分布式文件系统的写性能优化
2012-09-17董晓明李小勇
董晓明,李小勇,程 煜
0 引言
如今,人类已经迈入云时代,信息总量正以几何级数的方式迅速增长,基于对象存储技术的大规模分布式存储系统由于其在容量和可扩展性等方面的优势,逐渐替代了以NFS为代表的传统存储方案,越来越受到企业界、学术界的青睐。在近十年内,大量新型的分布式文件系统被研制开发出来,比如 GFS[1],HDFS[2],KFS[3],GlusterFS[4]等等,它们在存储领域都有着广泛的应用,不过让人遗憾的是,这些分布式文件系统虽然有着很大的容量,很好的可扩展性,但是它们的读写性能却远远没有达到网络上限。而且,随着计算技术的迅猛发展,应用程序对用户文件的存取能力也有着越来越严格的要求。因此,提高分布式文件系统的读写性能不仅有学术意义,还有其实践意义。
常用的分布式文件系统的优化写性能的方法主要是写合并。写合并是将应用程序要写的数据先缓存到文件系统客户端的缓冲区中,等到缓冲区的数据堆积到一定数量后再将数据发送到服务器端。这种方法确实有助于提高文件系统的写性能,我们的BlueOcean分布式文件系统也采用了这种方法,但是这种方法对写性能的提升有限,远远没有达到应用程序对写性能的要求,所以我们必须从其他的方面来对BlueOcean分布式文件系统的写性能进行优化。本文以我们设计实现的BlueOcean大规模分布式文件系统为基础,对其写性能进行了三个方面的优化。
文章的剩余部分组织如下:第 2节介绍了 BlueOcean分布式文件系统的整体架构;第3节介绍了FUSE部分的写性能优化;第4节介绍了零拷贝;第5节介绍了应用程序写客户端文件缓冲区与客户端写数据服务器的并行化;第 6节列出了写性能优化前后的实验数据;第7节对本文工作进行了简要的总结。
1 BlueOcean系统架构
BlueOcean是我们实验室设计开发的基于对象存储的大规模分布式存储系统,其架构类似于GFS、HDFS和KFS,它由一个元数据结点,一个备份结点(可选),多个数据结点和若干个客户端组成。其中元数据结点主要用于管理文件元数据信息,并负责负载均衡和租约管理等;备份结点用于在元数据结点停止服务(比如掉电,或网络不通等)后,接管元数据结点的功能,保证元数据结点功能的可靠性;数据结点负责保存数据,并以线程池的方式高并发的处理来自客户端的IO请求;我们使用FUSE在用户态开发客户端文件系统,客户端采用了单线程异步的框架,与元数据结点进行元数据交互,与数据结点进行数据交互。
在我们开发的 BlueOcean分布式文件系统中,用户存储的文件被分割成多个固定大小的 chunk存储在数据结点上,用户可以根据具体应用为每个chunk设置一份或者多份副本,以提高系统的可靠性,保证系统的可用性。
BlueOcean存储系统的架构图,如图1所示:

图1 系统的架构图
2 FUSE部分的写性能优化
使用FUSE在用户态开发客户端文件系统是现有的分布式存储系统客户端的常用的实现方案,例如 GlusterFS。该方法实现起来比较简单,而且FUSE还提供了POSIX语义的接口,通用性强,更由于其在用户态运行,这就保证了客户端程序的安全性和稳定性。BlueOcean分布式文件系统的客户端也是使用FUSE开发的,但是,使用FUSE带来的负面影响就是会比较严重的影响文件系统的写性能。
在对FUSE部分的写性能进行优化之前,我们首先来介绍两个比较重要的概念,模式切换和上下文切换。众所周知,大多数的进程都至少支持两种执行模式:内核模式和用户模式,模式切换就是进程由一种模式切换到另外一种模式,通常情况下,模式切换的代价是比较小的。上下文切换就是将CPU的控制权由一个进程转移到另外一个进程,不仅需要保存住当前进程的运行状态,并且还要恢复将要执行的进程的状态。一次上下文切换的代价是来自很多方面的,CPU寄存器需要被保存和重新载入,TLB表项需要被重新载入,CPU上的流水线也需要被刷掉。虽然影响上下文切换的因素有很多,比如CPU性能,负载情况以及进程的内存访问模式等等,但是显而易见,与模式切换相比,上下文切换的代价是相当巨大的。
在应用程序使用本地文件系统(例如EXT3或者EXT4)的时候,每个文件系统的操作都会产生两次内核态/用户态的模式切换(应用程序进程会先从非特权的用户态切换到特权的内核态,然后再从特权的内核态切换到非特权的用户态),并不会产生上下文切换。而在使用FUSE的时候,每一个FUSE请求不仅会有上面的两次模式切换,还引入了两次上下文切换(从用户态的应用程序进程切换到用户态的libfuse进程,再从用户态的 libfuse进程切换到用户态的应用程序进程),所以执行一次FUSE写请求是要耗费很大代价的。
BlueOcean客户端在执行文件系统写操作的时候,是将写操作先组织成4K大小的FUSE写请求[5],然后再传递给libfuse进程进行处理的。这就产生了一个问题,如果应用程序写操作的数据块的大小超过了4K,那么FUSE是如何处理的呢?目前看来,FUSE在处理数据块大小超过4K的写操作时,是将写操作分割成多个4K大小的FUSE写请求,然后将这些FUSE写请求串行的传递给libfuse进程进行处理。很明显,这种处理方式有着其显著的缺点,就是它可能会将原本一次 FUSE写请求就可以执行完的操作分割成了多个FUSE写请求,产生了额外的上下文切换,严重影响文件系统的写性能。
通过研究我们发现,大多数的应用,包括linux的cp,tar等命令,它们使用的数据块的大小都是大于4K而小于128K的,如果继续保持4K大小的FUSE请求是没有任何意义的,而且还会产生性能上的问题。所以我们将FUSE写请求的大小由原来的 4K增加到128K,这样做将上下文切换的次数降低到了原来的 1/32,避免了原来大量的无谓的上下文切换,使得BlueOcean文件系统的写性能有着显著的提高。
3 零拷贝
在大多数的分布式文件系统中,为了提高写性能,大都会将要写的数据先存放到客户端的缓冲区中,等到数据积攒到了一定的数量后,再集中将数据发送出去。这样做可以有效地降低客户端与数据服务器的交互次数,提升系统的写性能。BlueOcean分布式文件系统在客户端也采用了这种优化方式,但是在实现这种优化的时候却多引入了两次内存拷贝。
在 BlueOcean分布式文件系统中,客户端写操作数据的大致走向,如图2所示:

图2 客户端数据的走向
1) 应用程序要写的数据会被分割成128K大小的块拷贝到FUSE的缓冲区进行处理。
2) FUSE在接收到应用程序发送来的数据后,会再将这些数据拷贝到 BlueOcean文件系统客户端的文件缓冲区中。
3) 当文件缓冲区填满或者文件关闭的时候,客户端程序会将文件缓冲区内的数据再拷贝给客户端的网络模块,并由网络模块将这些数据通过网络接口发送出去。
众所周知,内存拷贝属于 CPU密集型操作,在 CPU性能不高,系统高负载等情况下,很容易成为系统瓶颈,会严重影响文件系统的写性能。因此我们在优化系统写性能的时候,引入零拷贝的概念,实现了FUSE到文件缓冲区的数据零拷贝和文件缓冲区到网络模块的数据零拷贝。
为了实现零拷贝,我们对char类型的数据块进行了封装。使得数据在由FUSE传递到文件缓冲区和由文件缓冲区传递到网络模块的传递过程中,并不执行数据的实际拷贝,而只是执行 char*指针的传递。如果文件缓冲区的大小设置为4M,那么两次数据拷贝会引入8M的数据拷贝量;而char*类型的指针只占 4到 8个字节,两次指针拷贝只会引入 8到16字节的数据拷贝量。很显然,指针拷贝的写性能会远远高于数据拷贝的写性能。
实现了零拷贝的后,客户端的写操作数据的大致走向,如图3所示:

图3 实现零拷贝后,客户端数据的走向
1) 应用程序要写的数据会被分割成128K大小的块拷贝到FUSE的缓冲区进行处理。
2) FUSE在接收到用户应用程序发送来的数据后,再将这些数据以零拷贝的方式传递到 BlueOcean客户端的文件缓冲区中。
3) 当文件缓冲区填满或者文件关闭的时候,客户端程序会将文件缓冲区内的数据再以零拷贝的方式传递给客户端的网络模块,并由网络模块将这些数据通过网络接口发送出去。
4 并行化
我们对BlueOcean文件系统的顺序写流程进行了分析,发现顺序写的整个过程可以大致分为如下三个时间消耗阶段。
第一阶段是客户端将应用程序发送来的数据写到客户端的文件缓冲区里,我们称这个阶段为写缓冲区阶段。BlueOcean文件系统将客户端的文件缓冲区设置为 8M 大小,而在第3节中提到过,我们已经将FUSE的写请求大小设置为128K,所以FUSE是需要至少发送64次FUSE写请求才能将客户端的文件缓冲区填满。这个阶段由于要进行大量的数据拷贝,模式切换以及上下文切换,因此整个过程是相当耗时的。
第二阶段是客户端将文件缓冲区内的数据通过TCP/IP协议以写请求的方式发送给 BlueOcean分布式文件系统的数据服务器,我们称这个阶段为网络传输阶段。在BlueOcean分布式文件系统中,向数据服务器发送写请求只是将要发送的数据推送到数据服务器,客户端并不需要等待接收来自数据服务器的对于写请求的应答,所以发送写请求的时间实际上就是网络推送写请求的时间。由于数据服务器在接收到来自客户端的写请求后,会立刻进行磁盘调度,将接收到的数据写磁盘,所以客户端发送的写请求的数据量越小,开始进行磁盘调度的时间就越早。因此,BlueOcean客户端会限制发送给数据服务器的写请求的大小(可以为 128K或者256K),那么客户端文件缓冲区内的数据会被分割成多个写请求发送给数据服务器。这样做实际上是以流水线的方式实现了网络传输与磁盘IO的并行化。客户端文件缓冲区内8M的数据会被分成64个或者32个写请求,顺序发送给数据服务器。
第三阶段是客户端向数据服务器发送同步写请求后,等待接收数据服务器返回写同步请求应答的阶段,我们称这个阶段为同步写阶段。在第二阶段的写请求全部发送完以后,客户端会立即向数据服务器发送一个包含所有写请求的校验和的同步写请求,只有数据服务器将接收到的所有写请求的数据全部写到磁盘以后,才会向客户端返回一个同步写请求的应答,这意味着客户端文件缓冲区内的数据已经写成功了,可以接收来自应用程序的写数据了。这个过程主要依赖数据服务器端磁盘IO的性能,磁盘IO越高,这个阶段所花费的时间就越短。
上述3个阶段的数据交互流程大致,如图4所示:

图4 写数据交互流程
分析上图不难发现,写缓冲区阶段和网络传输阶段以及同步写阶段是串行执行的,这就说明整个顺序写流程是有性能提升的空间的,通过将整个串行流程改成并行流程可以实现延迟隐藏,达到提高文件系统写性能的目的。实际上,通过上图还可以发现,网络传输阶段与写同步阶段合并在一起就是网络传输与磁盘IO实现两阶段流水线以后的整个流水线阶段,所以我们将网络传输阶段与同步写阶段统称为写服务器阶段。
一种简单的并行化的实现方案是将写缓冲区阶段与写服务器阶段做一个两阶段的流水线处理,实现写缓冲区与写服务器的并行化。众所周知,实现阶段间的流水化,就必须独立这些阶段。所以为了独立写缓冲区阶段与写服务器阶段,客户端必须为每一个文件多申请一个文件缓冲区,这样当一个缓冲区用于向数据服务器发送数据的时候,另一个缓冲区可以接收来自应用程序的数据。
实现了写缓冲区与写数据服务器并行化的写数据交互流程,如图5所示:
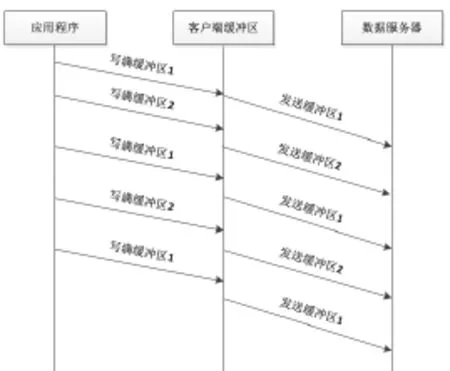
图5 两阶段流水的写数据交互流程
很显然,这种实现方案会消耗大量的内存,使得客户端的文件打开数量的上限减少为原来的一半。如果客户端的内存大小为2G,文件缓冲区的大小为8M,那么优化之前,客户端文件打开数量的上限为256个;而以这种方案优化之后,客户端的文件打开数量就变成了128个,这是很不合理的。所以我们否定了这种方案,并且提出了一种既可以提高顺序写的性能,又不产生额外的内存消耗的方案。
我们知道,BlueOcean分布式文件系统已经将网络传输与磁盘 IO进行了流水线处理,实现了网络传输与磁盘 IO的并行化,而我们提出的这种优化方案就是将写缓冲区阶段也纳入到网络传输与磁盘IO的流水线中,实现写文件缓冲区,网络传输与磁盘IO这三个阶段的并行处理。
在我们的优化方案中,一个文件仍然只有一个文件缓冲区,大小仍然为8M,但是客户端程序并不是要等到文件缓冲区写满以后才向数据服务器发送写请求,而是只要文件缓冲区内尚未发送的数据量达到 128K,我们就会先把这128K的数据以写请求的方式发送给数据服务器。
我们为客户端的文件缓冲区关联了一个计数器,该计数器记录了缓冲区当前已发送的数据的数量(我们用 Q表示)。在每次应用程序写完缓冲区以后,客户端程序都会更新缓冲区的数据总量(我们用T表示),并且计算出缓冲内尚未发送的数据量(Q-T),设(Q-T)/(128K)= N,如果N大于0,就说明客户端缓冲区内尚未发送的数据量已经达到128K,就会向数据服务器发送N个写请求,并且更新Q= Q+N*128K;如果N等于0,则说明客户端缓冲区内尚未发送出去的数据还没有128K,就直接返回,并不向数据服务器发送写请求。只有当缓冲区当前已发送的数据总量(Q)等于 8M(即 Q=T=8M),或者文件被关闭了,才会向数据服务器发送一个写同步请求,同步那些已经发送给数据服务器的写请求。该方案的大致交互流程,如图6所示:
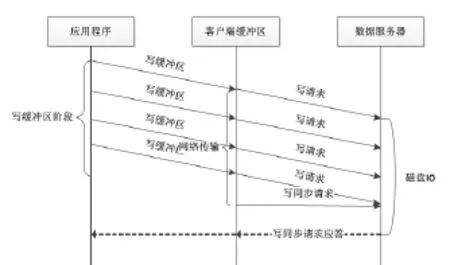
图6 三阶段流水的写数据交互流程
比较图6和图4不难发现,我们的优化方案将原来只实现了网络传输与磁盘IO的两阶段流水线优化成了应用程序写客户端文件缓冲区、网络传输以及磁盘IO的三阶段流水线,大大降低了客户端向数据服务器写8M数据所需要的总的时间延迟,实现了写缓冲区、网络传输与磁盘IO三个阶段的完全并行化,显著地提高了分布式文件系统的写性能。
5 性能测试
5.1 测试环境
本次性能测试,使用了 5台高性能服务器,一台作为元数据结点,一台作为客户端,另外三台作为数据结点。所有的服务器都通过一台千兆交换机相连。所有的服务器都采用了双网卡绑定技术,每个服务器的两个网卡被设置成load-balance模式。
元数据结点的配置信息,如表1所示:
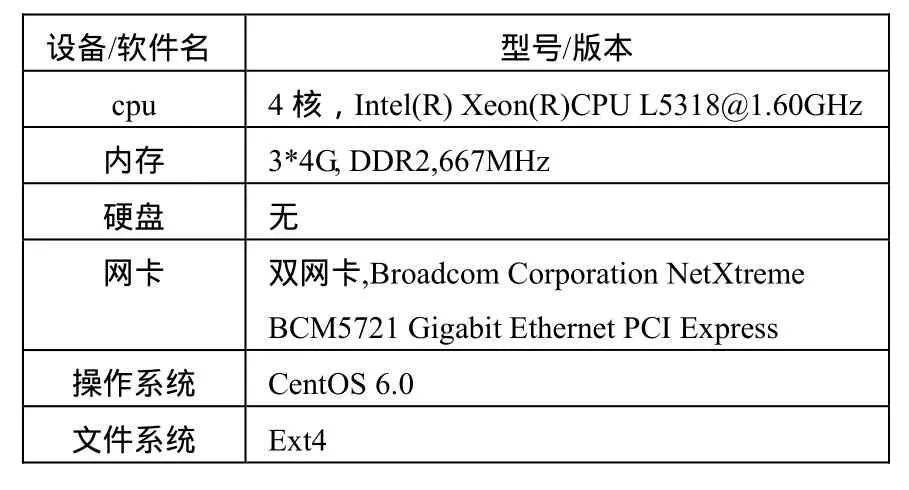
表1 元数据结点配置信息
数据结点和客户端的配置信息,如表2所示:

表2 数据结点和客户端的配置信息
5.2 测试内容
测试1:使用iozone测试工具,在chunk副本数为3的前提下,对优化前后的文件系统的写性能做测试对比。
测试集:文件大小为8G,chunk副本数为3,iozone块大小为16K,32K,64K,128K,256K,512K,1024K。
测试结果,如图7所示:

图7 三副本下,优化前后的系统吞吐量
测试2:使用iozone测试工具,在chunk副本数为1的前提下,对优化前后的文件系统的写性能做测试对比。
测试集:文件大小为8G,chunk副本数为1,iozone块大小为16K,32K,64K,128K,256K,512K,1024K。
测试结果,如图8所示:
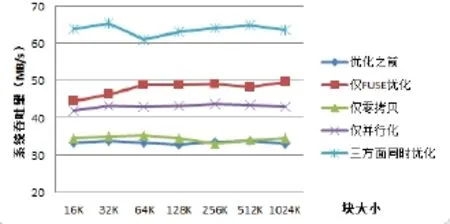
图8 单副本下,优化前后的系统吞吐量
测试3:使用linux的top命令,对优化前后的客户端程序的内存使用量做测试对比,内存使用量,如图9所示:

图9 优化前后客户端程序的内存使用量
5.3 结果分析
1) 单副本的系统吞吐量比三副本的高。这是因为推送三个副本时,网络传输和磁盘IO的时间明显增加。
2) 虽然,仅采用零拷贝对系统吞吐量的提升并不是特别大,但是它降低了在执行写操作时客户端的内存使用量,降低了系统高负载时对写性能的影响。
6 小结
本文对 BlueOcean分布式文件系统的写交互流程进行了详细的分析,指出了影响BlueOcean文件系统写性能的关键因素,并从3个方面对写性能进行了优化。最后通过对优化前后的写性能的对比测试,证明了优化后的文件系统的写性能确实大大提高了。
[1]Sanjay Ghemawat, Howard Gobioff and Shun-Tak Leung.The Google File System[C]. Proceedings of the 19thACM Symposium on Operating Systems Principles. Lake George, NY , October, 2003.
[2]Konstantin Shvachko, Hairong Kuang and sanjay Radia.The Hadoop Distributed File System[C]. Proceedings of 26thIEEE International Sysposium on Mass Storage System and Technologies (MSST’10). pages 1-10,2010.
[3]Kosmos. http://kosmosfs.sourceforge.net.
[4]Gluster. http://www.gluster.org.
[5]Aditya Rajgarhia, Ashish Gehani.Performance and extension of user space file systems[C]. Proceedings of the 2010 ACM Symposium on Applied Computing. New York, 2010, 206-213.
