基于关联词的主题模型语义标注
2012-09-24周亦鹏杜军平
周亦鹏,杜军平
(1.北京工商大学计算机与信息工程学院,北京 100048;2.北京邮电大学智能通信软件与多媒体北京市重点实验室,北京 100876)
主题分析通常采用概率生成模型,如LDA、PLSA等方法,以语义词概率分布的形式描述主题[1-2],这使得一般用户较难理解主题的内容.通常的方法是取概率较高的若干个语义词来表示主题含义[3],但这种方法也常常不能准确表示整个分布所覆盖的全部语义.因此,提出一种主题模型的自动标注方法,提取具有一定语义覆盖度和区分度的主题关联词来描述主题的内容.
1 主题模型的语义标注
主题模型的自动语义标注通常包括2个步骤:首先构造能够表达各种主题语义的候选标签集,标签可以是词、短语,也可以是句子;然后,为不同的主题模型选择与其语义相关的一个或多个标签进行标注.最常用的方法是最大概率主题词标注[4],这种方法的标签集由从文档中抽取的单个词语构成,标签的选择是根据词语在主题模型当中的分布概率来决定的.
相对于单个词语的标注方法,采用短语作为标签进行标注更容易表达主题模型的语义,因此需要生成短语标签集合.常用的短语生成方法是基于统计模型的短语抽取[5-6],即根据同现概率获得同现词,并通过互信息或χ2测试从文本集中抽取可能的短语.但是,这些方法会受到同义词等问题的影响,因此抽取出的标签会出现语义重复问题,并且仅仅根据概率统计获得的标签也存在语义相关性低或语义覆盖性低的问题.此外,如果选择多个标签对主题模型进行标注,还存在如何比较多标签与主题模型的语义相关度、语义覆盖度以及标签间的语义区分度等问题.本文提出一种基于关联词的主题模型自动语义标注方法,其框架如图1所示.
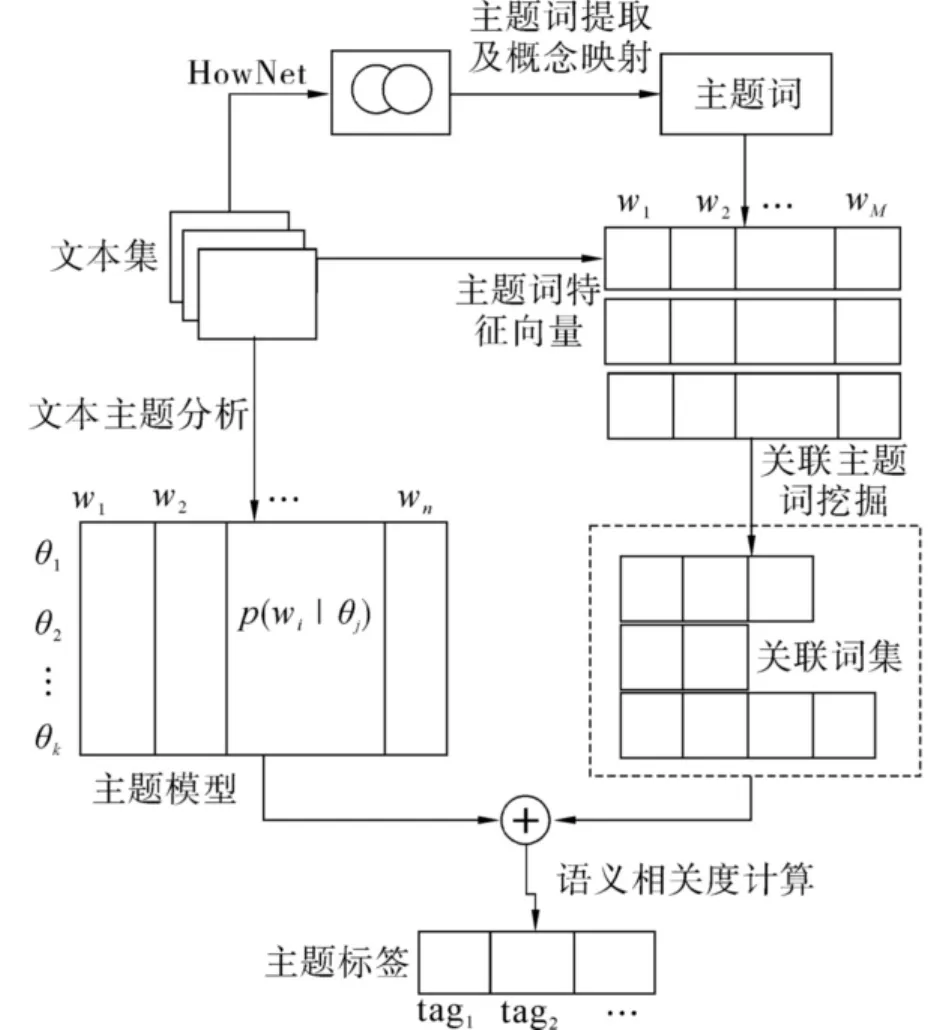
图1 基于关联词的主题模型语义标注框架Fig.1 Framework of topic model tagging based on associated words
首先从参考文本集中抽取词语,并根据语言本体将其映射为义原,实现词语在概念上的归并,从而获得描述语义概念的主题词,同时主题模型也从一般的词语分布转换为概念主题词分布;然后根据实体、环境、活动等不同语义类别对概念主题词进行分类,同时采用基于语义分类的关联规则挖掘获得具有语义关联的主题词,从而建立候选标签集;最后,将标签也以主题词概率分布的形式进行描述,并计算其与主题模型的语义相关度,选择具有高语义覆盖度和区分度的多个标签进行标注.
2 关联主题词的生成
2.1 主题词的语义概念
关联词是依据上下文关系经常搭配使用的词,在自然语言中,为了表达的需要,文本中常常会出现大量关联词.例如,在旅游信息中,“杭州”与“西湖”同时出现的几率非常大,在食品安全事件中,“婴儿”、“奶粉”与“三聚氰胺”同时出现的几率较大.如果将这些关联词作为多个语义单元,一方面会增加主题模型的维数,另一方面也降低了主题模型对文档的表达精度.虽然文本特征抽取可以通过预先设定的阈值来降低特征向量的维数,但它不是在保证语义精度的前提下,因此常常适得其反.
而在另一方面,为了解决主题的表达问题,也必须分析词与词之间的联系,不单是对文本中词的概率统计描述更应从语义上加以理解,此时就需要将具有语义关联性的词语抽取出来用于描述主题的内容.因此,利用关联规则挖掘构造关联词集是一个简单可行的方法,挖掘具有关联性的词语作为一个语义单元,既可以实现特征向量的降维,又可以增大主题表达的准确性.使用关联词集合可以有效地对文本特征空间的关联词进行归并,改进主题标注的效率和精度.
构造关联主题词集合需要解决2个问题:
1)同义词问题.由于中文文本存在语法修饰,不同的词汇表示相同的概念,因此,关联规则算法无法根据中文文本中的深层语义信息挖掘关联词,影响了关联词归并的质量.
2)语义相关性问题.虽然关联规则挖掘可以发现特征词的同现关系,但因为主要反映的是一种统计规律,所以存在某些规则不能很好反映特征词之间语义相关性的问题,即某些关联规则在语义上是无效的.
因此,本文采用“知网”作为概念空间,将特征词映射到概念空间,解决同义词问题,同时提出基于语义概念分类的关联规则挖掘方法来提高关联词的语义相关性.
“知网”[7](HowNet)是著名的采用汉语描述的本体论.它将汉语和英语的词语所代表的概念作为描述对象,同时描述了概念之间、概念所具有的属性之间的关系,并建立了反映这些概念和关系的知识库.“知网”中,单个或复杂的概念以及各个概念之间、概念的属性和属性之间的关系是通过义原或义原的组合来进行标注的.这样的好处是虽然新词不断出现,但义原的增加却极少.因此,在“知网”中,词义就被定义为各种义原的组合.
在主题的词语概率分布模型中引入“知网”作为背景知识,将主题词映射到义原,可以在一定程度上解决同义词替换的问题,使得相同概念、不同描述的词可以进行归并.
为了获得主题信息的概念集,首先对文本集D={d1,d2,…,dN}进行预处理,抽取每篇文本 di中权重较高的特征词,构成基于特征词集的特征向量:

式中:tfi为特征词ti在网页di中出现的频率,n为特征词的数量.
然后引入知网,将特征词映射到义原.在将文本di中的每个特征词t映射为义原时,首先对具有2个或2个以上语义解释的词t进行语义排歧,获取其对应每个语义解释的概率p,然后以p作为权重为语义解释涉及到的每个义原a所对应的特征向量赋值.由于目前知网收录的词条有限,有些特征词没有被知网收录,对于这些特征词予以保留,这样就形成了义原加特征词的特征向量:

式中:ti(1≤i≤k)为没有被知网收录的特征词,w(di,ai)为义原ai在文本di中的权值:
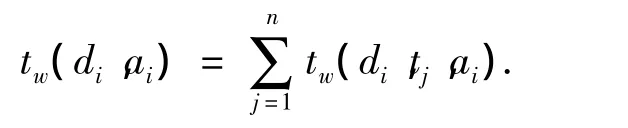
式中:tw(di,tj,ai)为文档 di中词条 tj对义原 ai的权重贡献:

式中:ref(tj)为词条tj对应的义原集合,λ为该义原类别的权重系数.
为了进一步缩减向量维度并提高关联规则挖掘的支持度和置信度,通过计算义原间的相似度[8]可以进一步将相似义原进行归并.义原相似度的计算方法如下:

式中:dis(a1,a2)是义原a1和a2在知网层次结构中的语义距离,α是一个可调节的参数.
2.2 基于语义分类的关联词集构造
经过分析,各类事件信息中的主题词根据语义可以分为5类,分别反映了信息中涉及的实体对象、环境、活动、事件和结果,它们从不同角度描述了事件信息的语义内容.因此,在建立主题词的概念空间之后,文本特征向量中的义原和主题特征词分量被分为实体对象、环境、活动、事件和结果5类,并且根据其概率分布,对主题语义的贡献度赋予不同的权重系数.通过挖掘这5类特征分量间的关联规则,在发现关联词的同时也有助于反映它们之间的语义联系.为了避免同类特征项出现在关联规则之中,定义基于语义分类的关联规则如下.
设文档特征空间中包含的所有义原和特征词构成集合:W={a1,a2,…,al,t1,t2,… ,tk},其中每个元素属于一个语义类别K.则定义基于语义分类的关联规则 A→ B,其中A⊂W,B⊂W,A∩B=Ø,并且,对于规则左部A和右部B中包含的任意项u、v,满足 Ku≠Kv.
对于文本集D,规则 A→ B的支持度为s=P(A·B),置信度为 c=P(B|A).
基于语义分类关联规则的关联词集构造算法如下:
1)利用关联规则算法[9]挖掘基于语义分类的关联规则,获得所有支持度和置信度分别大于s和c的关联规则;
重复2)~5),对获得的每一条关联规则的左右部包含的关联词进行归并;
2)将关联规则右部包含的主题词从主题词集合中删除;
3)在归并后的主题词集合中查找含有关联规则任一边的主题词的归并主题词组合;
4)如果找到,则将另一主题词加入到该归并主题词组合中;
5)如找不到归并主题词组合,则以关联规则左右部的2个主题词构造一个新的主题词组合,并放入归并后的主题词集合中去;
6)在完成所有关联规则的归并后,得到新的主题词集合,集合内包含多个关联主题词组合,即得到关联词集合.
3 关联主题词的语义相关度计算
3.1 语义相似性计算
在抽取出主题词并得到关联主题词集合后,需要从其中选择与主题语义相关性高的词作为主题模型的标注词——标签,实现对主题模型的自动语义标注.而语义相关性计算的难点在于标签和主题模型(主题词的概率分布)之间的匹配.因此本文将标签也以概率分布的方式表示,这样就可以直接与主题模型相比较.
假设标签l以语义词分布{p(w|l)}来表示,则可以使用 Kullback-Leibler(KL)距离算法计算{p(w|l)}与主题{p(w|θ)}之间的相似度.为了获得标签l的语义词分布{p(w|l)},本文采用一种近似方法,通过数据集D来估计{p(w|l,D)},以代替{p(w|l)}.标签和主题之间的语义相似性通过式(1)进行计算.

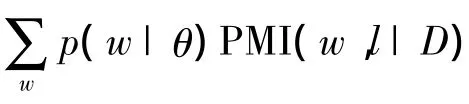
3.2 语义覆盖度计算
好的标签应该对主题的语义内容有较高的覆盖度,语义相关性仅能保证所选择的标签与主题信息具有高相关性,但可能仅表达了该主题的部分语义.因此,当选择多个标签对主题进行标记时,希望选择的新标签能够覆盖主题其他的语义部分,而不是已有标签已经涵盖的内容.
本文采用最大边缘相关(maximal marginal relevance,MMR)方法来选择高语义覆盖度标签.MMR方法常常用于多文档摘要问题,是一种十分有效的去冗余并且取得最大相关性和差异性的方法.本文对MMR进行了一定简化以实现对标签的选择,通过最大化MMR来逐个选择标签,如式(2):

式中:S是已经选择的标签,λ是经验参数.
3.3 语义区分度计算
以上标签选择方法仅考虑了对单一主题的标注,当对多个主题进行标注时,则需要考虑不同主题间的区分,因为如果一个标签在多个主题内都具有较高的相关度,则该标签对于人们区分不同的主题是缺乏帮助的,因此为多个主题选择标签既需要考虑相关度,也需要考虑区分度,在这种情况下,对式(1)进行修正,提出了考虑区分度的语义相似性计算方法:

式中:θ-i表示除主题θi之外的其他k-1个主题,即θ1,2,…,i-1,i+1,…,k,k 为主题数.
式(3)通过S'(l,θi)计算跨主题的标签语义相似度并进行排序,可以为多个主题生成语义相关且具有一定覆盖度和区分度的标签.
4 实验结果及分析
4.1 实验方案
实验选择旅游信息和食品安全事件信息中的4 200条文本数据构成训练文档集,采用LDA主题分析方法[10]在文本集上建立主题模型,利用快速Gibbs采样进行参数估计,设定主题数K=30,超参数 α =50/K,β=0.1,迭代次数为1 000.
采用本文提出的主题词生成方法进行主题词的提取和关联词集构造,将其作为主题标注的候选标签集,然后在候选标签集合上,采用本文提出的语义相关度计算方法选取能够描述主题语义的标签进行自动标注.
实验抽取主题词数N=1 000,为了控制程序运行时间,设定概念空间维数为20,关联归并的支持度s=1%,置信度c=1.5%.最后选择286个关联主题词,每个关联主题词对应1~3个主题词,构成主题的候选标签,该标签集记为TagSet-1.同时,为了与本文的候选标签生成方法进行对比,采用N-gram方法(n=1,2)抽取关键词,并通过χ2测试选择前300个主题词建立另一个候选标签集,记为TagSet-2,从而利用这2个标签集分别进行主题标注,以评价标签集的有效性.在食品安全和旅游信息领域采用以上2种方法分别建立的部分候选标签如表1所示.

表1 部分候选标签Table 1 Some candidate labels
4.2 主题标注结果
表2和表3分别列出了食品安全和旅游领域的部分主题的标注结果.
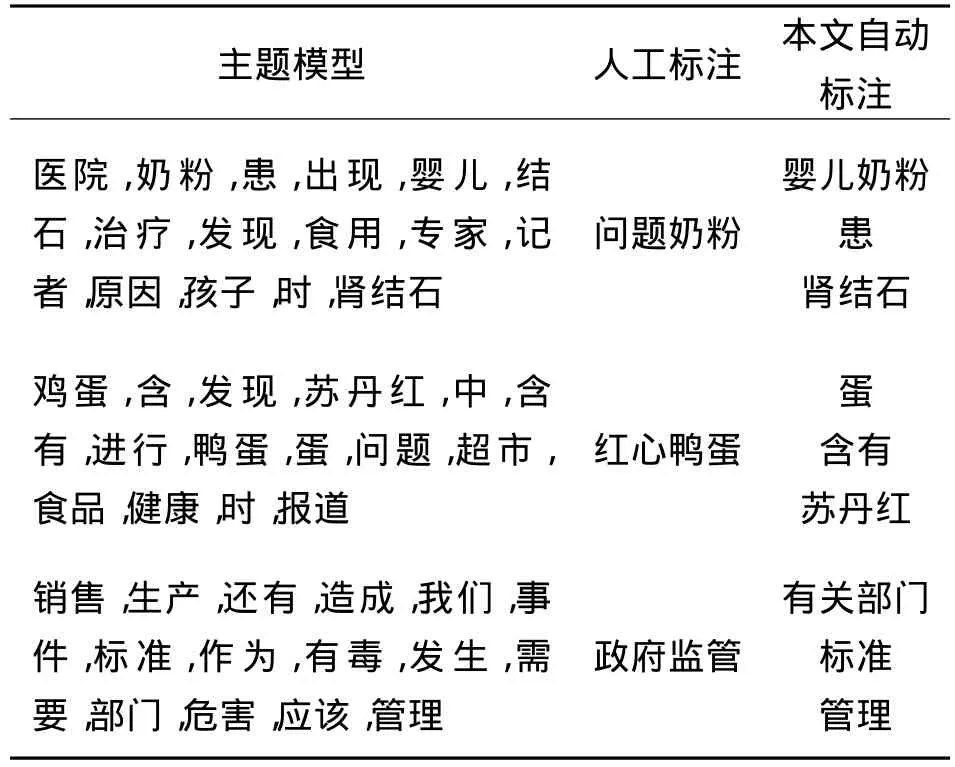
表2 部分食品安全主题及相应标签Table 2 Some food safety topics and corresponding labels

表3 部分旅游主题及相应标签Table 3 Some tourism topics and corresponding labels
表2、3中列出了每个主题模型中概率最大的前15个词,以及根据本文方法自动标注的标签.为了便于比较,表中也给出了每个主题模型的人工标注标签.人工标注的具体方法是将每一主题的主题模型(主题词概率分布)、代表性文档及候选标签集展示给志愿者,由他们选择合适的标签进行人工标注.
可以看出,自动标注的标签基本涵盖了主题的语义,尤其在食品安全领域,例如“婴儿奶粉”、“患”、“肾结石”、“蛋”、“含有”、“苏丹红”等标签已经很好地表达了主题语义,与“问题奶粉”、“红心鸭蛋”等人工标注结果较为吻合.某些情况下比人工标注还要准确,例如志愿者因受媒体报道等的影响,将禽蛋类食品中发现苏丹红的主题标注为“红心鸭蛋”,这是因为最早发现苏丹红是在鸭蛋中,所以媒体将此类事件报道为“红心鸭蛋事件”;而实际上,主题模型中包括鸡蛋和鸭蛋,本文标注方法将它们映射为义原“蛋”并据此生成标签,因此语义上更为准确.
4.3 主题标注的有效性
为了能够准确评价主题标注的有效性,采用评分法将本文标注方法与人工标注和最大概率主题词标注方法进行比较.其中,最大概率主题词标注根据主题模型中词语的概率分布选择概率最高的前3个词作为主题标签.
标注结果的具体评分方法是:通过5名志愿者对3种方法的标签进行打分,即将随机排序的主题及其主题词分布、标签和该主题的最相关文档提供给志愿者,由志愿者对3种方法产生的标签分别打分,然后统计平均得分.打分规则是总分为5分,由志愿者将这5分按照其对标签准确性的评估分别分配给3种方法生成的标签.并且,要求志愿者对仅使用1个标签和使用3个标签进行标注的情况分别打分,结果如表4所示.

表4 主题标注的有效性对比Table 4 Comparison of topic labeling methods
从表4中可以看出,虽然在所有情形下人工标注的得分都是最高的,但本文标注方法的得分明显高于最大概率主题词标注方法.在食品安全领域,本文方法已经接近于人工标注的得分,这主要是因为在食品安全领域中,不同主题的主题词之间具有更高的区分度,尤其是一些专有名词和术语主要在特定主题中出现.
此外,在食品安全领域仅采用1个标签的情况下,本文方法相比最大概率标注方法优势明显,但若采用3个标签,则优势不大.然而在旅游领域使用3个标签的情况下,本文方法仍具有较大优势,这主要是因为旅游领域除特定地点或景点主题外,主题词多是一些通用词,且某些高概率词的语义类别单一,并不能充分表达主题语义.而通过概念映射和建立关联词,则可以将属于不同语义类别且具有语义相关性的主题词组织起来,从而提供更为丰富的语义.例如,“菜”、“肉”、“茶”等主题词被映射为概念“食物”,与关联词“制作”共同构成标签“食物制作”,这样可以表达更明确的语义.
为了比较不同标签集生成方法的有效性,采用本文提出的语义相似性计算方法,分别利用TagSet-1和TagSet-2 2个候选标签集对主题进行标注,并对标注结果打分,总分2分,评分结果如表5所示.

表5 标签集的有效性对比Table 5 Comparison of tag sets
从表5可以看出,本文方法建立的关联词集TagSet-1在总体得分上均高于N-gram关键词集TagSet-2,这主要是因为TagSet-2中存在的多个同义或同语义类别词分散了语义相似度的计算结果,如“鸭蛋”、“鸡蛋”和“禽蛋”被作为3个标签分别计算语义相似度,导致计算结果偏低,影响了标签的选择.而且,TagSet-2中的标签也存在语义类别单一的问题,降低了每个标签的语义表达能力.
5 结束语
提出了一种概率主题模型的自动标注方法,通过主题词提取和语义概念空间上的关联词挖掘方法来生成候选主题词,并且给出了主题词语义相关性计算以及高语义覆盖度和区分度标签的选择方法,实现了主题模型的自动语义标注,解决了对主题词模型进行语义理解的问题.该方法被用于食品安全主题和旅游信息主题的自动标注,实验证明该方法的标注效果优于最大概率主题词标注方法.尤其在食品安全等专业领域,由于充分考虑了专业术语与一般词汇的语义区分度和语义覆盖度,使得本文方法能够取得更好的效果
[1]BLEI D M,NG A Y,JORDAN M I,et al.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3(7):993-1022.
[2]COHN D,HOFMANN T.The missing link—a probabilistic model of document content and hypertext connectivity[EB/OL].[2010-05-10].http://books.nips.cc/nips13.html.
[3]GILDEA D,JURAFSKY D.Automatic labeling of semantic roles[J].Computer Linguist,2002,28(3):245-288.
[4]石晶,李万龙.基于LDA模型的主题词抽取方法[J].计算机工程,2010,36(19):81-83.
SHI Jing,LI Wanlong.Topic words extraction method based on LDA model[J].Computer Engineering,2010,36(19):81-83.
[5]BANERJEE S,PEDERSEN T.The design,implementation,and use of the ngram statistics package[C]//Proceedings of the Fourth International Conference on Intelligent Text Processing and Computational Linguistics.Mexico City,Mexico,2003:370-381.
[6]刘铭,王晓龙,刘远超.基于词汇链的关键短语抽取方法的研究[J].计算机学报,2010,33(7):1246-1255.
LIU Ming,WANG Xiaolong,LIU Yuanchao.Research of key-phrase extraction based on lexical chain[J].Chinese Journal of Computers,2010,33(7):1246-1255.
[7]孙景广,蔡东风,吕德新,等.基于知网的中文问题自动分类[J].中文信息学报,2007,21(1):90-95.
SUN Jingguang,CAI Dongfeng,LÜ Dexin,et al.HowNet based Chinese question automatic classification[J].Journal of Chinese Information Processing,2007,21(1):90-95.
[8]夏天.汉语词语语义相似度计算研究[J].计算机工程,2007,33(6):191-194.
XIA Tian.Study on Chinese words semantic similarity computation[J].Computer Engineering,2007,33(6):191-194.
[9]黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展[J].软件学报,2009,20(7):1854-1865.
HUANG Mingxuan,YAN Xiaowei,ZHANG Shichao.Query expansion of pseudo relevance feedback based on matrixweighted association rules mining[J].Journal of Software,2009,20(7):1854-1865.
[10]石晶,范猛,李万龙.基于 LDA模型的主题分析[J].自动化学报,2009,35(12):1586-1592.
SHI Jing,FAN Meng,LI Wanlong.Topic analysis based on LDA model[J].Acta Automatica Sinica,2009,35(12):1586-1592.
