基于形状上下文的车牌字符识别
2012-10-08郭燚平武二永
郭燚平,张 桦,武二永
(杭州电子科技大学计算机应用技术研究所,浙江杭州310018)
0 引言
车牌识别是智能交通系统中的关键技术之一,已广泛应用于各级公路和城市道路交通管理,具有巨大的经济价值和现实意义。目前常用的字符识别技术有OCR[1],神经网络[2]和形状上下文[3]。文献1提出的OCR光学字符识别,对于在字符倾斜,以及粘连断裂干扰下的识别正确率有明显下降。文献2的识别法对字符的清晰度要求比较高。本文在文献3的基础上进行改进,对车牌字符进行预处理,均匀采样轮廓点,由数极坐标直方图计算形状匹配代价进行识别。结果表明,该算法使车牌字符识别总体性能得到改进。
1 算法实现
目标轮廓信息在人类感知中非常重要,即使在复杂环境下,目标轮廓也能显得突出和稳定。形状上下文是以统计学角度提出的,它是基于轮廓的点集表示建立的一种强形状描述子,能够利用点与点之间的距离、点在形状中的相对位置关系等字符的轮廓信息用于识别[3-5]。根据对数极坐标变换的二维不变性,在二维目标经过比例、旋转和平移变换后,仍能有效地进行形状匹配。
1.1 前期准备
(1)对分割字符进行预处理
对车牌字符大小归一化,采用双线性插值算法对字符进行归一化大小为20×40;利用阈值迭代法,对归一化后的灰度字符进行二值化;二值化后图像存在部分噪音,会影响后续的处理,利用中值滤波能在衰减随机噪声的同时不使边界模糊,从而较好地保护原始信号,在灰度值变化较小的情况下可得到很好的平滑处理效果。
(2)提取字符边缘
边缘是图像重要的基本特征信息,是图像分割最重要的依据。多次实验结果证明,Canny算法提取轮廓的效果最好,在将图像缩小的情况下,其时间消耗可满足算法的要求[6]。
(3)边缘点采样。采取对轮廓均匀采样的方法,减少象素点数目,从而降低形状下文描述的复杂度,虽然采样点的位置对于形状上下文没有影响,但实验表明,对字符轮廓采取大致均匀地采样对匹配效果具有明显的优势。
1.2 计算形状上下文
(1)对数极坐标变换
一般图像中象素的位置可用笛卡尔坐标(x,y)表示,也可用极坐标(r,θ)来表示,对于选定的坐标原点(x0,y0),它们之间满足如下关系:

当笛卡尔空间中的图像相当于坐标原点发生了缩放和旋转变换,例如图像放大了ri倍,旋转了θj度,变换后新的相应极坐标为(r+ri,θ+θj)时,对数极坐标空间w(u,v)的坐标将产生平移,即u=lnr+lnri,v= θ + θj。
(2)计算对数极坐标直方图
根据形状上下文含义,在对边缘点进行采样后,需计算所有采样点的形状上下文。对于某一点计算形状上下文,就是以该点为原点,作对数极坐标变换,计算对数极坐标直方图[7]。如对轮廓上一给定点pi,对数极坐标系为12θ×5lnr,划分为60个区域bin,计算pi直方图,对应数学公式为:

式中,k=0,1,2,…,59,表示极坐标所划分的第k个bin区域,pij为轮廓上的边缘采样点,则hi(k)就是pij在第k个区域中的数量[8]。要求象素pij是在以pi为原点的对数极坐标系中,且象素pij必须是在第k个bin中。如图1所示,图1(a)中提取轮廓点p1、p2,图1(b)中提取轮廓点q1;分别以这3个点为极坐标原点按图1(c)所示极坐标系进行对数极坐标变换,计算每个点的直方图,结果分别如图1(d),(f),(e)所示;显然图1(b)中轮廓点q1和图1(a)中的点p1直方图相近,互为匹配点。

图1 形状上下文计算与匹配示例
1.3 匹配代价
(1)两点之间的匹配代价
对于两个形状S,M中的任意轮廓点pi和qj,它们之间的匹配代价Cij为:
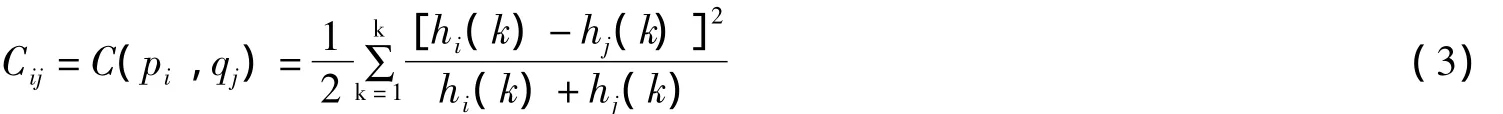
式中,hi(k)和hj(k)分别代表pi,qj的极坐标直方图,得到一个关于最低匹配的映射函数f(i):

那么对于S中的一点pi,由f(i)得到最小的qj,则qj即为点pi在形状M中的匹配点。
(2)两个形状之间的匹配
得到两个形状所有点之间的匹配代价之后,形状匹配的目标是寻找一个置换匹配 ,令匹配代价之和最小,即:

这是二部图匹配的一个特例,可以用匈牙利算法在O(N3)时间内解决,计算结果 就是两个形状轮廓点集之间的对应关系的一种排列[9]。如图2所示,图2左图表示采样特征点,其中“+”和“o”分别为要识别图像和模板图像的特征点;图2右图表示两个形状之间的匹配,连线代表对应点之间的匹配关系。整个算法流程如图3所示。
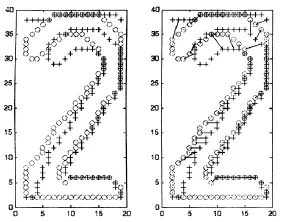
图2 形状上下文匹配示例
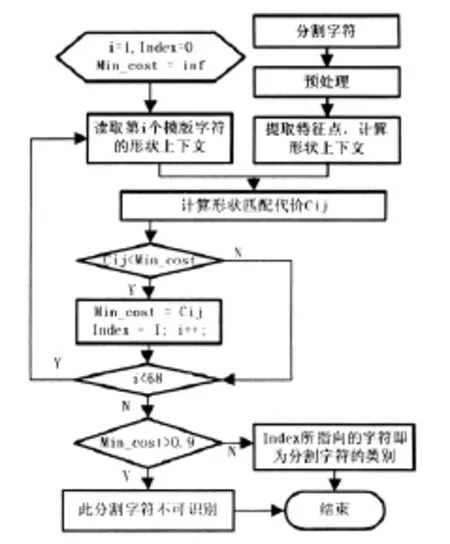
图3 形状上下文算法流程
2 实验研究
实验选取的车牌库为实验室项目提供的500幅真彩图,大小为720×576,对每个字符的采样数目为字符归一化后所含总象素数的70%。所用字符库,是在得到的车牌库中截取
出来的,并随着本算法的实现不断更新。利用matlab进行仿真实验,部分结果如图4所示:

图4 部分实验结果
由上述结果可以看出,根据形状上下文提取字符特征做识别得到的效果还是具有较强鲁棒性的,全部字符的识别率达到83%。但仍然存在部分不足,如字符“Q”,“O”,数字“O”,这些字符本身的相似性,再加上车牌定位、分割、识别操作对图像带来的噪声干扰,更难将这些字符区别出来;还有部分倾斜车牌,易造成“T”,“7”,“1”,“L”识别带来混淆。
3 结束语
本算法基于车牌分割字符边缘点选取的形状上下文方法,根据二维目标形状,采用了归预处理方法,通过边缘检测的Canny算法提取图像的轮廓进行采样;计算对数极坐标直方图;计算不同目标之间的相似度对待识别字符进行判类。实验结果表明,基于形状上下文的字符识别算法具有较高的匹配度和较强的适用性,可广泛用在车牌字符识别中。
[1]贺强.字符识别的相关方法研究[D].镇江:江苏大学,2010.
[2]魏武,黄心汉,张起森,等.基于模版匹配和神经网络的车牌字符识别方法[J].模式识别与人工智能,2001,14(1):123-127.
[3]Belongie S,Malik J,Puzicha J.Shape Context:A New Descriptor for Shape Matching and Object Recognition [D].Berkeley:University of California at Berkeley,2000.
[4]Belongie S,Malik J,Puzicha J.Shape Matching and Object Recognition Using Shape Contexts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(24):509-522.
[5]Mori G,Belongie S,Malik J.Efficient Shape Matching Using Shape Contexts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(11):1 832-1 837.
[6]古昱,汪同庆.基于BEMD的Canny算子边缘检测算法[J].计算机工程,2009,35(11):212-213.
[7]张元元.基于序列统计特性的步态识别算法研究[D].济南:山东大学,2010.
[8]Sinaie S,Ghanizadeh A,Majd E M,et a1.A Hybrid Edge Detection Method Based on Fuzzy Set Theory and Cellular Learning Automata[J].IEEE International Conference on Computational Science and Its Applications,2009,1(9),208-214.
[9]罗磊.基于轮廓的形状匹配方法研究[D].长沙:国防科学技术大学,2008.
