图书馆3.0是个假命题
2012-09-11黄辉
黄 辉
(广东农工商职业技术学院图书馆,广东 广州 510507)
在中国知网和万方等中文期刊数据库检索图书馆2.0,有将近两千条记录检索结果。在Google、百度上搜索Web2.0,有超过5.7亿条以上的链接。如今,随着Web3.0的提出,图书馆3.0也逐渐成为研究热点。
笔者认为,图书馆3.0是个错误的概念。因为图书馆2.0、图书馆3.0是某些图书馆人模仿Web2.0、Web3.0提出来的概念,而Web3.0,IT界还没有广泛的认同,只是部分人的一种说法。
1 Web3.0是个未被认同的概念
Web 3.0是批评Web 2.0时提出的,较有名的首次提及是2006年初Jeffrey Zeldman(笔者注:杰弗里·泽尔德曼,最早的Web设计师之一,Web标准创建者,制定万维网标准并终止了浏览器之战,让所有网民看到了同一个互联网。)在其个人博客上发表的一篇批评Web 2.0的文章。要理解什么是Web3.0,首先要知道什么是 Web、Web1.0、Web2.0。
1.1 Web2.0、Web3.0是从Web延伸出来的概念
Web的英文意思是蜘蛛网或者网。现在一般都被译作网络、互联网。1989年英籍美国人蒂姆·伯纳斯-李(Tim Berners-Lee)创建了万维网(World Wild Web,简称 Web),即人们常说的Web1.0,它和Web实际是同一个事物的两种提法[1]。
2001年秋天互联网公司(dot-com)泡沫的破灭标志着互联网的一个新转折点。从那以后技术有了实质的进步,很多早期的网络应用又有了新的表现形式,如Ajax、Rss、Blog、Google地图等。大家熟悉的一些早期应用,现在换了一种模式,于是有人就称这个时期(2001至今)为Web2.0,把蒂姆·伯纳斯-李创建的Web称为Web1.0。提出Web2.0中最著名的人,是美国O'Reilly媒体公司总裁兼CEO提姆·奥莱理(Tim O'Reilly)。他是美国IT业界公认的传奇式人物,是“开放源码”概念的缔造者,他还撰文列举了一些 Web1.0、Web2.0,来对比说明它们是不同的事物。如表1。
表1里面列出的,是我们熟悉的一些过去和现在的热门。
Web2.0至今仍未被广泛认同,还在饱受争议,已经有人开始提出Web3.0。提出者认为Web3.0时代已经到来,使用Web3.0的每个用户都会拥有一个基于个人浏览历史记录的网络档案,Web3.0将根据这个档案为每个用户量身定制一套浏览体验。两个兴趣爱好完全不同的人,使用同一项搜索服务,他们得到的搜索结果也会截然不同,因为他们拥有完全不同的网络档案。也就是说有了Web3.0,用户就好像多了一个私人助理,它具备高度的人工智能,对你的所有个人信息了如指掌,并能在互联网上搜集所有相关信息来回答你提出的任何问题[3]。假如某人准备去某地度假,预算是5000元。他在Web3.0浏览器输入“费用在5000元以下的某地度假地”,Web3.0浏览器就会根据输入要求,提供非常符合个人需求的相关信息和方案。
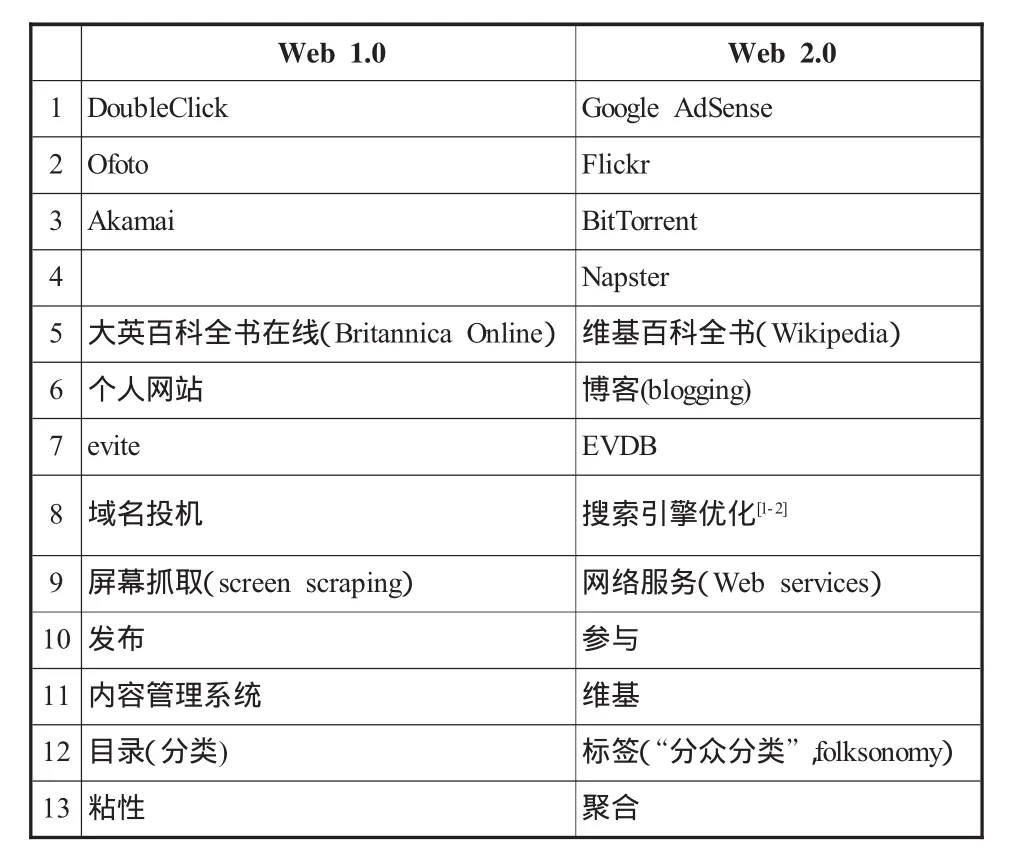
表1 [2]W eb1.0与Web2.0应用
关于Web3.0的种种应用想象,非常具有诱惑性,可是不管是 Web1.0,还是Web2.0、Web3.0,它们在物理层上,都是基于Web,基于最初创建的互联网络协议,唯一不同的只是程序功能发生了改变,由原来的不可编辑、只读性质的,变为现在可参与编辑、可写的、更先进、智能的程序。现在所谓Web3.0网络的基础结构、环境、使用的协议等等,跟蒂姆·伯纳斯-李1989年创建的Web相比,没有任何实质改变。所以,Web2.0、Web3.0都是Web的延伸。
1.2 Web3.0的前身Web2.0仍没有被广泛认同
提姆·奥莱理(Tim O'Reilly)于2004年提出了Web2.0这个概念,用来形容能让用户发布和分享内容的新一代互联网创新技术,如应用很广的Blog、Google地图、Rss订阅等。这些网络应用更注重用户的交互作用,用户既是网站内容的浏览者,也是网站内容的制造者。所谓网站内容的制造者是指互联网上的每一个用户不仅是互联网信息的消费者,同时也是互联网信息的提供者;不仅在互联网上冲浪,同时也是波浪制造者;在模式上由单纯的“读”向“写”以及“共同建设”发展;由被动地浏览、接受互联网信息向主动创造互联网信息发展,从而更加调动了用户的积极性。
实际上,不仅Web3.0没有广泛的支持,Web2.0从提出到现在,仍然饱受争议。互联网之父伯纳斯-李就对“Web2.0”是否真的存在表示怀疑,他认为“Web2.0”只不过是个毫无意义的词[4]。伯纳斯-李一直认为,他设计万维网的目的就是让它处理Web2.0所能处理的所有工作。
1.3 IT界对Web3.0还没有一致的理解和定义
2011年1月7日,Adworld2011互动营销世界暨微time*峰会在北京举行。中国互联网协会副理事长高新民在大会开幕时致辞,认为Web3.0有多种理解,关于Web3.0的定义,现在还没有统一认识[5]。
与Web2.0相比,Web3.0有可能增加一些功能更强大、智能度更高的应用,如果必须要对这些新的应用、新的服务定义一个名称,称其为应用1.0、应用2.0、应用3.0更好一些,使用Web2.0、Web3.0的名称后,容易让人们产生错误的理解。
2 图书馆3.0是盲从W eb3.0的一个错误概念
图书馆3.0是在Web3.0出现后提出的概念。提出者在没有对Web2.0、Web3.0完全理解的情况下,轻率地对图书馆3.0下了定义,认为图书馆3.0=Web3.0(语义网络)+P2P(对等网)[6]。
提出者这样解释他提出的图书馆3.0模型:语义网络解决信息资源描述问题,对等网通过新的网络结构解决服务模式问题。图书馆3.0的核心是资源整合。图书馆3.0是在图书馆2.0基础上发展起来的,显然要继承图书馆2.0的成果。我们如果将图书馆2.0和图书馆3.0结合起来,形成以“整合”为核心的新图书馆模式,即:
● 图书馆服务整合用户—图书馆2.0的用户参与模式
● 信息资源的整合—图书馆3.0的信息描述机制
● 服务模式的整合—信息服务的推模式与拽模式整合
这个观点最早于2006年,在一个较具人气的图书馆员个人博客上提出,之后就被某些图书馆人盲目引用,如在2010年6月《情报杂志》刊登的《基于Web3.0思想的图书馆3.0服务新模式》[7],引用了这个定义;2008年4月《图书馆建设》刊登的《从“Web3.0”到“图书馆 3.0”》[8]也引用了同样的定义。
2.1 图书馆3.0是一个拼凑的错误概念
很显然,图书馆3.0的提法是没有理论依据的,是将Web3.0和P2P拼凑起来的概念。
语义网[4]是互联网之父伯纳斯-李目前正在研究开发中的下一代智能网络,还没有任何突破性的进展,不过他希望这个新的智能网络具备足够的人工智能,可以理解人们输入的命令,并且使用网络数据库语言,根据各个分散的网络数据库检索、处理数据然后返回解决方案。如在搜索引擎输入“一家3口要去某地旅行”,接着系统会返回往返航班、下榻酒店及旅行路线等。这种智能网络即语义网,与所谓的Web3.0是两个事物,前者是具备人工智能,能够理解使用者输入的互联网,后者是一些先进网络应用软件的组合体,本身就不是同一类事物。
P2P[9]是英文Peer-to-Peer(对等)的简称,又被称为“点对点”、“对等”技术,是一种网络新技术,依赖网络中参与者的计算机性能和网络带宽,而不是把依赖都聚集在较少的几台服务器上。对等网[10]是没有任何集中控制的分布式系统,系统中每个节点既是客户机又是服务器,它们在功能上是等同的。
对它的解释,也是含糊不清的:“语义网络解决信息资源描述问题”,这里明显是错误地把Web3.0理解成了语义网;“图书馆3.0的核心是资源整合”,为什么3.0的核心是资源整合?语义网和对等网加起来就能整合,要如何实现,技术方法和手段要怎么操作,提出者没有说清楚。
从以上分析可见,图书馆3.0是个拼凑的概念,提出者没有分清Web3.0与语义网的区别,也没有分析Web3.0跟对等网结合的可行性,而盲从引用者在尚未理解的情况下,就开始讨论图书馆3.0的前景。
2.2 Web3.0尚未被认同,图书馆3.0从何而来
姑且不论图书馆3.0是由Web3.0和P2P组成这个定义是否正确,退一步来讲,即使这个定义是正确的,它应该具备什么功能呢?即便Web3.0已经成为现实,具备与语义网类似,可以自我思考的人工智能,那么,图书馆3.0要利用这种人工智能,为读者提供什么样的服务,具体应该如何实现呢?
事实是,语义网是否能够成为可能,还是水中月、雾中花。1981年诺贝尔医学奖获得者、美国著名神经生物学家、生物心理学家罗杰·渥尔考特·斯佩里(RogerWolcott Sperry)证明,大脑两半球的高度专门化以及许多较高级的功能集中在右半球[11]。日本著名的中医春山茂雄的研究也表明人脑具有左右半球,而机器只是模仿左脑的逻辑计算功能,因而无法具备人脑的想象功能,从而取代人的大脑[12]。所以,语义网即使研发成功,很可能无法实现高级的想象功能,来理解用户输入的复杂命令。同样,模仿语义网的Web3.0自然也无法达到这个功能,在语义网和Web3.0间模糊定位的图书馆3.0就更没有实现的可能了。
3 图书馆3.0是个伪命题
图书馆3.0只是一个伪命题而已,是一些人在错误理解Web3.0后拼凑出来的一个错误定义。另外一部分人又在这个错误基础上将它放大了,认为图书馆3.0的前景广阔,大有可为,甚至一些对图书馆学术界影响比较大、比较著名的期刊也刊登了相关内容的文章。笔者觉得,关于图书馆3.0的争论,可以放一放了。
[1] 陈颖健.语义网悄然崛起沟联全球信息孤岛[J].国外科技动态,2004(10):8-9.
[2] O’Reilly.What Is Web 2.0 Design Patterns and Business Models for the Next Generation of Software[J/OL].O'Reilly,2008(7).[2011-11-18].http://oreilly.com/web2/archive/what-is-web-20.html.
[3] Jonathan Strickland.Web3.0展望[J/OL].[2011-11-18].http://computer.bowenwang.com.cn/web-30.htm.
[4] Tim Berners-Lee,James Hendler,Ora Lassila.The Semantic Web[J/OL].Scientific American Magazine,2001(5).[2011-11-18].http://www.scientificamerican.com/article.cfm?id=the-semantic-web.
[5] 高新民:Web3.0是未来互联网的代名词[OL]http://www.china.com.cn/economic/txt/2011-03/01/content_22025371.htm.
[6] 终于我们可以讨论图书馆3.0(Lib3.0)了[OL].http://rainzen.bokee.com/5863420.html.
[7] 吴一平.基于Web3.0思想的图书馆3.0服务新模式[J].情报杂志,2010(6):244-247.
[8] 吴汉华,王子舟.从“Web3.0”到“图书馆 3.0”[J].图书馆建设,2008(4):66-70.
[9] John Borland.File-Swapping Veers into the Fast Lane[J/OL].Scientific American Magazine,2007(5).[2011-11-18].http://www.scientificamerican.com/article.cfm?id=file-swa pping-veers-into-the-fast-lane.
[10] 宋建涛,等.语义对等网构造及搜索机制研究[J].计算机研究与发展,2004(4):645-652.
[11] 张尧官,方能御.1981年诺贝尔生理学、医学奖获得者罗杰·渥尔考特·斯佩里[J].世界科学,1982(2):47-49.
[12](日)春山茂雄.脑内革命[M].赵群译.南京:江苏文艺出版社,2011:129.
