智能组卷中的试题难度评价建模
2012-09-27吴玉田
李 捷,吴玉田
(肇庆学院 数学与信息科学学院,广东 肇庆 526061)
智能组卷中的试题难度评价建模
李 捷,吴玉田
(肇庆学院 数学与信息科学学院,广东 肇庆 526061)
主要研究了网络考试系统设计中利用遗传算法进行智能组卷的问题.首先根据用户对组卷的要求,利用遗传算法对组卷所需的约束条件设置各项指标,利用矩阵理论建立有利于遗传算子进行组合交叉和变异的数学模型;再针对组卷问题中的一个重要约束条件——试卷的难度指标,采用模糊数学方法和项目反应理论对试题库中每一小题进行综合评价试题难度的数学建模,以准确确定每道小题的试题难度系数,最终为实现遗传算法全局寻优和智能搜索奠定基础.
智能组卷;数学模型;试题难度系数;模糊评价
计算机技术的发展为利用计算机进行考试提供了技术基础.越来越多的学者发现利用遗传算法(genetic algorithm,GA)进行智能组卷,能够在较短的时间和占用较少内存的情况下得到较为满意的效果.数学模型是利用算法组卷的基础和关键,模型建立的合理与否决定了试卷的质量和算法设计的优劣.
1 组卷问题的数学模型
计算机智能组卷的目标是组合出一套能满足用户需求参数的最优试卷,可以将其看作一个对多目标组合优化的问题.系统生成的试卷必须同时满足不同的优化指标,找到满足所有约束条件的最优解[1],因此组卷问题是一个典型的约束满足问题的求解过程.
GA是一种并行且能够有效优化的算法,该算法以Morgan的基因理论和Eldridge与Gould的间断平衡理论为依据,同时融合了Mayr的边缘物种形成理论和Bertalanffv一般系统理论的一些思想,模拟达尔文的自然界遗传学:继承(基因遗传)、进化(基因突变)、优胜劣汰[2].GA实际上就是将自然界种群中个体优胜劣汰的进化机制与某一群体中每个个体间的随机信息交换进行全局寻优的一种搜索算法.运用GA进行问题求解,首先要根据计算机信息交换的要求,将所要求解问题的解表示成二进制编码,之后再根据环境要求设置不同的控制参数.例如:按用户设定的试卷难度进行基本操作,如选择、交叉、变异、局域与邻域等,按照适者生存和优胜劣汰的原理,逐代演化产生出越来越好的近似解,最后收敛到由环境限制的最佳个体上,也就是寻找到问题的全局最优解.GA由于自身的全局搜索性、随机性、高度的并行性和较好的编码方式,对处理智能组卷问题非常有利.
根据上述基于GA的组卷特点和组卷系统所要求具有的功能,可以应用矩阵理论建立控制状态空间[3].首先,可以建立一个状态空间控制自动组卷过程中的各项指标:如总题量、题型比例、各题型分值、各章节比例、考试总体时间、试卷难度、试题出现频率,等等.
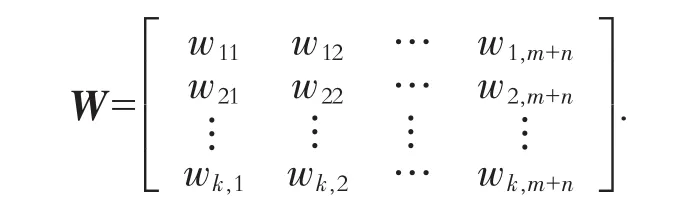
其中:k为试卷的总题量;m为与抽题组卷无关的属性数量,如题目编号、题型编号等;n为抽题组卷约束条件的属性数量,如试题分值、试题难度系数等;W的每一行都是一个分目标,即某一试题的控制指标,如题目编号、题型编号、试题分值、章节、估时、使用频率、试题难度系数等,并且这些属性指标都表示为二进制编码,而题库中某一指标的全部取值则是矩阵中对应的一列二进制编码.假设要求抽取的选择题数量为20,而题库中选择题数量为2 000,每个题目编号为4位整数,每位整数由4位二进制数表示,则染色体的长度为320(4×4×20)位二进制数[4].
2 难度值综合分析
试题的属性指标中最难确定的就是难度系数,而准确确定每道试题的难度系数关系到网上考试的公平性,因此要避免试卷平均难度偏高或偏低,首先要正确反映每道试题的难度系数.本文中,笔者利用模糊数学方法和项目反映理论(item response theory,IRT),综合评价试题的难度系数.
2.1 试卷难度系数模糊评价的建模
每份试卷至少应满足以下几项要求:
1)试卷总分:∑f(Wi)=100(i=1,2,…,k),其中f(Wi)表示试题Wi的题分,总分默认为100分,可由管理员更改.
2)试卷总时间:∑s(Wi)=120(i=1,2,…,k),其中s(Wi)表示试题Wi所需时间,总时间默认为120 min,可由管理员更改.
3)试题类型:∑g(Wi)=gi(i=1,2,…,k),其中gi表示第k类试题的总题数.
4)试卷平均难度系数:p=∑d(Wi)/k(i=1,2,…,k),其中d(Wi)为试题Wi的难度.
5)试题使用频率:r(Wi)<0.2(i=1,2,…,k),其中r(Wi)为试题Wi的使用频率,默认为0.2,可由管理员更改.
6)试题章节:∑t(Wi)<ti=4(i=1,2,…,k),其中ti表示每章节的试题总数,默认为少于4题,可由管理员更改.
7)第i道题难度系数允许的误差|d(Wi)-p|≤Eij(i=1,2,…,k),其中Eij的取值相当于一个适应度函数值,它限制试题的难度系数应尽可能达到以下要求:
a.生成试卷的平均难度接近用户给定的整个试卷的难度系数;
b.难度分布应合理,一组试题中简单题与难题都应该占有一定比例;
c.“拔高题”的难度值应该接近或略高于平均难度,至少不能明显低于平均难度.
由此可见,试题库试题的难度系数在自动组卷中起着很重要的作用.难度值可以结合教师评估和学生测试2个方面进行确定,具体如图1所示.
试题的难度值由教师和学生2方面决定,可以通过评价指标并结合项目反应理论,用模糊数学综合评价法定量地描述出试题难度值.
2.2 试题难度系数模糊评价
应用模糊数学的知识[5],可知对于有限论域u,v,有

图1 试题难度值的确定过程
u={u1,u2,...,un},v={v1,v2,...,vn}.
u称作评价因素集,v称作评语集.若∀ui∈u,则对评价对象给出的模糊评判,可用一个定义在评语集v上的模糊子集写成1组序偶:
{ri1/v1,ri2/v2,…,rim/vm}, 0<rij<1,i=1,2,…,n;j=1,2,…,m.
将这些序偶排列起来组成矩阵,从而得到该对象的评判矩阵为

其中:m为评价指标集ui中元素的个数;n为评价集W中元素的个数.由于学生的个人能力不同,此外还受考场、身体情况、授课教师及其使用的授课手段等因素的影响,不同学生对同一道题的难度具有不同的判断.而教师确定一道题的难度主要以其主观判断和教学经验作为依据,缺乏科学性.笔者建立了一个模糊综合评判模型,试题难度值综合评价系统的结构及各评价指标的具体含义见图2.

图2 试题难度值的评价指标体系
试题难度W={w1,w2,w3,w4,w5}={难,较难,一般,较易,易}={1,0.8,0.6,0.4,0.2}.在进行模糊综合评判时,权重对最终的评价结果会产生很大影响,我们采用专家估计法确定权重.考虑到抽查的学生不能完全代表所有学生的情况,所以主要还是依据教师的经验确定权重:
u=(0.6,0.4), u1=(u11,u12,u13)=(0 5,0.3,0.2), u2=(u21,u22,u23)=(0 5,0.3,0.2).
u1,u2所确定的权重是各元素相对于其上一层次元素的相对重要性权重值.它们所取的值和目标因素集合中的因素一一对应.
选取学生和有关教师组成评审团,对评价指标体系中第2层各元素进行单因素评价.通过对调查结果的整理、统计,得到单因素模糊评判矩阵,之后进行如下综合评判:
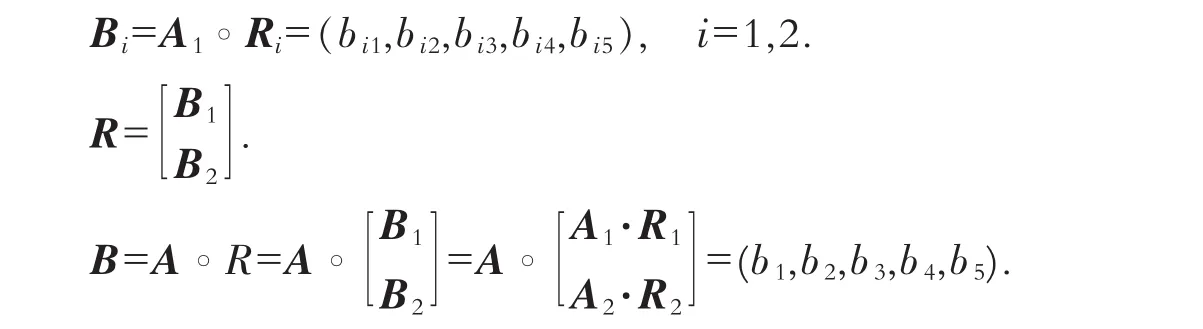
“。”表示广义的合成运算,有如下3种合成运算算子可供选择:
2)若要适当兼顾各因素并保留单因素评价的全部信息,可选算子M(,+),这时
算子M(∧,∨)和算子M(,∨)在突出主因素的同时丢弃了大部分有用信息,所以笔者考虑采用算子M(,+).由M(,+)的运算表达式可发现其具体计算方法就是矩阵乘法运算,这给评价模型的实际应用带来了方便.
3 总结
利用矩阵理论能够清晰描述抽取试题的目标及约束关系,从矩阵可以看出抽题组卷问题是GA在多约束背包问题上的一个具体应用,矩阵理论也有利于二进制编码的GA实施.而采用模糊数学理论和IRT综合评价试题难度,其结果能汇总教师和学生对试题难度的评价意见,较全面地反映试题的难度,有助于实现利用GA组卷时对试卷难度的约束.
[1] 肖寒鹏.基于遗传算法的组卷系统的研究[J].电脑知识与技术,2010,6(9):7 569-7 570.
[2] HOLLAND J H.Adaptation in Natural and Artificial Systems[M].Boston:MIT Press,1992:6-24.
[3] 张帆,唐湘蓉.基于遗传算法的优化搜索技术[J].矿物岩石,1998(S1):236-238.
[4] 马青山.遗传算法在网络考试系统中的应用[J].信息与电脑,2012(2):90-92.
[5] DAN S.Query decomposition and view maintenance for query language for unstructured data[C]//San Francisco:Morgan Kaufmann,1996:227-238.
An Evaluation Model for the Item Difficulty Coefficient in Intelligent Test Paper Composition
LI Jie,WU Yutian
(College of Mathematics and Information Sciences,Zhaoqing University,Zhaoqing,Guangdong 526061,China)
The present paper mainly studies the intelligent test composition by using genetic algorithms in network test system design.In the first place,the indicators are set according to user requirements on the test paper and the constraints by using genetic algorithm to carry out the test paper, using matrix theory to create the mathematical model that enabled genetic operator to crossover combination and mutation,and then one of the major constraints-the difficulty of indicators for Test Paper-is constructed,using fuzzy comprehensive evaluation of the mathematical methods and item response theory to each question in the test database to evaluate difficulty of mathematical modeling in order to accurately decide the difficulty coefficient of each item,and ultimately lay the foundation for the realization of the genetic algorithm global optimization and intelligent search.
intelligent test paper composition;mathematics model;the item difficulty coefficient;fuzzy evaluation
O29;TP301
A
1009-8445(2012)05-0010-04
(责任编辑:陈 静)
2012-05-23
肇庆市科学技术创新计划项目(2012011);肇庆学院自然科学基金资助项目(201119)
李 捷(1980-),女,广东肇庆人,肇庆学院数学与信息科学学院讲师,硕士.
