基于纠错能力的SVM在变压器故障诊断的应用
2012-08-11祖文超李红君苑津莎张卫华
祖文超,李红君,苑津莎,张卫华
(1.华北电力大学 电气与电子工程学院,河北 保定 071003;2.大唐七台河发电有限责任公司,黑龙江 七台河 154600)
0 引言
电力变压器是电力系统中最重要的电气设备之一,及早发现变压器潜伏性故障,是电力部门关注的一个重要问题。检测变压器状态的方法有很多,其中油中溶解气体分析法 (DGA)是检测变压器内部故障的重要方法,如IEC标准中的三比值法则以特征气体的3个相对比值CH4/H2、C2H4/C2H6和C2H2/C2H4来进行故障诊断,实际应用中存在编码不全,编码边界过于绝对等弊端。由于对样本数据缺乏准确的科学分析,很难确切反映故障与表现特征之间的客观规律,因此在溶解气体含量较小的情况下,难以对变压器状态进行有效分析[1,2]。传统方法的这些缺点无疑对变压器潜伏性故障的发现和分析非常不利。因此,由于支持向量机具有小样本学习、全局最优、结构风险最小化及训练诊断时间短等优点,提出了将支持向量机用于变压器油中溶解气体分析的故障诊断。
SVM是针对两分类问题设计的,不能直接用于多类分类问题。而变压器的故障诊断实际是多类分类问题,所以目前SVM难以用来解决变压器的故障多分类问题。为了克服这个缺陷,人们对SVM多分类算法进行了大量的研究,提出了一些有效的SVM多类分类算法[3~5],但这些算法中大部分都没有得到有效分析,使得人们无法使用这些算法获取更好的分类结果。然而对于任一分类问题而言,由于采集的训练样本不足、特征提取不完整以及训练算法本身的缺陷,都会对分类的正确性造成影响,产生分类误差,而纠错编码(ECOC)最大的优点就在于能够有效地对这些误差进行修正,对于一组最小汉明距离为d的纠错编码来说,至少能修正(d-1)/2」位误差,即便有(d-1)/2」个分类出错,系统还是能给出正确的判别结果。而且如果错误量很少,还可能恢复原始信息。因此本文提出了一种基于纠错编码[6]的SVM多类分类算法并应用于变压器故障诊断中。
1 SVM的分类原理
支持向量机算法是一个凸二次优化问题,能够保证找到的极值解就是全局最优解。这些特点使支持向量机成为一种优秀的学习算法。设xi,i=1,2,…N是训练集X中的特征向量,这些向量来自于类yi,i=1,2,…N中。Xi为输入矢量,yi为对应的目标输出矢量,N为对应的样本数。当样本集在原空间是不可分的,需要用非线性变换φ(x)(核函数),把样本向量集从原空间映射到高维特征空间F中,并在F中构造最优的线性决策函数:
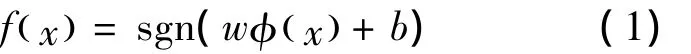
式中:w为超平面的权值向量;b为偏置常数。非线性SVM的学习任务可以转化为以下优化问题:

Cortes和Vapnik在1995年引入了“软边缘”(soft margin)最优超平面的概念,可以通过引入非负松弛因子ξ来允许错分样本的存在,这种方法又被称为C-SVM。C-SVM的一个基本原理就是:如果某个样例不能被分类面正确区分,则通过给定的系数C,控制对错分样本惩罚度的作用,实现在错分样本比例和算法复杂度之间的折衷。
最后得到判别函数为:

2 纠错编码算法
纠错编码 (ECOC)是Bose和Ray Chaudhuri在1960年提出的一种分布式输出码,1963年,Duda,Machanik和Singlleton将其应用于机器领域中[7],1995年,Dietterich和 Bakiri提出了利用纠错编码来将二元分类器扩展到多分类问题中:若类别数为K,则为每一个类别分配一个长度为L的二元纠错编码序列Wi,形成一个K行L列的码本,在训练网络模型时,对于第j列,将该列中码“1”对应的所有类别的数据归为一类,码“0”对应的所有类别的数据归为另一类,以此来构造一个二元分类器,这样K类的分类问题就转化成了L个两类的分类问题。在测试时,L个分类器都对新样本进行判别,得到各分类器输出一个二元序列B={b1,b2,,…bL},然后计算此序列和各类别的码字 {Wi}间的汉明距离,最小距离对应的那个码字所代表的类就是最终的判别结果,即:
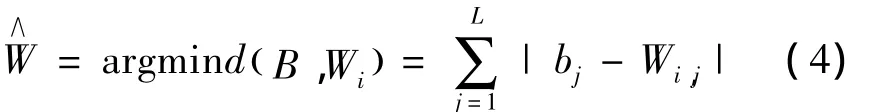
对纠错编码的选择应基于以下两点:
(1)行与行之间互不相关,也即是各行之间汉明距离最大,以便有更强的纠错能力。
(2)列与列之间即不相关也不互补,即某列与其他各列的补集的汉明距离最大,增加列之间的独立性以便进行纠错处理。对于K类分类问题,编码长度L必须满足log2K<L≤2k-1-1。
3 变压器故障诊断
3.1 纠错编码与支持向量
变压器故障类型:低温过热、中温过热、高温过热、局部放电、低能放电、电弧放电。结合变压器常见故障,构造一种编码应用于变压器故障诊段中,如表1所示。

表1 编码长度为10bit的ECC-SVM编码Tab.1 Encoding length of 10bit ECC -SVM codes
表1中各行之间的最小汉明距离是4,表中C1代表正常,{C2,…C7}以次代表上述6种变压器故障类型,表中构造的纠错编码码本中每一列对应一个支持向量机,训练时把码字“1”对应类别的训练样本作为一类,“0”对应类别的训练样本作为另一类,以此构造出一个SVM模型,按照上述方法总共构造出10个SVM。
3.2 ECC-SVM的推广性理论分析
ECC编码的纠错能力是衡量ECC编码性能的主要指标之一。T.GDietterich 等[6,7]指出,码间最小汉明距离决定ECC编码的纠错能力。对于码间最小汉明距离为d的ECC编码,最少可以纠正(d-1)/2」个码位上的分类错误,或者可以检测到d-1」个错误。文献[8]通过分析ECC-SVM的推广性,发现ECC-SVM的推广能力与编码长度、码间汉明距离、编码顺序以及每个SVM的分类间隙等之间的关系,这将从理论上指导人们更合理地使用ECC-SVM来获取更好的分类结果。对于ECC-SVM的推广性,有如下面的结论:对于K个类别的分类问题,码间最小汉明距离为d,ECC的码长为L,.依据未知概率分布产生的m个样本的最小包容球半径为R。如果ECC-SVM能够把m个样本完全正确分类,L个SVM的分类间隙由大到小排列,分别记为r1,r2,…rL,令ki=fat(ri/8),i=1,2…L。那么对于由p产生的m个样本记为Y,有ECC-SVM的分类错误风险至少以概率1-δ不大于下式:2N是码长为L,码间汉明距离为d的编码组数,每一组中有K个码字,依据上述公式,我们计算所有可能的编码,假如一共可以找到N组这样的编码。根据排列组合原理,每一组编码有K!个不同的编码顺序。根据文献[6]中定理5.1,我们只需要保证分类间隙较大的M个SVM的分类精度就够了。每一个码位SVM分类器的1≤ki=fat(ri/8)≤m所有可能情况一共N·K!·mM种设δθ=δ/M,i=1,2,…M。采用文献[9]中定理3.8可得ECC-SVM的分类误差至少以1-δ概率不大于从上式可以看出,ECC-SVM的推广能力不是由推广性最差的SVM的分类精度决定,而是由前M个推广性较好的SVM的分类精度决定。
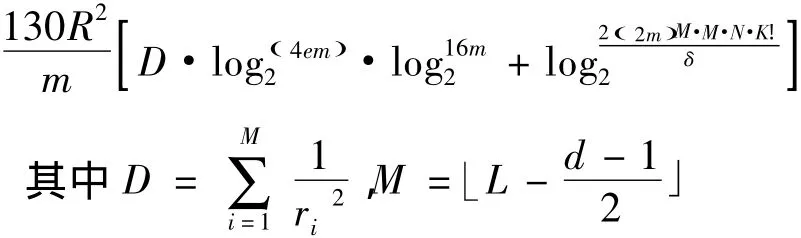
3.3 Iris数据集对ECC-SVM算法的测试
该文在UCI标准的数据上进行试验,下面的试验说明本文算法的有效性和优越性。
Iris数据集是应用于模式识别分析的标准数据集之一,该数据集里有150条数据记录,分别取自三种不同的鸢尾属植物 Setosa、Versicolor和Virginica的花朵样本。每一类鸢尾属植物有50条记录,其中每条记录有四个属性值。
为了便于比较选用1-v-1、BT-SVM和ECC-SVM三种不同的支持向量机多值分类算法,随机选取每一种花朵样本的40个数据作为训练样本,其余的10条数据作为测试样本,测试结果如表2所示。
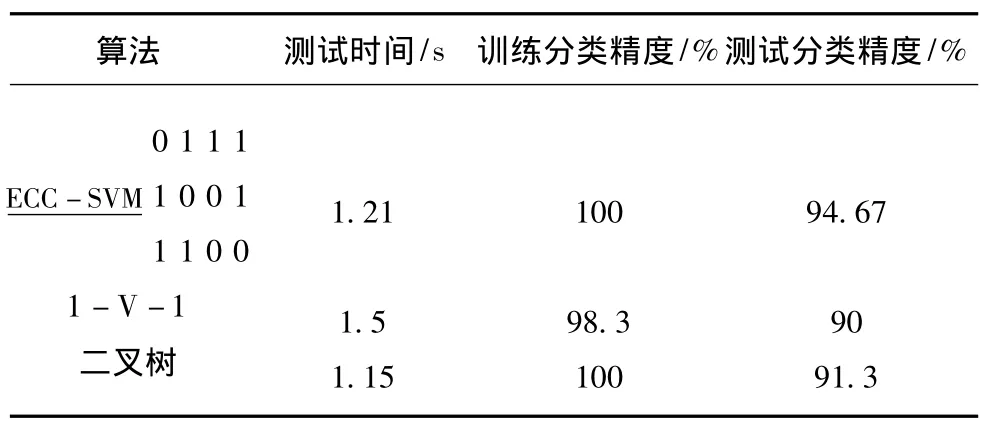
表2 支持向量机分类器测试分类结果Tab.2 Test classfication result of Support Vector Machine classifier
从表2中的实验结果看到,算法测试分类精度最高,说明ECC-SVM多分类算法的分类器具有更好的推广性。对于测试时间,算法计算时间介于1-v-1和二叉树多分类算法之间,但明显优于传统的1-v-1算法,说明本文算法有良好的时效性。
3.4 故障诊断验证与分析
为了验证纠错编码的支持向量机在变压器故障诊断中的效果,首先选取的训练数据是基于色谱分析得到的油中溶解气体的数据。目前国内外所分析的气体对象不统一。在不妨碍判断准确率且分析对象尽可能少的前提下选取这5种:氢 气 (H2)、甲 烷 (CH4)、乙 烷(C2H6)、乙烯 (C2H4)、乙炔 (C2H2),作为原始特征向量。
从相关文献资料收集了大量的具有明确结论的变压器故障数据,整理了340条数据,其中240条作为训练样本,其余100条作为测试样本。同时把这些数据存入SQLSever2005数据库的10个训练样本集中。在VS2008语言环境下结合LIBSvm实现变压器故障诊断 (SVM)模型,结合表2构造的纠错编码来训练网络模型,变压器的DGA数据属于非线性可分数据,目前对于采用何种方法处理并没有明确的理论指导,因此采用C-SVM、基于径向基形式作为核函数来训练模型。
为了对纠错编码多分类性能进行较为全面的研究,构造了2个码组和上表1码组作对比,来探讨类间码字不同分配情况对识别性能的影响。另外,为了更好地评价文中提出的ECC-SVM变压器故障诊断方法的有效性,用相同的数据集在二叉树多分类算法进行识别比较,比较结果如表3所示。

表3 ECC-SVM编码长度、海明距离和分类精度之间的关系Tab.3 Relationship between code length,Hamming distance and classification accuracy
从表3中可看出:
(1)在三种不同码组情况下,其中码组Code1和Code2编码长度相同,所训练的SVM模型个数相同,但码组中Code2的最小汉明距离比Code1的大,结果Code2编码情况下分类精确明显偏高。根据纠错编码性质可知Code2码组可以纠错1个错误或者检测2个错误,而Code1没有纠错能力,故识别性能强于Code1。Code3的编码长度为10,而Code2为7,该两码组最小汉明距离相同情况下,编码长度较长的Code3的分类精确度优越于Code2。
(2)本文提出的多分类算法在分类精度上明显优于传统的二叉树多分类算法。这是因为本文算法有纠错能力即可以允许一定的差错,而二叉树多分类算法,一旦一个节点出错,就会造成判别误差累积。
(3)本文所用纠错编码的多分类算法故障准确率与编码长度、最小海明距离有关。编码长度越长,SVM的推广能力越强,分类精度越高,汉明距离越大,SVM模型的诊断精确度越高。
为了进一步验证本文方法的优越性,分别采用了单隐层BP神经网络 (包含5个输入节点、40个隐含节点、7个输出节点)和三比值法对变压器故障识别问题进行研究对比,采用了与前面方法完全相同的训练样本和测试样本,对BP网络进行网络训练和测试,训练采用了动量法改进的快速学习算法 (学习率v=0.04,动量常数取0.8)目标误差g=0.01,训练次数n为5000。SVM模型的训练采用网格寻优得到最优参数惩罚参数C=1.25,核函数系数g=0.02,对于纠错编码码组之间的最小距离d为6。三种方法的测试结果如表4所示。

表4 故障诊断结果对比Tab.4 Contrast of fault diagnosis results
表4与BP神经网络识别方法相比,ECCSVM分类器的电力变压器故障识别方法识别错误率更低,测试时间小于BP神经网络的测试时间。本文方法远大于三比值测试率,主要因为三比值有时会出现分类错误和诊断结果没有对应的编码。可见,通过和 BP神经网络以及三比值比较,ECC-SVM由于其汉明距离d为6,在进行故障诊断时可以检测到5个SVM模型出错,可以纠出2个错误模型,即有2个模型出现识别错误,也能正确进行故障诊断。由此可见,利用ECCSVM可以减少在实际应用中基于油气数据训练样本不足以及特征提取不完整带来的分类误差,以便提高故障识别精度。
4 结论
针对SVM多分类算法的不足,文中提出纠错编码和支持向量机相结合的多分类算法,从理论上分析了该算法的推广性。与BP神经网络以及三比值方法作对比,通过变压器故障诊断验证了该方法的可行性。基于纠错编码的支持向量机的最大优点是能对一定误差进行修正以及检测出错误的信息,解决了由于搜集样本的不足,以及算法本身的缺陷带来的分类误差问题。
为不同的类设计合适的代码字集合是一个重要的问题。多类学习要求将代码字列向量和行向量的距离很好地分开,较大的列距离可以确保二元分类器是相互独立的,所以如何更好地用二元分类器解决多分类问题需要进一步研究。
