基于混合策略的藏文虚词识别方法
2019-08-05拉玛扎西才智杰班玛宝
拉玛扎西,才智杰,班玛宝
(1. 青海师范大学 计算机学院,青海 西宁 810016;2. 青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008;3. 藏文信息处理教育部重点实验室,青海 西宁 810008)
0 引言
藏文是一种典型逻辑格语法体系的拼音文字[1],由实词和虚词按一定的语法结构组合而成。实词具有具体词汇意义,包括名词、代词、动词、形容词、数词等,可以单独使用;而虚词没有实际意义,包括语法虚词[2](格助词和接续助词)和关联词等,不能单独使用。计算机自动识别虚词对文本的歧义消解、句法分析、句型及语义处理等具有重要作用,并在藏文分词[3]和停用词选取[4]等方面有重要的应用价值。现有文献中未见详细面向自然语言处理的藏文虚词特征及其个数的分析,并且没有研究多音节虚词的识别。本文在分析传统藏文虚词研究成果的基础上,初步统计了面向自然语言处理的藏文虚词,并分析了藏文虚词的特征,从而提出了基于规则和最大熵模型相结合的藏文虚词识别策略。
本文组织结构如下: 第1节分析藏文虚词识别的研究现状和主要技术方法;第2节归纳并总结传统藏文文法和面向自然语言处理的藏文虚词,确定面向自然语言处理的虚词数量及特征;第3节设计基于规则和最大熵模型相结合的藏文虚词识别方法;第4节实验验证算法的有效性,并对存在的问题进行分析;第5节是结论与展望。
1 研究现状
分词既是藏语自然语言处理的一项基础性研究工作,也是一个存在很多难点的研究范畴。陈玉忠等[2]在分析藏文文本自动切分难点时指出,藏文分词中较难解决的问题有四类: ①由实词—实词、实词—虚词、虚词—实词、虚词—虚词的交集性字段引起的错误; ②由实词—实词、实词—虚词、虚词—实词、虚词—虚词的组合型歧义字段引起的错误; ③由紧缩词识别引起的错误; ④由未登录词引起的错误。在这四类错误中,前三项与虚词的识别有关。因此,藏文虚词(包括紧缩词)的识别问题引起学者们的关注。其中,紧缩词是一种特殊的虚词,学者们先后研究了紧缩词的识别问题。才智杰[5]首次提出了紧缩词的“添加—还原法”识别方法,识别准确率达99.83%,取得了理想效果。完么扎西等[6]在“添加—还原法”的基础上利用藏文文法规则识别紧缩词,其识别准确率达99.95%。李亚超等[7]为解决无法识别未登录词后的紧缩词问题,提出了基于条件随机场的紧缩词识别方法,其识别准确率达98.91%,克服了“还原法”中不能识别“未登录词+紧缩词”的问题。华却才让等[8]利用藏文紧缩词识别音节的方法,识别准确率达到了99.91%。康才畯等[9]采用基于词位的统计分析方法识别藏文紧缩词的准确率为95.89%,解决了未登录词对识别效果的影响。拉玛扎西等[10]通过剖析现有藏文紧缩词识别方法,分析藏文字词的特征,有针对性地提出了基于规则、添加—还原法与最大熵模型相结合的藏文紧缩格识别方法,其识别准确率达到了99.26%,相比现有准确率,有明显的提高。同样,在一般虚词识别方面,学者们也提出了若干识别方法。赵栋材[11]通过建立虚词兼类词典库,在采用正向最大匹配算法对文本切分后,利用不自由虚词的接续规则识别虚词(单音节虚词)。高定国等[12]提出了基于规则的藏文虚词识别方法,其识别准确率达97.08%。拉巴顿珠等[13]通过建立虚词兼类词典、单音节词典、规则的不自由虚词词典库等识别藏文虚词。由以上文献可见,特殊虚词紧缩词的识别问题利用统计与规则相结合的方法可以得到解决,但一般虚词的识别还不能满足实际需求。一般虚词的识别主要有两个不足点: ①识别方法只用了规则法。由于虚词的多样性,仅依靠规则不能识别出好的效果。正如文献[12]在实验分析中指出,在规则法的基础上引入统计方法,可以提高藏文虚词识别率。②没有具体分析虚词的特征,只是笼统地将藏文文法中提到的虚词认定为面向自然语言处理的虚词对象,其识别对象没有完全囊括藏文文本中的虚词。
2 藏文虚词及其特征
在藏文虚词识别研究的文献中,没有明确藏文虚词及其数量,因而在自然语言处理的各项研究中没能获得理想的成果。研究面向藏语自然语言处理的藏文虚词识别方法,依据藏文文法理论,并将其具体化,才能取得好的效果。本节通过分析传统藏文文法中虚词的定义及数量,确定了面向自然语言处理的藏文虚词,并分析其特点。
2.1 传统藏文文法中的虚词
藏文文法《三十颂》是一部最早阐述藏文文法的专著,里面有专门阐述藏文虚词的内容。《三十颂》从语法功能角度给出了虚词的定性描述: 虚词是指按语境添接在实词的前或中或尾部后,使各零散的实词具有一定意义的功能词[14]。《三十颂》中罗列的虚词都是单音节虚词。在后续的研究中,学者们对《三十颂》做了很多不同的解读,将虚词按音节数分为单音节虚词和多音节虚词[15]。文献[14,16-18]解读《三十颂》中对虚词的阐述,罗列了藏文虚词(下文中把这类虚词称为语法虚词),各文献收录的藏文语法虚词数量统计见表1。


表1 藏文语法虚词数量统计表

表2 藏文补遗虚词统计表
表2中的补遗虚词不包含语法虚词,语法虚词在藏文真实文本中经常出现,起到转折、关联等作用。
2.2 面向自然语言处理的藏文虚词
由于自然语言处理的特殊需求,面向自然语言处理的虚词不能直接选用传统藏文文法中规定的虚词,需要分析语法虚词中单音节虚词的语法作用以及在文本中的词性,并对个别在藏文文法中提到的补遗虚词进行相应处理后,才能最终确定虚词识别任务的处理对象。
本文在选取和识别面向自然语言处理的虚词时,遵循以下5条原则。





本文从表1、表2罗列的虚词中,遵循以上5条原则,确定了面向自然语言处理的552个虚词,面向自然语言处理的藏文虚词及其分布如表3所示。
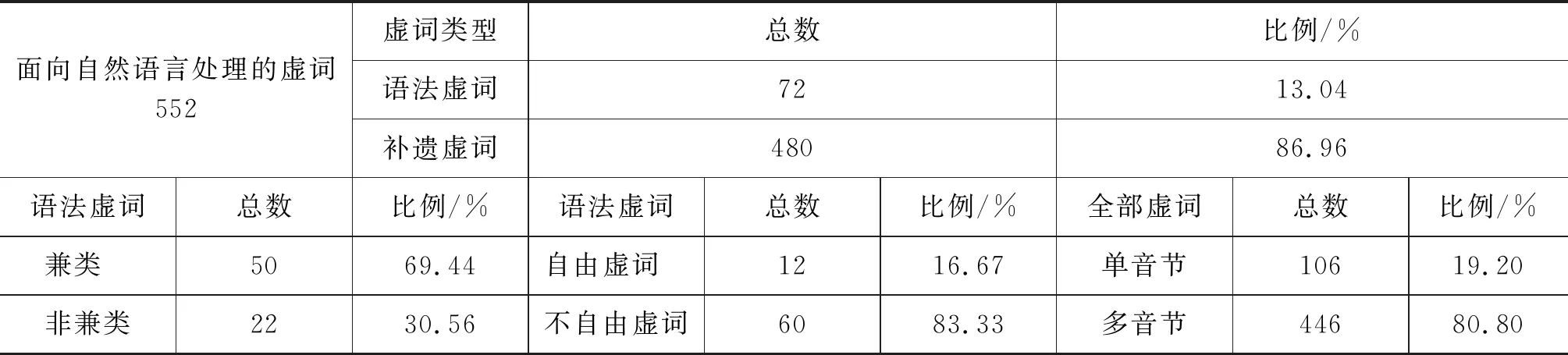
表3 面向自然语言处理的藏文虚词及分布表
由表3可知,在552个面向自然语言处理的藏文虚词中,有72个语法虚词和480个补遗虚词。72个语法虚词中兼类虚词有50个,480个补遗虚词中兼类虚词有16个。藏文语法虚词中兼类虚词所占比例高达69.44%,对虚词的识别带来了困难。语法虚词中自由虚词有12个,不自由虚词有60个,占语法虚词总数的83.33%,480个补遗虚词都为自由虚词。从虚词所含音节角度看,单音节虚词有106个,多音节虚词有446个,可见藏文虚词以多音节为主。
2.3 藏文虚词的特征
藏文虚词除了表示语法意义和不能单独使用的共性特征外,还具有以下5种个性特征。
(1) 黏着特征
(2) 兼类特征

(3) 实词中包含单音节虚词的特征

(4) 多音节虚词包含单音节虚词的特征

(5) 多音节虚词具有嵌套特征。

3 藏文虚词识别
3.1 藏文虚词识别策略
本文采用逆向最大匹配法和最大熵模型相结合的混合策略识别藏文虚词。其识别模型如图1所示。
图1 基于混合策略的藏文虚词识别模型
图1是根据藏文虚词特征提出的基于规则法和最大熵模型相结合的混合策略模型。针对虚词中具有黏着特征的紧缩词识别已有很多研究,其识别准确率达99.83%以上,本文运用了文献[5,10]中提出的“添加—还原法”和基于规则、添加还原法与最大熵模型相结合的藏文紧缩词识别方法,具体参见文献[5,10]。针对藏文虚词的第(4)类特征,文章采用多音节虚词优先识别策略,因此,基于混合策略的藏文虚词识别模型包含多音节虚词识别模块和单音节虚词识别模块。
多音节虚词识别模块在“包含虚词的实词库”中对文本预处理中逆向提取的8音节字串进行查找,若找到,则可断定8音节字串中无虚词;否则,在“多音节虚词库”上采用逆向最大匹配法判断是否为多音节虚词。这里只提取8音节字串的原因是藏文多音节虚词中最大音节数为8,而且“包含虚词的实词库”中的最大音节数也不超过8个。其中,“包含虚词的实词库”含719个词条,“多音节虚词库”含446个词条。
单音节识别模块首先判断多音节模块未能识别的最后一个单音节虚词是否为兼类词,若该单音节虚词不是兼类虚词,则一定为虚词;否则,该单音节有可能是虚词,也有可能是实词。然后,对这个单音节用最大熵模型判别其是否为虚词。由于单音节兼类虚词有33个,因而判别虚词的兼类性也比较简单。
3.2 最大熵特征模板
Jaynes于1957年首次提出最大熵原理,被广泛应用于自然语言处理领域。其基本原理是,在已知部分信息的前提下,关于未知分布最合理的推断应该符合已知信息最不确定或最大随机的推断[20]。藏文虚词识别可看作是一个序列标注问题,标注时对每个对象随机标注一个标签,并建立已知特征x的条件下输出标签y的概率分布模型p(p∈P)。其中,x属于上下文信息集X(x∈X),y属于对应的标签集Y(y∈Y)。从训练集中可获得N个样本集,即S={(x1,y1),(x2,y2),…,(xn,yn)},根据这些样本可以定义一个事件空间,其特征是一个二值函数f:X×Y→{0,1},其定义如式(1)所示。
则模型p的熵为:
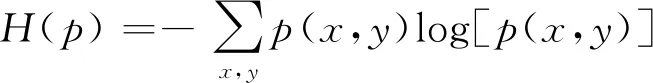
(1)
从式(1)中可得出最大熵模型,如式(2)所示。
(2)
式(2)中的C为符合约束条件的模型集合,然后计算满足C条件的最大p*,如式(3)所示。
(3)
其中,z(x)是归一化常数,并有式(4)。
(4)
式(3)、式(4)中的λi为模型参数,即特征fi对应的权重λi,可通过IIS算法来估计。
最大熵模型中,如何针对研究对象选择有效的上下文特征是一个关键问题。本文根据藏文词语音节的分布特点及上下文激发环境确定模型,并抽取特征模板。本文选取的特征模板如表4所示。

表4 特征模板
4 实验数据及分析
为了验证本文提出的藏文虚词识别方法的有效性,我们从青海师范大学才智杰教授研究小组建立的藏语语料库中选取了含30 404个音节的语料作为测试语料,语料领域包括政治、教材、历史、小说、新闻等五种题材。语料中含9 187个藏文虚词,利用本文提出的藏文虚词识别方法正确识别出了9 040个虚词,共出现187个识别错误,实验数据见表5。

表5 虚词识别实验数据

5 结论与展望
藏语虚词识别既是藏语自然语言处理的一项基础性工作,也是一项具有挑战性的研究工作,在藏文分词和停用词选取等方面有重要的应用价值。本文重点探讨了面向自然语言处理的藏语虚词及其语法特征,确定了面向自然语言处理的虚词及数量,提出了规则法和最大熵模型相结合的藏文虚词识别混合策略。实验表明,该方法识别藏文虚词的准确率、召回率和F1值分别达98.39%、98.75%、98.57%。今后在该研究成果的基础上,将进一步研究藏文分词及停用词选取技术,为藏文词向量表示奠定基础。
