基于美国当代英语语料库的公式化序列习得模式研究*
2012-09-04周韵,刘颖
周 韵,刘 颖
(湖北科技学院 外国语学院,湖北 咸宁 437100)
要掌握一门语言,不仅仅要学习单个单词的用法,还要知道如何对这些独立的单词进行组合运用.要达到上述要求,一方面需要发展语法能力以便生成合乎句法规则的用法,更重要的另一面则在于对符合本族语者使用习惯的地道表达保持敏感性.Pawley· Syder(1983年)指出,即使是对最熟练的二语习得者而言,最困难的任务之一就是要学会掌握那些别本族语使用者从一系列可能性的表达中挑选出的习惯性用法,例如,本族语者更频繁地使用“let me have a go”而不是“I should like to try”来表达思想.[1]
Wray(2000年)提出公式化序列这一概念用来泛指呈连续或者不连续结构,在大脑中作为一个整体储存和使用,无需通过语法规则再进行生成分析的语串.[2]在1995年,首先留意到公式化语言现象的语言学家We inert曾撰文指出:在语言习得中对公式化语言角色的关注虽然处于持续增长状态,但是总体上还处于边缘化状态,相关研究还未形成一个连贯统一的系统.他认为当务之急是要提供围绕在公式化语言定义和识别方式等理论和操作层面上的困难的解决办法,并将公式化语言的研究置于一个更大的,前后衔接的理论框架中.他建议此举只有在放弃语言知识与语言使用之间的严格界限才能成功实现.[3]鉴于公式化序列表达在语言习得中的重要地位,本研究尝试以新兴的大型历时平衡语料库——美国当代英语语料库为辅助工具来提取和凸显公式化序列.
1 美国当代英语语料库简介
美国杨百翰大学的Mark Cavies教授创建了一系列不同语言包括英语、西班牙语和葡萄牙语在内的语料库.这些语料库都有各种不同的用途:例如佐证本族语使用者在口语和写作方面的特征,关注语言发展变化,调查单词短语以及搭配的词频,并且为语言教学提供真实的语言材料和资源.
本研究关注的是其中的一个大型平衡语料库:美国当代英语语料库(Corpus of Contemporary American English)(以下简称COCA)COCA是当前最大的可供免费使用的平衡语料库,包括有4.5亿词以上的语料,并且均衡的分布在口语、小说、流行杂志、报纸和学术类文章五个不同的文体中.COCA的语料收集始于1990年,并且每年以0.2亿词的速度递增,截止到目前,已具有4.5亿词规模.COCA语料库于2008年被放上互联网,用户经过简单注册确认身份后便能够免费使用该语料库,并在一定范围内可以下载词表等有用数据,极大地方便了广大语料库研究者和使用者.
基于美国当代英语语料库,Mark Davies还开发了一系列关系语料库,都可以通过http://www.wordandphrase.info进入.这一系列关系语料库的检索是以COCA的语料为基础,以频率为标准,方便学习者考查美国当代英语中的典型搭配和用法.
2 基于美国当代英语语料库的公式化序列习得模式探析
美国当代英语语料库自上线以来,每月均有超过10万人次的访问者.由于该语料库做到了语料与检索工具的整合,使用方便而且免费,其应用处于一个持续增长的趋势.COCA语料库被广泛应用在文化对比、汉语新词英译以及自主学习等方面,[4~6]本研究将语料库与公式化序列联系起来,基于语料库数据提取公式化序列并进行有效习得模式探讨,以帮助学习者掌握英语语言的精髓.
2.1 基于美国当代英语语料库提取公式化序列
公式化序列是指一系列的连续或者非连续约定俗成的词的组合形式,体现的是词与词之间的共现关系.在口语或者文本材料中,这一类型的共现关系并没有通过有效的形式体现出来,不便于学习者观察其特征并进行掌握.基于COCA的关系语料库能够以词频为基准,将词与词之间的共现关系进行提取归纳,使公式化用法得以凸显.
进入COCA关系语料库(http://www.wordandphrase.info/frequency List.asp)的频率检索主页面后得到如图1所示的检索页面.该检索范围主要是从COCA语料库的语料中提取的前六万个高频词,并且在检索结果中体现与检索词共现的各类用法.例如,以 love一词为例,将其输入WORD一栏检索框中并勾选所有的词性进行检索,结果如图2所示.
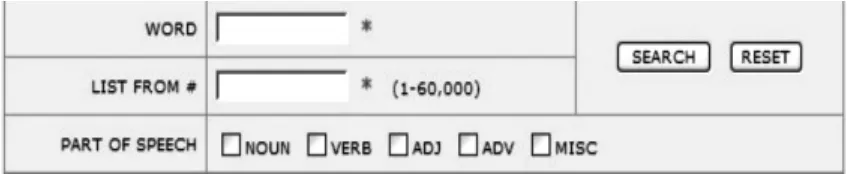
图1 COCA关系语料库检索界面
从图2中可以看到,Love一词的词性限制为名词和动词,并且作为动词出现的频率要高于其名词性用法,不同词性的文体特征也有所不同.动词love的文体特征表现得比较偏口语化,在书面语中则主要出现在小说或杂志类文体中.而名词love则主要出现在书面语中,口语化用法则比较少.上述检索结果体现了love一词在语料库中的词性与语体分布,如果要进一步考查其公式化用法,则可以继续点击图2中的单词进行操作.假设我们要考查love一词的名词性用法,点击该词后出现大量的有用信息.

图2:Love在关系语料库中的检索结果
首先是如图3所示的名词love的文体特征分布图.Love作为名词的用法在整个语料库中共有73652个例子.这些用法分布在各类不同的文体中.注意STORED和MORE这两栏的数字都是超级链接,点击后可以查看相关的语境共现索引行.除此之外,love一词的定义和近义词也被提供.
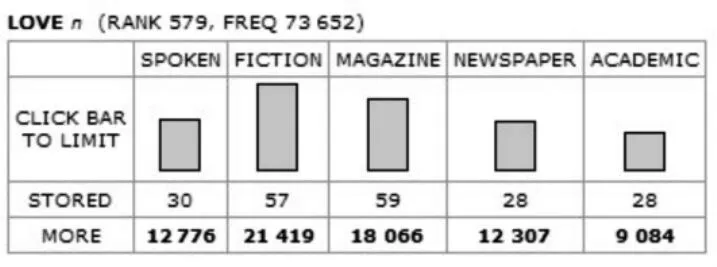
图3 love作为名词的语体特征分布图
帮助学习者掌握公式化序列的用法则在collocate一栏显示.与love连用的词类包括形容词、名词和动词,其具体信息如下:
Adj:romantic, tough, unconditional, lost, brotherly,passionate
Noun:life,affair,story,song,sex,marriage,scene,labor,respect
Verb:fall,make,share,express,declare,inspire,profess,conquer,bind,confess
以上搭配都是按照频率高低排序.也就是说,与名词love呈公式化搭配用法频率最高的形容词是romantic,其次为tough,再次为unconditional等.其次,这些搭配词也是通过超链接形式呈现,即点击搭配词可以得到相关的语境,并且这些词和love之间并不是零词距,也就是说,搭配词与love之间有可能插入其他成分,这也正好符合公式化序列是一个连续或者是不连续的结构组成的特征.通过点击搭配词并观察语境索引行可以得出love与动词构成的如下公式化序列用法:
Fall in love(with)
Make love(towith)
Share one’s love for sbsth
Share one’s love of sth
上述操作简单明了,便于学习者自行开展以某词为中心的公式化序列用法检索,结果易于保存,对于学习者有效进行公式化自主学习无疑会颇有帮助.
2.2 基于美国当代英语语料库甄别公式化序列时效性
语言是随着时代的变迁而不断发展变化的,变化是永恒的.语言中的许多表达都具有极强的时效性,公式化序列也是一样.公式化序列代表本族语使用者对某一部分的单词组合表达形式的偏好,但是这种偏好并不是长期固定不变的.同样一个公式化表达可能在某个阶段是主流化的表达,但是在另一个阶段则可能失去原有的地位.作为公式化序列的重要组成部分之一的短语动词就带有其鲜明的时代特征.Mark Davies(2010)在对两个时间段1990-1994,2005-2009年的短语动词用法进行对比研究后指出:结构相同的有动词+up组成的短语动词中,有部分如hitup,change up,switchup等使用频率呈上升趋势,而另一部分如foulup,sewup,yield up的用法不仅显著下降,而且显得不合时宜.[7]
在短短的十余年的时间里,短语动词的变化不可谓不大.学习者在掌握公式化序列的时候,必须将其用法的时效性纳入考虑范围,也就是尽量挑选在当前的主流化用法.短语动词是公式化序列的重要组成部分,数量庞大,意义广泛,一直是语言习得者的重点和难点,在学习过程中很难将其全面覆盖.学习者可以通过COCA语料库检索锁定最典型的公式化表达,并将其按照重要性排列.例如,在英语中有许多v+up的表达,到底哪个动词与up的搭配最为典型呢?在如图4所示的COCA检索主页面进行如下设置,表示检索对象为up,查找的是与up一词左相邻搭配的原形动词,并体现该检索结果的文体特征和不同年度内的使用情况.
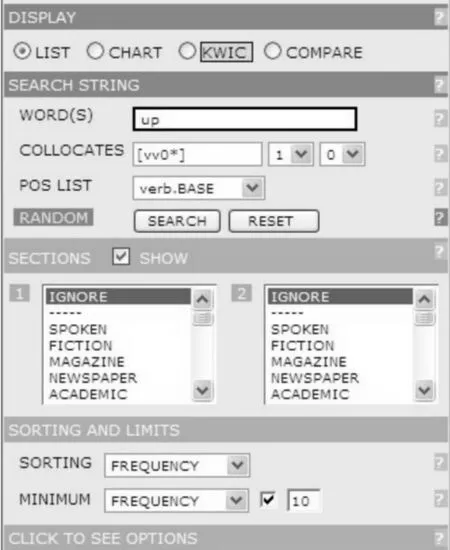
图4 COCA语料库检索主界面
通过图5中的检索结果可以看到,v+up结构短语使用频率最高的动词按照使用频率高低前八个动词分别为make,end,pick,come,wake,get,shut,set.这些短语动词在语料库中的总频率以及其在各种文体中的分布也在图5中有显示.此外,这些短语动词在1990-1994,1995-1999,2000-2004以及2005-2009这四个时间段内的使用频率并没有大起大伏,而是处于一个大体稳定的状态,表明这些短语在近年来一直是英语中大量使用的主体.如果检索到某些短语的使用率呈下降趋势,那么则表明该用法正在逐渐丧失其主流地位.

图5 v+up结构在COCA语料库中的检索结果
仅仅只将注意力放在短语动词上显然是不够的.学习者需要了解该短语动词的搭配,即该短语动词与其它词的共现关系,也就是这个短语使用的公式化特征.在如图4所示检索界面的WORD一栏输入[make]up,表示检索对象各种形式的makeup,包括made up,makingup,makesup,然后在COLLOCATES一栏将搭配词的词性设为名词,并将词距设定为左边为0,右边为4,表示检索与该短语连用的四词距范围内的名词,检索结果表明,与之搭配频率最高的前六个名词分别是:mind,percent,minds,difference,story,time.如果保持其他检索条件不变,将COLLOCATES一栏改设为动词,并设定检索结果显示方式由默认的按照频率高低排列改为基于相关性(RELEVENCE)排序,可以观察到与makeup共现度最高的副词依次为entirely,mostly,roughly,approximately,primarily.基于类似操作,学习者就能够掌握与某个短语动词共现频率最高的各种不同词类.
3 结语
语言学习是一个漫长而反复的过程.要切实掌握一门语言,不仅要熟悉词类搭配的共现关系,还要对语言变化保持敏感,不使用过时的表达.美国当代英语语料库的出现,不仅提供了对当前语言使用的最真实的描述,还能通过其检索软件将语言规律和用法呈现在学习者面前.借助COCA语料库,学习者能够在浩瀚的语言文字中提取那些呈公式化特性的表达并逐步将其纳入自己的学习重点中.在不久的将来,COCA语料库将在语言学习和习得中发挥更大的作用.
[1]Pawley,A.&Syder,F H.Two puzzles for linguistic theory:nativelike selection and native like fluency[A].In J.C.Richards & R.W.Schmidt(eds.)Language and communication.New Youk:Longman,1983,191~226
[2]W ray,A.Formulaic sequences in second language teaching:principle and practice[J].Applied Linguistics.2000,(4).
[3]Weinert,R.The role of formulaic language in second language acquisition:a review[J].Applied Linguistics.1995,112:180~205.
[4]张小宁,从在线COCA看中国文化词汇在当今美国社会的接受[J].长春理工大学学报(社会科学版),2011,(2).
[5]孔雁,基于COCA语料库的汉语新词英译研究[J].长春理工大学学报,2012,(2).
[6]方玲,汪兴富,美国当代英语语料库(COCA)的自主学习应用[J].中国外语,2010,(11).
[7] Davies,Mark.The Corpus of Contemporary American English as the first reliablemonitor corpus of English[J].Literary and Linguistic Computing 2010,(1).
