串估计查询模型。
文档集合的一致性定义如下:

这里使用cosine相似度来计算查询返回的前20篇文档集合的一致性。
4 查询个性化潜力预测模型
本小节先介绍预测查询个性化潜力的预测目标,即点击熵和Potential@N,然后介绍模型使用的查询特征和历史特征。
4.1 查询个性化潜力的衡量指标
点击熵(Click entropy)和Potential@N都是查询个性化潜力的间接衡量指标,其值可以根据查询日志计算得出。点击熵用式(5)计算:

其中P(cu|q)是输入查询q后点击URLu的概率。
Potential@N是根据NDCG定义的用来衡量个性化潜力,其中NDCG的定义如式(6):

其中R(j,m)是对于查询j、文档m的相关等级,Zk是计算到第k个位置最佳排序的正则化因子。为了计算Potential@N,对于每个查询,都要分别计算个人最佳排序的NDCG和群体最佳排序的NDCG。两个NDCG值的差值被定义为Potential@N[6],其中N是群体中的人数。
4.2 预测模型使用的特征
查询特征和历史特征如表2所示。最基本的特征就是查询字符串,主要包括查询长度和命名实体特征。历史特征是从查询日志中抽取的,包括查询的用户数、查询的URL数等。

表2 用于预测查询潜力的查询特征和历史特征
5 实验结果及分析
5.1 实验设置
实验选择2006年3月1日到2006年5月31日的 AOL(美国在线)查询日志数据[20],从中抽取被至少50个不同用户提交过的查询。选择被至少50个不同用户提交过的查询,是为了保证有充足的数据,了解提交相同查询的用户之间信息需求的差异。表3是AOL数据和实验所用数据的统计信息。
下载了2009年10月份的Wikipedia英文数据,然后用indri①http://www.lemurproject.org/indri工具建立索引。取词根(Stemming)用的是Porter算法。

表3 AOL和实验使用的数据统计
5.2 实验一:查询日志和Wikipedia的覆盖率
根据上述的AOL查询日志和Wikipedia英文数据,初步分析了它们的查询覆盖率。如果一个查询完全匹配一篇 Wikipedia文章的标题,就称该查询被Wikipedia覆盖。如果一个查询在查询日志中被至少50个不同用户提交过,则称该查询有足够的点击历史。
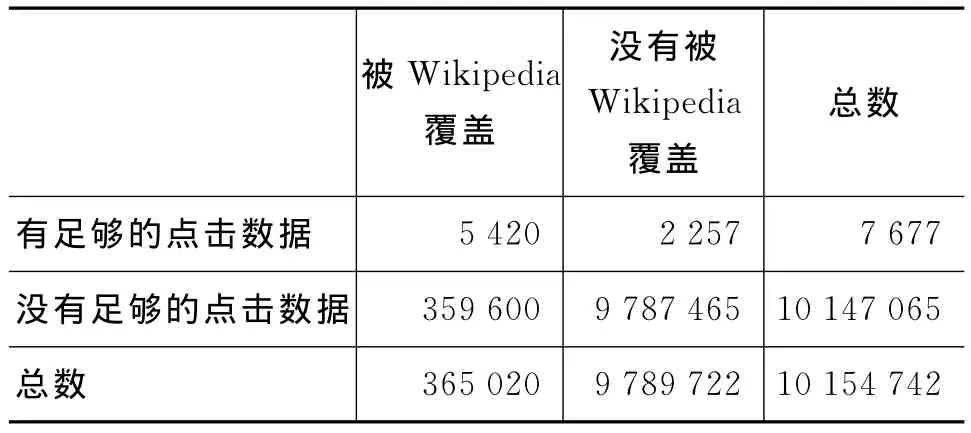
表4 足够的点击数据和被Wikipedia覆盖的查询的统计
表4是被查询日志和Wikipedia覆盖的唯一查询的统计数字。从表4可以得出如下发现。
第一,查询日志中有10 154 742查询,只有0.075 6%(7 677)的查询有足够的点击历史。这表明在查询日志中只有少量的查询具有足够的点击历史。
第二,在具有足够点击历史的7 677个查询中,有70.60%(5 420)的查询被 Wikipedia覆盖。这个比例保证研究Wikipedia对于查询个性化潜力预测的效果,还反映出Wikipedia可以多大程度地帮助那些没有足够点击历史的查询,预测个性化潜力。
第三,359 600个查询没有足够的点击历史,而被Wikipedia覆盖,占全部10 154 742个查询的3.54%。Wikipedia是比查询日志更丰富的知识库,因为查询日志为全部查询的0.075 6%提供知识,而Wikipedia却可以为为全部查询的3.59%提供知识。尤其,Wikipedia可以为那些没有足够点击历史,但却被 Wikipedia覆盖的查询提供丰富的语言学知识,帮助预测这些查询的个性化潜力。
5.3 实验二:预测模型性能
使用表1中的Wikipedia特征和表2中的查询特征和历史特征。按照Teevan等人的工作[5],把测试查询根据查询个性化潜力值四等分,所以Baseline就是25%。实验结果都使用五交叉验证。显著性检验采用双尾成对t检验。统计显著性检验(p<0.05)比较的是加入 Wikipedia特征前后的效果。
在计算点击熵和Potential@N时,假设用户点击的文档就是相关文档,即点击数据就是标注数据。Teevan等人[5]已经证明了用户点击的数据可以较为准确地得到查询个性化潜力值。
为了预测查询潜力,根据训练数据学习一个分类模型。Logistic回归模型和C-SVM模型被用于预测查询个性化潜力。实验的目的是比较常用的机器学习算法Logistic回归模型和C-SVM模型的性能。
Logistic回归作为概率判别式模型,该机器学习模型的主要优势是训练参数比较少。Logistic回归模型的公式如式(7):

其中wk是类别Ck的权重向量,φ是基函数。C-SVM作为分类模型用于查询个性化潜力预测,其公式如式(8):

其中w是权重向量,φ是基函数。
表5是模型使用不同的特征,预测不同目标值的结果。在“特征”列,“查询”指的是查询特征,“维基”指的是 Wikipedia特征,“历史”指的是历史特征。“*”表示加入 Wikipedia特征后,精度统计显著地提高。
从表5、表6可以看出,点击熵(Click entropy)和Potential@N的实验结果是一致的,也就是说使用相同的特征,如果点击熵的预测精度很高,那么Potential@N的预测精度也会很高。当仅使用查询特征时,预测精度较差,但是查询特征可以在一定程度上识别查询的个性化潜力。相对于34.95和33.32,加入 Wikipedia特征可以相对提升4.72%和10.38%的准确率,而且 Wikipedia特征的贡献是显著的。实际上,通过查询特征很难判断查询的个性化潜力,而从 Wikipedia中挖掘出来的歧义和同义知识可以发挥作用。例如,“evolution”匹配了57个概念网页的标题和1个歧义网页的标题,而且有较高的NSCQ和QC值。这些证据表明该查询的个性化潜力很高,根据查询日志也证实了这点。当缺少查询日志信息时,可以使用从Wikipedia中挖掘出来的知识预测个性化潜力,所以Wikipedia可以在一定程度上克服查询日志的数据稀疏问题。
历史特征非常有效,可以大幅度地提升预测精度,因为点击熵和Potential@N跟历史特征是高度相关的。实际上,如果已知一个查询的大量点击历史,就可以直接使用历史特征预测查询个性化潜力。在使用查询特征和历史特征的基础上,如果再加入Wikipedia特征,准确率稍有提升,可见 Wikipedia特征可以起到辅助预测的作用。
综合表5和表6的实验结果,在预测查询个性化潜力时,Logistic Regression模型和Support Vector Machine模型的性能几乎一样的,没有显著差别。由于Logistic Regression模型的计算复杂度较低,所以在以下特征贡献分析时,采用Logistic Regression模型。

表5 不同特征和预测不同目标时的Logistic Regression(LR)的模型性能

表6 使用不同特征和预测不同目标时的Support Vector Machine(SVM)模型的性能
5.4 实验三:特征贡献分析
本小节通过预测模型准确率的变化,深入地研究每个Wikipedia特征对于查询个性化潜力预测的贡献。根据表5的实验结果,发现点击熵和Potential@N的预测结果是一致的,所以,分析Wikipedia特征贡献的实验只考虑预测点击熵的情况。一个特征的贡献是显著的,当且仅当删除该特征后,准确率会显著下降,或者加入该特征后,准确率会显著提升。分析Wikipedia特征贡献的实验分成两部分:第一,先使用查询特征和全部Wikipedia特征,然后每次删除一个 Wikipedia特征,这样就可以得到去掉该特征后,预测模型的准确率;第二的变化情况,先使用查询特征,然后每次加入一类 Wikipedia特征。表7列出删除或者加入Wikipedia特征后,预测模型的准确率。

表7 预测点击熵时的特征贡献
表7中“leave one out”列表示删除一个 Wikipedia特征后的准确率。需要注意的是,每个特征不是单独评价的,删除该特征后预测准确率没有显著性下降,并不意味着该特征是无效的,而是有可能该特征和其他特征是相关的。根据去掉特征后,准确率下降的多少,可以看出最有效的特征是SumDev,第二和第三有效的特征是AvgICTF和MHT。由于实验的目的是检查每个Wikipedia特征在预测模型中的作用,而不是寻找最优的特征组合,所以这里没有做特征选择的迭代检验。此外,去掉一些特征后,预测模型的准确率却升高了,这说明相关的一些特征会起到负面作用。
在表7中,“Add one type in”列表示在查询特征的基础上,每次加入一类 Wikipedia特征后的准确率。除了CS和Dev特征类型外,其他特征类别都可以提高预测准确率。基于标题的特征、IDF相关的特征、SC相关的特征和Coh相关的特征的贡献都是显著的。
6 结论及下一步的研究
从Wikipedia中挖掘出大量语言学知识,然后利用语言学知识定义特征,建立查询个性化潜力预测模型。实验结果表明,在查询日志中,有很多查询没有足够的历史信息,却可以被Wikipedia所覆盖,所以Wikipedia是比查询日志更丰富的知识库。而且,从Wikipedia挖掘出的语言学知识,可以有效地提高查询个性化潜力预测准确率。在预测模型中,歧义词数量是最有效的基于标题的特征,而IDF类型的特征是最有效的基于文档的特征。Wikipedia特征可以降低查询日志数据稀疏问题的影响。即使对于日志数据充足的查询,Wikipedia特征也起到良好的辅助预测作用。
未来的研究工作可以从以下方面展开。第一,从Wikipedia中挖掘语言学知识,预测查询个性化潜力,其效果还不能用于搜索引擎,需要探索从其他资源中挖掘更多的语言学知识,进一步提高预测的准确率;第二,评价采用根据查询个性化潜力值四等分的方法,该方法需要进一步的研究;第三,有很多因素会影响查询的个性化潜力,未来会考虑加入更多的特征,使模型可以更加准确地预测查询个性化潜力。
[1]Croft B,Metzler D,Strohman T.Search engines:information retrieval in practice[M].Addison-Wesley Publishing Company,USA,2009.
[2]Shen X,Tan B,Zhai C.Implicit user modeling for personalized search[C]//Proceeding of the 14th ACM International Conference on Information and Knowledge Management.2005:824-831.
[3]Teevan J,Dumais S,Horvitz E.Personalizing search via automated analysis of interests and activities[C]//Proceeding of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2005:449-456.
[4]Dou Z,Song R,Wen J.A large-scale evaluation and analysis of personalized search strategies[C]//Proceeding of the 16th International Conference on World Wide Web.2007:581-590.
[5]Teevan J,Dumais S,Liebling D.To personalize or not to personalize:modeling queries with variation in user intent[C]//Proceeding of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2008:163-170.
[6]Teevan J,Dumais S,Horvitz E.Potential for personalization[J].ACM Transactions on Computer-Human Interaction(TOCHI),2010(17):1-31.
[7]Fellbaum C.Wordnet:an electronic lexical database[M].The MIT Press,1998.
[8]Chirita P,Nejdl W,Paiu R,et al.Using odp metadata to personalize search[C]//Proceeding of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2005:15-19.
[9]Haveliwala T.Topic-sensitive pagerank:a contextsensitive ranking algorithm for web search[J].IEEE Transactions on Knowledge and Data Engineering,2003(15):784-796.
[10]Cronen-Townsend S,Zhou Y,Croft W.Predicting query performance[C]//Proceeding of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2002:299-306.
[11]He J,Larson M,De Rijke M.Using coherence-based measures to predict query difficulty[J].Advances in Information Retrieval,2008(4956):689-694.
[12]Song R,Luo Z,Wen J,et al.Identifying ambiguous queries in web search[C]//Proceeding of the 16th International Conference on World Wide Web.2007:1169-1170.
[13]Broder A.A taxonomy of web search[C]//Proceedings of ACM SIGIR Forum.2002:3-10.
[14]Kang I,Kim G.Query type classification for web document retrieval[C]//Proceeding of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval.2003:64-71.
[15]Lee U,Liu Z,Cho J.Automatic identification of user goals in web search[C]//Proceeding of the 14th International Conference on World Wide Web.2005:391-400.
[16]王锦,王会珍,张俐.基于维基百科类别的文本特征表示[J].中文信息学报,2011,25(2):27-31.
[17]韩先培,赵军.基于 wikipedia的语义元数据生成[J].中文信息学报,2009,23(2):108-114.
[18]熊德意,刘群,林守勋.融合丰富语言知识的汉语统计句法分析[J].中文信息学报,2005,19(3):61-66.
[19]俞士汶,段慧明,朱学锋,等.综合型语言知识库的建设与利用[J].中文信息学报,2004,18(5):1-10.
[20]Pass G,Chowdhury A,Torgeson C.A picture of search[C]//Proceeding of the 1st international conference on scalable information systems,2006.
