数据挖掘技术在学生成绩管理系统中的应用
2012-10-13郭慧
郭慧
(山西华澳商贸职业学院,山西 太原 030031)
数据挖掘技术在学生成绩管理系统中的应用
郭慧
(山西华澳商贸职业学院,山西 太原 030031)
将数据挖掘技术引入到学生成绩管理系统中,能够对教育决策和教学评价提供强大的理论支持,提高教师“教”和学生“学”的质量。论文以学生成绩分析表为数据集建立挖掘模型,使用决策树ID3算法完成构建模型,并对模型的准确性进行了必要的评估。通过分析,得到相关属性与学生成绩之间的关系,并从中挖掘出学生成绩的好坏与哪些因素有关、它们之间存在怎样的关系等。
成绩管理;数据挖掘;决策树;ID3
作为决策支持过程的最新技术,数据挖掘能够深层次地对数据进行挖掘和分析,其无疑会对教学决策和教学评价提供强大的理论支持。在学生成绩管理系统中,数据挖掘技术的应用可以深入分析学生成绩与各因素之间潜在的关联。譬如,经过对学生成绩的相关分析,数据挖掘技术可以解决诸如“学生成绩的好坏与哪些因素有关”、“它们之间又是怎样的关系”的问题,其评价结果对于教与学的改进及提高意义重大。
在传统的教学过程中,习惯采用数据库查询的方法实现对数据信息的处理。笔者将采用数据挖掘技术中的ID3算法实现对数据的处理,并形成分类规则,从而更深入地分析此数据。
一、数据挖掘的流程
(1)明确挖掘对象及目标:定义好要解决的问题。此处以山西华澳商贸职业学院计算机2009级软件班学生,共有60名学生、12门课程、三个学期为例,希望根据学生的考试成绩,分析出学生成绩的好坏与哪些因素有关,并以此所得结果来指导并促进教师“教”和学生“学”。
(2)数据准备:从学生成绩管理系统的数据库中提取相应的数据,并进行预处理,如去除噪声、对丢失数据进行填补及删除无效数据等。
(3)数据挖掘:数据经过预处理后,根据数据功能的类型和特点选择相应的算法对其进行数据挖掘。
(4)结果分析:对挖掘的结果要进行必要的解释和评价,使其转换为易于用户理解的知识。
(5)知识运用:教师可以将分析所得知识运用到教学环节中,如进行教学决策,从而达到教学指导的目的。
二、数据仓库的建立
基于本数据挖掘的目标是分析学生成绩的好坏与哪些因互素有关,而学生成绩管理系统数据库的数据必然存在大量的冗余问题,此处必须对库的信息进行提取以便形成相关数据表。之后,还必须对数据进行相关性操作。
(1)数据集成
数据集成决不是简单的数据合成,而是在原始数据的基础上经过转换、提炼,形成规范化的、统一的、可挖掘的数据。此处针对数据库技术,将收集到的相关数据库文件进行利用SQL语句实现表的连接操作,从而生成“成绩分析”表,其数据结构为:学号、姓名、性别、作业、参加活动、平均成绩等。由于针对的是专业能力基本信息收集,一些无关属性应被剔除,如学生的出生日期、家庭住址等。集成后的数据如下:
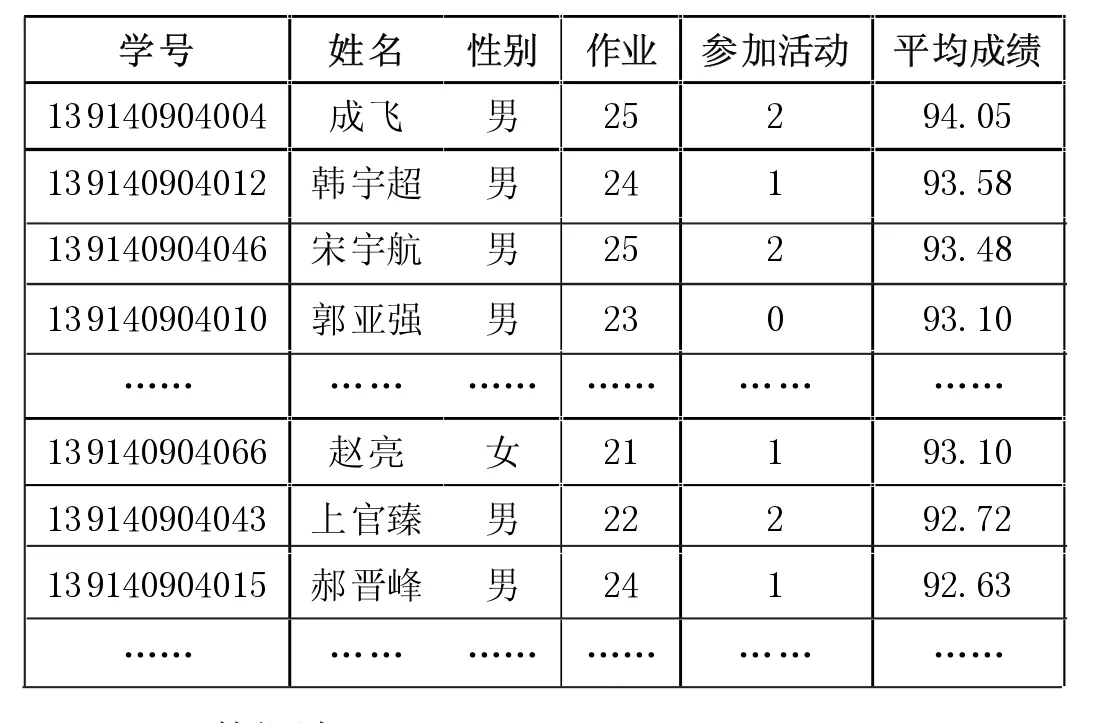
表1 学生成绩集成后数据表
(2)数据清理
由于数据仓库中的数据是面向某一主题的,数据可能从几个表中抽取出来,数据库中的数据类型不同,必然出现一些数据不完整、数据错误、数据重复等各种问题。
在该课题中,学生成绩数据库中的数据都非常重要,且是经过多次复查才得到的,所以错误数据和不一不致性一般不会存在。但是,可能会出现另外的情况。比如,有的学生有些课程缺考或休学,需要对数据进行置“0”的处理。且这些数据对成绩的分析是无意义的,故可以剔除,以免影响分析结果。
(3)数据归约
数据归约,其目的是缩小数据规模。经过数据预处理后,根据聚类评价模型,把每个学生划分到相应的簇中,对学生形成定性的评价,再根据数据转化规则,得到如表2的数据:
分析如下:
①学生记录共60个;
②性别字段为男或女;
③对“作业”提交情况进行离散化处理,结果为:0表示经常不交作业;1表示偶尔不交;2表示全交;
④对“参加活动”情况进行离散化处理,结果为:0表示不参加活动;1表示偶尔参加;2表示经常参加活动。
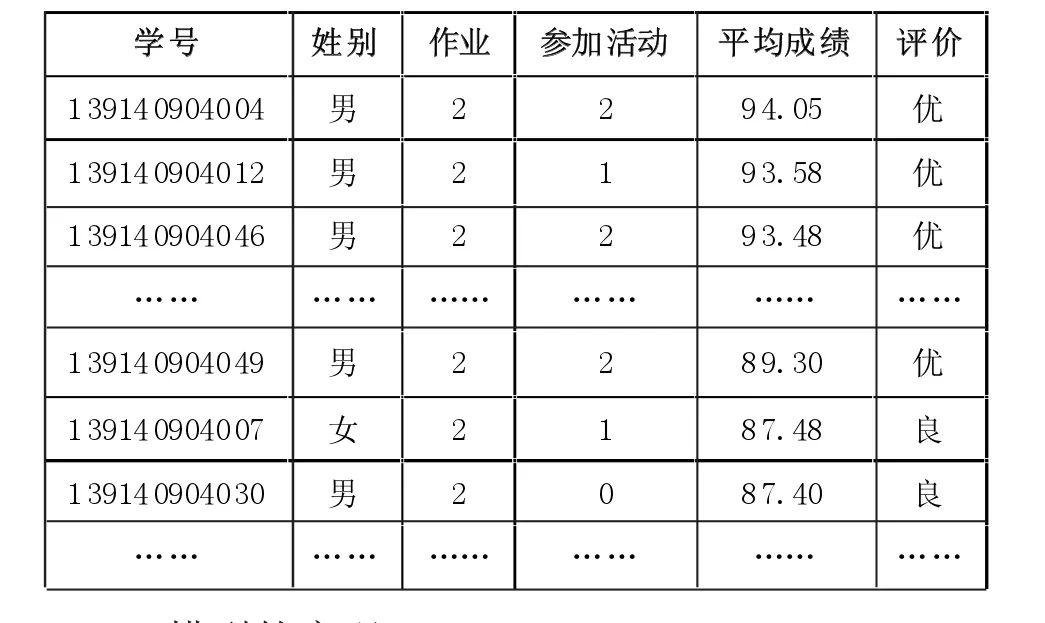
表2 学生成绩归约后数据表
三、模型的实现
为了寻找学生学习成绩的好坏和哪些因素有关、它们之间又存在怎样的关系,论文基于决策树算法建立数据模型,首先对学生成绩数据库中的数据进行处理,然后应用决策树算法建立相应的决策树,并通过分析,得到相关属性与学生成绩之间的关系。
论文以学生成绩分析表为数据集建立挖掘模型,使用决策树算法中经典的ID3算法完成构建模型,具体过程如下:
首先,对成绩分析表中的各属性计算其信息熵;其次,把计算得到的信息增益最大的属性作为决策树根结点,再进行数据子集划分;
最后,划分得到的每个子集递归进行,直到所有属性都划分完为止。
根据上述步骤,详细过程如下:
(1)根据定义的信息熵,计算分类属性的信息量
以上的训练集中,共有60个样本。经过聚类后,得到的簇是“优”的样本有12个,“良”的有16个,“中”的有17个,“差”的有15个。为计算每个属性的信息增益,首先给定样本分类所需的信息熵:
根据信息熵计算公式得到:I(s1,s2,s3,s4)=I(12,16, 17,15)=1.988394308
(2)依次计算每个属性的信息熵
例如:计算“性别”属性,该属性有两个值,需要对每个值所划分的子集计算信息量。
对于“性别”=“男”和“性别”=“女”而言,样本分布如表:

表3 “性别”=“男”的样本分布表
根据公式得每个属性的信息熵计算得到:
E(性别)=48/60×I(24,13,11)+12/60×I(7,2,3)=1.474880232
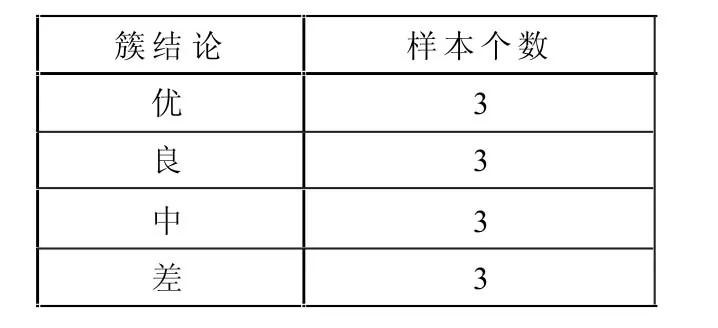
表4 “性别”=“女”的样本分布表
E(作业情况)=31/60×I(12,12,6,1)+15/60×I(0,3,9,3) +14/60×I(0,1,2,11)=1.39741438
E(参加活动)=19/60×I(5,5,2,7)+21/60×I(5,6,8,2) +20/60×I(2,5,7,6)=1.87711283
根据公式Gain(A)=Info(D)-InfoA(D),计算得到:
Gain(性别)=I(s1,s2,s3,s4)-E(性别)=1.39741438
Gain(作业情况)=I(s1,s2,s3,s4)-E(作业情况) =0.590979928
Gain(参加活动)=I(s1,s2,s3,s4)-E(参加活动) =0.111281478
根据以上各属性的信息增益,选择信息增益最大的属性作为根结点,即将“作业”属性的信息增益最大,故以作业决策树的根结点,并且根据该属性的三个值分为三支,如下:

图1 初生成的决策树
递归上述过程,计算出性别、参加活动属性的信息增益,经过计算,“参加活动”的信息增益最大,将它作为“作业”的子节点,引出三个分支,再递归。
经过剪枝等处理后,最终生成的决策树为:
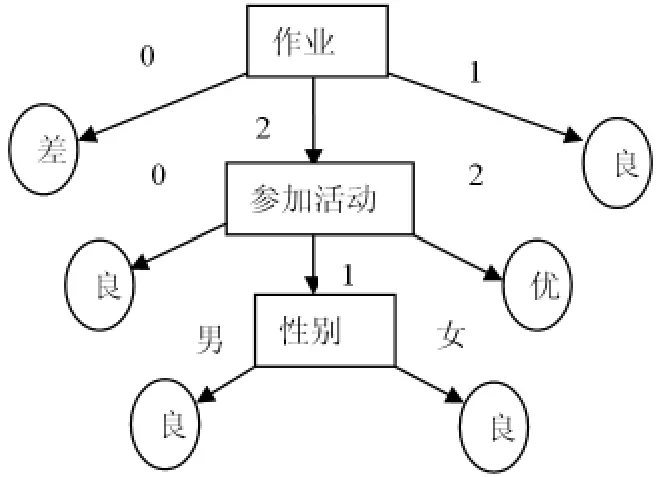
图2 最终生成的决策树
根据以上决策树,通过分析,得到如下结论:
①经常不交作业的学生成绩往往不好。
②性别不能决定学习成绩的好坏。
③学生的学习成绩和参加活动是可以相互促进的,如果学生能很好地调控二者的时间,完全可以相互促进。
四、模型准确性评估
通过研究与测试数据分析,确定以上模型的准确率阈值为85%。将预测集数据利用决策树模型验证结果与实际学生学习成绩的情况相比较,并与相关的教师进行论证,确认本模型的准确率为90%,超过预定的准确率阈值,能够反映学生成绩与影响因素的关系。
其结论为:学生成绩的好坏与学生作业的完成情况及学生是否能合理分配参加活动时间有关。因此,教师在教学中要合理引导学生安排活动与学习时间,并及时督促学生及时完成作业,学生也应学会自我调控,提高学习效率。
[1]韩家炜.数据挖掘概念与技术[M].北京:机械工业出版社,2007.
[2]汉德.数据挖掘原理[M].北京:机械工业出版社,2003,1-2.4.
TN
A
1673-0046(2012)5-0180-02
